One of the issues in play in criticisms of Douglass et al 2007 pertained to their use of RAOBCORE 1.2 rather than RAOBCORE 1.4.
As an editorial comment, since some critics of Climate Audit seem to feel that I bear some personal responsibility for defending this paper, I was not a co-author of Douglass et al nor I did not provide advice on it. I had not posted on it or reviewed it or even read it until a few days ago. Nor did I have any personal familiarity with radiosonde data sets. Nor had I followed the realclimate discussion of this article until a few days ago. I posted up a few days ago on tropical troposphere temperatures because of Ross McKitrick’s T3 concept and I merely did a simple plot of tropical troposphere temperature.
My proximate interest in this paper arose because this post prompted commentary on Douglass et al., including a statistical issue, previously raised by Gavin Schmidt (which I had not followed at the time), which was raised here by Beaker, which caught my interest. The idea of a climate scientist making a gross statistical error is something that would obviously not come as a total surprise to me, though I remain unconvinced that the particular issue advanced by Schmidt and endorsed by Beaker, concerning multi-model means, rises much above a play on words. In fact, my impression is it is more likely that Schmidt has committed the error, by confusing the real world with the output of a model, something that anthropologists have observed as something of an occupational hazard for climate modelers. (See discussion of Truth Machines here.)
The issues concerning radiosonde trends are more substantial, though Schmidt’s commentary is more oriented to proving a gotcha than a careful commentary on real issues pertaining to this data.
RAOBCORE is a re-analysis of radiosonde data by Leopold Haimberger and associates. RAOBCORE 1.2 was published in April 2007, though presumably available in preprint prior to that. Douglass et al 2007 was submitted in May 2007, when the ink was barely dry on the publication of RAOBCORE 1.2. Nonetheless, Schmidt excoriates Douglass et al for using RAOBCORE 1.2.
To date, RAOBCORE 1.4 has not been published in a peer-reviewed journal, though a discussion has been submitted (Haimberger et al 2008) and is currently online at Haimberger’s site. It was announced in Jan 2007 with Haimberger’s website stating that it used the “more conservative ERA-40 bg modification”. “Conservative”. I must say that I dislike the use of such adjectives by climate scientists. Dendros talk about “conservative” standardization, never about “liberal” standardization. Another adjective that sets my teeth on edge is “rigorous” as in a “rigorous statistical procedure”. Inevitably, such procedures are anything but.
RAOBCORE 1.4 data is online in a MSU gridded format at ftp://raobcore:empty@srvx6.img.univie.ac.at/v1_4/grid2.5_invd_1_6, with 24 different data sets covering combinations of 4 layers: tls=Lower Stratosphere (MSU4), tts=Troposphere-Stratosphere (MSU3), tmt=Mid-Troposphere (MSU2), tlt=Lower Troposphere; 3 versions: bg, tm and tmcorr; and two times: midnight (00) and noon (12). I’ve written a short program to extract this data and have made monthly time series for the tropics for all versions.
The underlying concept of the RAOBCORE re-analysis is to apply changepoint algorithms to detect inhomogeneities in the radