UC and Hu McCulloch have been carrying on a very illuminating discussion of statistical issues relating to calibration , with UC, in particular, drawing attention to the approach of Brown (1982) towards establishing confidence intervals in calibration problems.
In order to apply statistical theory of regression , you have to regress the effect Y against the cause X. You can’t just regress a cause X against a bunch of effects Y, which is what Wilson did in Kyrgyzstan and occurs all too frequent in paleoclimate, without a proper consideration of the effect of the inverse procedure.
Calibration deals with the statistical situation where Y is a “proxy” for X and where you want to estimate X, given Y. It’s the kind of statistics that dendros should be immersing themselves in, but which they’ve totally disregarded, using instead procedures for estimating confidence intervals that cannot be supported under any statistical theory – a practice unfortunately acquiesced in by IPCC AR4, hardly enhancing their credibility on these matters.
The starting point in Brown (1982) is the following:
Perhaps the simplest approach is that of joint sampling. It is easy to see that given α, β, σ, X, X’, the joint sampling distribution of is such that:
is standard normal. Note that this standard normal does not involve any of the conditioning parameters α, β, σ, X, X’ so that probability statements are also true unconditionally and, in particular, over repetitions of (Y,X) where both Y and X are allowed to vary.

I dare say that many readers may find that this statement is a fairly big first bite and that it may not be as obvious to them as to Brown’s audience.
However, this particular result is derived in chapter 1 of a standard textbook, Draper and Smith, Applied Regression Analysis (1981). I worked through this chapter in detail and found the exercise very helpful. Its’ approach is, in turn, derived from E.J. Williams (1959), Regression Analysis, chapter 6. In some fields, while people “move on”, they try to at least achieve results that survive the test of time.
The key strategy in the univariate cases is to draw curves enclosing the 100(1-γ) confidence intervals for y given x. These are quadratic in x. Illustrations are given in Draper and Smith Figures 1.11 and 1.12 and Williams Figure 6.2. The equation for the confidence interval curves is:

where t is the 100(1-γ) t-statistic for the relevant degrees of freedom, 
This can be transformed to a quadratic equation in x. The strategy in these texts for estimating fiducial limits on x given y is to draw a horizontal line at y, determine the intersections with the two confidence interval curves and take the x-values of the intersection as the upper and lower fiducial limits, with the estimate 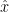
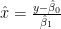
In a “well behaved case”, the upper confidence limit is on the upper quadratic and the lower confidence limit is on the lower quadratic and the estimate
In these cases, if one examines the regression fit in univariate calibration, one finds that there was no statistically significant fit and in effect 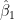
I went through all 14 MBH99 proxies and found that they beautifully illustrated the pathologies warned about in these texts.
First here is an example where the calibration graphic in the style of Draper and Smith 1981 has the structure of a “well behaved” calibration. This is for Briffa’s Tornetrask series. The calibration here has been “enhanced” by some questionable prior manipulations by Briffa, who constructed his temperature series by an inverse regression of regional temperature against 4 time series – so the “raw” proxy is not really “raw” any more. In these graphics, I’ve used the average value of the proxy in the 1854-1901 “verification” period as the y-value (everything’s been standardized on 1902-1980). In this case, the fiducial limits for x (temperature) given y are 0.36 deg C, so this looks like a pretty successful calibration (BUT the prior massaging will have to be deconstructed at some point.)
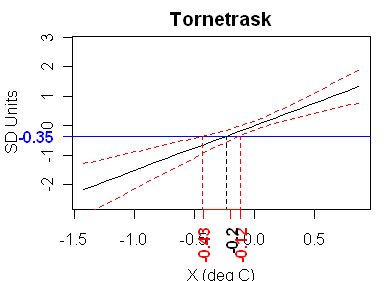
Figure 1. Proxy value (as in other figures) is in SD Units; X-axis in deg C.
Next here is the same style of diagram for the Quelccaya 2 accumulation series, showing a very pretty example of complex roots and no fiducial limits. Examining the original calibration regression, one finds an r^2 of 0.011 (Adjust r^2 of -0.00147) with an insignificant t-statistic of -0.94 for the proxy-temperature relationship. Because the coefficient is not distinguishable from 0, there is no contribution towards calibration from this data.
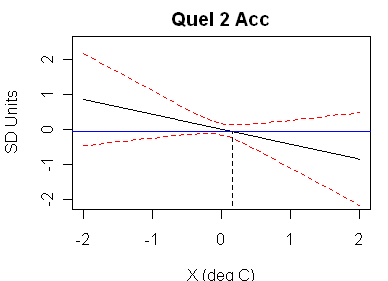
Here’s a snippet of the corresponding Draper -Smith from Google, which shows enough that you can see that the Quelccaya 2 Accumulation case matches the situation in the Draper Smith Figure 1.12 top panel diagram.
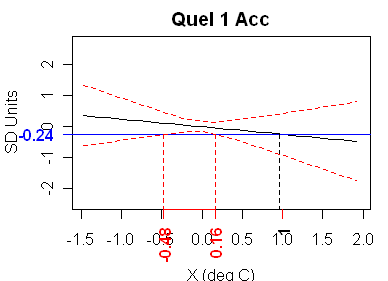
Quelccaya 1 accumulation is also pathological but, in this case, the quadratic solves, but the both the “upper” and “lower” confidence intervals are on the same side of the estimate, as shown below. This calibration also fails standard tests, as the t-statistic is -0.544 (the r^2 is less than 0.01).
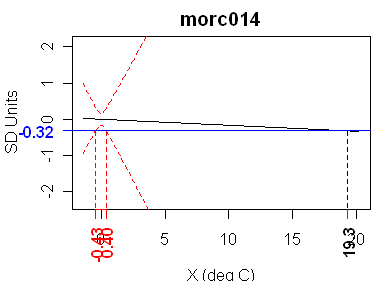
Here’s another pretty example of total calibration failure – the morc014 tree ring series. This would make a nice illustration in a statistics text. This has a t-statistic of -0.037 – a value that is low even for random series.
In total, 10 of the 14 series in the MBH99 failed this chapter 1 calibration test. In addition to the above 3 series, other failed series were: the fran010 tree ring series, Quelccaya 1 dO18, Quelccaya 2 dO18 (why are there 4 different Quelccaya series??), a Patagonia tree ring series, the Polar Urals reconstruction and the West Greenland dO18 series.
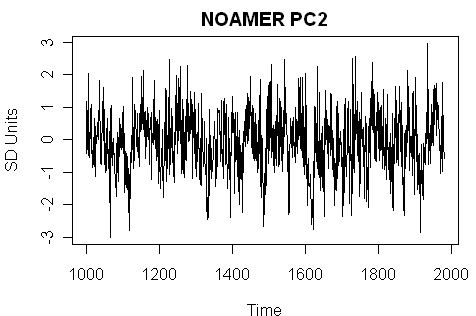
Only 4 series passed this elementary test. In addition to the highly massaged Tornestrask series, the three were: the Tasmania tree ring series, the NOAMER PC2 and the NOAMER PC1 (AD1000 style.) I guess the Tasmania series teleconnects to NH temperature more than most of the NH tree ring reconstructions. Its calibration results are not strong – the t-statistic is 2.1 and the adjusted r^2 is 0.04.
Now to what we’ve been waiting for: the NOAMER PC series. The NOAMER PC2 (and the AD1000 network is far more dominated by Graybill bristlecones than even the AD1400 network) has the strongest fit. It has a t-statistic of 4.3 and an adjusted r^2 of 0.19, the highest in the network.
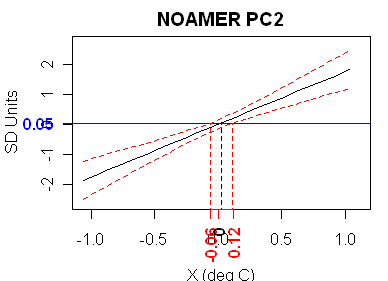
And what does this high-correlation reconstruction look like? Not very HS, that’s for sure.
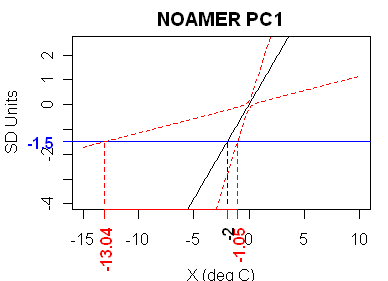
Now what of the NOAMER (Graybill bristlecone) PC1? This is the only MBH99 series that has a HS shape (I’ve flipped the archived series so that it has the expected upward bend). It has a very idiosyncratic appearance in the Draper-Smith style diagram as shown below. The upper and lower limits are on opposite sides of the estimate, but this series yields very broad fiducial limits. The t-statistic here is 1.71, somewhat below statistical significance. The MBH99 “adjustment” of the PC1 has the effect of “improving” its fit to temperature, and thereby increasing its weight in an MBH-style reconstruction.
Moving towards Multivariate Calibration
As we approach the mountain of multivariate calibration, let’s pause and consider the information on fiducial limits from the 4 series that actually calibrated, as summarized in the table below:
| Proxy | Lower (deg C) | Upper (deg C) |
| NOAMER PC1 | -13.04 | -1.05 |
| Tornetrask | -0.43 | -0.12 |
| NOAMER PC2 | -0.06 | 0.12 |
| Tasmania | 0.09 | 1.04 |
Thus, we have the remarkable situation where the 95% fiducial limits for the 4 proxies essentially do not overlap at all (there’s a miniscule overlap between the NOAMER PC2 and Tasmania). It will be interesting to see what happens as one works through a Brown 1982 style calibration. It also illustrates rather nicely the total lack of significance of the majority of proxies.
It’s hard to think how one can purport to derive confidence intervals of a few tenths of a degree, when 10 of 14 proxies don’t calibrate at all and the remaining 4 yield results that are inconsistent in the verification period.
I did these calculations with the MBH “sparse” temperature series since it had a verification value. MBH obviously used temperature PCs for calibration. Even though the two series are highly correlated, the calibrations will be different though I’d expect the patterns to stay pretty similar.





53 Comments
These proxies seem to be used like Tarot cards. Seems if they support your favored conclusion you trust them and if they don’t you just reshuffle the deck and try again. The difference being that climate scientists can (mis)use arcane statistical methods to try to give their divinations validity where spiritualist hucksters can only wear funny clothes and make spooky noises to sell their prognostications.
Just demonstrates the question you have asked many times, Steve:
What leads dendros to assume a proxy relationship between tree ring widths and temperature?
In this case, 5 tree ring proxies abysmally failed (fran010, morc014, Patagonia, Briffa’s Polar Urals and the NOAMER PC3), 3 dO18 ice core series failed, 2 ice accumulation series, while 4 TR series “passed” but yield inconsistent results.
At this point, I’m really trying to focus more on methodology and confidence intervals in terms of showing objectively the meaninglessness of these things, since this point seems to completely elude RC-types who seem to think that because something is called a “proxy” it is one.
The MBH network is also quirky in that it includes a very large proportion of really bad proxies.
Lance, nice post. Great visual image.
Steve,
I am not certain if I understand you correctly. I am not a statistician so I cannot follow the math. Pat Frank has been saying that tree ring thermometry is not valid because it is not proven to relate to the physical world. Are you coming to the same conclusion?
The point here is a different one- not that there aren’t manifold problems with tree ring thermometry.
What I’m doing here is following up on approaches encouraged by UC and Hu in terms of actually working through known statistical techniques for handling calibration.
Also we’re just working here with MBH proxies. This doesn’t prove that tree ring thermometry couldn’t be done properly – only that this particular network doesn’t cut it.
I think that there will be some dividends in terms of RegEM, which has been plopped down as a new methodology but which is built on all these underlying meaningless things.
Regarding the validity of tree rings as temperature proxies:
About ten years ago, a colleague and I visited the University of East Anglia to beg for a overview of climate proxies; Prof. Briffa very kindly obliged. He explained that tree rings would only be good temperature proxies under certain very special conditions: namely, they had to be growing near the tree line in a region where precipitation is in regular supply. Trees in these special circumstances would not have their growth limited by precipitation, but would be quite sensitive to variations in temperature. He offered Scandinavian trees as an example of potentially good temperature proxies. I don’t recall trees in the American Southwest being mentioned as good candidates, and the reason for the omission seems pretty obvious in retrospect.
Prof. Briffa also threw a splash of cold water on our hopes of studying century-scale variability via tree rings. He opined that such low frequencies were not faithfully preserved in tree rings, as changes in local growing conditions over centuries would overwhelm the temperature signal. (Think for example of a neighboring tree dying and dramatically changing the sun exposure of a remaining tree.) Apparently new statistical techniques have been found in the meantime, so he has changed his views on this. If I had Steve’s expertise in statistics, I would probably want to examine whether those techniques for extracting a signal on multi-century time scales can be validated.
As for Quelccaya, it was then the great hope of proxies away from polar regions, until it was realized that the site is sometimes under the influence of atmospheric backwash from the Amazon basin, so the temperature signal in the oxygen isotope ratio is badly obscured by effects of changing regional circulation patterns. As for accumulation rate, is that actually being proposed as a temperature proxy? I never heard such a claim back then.
Steve,
Some initial results are here, http://signals.auditblogs.com/2007/07/09/multivariate-calibration-ii/
indicating that dendros have found shorter sets of CIs than Brown.
Re: 6
The revised Torneträsk pine series is a good candidate for a climatologically useful proxy. It is from an area with a quite maritime climate (drought in the growing season is very rare), it is right at the local treeline, pine is known to be quite sensitive to summer temperatures in this area, there is a long high-quality instrumental record right in the area (Abisko) for correlation and the series mostly contains a sufficient number of trees to smooth out microclimate effects. But how many series like this is there in the world – not many I should think.
As for the pines’ sensitivity to summer temperatures, it is well known to swedish foresters that replanting pines in this area is an almost hopeless undertaking – the plants will only survive if there are several unusually warm summers in a row. Nearly all the old pines in the Torneträsk area started growing in the mid-eighteenth century when there was a couple of decades with exceptionally warm summers.
#6 “tree rings would only be good temperature proxies under certain very special conditions: namely, they had to be growing near the tree line in a region where precipitation is in regular supply.”
A *big* problem with this approach is that the judgment of temperature limitation is always qualitative. This sort of judgment is always useful only for a first filter to get a set of candidates likely to yield a viable data set for evaluation using a quantitative theory that relates some observation (e.g., tree ring widths or densities) to the desired quantity (e.g., temperature).
But there is no such theory. The entire statistical approach to tree ring temperature proxies, with their 0.1 degree plot tick marks, is no more than false precision.
Steve M is doing a brilliant job deconvoluting a complicated statistical problem that Michael Mann’s obscurantism has made far more difficult to assess and develop. Steve’s work will likely eventually revolutionize the field of climate proxies. It’s a revolution long past due. I hope to still be alive when the field honors Steve M for his monumental work.
But absent a quantitative and falsifiable physical theory, proxy climatology will never progress past the quadrupole organization of ‘warm/wet’ ‘cool/dry’; ‘warm/dry’; ‘cool/wet.’
8,9: Thanks for clarification. In my first paragraph, change “would” to “could” or “might.”
Well, I cannot say I understand this post well, but it “rings” of what I remember from my statistics classes long ago.
Steve:
I assume this teleconnection is equivalent to the magical teleconnection of bristlecone pines to global mean temperature?
Steve,
A beautiful essay against which it is hard to argue. Until now I had thought that adequate doubt existed in plant life observations and that stats was the icing on the cake. But it is more than icing, it’s a critical ingredient in the prime examples you analyse. BTW you often quote a correlation coefficient without much comment after calculations. Is it permissible to admit to an overall coefficient value that discriminates good news from bad in your estimation, or would an answer require too much qualification?
Some Web softwares allow posters to add a favourite signature quotation to help recognise them and their style. A good candidate for you would be your own words, slightly arranged for clarity but with the same message.
For example, one I use is
When I was writing my stats package (around 1980) I spent quite a lot of time trying to produce something useful in calibration work. Draper and Smith provide the fundamentals, and their book opens ones eyes to the inherent problems of inverse regression and indeed regression in general. In the ’80s calibration was (still) a subject of controversy, and may well still be. (I lost contact with the literature years ago!)
I decided to implement a relatively simple technique for linear calibration estimating, fully described in “Statistical Methods in Research and Production” by Davies and Goldsmith (Longman 1976) which is usually satisfactory for industrial linear calibration problems, but may be superceded by now I guess. Standard regression will give a biased and unduly optimistic of the calibration and its associated uncertainties.
As Steve has pointed out, it seems that not many, if any, who publish in the paleoclimate literature seem to be aware of the “calibration problem”.
Robin
Steve,
Once again an excellent thread which reveals just how useless proxies are and in particular tree ring proxies at determining the earth’s past temperature.
But of course you do also know that we are now in the post-modern era including the post-modern era of statistics. In the post-modern era 1980s statistical methods don’t hack it and today the message is clearly far more important than the method. It is therefore perfectly acceptable to invent ‘novel’ statistical methods as the climatologist do inorder to re-inforce the planet saving message that fossil fuels are evil and that sustainability is paramount.
scientist
“Apparently new statistical techniques have been found in the meantime, so he (Keith Briffa) has changed his views on this.”
No doubt he did once he’d realised just how much UK taxpayer funding UEA and the Met Office would receive provided he embraced Mannian statistics.
KevinUK
No matter ….The measure of progress depends upon the context of the situation.
Proxy climatology has been highly successful in serving the Global Warming Industy (GWI) and its lucrative market for custom-manufactured analysis work.
Proxy climatology is a well-paying proposition, and there is every evidence it will continue to be a well-paying proposition, regardless of Steve’s or anyone else’s very professional work in examining the joinery of Mann et al’s custom proxy cabinetry work.
Great metaphor 🙂 Steve seems to be demonstrating that there is no glue in those joints.
Good thread, Steve!
It should be noted up front that there’s some semantic confusion about which method is “inverse”. As UC has noted on his blog at http://signals.auditblogs.com/2007/07/05/multivariate-calibration/#more-5, the method Steve is illustrating has been called “Classical Calibration Estimation” (CCE) by Williams 1969, “Indirect Regression” by Sundberg 99, and “Inverse Regression” by Jukes 2006. Here, the regression is run in the natural way, with the truly dependent variable (a proxy) on the LHS and the truly independent variable (temperature) on the RHS, and then unobserved values of temperature are backed out of the equation from observations on the proxy by inverting it.
The alternative, which is simply to regress temperature directly on the proxies even though temperature is exogenous and the proxies endogenous, is called “Direct Regression” by Sundberg 99, but also “Inverse Calibration Estimation” or ICE, by Krutchkoff 1967, because the regression is being run backwards from the natural way. This is the approach used eg by Li, Nychka and Ammann, and advocated by North et al (NAS report 2006, chapter 9).
Our stats mentor UC is very fond of the acronym ICE, which admittedly has a very “cool” sound to it. However, I would suggest that this now be laid to rest because what it refers to as “inverse” is just the opposite of what almost everyone else is calling “inverse”. I suggest that we replace this with Sundberg’s “Direct Regression,” with the understanding that simple-minded is not necessarily correct.
The fact that the North NAS panel (which included statisticians like Nychka and Peter Bloomfield) endorses “Direct regression” over “Inverse Regression” indicates that this is by no means a settled issue. They correctly observe that direct regression is the way to go when X and Y are known to have a bivariate Gaussian distribution. But the problem with this seemingly innocuous assumption is that it assumes that X is known to have an unconditional or prior distribution that is Gaussian with the same parameters that the calibration values were drawn from. With this prior, the conditional distribution of X given Y is indeed given by the “direct” regression of X on Y. But this implicit assumption that the past looks pretty much like the present excessively attenuates the reconstruction, and indeed makes the past look pretty much like the present, even for big swings in Y.
Indirect or inverse regression, on the other hand, makes no such prejudgement about what the reconstruction should look like, and just lets the data do the talking. In the multiproxy case, this can be formalized as a uniform or “diffuse” prior on X.
Incidentally, North et al note that the term “inverse regression” goes clear back to Eisenhart in 1939.
#18, Hu, the underlying statistical null for temperature reconstructions should be a situation that hasn’t been studied in received theory (to my knowledge): a multivariate combination of one “classical” spurious regression e.g. a Yule 1926 type relationship, and 21 white noise equivalents. The starting null is one where the assumptions of the Brown 1982 model don’t apply. Having said that, without carefully understanding every line of how the Brown-style analysis works, you can’t begin to modify the calcs for the more complicated and more relevant null.
My sense is that the “X on Y” strategies – a terminology which is perhaps least likely to mislead – may work well in “well behaved” cases, but are more fragile to spurious regression in the practical null.
In circumstances where there really is no common signal in the data – which is the problem in MBH98 AD1400, MBH99, it seems to me like the Y on X approach in this first univariate step is yielding excellent results. It also looks like the next step is going to deliver some really interesting results.
The case that interests us can be expressed as q=14 or q=22 and p=1, so some of the Brown expressions in x become pretty simple.
I think that a calculation along the style of Brown’s Theorem 1 (see the calcs on pages 292 and 293) is going to give some very compelling results, which won’t take very long but I’ve got chores to do today. We know that the only 4 MBH99 series that calibrate yield inconsistent results. Brown p 293 says:
I’ll bet dollars to doughnuts that this is going to happen in the MBH99 case that we’re studying. We’re going to end up with a rock-solid statistic proving this.
The fallback position for MBH supporters would be – well, this is all regional – to brush off the contradiction. But there’s an approach in Rao that cuts off this approach as well. Rao has a rather nifty approach to multivariate normal distributions through studying linear combinations and thereby reducing multivariate problems to univariate problems. Since the NH temperature index is a linear combination of the reconstructed PCs, the issues here never rise above the univariate situation, so there really is no escape route.
If there’s a valid model, then you shouldn’t get radically different results by using X on Y strategies (which is perhaps what is the heart of Li et al, though I haven’t parsed it enough to tell) as opposed to Y on X strategies. However, I think that the statistical null that I posed above will behave rather differently under X on Y versus Y on X strategies.
As you’ve observed, the re-scaling step creates a further interesting statistical situation. There are precedents for re-scaling in Partial Least Squares – which I’ve observed as being “homeomorphic” to MBH in some key aspects, so it’s not as totally unjustified as you’ve argued elsewhere, but there are intriguing issues in connection with the procedure that have not been reflected on in the literature.
Here’s another problem in going to the next step in Brown 1982. Brown uses the matrix , as UC and Hu have observed. I did a quick calculation in which I did a SVD of
, as UC and Hu have observed. I did a quick calculation in which I did a SVD of  and plotted up the first eigenvector, which yielded the following:
and plotted up the first eigenvector, which yielded the following:
We’ve previously observed the seeming sloppiness of using two near-duplicate series as supposedly “independent” measurements of world climate. The section in Draper and Smith 1981 chapter 1 that follows where I left off deals with exactly the sort of near-duplicate series and requires that such near-duplicates be consolidated prior to the calibration.
In this case, the near-duplicate Quelccaya dO18 series become more than a nuisance as they dominate the matrix (the first eigenvalue is very large.)
matrix (the first eigenvalue is very large.)
This paper really is a treasure house of intriguing statistical horrors. The gift that keeps on giving.
I did the calculations for Brown Theorem 1. The following is the plot for the equation

in a univariate case (using the MBH sparse as X).
I did this calculation for the entire verification period mean. One of the good aspect of Brown 1982 is that they derive distributions for the mean, so that when Ammann and Wahl attempt to salvage “low frequency” means and such, we have a distribution here to test their prevarications.
As one sees, even for the verification period mean, there are no real roots. This means that no confidence intervals can be assigned to the reconstruction. This arises from the inconsistency of the MBH proxies. It will be interesting to try to reconcile these results with the results of Li et al.
The results here are coming from an actual distribution theory – and the results here err on being overly generous to MBH because no account is taken for autocorrelation, which would reduce the degrees of freedom and increase the penalties.
#20 —
Interesting, but are you sure MBH99 didn’t average the virtually redundant Quelccaya series before calibrating? MBH99 speak repeatedly of having 12 proxies: The Data and Method section states that “Before AD1400, only 12 indicators of the more than 100 described by MBH98 are available.” Table 1 describes “12 Proxy Indicators Available Back to AD 1000”. The Verification and Consistency Checks section states that “The calibration/verification statistics for reconstructions based on the 12 indicators available back to AD 1000 are, as expected, somewhat degraded relative to those for the post AD 1400 period.” Then, “Only 5 of the indicators (including the ITRDB PC #1, Polar Urals, Fennoscandia, and both Quelccaya series) are observed to have…” (emphasis added — note that there are implicitly only 2 Quelccaya series in play.)
It’s true that their data file has 4 Quelccaya series, but the only mention they make of 14 series is in Data and Method, where they state, “The 12 indicators (14 counting two nearby ice core sites) are summarized in Table 1.” The Table lists Quelccaya only twice, once for dO18 and once for accumulation, but with an indicator (2) after the name that confused me at first because I thought it was an indicator of which of the two cores they were using. Have you or UC or JeanS actually replicated MBH99 with all 14 series? Or does it work better with 12?
It is also true that Li, Nychka and Ammann used all 14 series, but perhaps they misunderstood what MBH99 had done.
In any event, if Q1dO18 and Q2dO18 are so positively correlated as to be nearly redundant, how can they get such dramatically opposite loadings? Shouldn’t they get similar loadings?
The fact that this is the first PC of the inverted covariance matrix may have something do do with units, since Quelccaya dO18 is in natural o/oo dO18 units, while PC1-3 are in very tiny units, and Morocco has much bigger units. The SVD of the correlation might be more interesting to look at.
Good to see you’ve toned down your rhetoric since the Georgia Tech visit. Heh.
Hu,
In the AD1400 network, they use 22 proxies, which means that all 4 Quelccaya proxies are used individually. This can be confirmed at the Corrigendum SI. Same with all other networks. It’s possible that they did something inconsistent in the MBH99 network. There are other inconsistencies – for example, they retained 3 NOAMER PCs in this network, which is more than the 2 PCs from the AD1400 network. I doubt that exegesis of statements can resolve whether they actually used 2 or 4 and our emulations are not so precise as to tell for sure. One can get close to their results but it’s never quite accurate enough to be 100% sure. (
In terms of the final reconstruction, it probably wouldn’t matter whether 1 or 2 versions of dO18 were used in the sense that the MBH recon is the bristlecone PC1 plus noise and 1 or 2 Q series doesn’t “matter”.
This isn’t anything to do with units, since I standardized everything prior to calculation.
The different loadings in the eigenvector of the inverse matrix is exactly what you see with near duplicates – you expect the opposite loadings since the small effect is the contrast between the two near duplicates. It’s probably not surprising that it bubbles up so high in the inverse matrix but you have to think about it a little.
I use 14.
RE original post, Steve’s diagrams do a good job of illustrating how “inverse” calibration works.
His first graph, for Tornetrask, is a case where the proxy (taken at face value for the moment) has a highly significant slope coefficient. The 95% confidence interval bounds are a pair of hyperbolas, whose common asymptotes are the 95% confidence limits on the slope coefficient represented by the black line. Since these limits exclude zero, both the red dotted lines are monotonic increasing, and hence intersect the blue horizontal line only once, giving a confidence interval of (-.48, -.12) dC for X.
In his second graph, for Q2Acc, the t-stat for the slope is only -.94, so that the 95% confidence interval for the slope does not exclude zero. In this case, the slopes of the 95% confidence interval bounds for the proxy necessarily change sign, with the upper one starting off downward sloping and then turning up, and the lower one starting off upward and then turning down. In this graph, the bounds are wide enough that there is no intersection at all with the blue line, which means that the 95% confidence interval for X is unambiguously (-inf, +inf) — ie we know nothing about X from this proxy. This is of course as it should be, since inverting the black line to find its intersection with the blue line requires dividing by its slope, and it is meaningless to do this unless we are very sure that the slope is not zero.
The graph for Quel 1 Acc likewise has a slope that is not significantly different from 0, which means that it should not be inverted. Formally, there are two intersections of the blue line with the lower dotted red line, but these do not give a confidence interval for X. Instead, what has happened is that the upper bound of the confidence interval has gone off to plus infinity, and then come back from minus infinity to -.48. Formally, the confidence region is therefore the entire real line except for the interval (-.48, .16)! But since the confidence region is unbounded in both directions, this is essentially the same situation as above for Q2Acc, and we should not be misled by the two real roots. Morc014 is similar.
PC2 has a significant slope, and therefore finite confidence intervals. It would have been interesting to see these added to the graph of the reconstruction which, incidentally, should be in dC, but for some reason is given in SD units.
Brown’s formula in Steve’s first box is for the distribution of a single Y’ value as a function of a hypothetical X’ value, and therefore is the correct formula to use when reconstructing the temperature for a single year. In fact, however, Steve’s graphs mostly illustrate the reconstruction of the average temperature for the entire 48-year validation period, 1854-1901. Since the black lines are straight, the point estimate for the average temperature can just be backed out of the average value of the proxy with no modification. However, when the average of m Y values is taken, they have a smaller variance than each single Y value by a factor of 1/m. Hence, we get to replace the “1 + 1/n + …” in Brown’s formula with “1/m + 1/n + …”. This will not affect the asymptotes of the confidence intervals for Y, but will make them much narrower in the “waist”, and hence the confidence intervals for X will be considerably narrower, assuming it is valid to construct them.
This effect is very important when one is trying to reconstruct say decadal or tridecadal averages of temperature from annual proxies. The point estimate of the average is just the average of the point estimates. However, the CI of the average is not the average of the CI’s, but in fact is much narrower!
This will also affect Steve’s Consistency Test in #21, since the narrower confidence intervals will aggravate the inconsistency of the different proxies!
BTW, there must be something wrong with the PC1 graph. Steve says that the t-stat for the slope is -1.71, yet the 95% confidence bounds are shown as being monotonic decreasing. In fact, if they were constructed with a t critical value greater than 1.71, they must turn around and give infinite confidence bounds. Something is wrong here.
Hu # 26 Thank You!!
re 20
Is Quel 2 O18 a mirror of Quel 1 O18
#26. Hu, as to your comment on #21, I used the formula from Brown 2.9 and subsequent equations, so that the factor for the verification average is incorporated into this particular calculation. In fact, this was one of the things that was very useful in this methodology – it dealt directly with the “verification period mean”, neatly disposing of the “low frequency” issue.
This differed from the post, which was based on the Draper and Smith 1981 diagrams – which is what I was using as a template. Draper and Smith drew their curves based on the formula for the “true mean” which they state as:
As you observe, this differs from both the formula for the “true mean” and the formula in the quote from Brown 1982, which is the formula for a single value.
I think that I navigated successfully between these different formulae,as I was keeping this issue in mind as it was one that I struggled through (even if I haven’t described the differences very clearly.)
The y-axis for the proxies is, as you observe, SD Units, as the proxies were standardized to standard deviation units in the calibration period, which is consistent with Brown equation 2.3. I think that this is preferable to denominating them in deg C, which is not a form in which they arrive. I’ve edited the graphics to show this.
Sometimes the PCs are oriented up and sometimes down. I used them as archived and , in the AD1000 network, the archived PC1 has a negative HS with a big downward bend. This is an artificial orientation which gets reversed in the regression stage. I’ve re-stated the graphic to show what happens if the orientation is flipped – the confidence intervals are the same; I’d verified that this doesn’t affect the comment #26 calculations.
It is not obvious to me why the direction of causation between temperature and tree growth matters in this case.
If we were foresters trying to estimate the effect of temperature on tree ring growth (ceteris paribus), and if we assumed (heroically) that all the other (omitted) variables which affected tree ring growth were uncorrelated with temperature, then it would make sense to regress tree ring growth on temperature, and not vice versa. (Reversing the regression would bias the estimated slope coefficient towards zero.)
But we are not, in this case, wanting to solve the forester’s problem. Instead, we want to “predict” or “forecast” temperature conditional on our information of tree ring growth. In our case, I think it is appropriate to regress temperature on tree ring growth, even though we know that causality runs in the opposite direction.
Assume the true (causal if you like) relation is given by: Y=bX+e where e is a set of omitted variables uncorrelated with X. (Y is tree ring growth, and X is temperature). In this case, Y is a noisy signal of X, where e is the noise. If we had an infinitely large sample (just to make things simple), we could estimate b perfectly, by regressing Y on X. Our forecast of Y, conditional on observing X, would be bX. But our forecast of X, conditional on observing Y, would NOT be Y/b.
This is the standard “signal processing” result. If I remember the formula correctly (and it’s been a long time) the forecast of X should be (VarbX/VarY)(Y/b), which is always smaller (in absolute value) than Y/b. You partly discount the signal, because you know the signal is partly noise. The bigger the noise/signal ratio, the bigger the discount. In other words, if you regress Y on X, then the fitted line from that regression does NOT give the correct forecast of X conditional on Y. The fitted line from the reverse regression, of X on Y, WOULD however give the correct forecast of X conditional on Y.
Please forgive me for wasting your time if I have totally misunderstood you.
Steve, regarding Quelccaya 1
Based on the graph, it appears that a more correct description would be that there is no solution for the upper limit, and two solutions for the lower limit.
Sorry to barge in here to pick a nit…this is marvelous work you’re doing. You and the CA statistical team (UC, Hu, Jean S.) should submit some of this work to Technometrics, or at the very least American Statistician.
Have you ever considered engaging Wegman as a co-author? Or has that poor fellow’s career suffered enough because of his stance on the hockey stick? 😉 I’d also love for Norm Draper to have a look at some of the things you’re doing. Norm’s got nothing to lose, his place is secure.
Re #21, 29, Brown’s (2.8) is a lot more intuitive to me than his (2.9) or (2.12), but he says they are all equivalent so I’ll take his word for it. For this purpose, taking an m-period average is equivalent to averaging over el replications of each proxy at a single point in time, so (2.8) etc would be valid with el replaced with m = 48 in your case.
Is this what you did? What test size did you use to get the F critical value?
I still don’t like using (2.8) etc to form a confidence interval for X, but this is a neat way to test the proxy network for internal consistency! Note that this doesn’t have to be restricted to the validation period, since in fact the formula doesn’t use the true value of X there. It can be used separately at every point of the reconstruction, whether annual or time-averaged.
I would think that autocorrelation would take it the other way, since on the one hand the coefficients will be estimated with less precision (thus giving more leeway), while on the other hand the variance of an m-period moving average of Y will be more than 1/m times the variance of a single value for Y. But one thing at a time.
RE NickR #30,
You may be way ahead of us here, Nick. So far all this calibration literature is just trying to make inference about an isolated X value that is so far from the calibration period and other known or infered X values that all we have to go on is the proxies.
But if in fact X(t) takes say a random walk in time, then X(t) has a distribution centered on X(t+1) even if we have no proxy information. If we have already observed X(t+1) (if it’s the first point in the calibration period) or estimated it (from its proxy data plus what we knew about X(t+2)), then we have a classic Kalman Filter signal extraction problem that merges the information from the proxies with the prior for X(t) that we back out of what we know about X(t+1).
(If X is not exactly a random walk, but has richer dynamics, the generalized KF will accommodate that as well.)
So I think you’re onto something here, but just regressing X on Y is too strong, since it assumes the prior for each X(t) is the calibration period average of X, instead of the posterior for X(t+1) convolved with the distribution for delta(X).
#30. One of the biggest differences between someone like myself with a background in business/economics and people more oriented to physical sciences is that I view “signal”-“noise” as a metaphor -it’s simply not a term that would occur in a econometrics context. It doesn’t make any sense to say that the Dow Jones Index is the employment “signal” plus noise, for example. Instead of assuming that things are “signals”, you have to prove the model.
X on Y regression may be rational if you KNOW that you have a signal-noise relationship but if you don’t really KNOW that there’s such a relationship, it seems fraught with peril to me. I think that you have to wade through the relationships one by one and show that there is a Y on X relationship for every “proxy” and that the relationship is physical rather than spurious.
RE Larry T #28,
No — these were separate cores. Apparently core 2 is what is known elsewhere as the “Summit” core.
In a Li, Nychka and Ammann-style direct regression of temperature on all 14 MBH99 proxies (plus AR(2) terms), Q1dO18 is highly significant (t = 2.65, essentially the same as for PC1), while Q2dO18 is insignificant and actually a little negative. However, there is sufficient positive correlation between them that you can’t reject the hypothesis that their coefficients (and those for Acccumulation) are equal. Of course, this regression is backwards, but the marginal significance levels are probably similar when the proxies are regressed on temperature, after the correlation is taken into account. (In a simple regression, the t-stats and R2 are identical no matter which way you run the regression, even though the product of the slopes is not 1 but R2.)
Results from a GLS run, Z is a data frame of temperature plus standardized MBH99 proxies :
Generalized least squares fit by REML
Model: sparse ~ .
Data: Z
AIC BIC logLik
37.26263 86.19561 -0.6313171
Correlation Structure: ARMA(1,1)
Formula: ~1
Parameter estimate(s):
Phi1 Theta1
0.9775272 -0.7790133
Coefficients:
Value Std.Error t-value p-value
(Intercept) -0.06851227 0.12465898 -0.5495975 0.5837
Tornetrask 0.03345209 0.01558081 2.1470060 0.0339
fran010 0.00937839 0.01554326 0.6033730 0.5475
NOAMER.PC1 0.02224757 0.02041603 1.0897112 0.2782
NOAMER.PC2 0.01722778 0.02146286 0.8026785 0.4239
NOAMER.PC3 -0.02276525 0.01710325 -1.3310477 0.1859
Patagonia 0.02160940 0.01673480 1.2912857 0.1993
Quel.1.Acc -0.02182089 0.01825973 -1.1950280 0.2346
Quel.1.O18 0.07480318 0.03540141 2.1129997 0.0368
Quel.2.Acc -0.00353665 0.01796287 -0.1968869 0.8443
Quel.2.O18 -0.06887792 0.03403978 -2.0234534 0.0454
Tasmania -0.01381249 0.01737051 -0.7951693 0.4282
Urals 0.02177762 0.01623049 1.3417722 0.1824
W.Greenland.O18 -0.03277348 0.01936025 -1.6928232 0.0933
morc014 -0.02713614 0.01920792 -1.4127574 0.1605
NickR
I think you are assuming a prior distribution for X (as also Hu observed in #33), and this leads us to filtering theory. ICE and CCE (or whatever you want to call them) are solutions to this problem when X is i.i.d Gaussian sequence and X has noninformative prior, respectively. What would happen in the middle, I don’t know;
Kalman filter is based on stochastic difference equation
where is the n-vector state at
is the n-vector state at  ,
,  is the state transition matrix,
is the state transition matrix,  is nXr matrix, and w is white Gaussian sequence,
is nXr matrix, and w is white Gaussian sequence,  . Observations are
. Observations are
where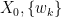 , and
, and  are assumed independent. But in Kalman filter,
are assumed independent. But in Kalman filter, 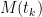 should be non-stochastic, so I’m not sure how to combine calibration theory with filtering. Yet, I’m interested in relevant literature references!
should be non-stochastic, so I’m not sure how to combine calibration theory with filtering. Yet, I’m interested in relevant literature references!
Note that signal and noise are here well defined, X is signal and v is noise. (w is called process noise, but it is part of the signal!) In many climate science papers SNR is mentioned but signal and noise remain undefined. This leads to great confusion, see for example
http://landshape.org/enm/rahmstorf-et-al-2007-ipcc-error/
Moore et al. cited in that post says
Fit any model, assume that residuals are noise. Nonsense.
Re # 37 UC
You are beyond my maths now, but re my 13 above, have you created your signature quote with this?
Over the last 30 years, I’ve noticed that for many in both science and in business, the mathematical analysis techniques have become both a near-complete abstraction and an end in themselves, as opposed to being tools for describing some physical reality or for describing and modeling some real-world process.
IMHO, because of the general decline of commercial industry and commercial science in this country, for graduates in science and mathematics, there is no longer a strong external motivation for making provable connections between their abstract models and the real world physical processes.
The jobs to be had, and the money to be made, in science and mathematics today lies in building analysis building blocks which support the customer’s pre-determined conclusions, whatever they are. In other words, please the customer by telling them whatever they want to hear, but make it all look scientific to those who don’t know the score.
What’s happening today in the Global Warming Industry — largely a government owned and operated industrial concern — is the most extreme example of this trend.
Re: first clarifying my own #30
My disagreement (or perhaps misunderstanding) is with Steve’s statement:
“…with the estimate X^ being calculated from the fitted linear equation: X^ = (B0^ – Y)/B1^ ”
(Sorry, I can’t figure out how to do maths or quotes)
I understand that Steve is here following an existing literature, and is not himself saying that this is a good estimator of X. What I am saying is that (I think) this is never a good estimator of X, because it is always biased, and that the estimator of X based on regressing X on Y is, at least sometimes, a good (unbiased) estimator of X conditional on Y.
Re: Steve #34
I too am coming from an economics background, and I too take the signal/noise thing as a metaphor. Actually, it’s a metaphor I picked up from the old rational expectations macroeconomics literature, which in turn must have picked it up from the physical sciences. Causation between the Dow and employment is obviously complicated. But if I had information on today’s Dow, and wanted to estimate today’s employment, I would regress employment on the Dow; and if I had information on today’s employment, and wanted to estimate today’s Dow, I would regress the Dow on employment. (I am assuming in each case I have no other data, and can only do simple regression.) The question is not which one causes the other; the question is which page is missing from today’s newspaper, the employment page or the Dow page.
Re Hu #33
I am definitely not way ahead of you (and Steve)! My econometrics was never very good, and I took it a long time ago, and haven’t really kept up. But I still think I am (at least partly) right in this case.
Your example has the variables being non-stationary, and trying to estimate temperature way outside the calibration/sample range, so no simple procedure will work under these conditions. My point is much simpler.
Suppose the variables are stationary, normally distributed, iid, whatever. In other words, let’s make all the assumptions we need to make (which I have forgotten from my long-ago classes) so that a simple OLS of Y on X will give us a good estimate of b in the equation Y=bX+e. Under these assumptions, Y^=b^X will give us a good (unbiased) estimate of Y conditional on observing X. But X^=Y/b^ will give us a bad (biased) estimate of X conditional on observing Y. And reversing the regression, regresssing X on Y, and using the fitted line from that regression, will give us a good estimate of X conditional on observing Y.
What happens outside those “nice” assumptions is another question, but at least the “reverse regression” procedure works sometimes, while the X^=Y/b^ never works, so why use it?
Re UC #37.
I’m sorry. I sort of understood your first paragraph, but then you lost me, because I lack the background to follow you. You are way more knowledgeable than me, but perhaps my point is simpler than you think it is.
Re #21
Let me get this straight. Because MBH99 uses many proxies (to justify its claims to be a global temp reconstruction), in order for any sensible confidence limits to be set, those proxies must substantially agree on some temperature range in which they respond approximately the same way.
But, if I’m following the argument correctly (so feel free to jump in here if I’m missed the point), the analysis of the individual proxies show that most of them have no correlation even with themselves and temperature, and of the remainder, their supposed temperature ranges of validity practically don’t intersect. This is turn means that the more of these inconsistent proxies added, the less significant the claimed results because the confidence limits blow up.
So Mann could have used “a few good men” but he wouldn’t have got anything like global coverage. But by using a larger number of proxies he made the result meaningless because the temperatures could have been from an Ice Age to the surface of Venus and his method would never have known one way or another.
Close? Or shall I shut up and go away?
Hu and others,
about two years, I did some interesting experiments on trying different methods on the very “tame” von Storch-Zorita network of pseudoproxies (uniform white noise additions to model output). One of the cases was multiple inverse regression (X on Y) – which is a technique that was used as long ago as 1979 by Groveman and Landsberg in one of the very first studies of this sort.
Regardless of what one may or may not expect, multiple inverse (X on Y) regression performed worse than other candidate methods in a tame situation. In the tame situation with uniform white noise aditions, the best solutions have more or less equal coefficients, whereas X on Y OLS sometimes flips the series upside down and ends up with overfitting in the calibration period and inability to extract low-frequency variations. It was easily outperformed by methods such as a simple average plus scaling or principal components.
PSeudoproxy testing as carried out in typical studies (the von Storch comment on MM2005, Mann and Rutherford have done a couple) are on highly over-simplified networks with uniform noise additions.
Let’s grant for argument’s sake that the “proxies” really are a temperature signal plus noise, but a more realistic case is that you don’t know how much noise is in them. That’s one thing. But if you don’t KNOW the orientation of the series on a priori grounds, then I don’t think that you can permit the use of such a series into a network. For example, can someone say on a priori grounds whether they expect the contrast between the average of 3 central SWM series and the composite of 2 northern and 2 southern SWM series to have a positive or negative relationship to world temperature? Nope. ACtually, I’d be surprised if it had any relationship.
The Composite-PLus-Scaling methods are, in effect, a way of playing it a bit safe, ensuring that you at least get the orientation right – so that they are more “robust” -using “robust” as statisticians use it – than X on Y regression. Viewed purely as a signal processing problem given the assumption that the things actually are proxies, you should be able to do better than either OLS or CPS by doing some sort of constrained regression in which the sign of the relationship is constrained to be positive. I’m sure that there must be canned programs that do this; I meant to experiment with this at the time but never got around to it.
I did do some experiments on my own pseudoproxy networks in which I did principal components on networks with one “signal” and non-uniform noise additions (heteroskedastic). The coefficients of the 2nd eigenvector directly tied into the proportion of noise, so there’s an easy way of making a better estimate under such circumstances than either X on Y regression or CPS.
Of course, none of this interesting multivariate analysis deals with the gorilla in the room – whether the Graybill chronologies are uniquely able to detect world temperature. People in the Mann, Rutherford, Ammann, Nychka camp all prefer to deflect the discussion into multivariate thickets where people can only follow with difficulty and avoid discussion of whether there’s any validity to the proxy network itself.
RE 30, 33, Sequential state-space modeling of temperature is somewhat complicated by the great uncertainty of the “hyperparameters” (the regression coefficients and the signal and noise variances), but with a little computer simulation this is not a real problem.
Taking any hypothetical values of the hyperparameters as given, the filter and smoother densities for temperature are Gaussian and can be found by a standard Kalman Filter, provided the underlying shocks are Gaussian.
But in fact, the regression coefficients are uncertain. Given the noise variance, they are Gaussian with standard covariance matrix. The OLS noise variance is chi-squared (in the uniproxy case, but still manageable in the multiproxy case), so drawing a variance first from this distribution and then a set of regression coefficients with this variance gives the regression coefficients their MV Student t distribution. The signal variance can simply be drawn from its independent chi-square distribution.
So simply draw say 10,000 sets of hyperparameters, and then run the KF and smoother with each set as they were true, numerically integrating the density for each point in time as you go. The result will be a heavy-tailed and skewed distribution for past temperature, but which efficiently takes adjacent proxy values into account. (The filter just takes adjacent values on one side into account — in this case the future. The smoother, which looks in both directions, is probably more relevant.)
This might take overnight to run, but we all have to sleep sometime!
This sort of simulation is no more difficult than what Li, Nychka and Ammann did (see recent CA thread), except that it would correctly model the proxies as responding to temperature rather than temperature as being proxy-driven, as they did.
Even CO2 and its uncertainty could easily be included in the estimation.
Steve (#42)
I think inability to extract low-frequency variations is due to the ICE (temperature on proxies) assumptions. ICE is correct practice when (X,Y), i.e. temperature and proxies are jointly multivariate normal. Now, if you observe Y alone, it should be non-autocorrelated sequence. If it isn’t, you are breaking the rules. You should use CCE, and ICE is a matrix weighted average between CCE and zero-matrix ( http://www.climateaudit.org/?p=2445 ). You are weighting the correct estimate towards zero. That leads to inability to extract low-frequency variations. If ICE assumptions hold, there are no such low-frequency variations ( just plain white noise ).
Mann vs. von Storch is very interesting story. If I got it correctly it goes like this:
1) Mann does Y on X
2) von Storch does X on Y and criticizes Mann’s method, as X on Y loses variance
3) Hand-waving starts from Mann’s side, but X on Y vs. Y on X issue is never mentioned.
#44. There’s a vast amount of hand-waving as I don’t think that any of the parties really understand what the methodologies are actually doing, let alone what the other party is doing. There’s nothing in their exchanges that rises much above a blog exchange.
However, there’s another VERY important nuance that gets lost in the X on Y versus Y on X discussion – and this goes to the Partial Least Squares point that I’ve been trying to articulate clearly.
The X on Y versus Y on X distinction gets substantially extinguished at the reconstruction stage. Mann’s Y on X ends up being a (Partial Least Squares) X on Y after the matrix algebra cancellation in the 1-D case. IF you have substantially uncorrelated proxies as in MBH, then the only difference between the coefficients in X on Y and (PLS) X on Y is the rotation by the matrix and for a substantially uncorrelated network, that matrix is “near” the identity matrix.
and for a substantially uncorrelated network, that matrix is “near” the identity matrix.
So some of von Storch’s comments end up being applicable, though his reasoning isn’t at all precise and his terminology is very unhelpful. And of course, the Mann/Ammann responses are little better than a squid emitting ink to make things incomprehensible. Here is a recent abstract that contains a helpful description applicable to Mann/Ammann ink releases:
Steve,
Agree. The exchange has some humoristic features. And journals like Science are involved in this. Fun to read, but the alarmist in me gets a bit worried. Where is science going..
Mann’s replies such as
are quite hilarious.
Some random notes (while trying to catch up with the main post)
For MBH99 AD1000 step, problematic proxies seem to be ( CIs over 10 deg C or complex roots, my implementation of Brown82 2.8)
fran010.txt
itrdb-namer-pc3.dat
npatagonia.dat
quelc1-accum.dat
quelc2-accum.dat
urals-new.dat
westgreen-o18.dat
morc014
Really inconsistent calibration results can be obtained by using Brown’s formulas with Juckes’ HCA proxy set (originally from Hegerl et al) . Univariate results look OK, but are in conflict with each other (except in the calibration period!), and thus Brown’s R gets really high values, and CIs go floor-to-ceiling ( see http://signals.auditblogs.com/2007/07/09/multivariate-calibration-ii/ )
Hu, #26,
With some exceptions, see http://www.climateaudit.org/?p=2955#comment-231229
Steve #29,
Brown’s 2.3. means that targets are standardized, not responses. Not sure if it just to make derivations easier, in Brown87 there’s no scaling of targets.
Re #26 last paragraph and Steve #29,
I still think there’s an inconsistency between your t of 1.71 for PC1 and the finite 95% CI reported in the post, whether Brown’s formula is used or the Draper and Smith version. The latter overlooks the fact that Y’ will contain an observation error in addition to the coefficient uncertainty, but it is the uncertainty of beta that makes the classical univariate CI blow up for confidence levels greater than the “significance level” (1 minus the p-value) of the slope coefficient.
I see now why your units in the millennial graph for PC2 were still in SD units — although the calibration in the preceding graph would permit translating it into dC, this translation is not necessary to see that there will be no HS, since both graphs have exactly the same shape, differing only in location and scale. I had assumed this was supposed to be the reconstruction, but in fact it is just PC2, which is adequate to make the point.
RE main post,
Do you mean the CO2 adjustment ( http://www.climateaudit.org/?p=2344#comment-159797 ) ? As Mann re-scales proxies with detrended std, this adjustment has insignificant effect to his verification (and calibration ) stats. But if stats are computed correctly, this adjustment has effect (in addition to making ‘astronomical cooling’ visible) – it makes CIs shorter because recon results will be closer to calibration mean.
Here’s IMO a nice example how Brown’s R works:
( http://signals.auditblogs.com/files/2008/05/hegerl_48.png )
I took two proxies from Juckes’ HCA set (mitrie_proxies_v01.csv, Northern Norway and Eastern Asia), calibrated them first separately to obtain CIs (yellow and red). Then I calibrated them together to obtain R (which is always zero in univariate case). When univariate CIs are in disagreement, R gets high values. Brown87:
Interestingly, Hegerl2006 is in the IPCC Fig. 6.10.c, where uncertainties (2*calibration residual std!!) are just overlapped, and conflict is not considered at all. But hey, .. 🙂
RE UC #50,
Very nice!
If this is the same as Sundberg’s 1999 “R”, it should be chi-square(q-p = 1) as calibration n becomes large. The 95% critical value is 3.84, but since you’re subtracting 3, this would leave 0.84.
There are several R’s above this value, but out of 1000 trials, there should on average be 50 false rejects at the 95% level. You probably have more than 50, but then the tests are not independent, since they all use the same calibration coefficients, so it’s not too clear how big an overall reject this is.
Isn’t there an F interpretation (at least approximately) to the Brown/Sundberg R stat? The calibration period is often far from infinite.
What kind of confidence intervals does Sundberg’s other term “Q” give? It doesn’t look like it would rule out an 11c MWP.
Hu,
167 values exceed 3.84. 18 is the largest value. To see how close chi-square(1) this should be, I think I need to walk to library for Fujikoshi & Nishi (1984) and Davis & Hayakawa (1987). R is large enough to make confidence interval empty, and I think it is a good indication that data doesn’t fit the model. Here’s what I think:
Model fits well in the calibration period, but not elsewhere ( cherry picking, spurious correlation ). Thus the residual covariance matrix will underestimate the true error covariance matrix, and these reconstructions based on subset of responses will be overconfident in accuracy, and we have a conflict.
If I’ll add Western USA (Hughes), for example, R will be very high in 11c as well.
Here’s another interesting R series, from MBH98 AD1600 step:
q=57, and p=4 (TPCs 1,2,11,15), so with large n we should have . This is clearly not the case, and thus assumptions
. This is clearly not the case, and thus assumptions  ,
,  are not valid.
are not valid.
One Trackback
[…] a post a few months ago, I discussed MBH99 proxies (and similar points will doubtless apply to the other overlapping series) from the […]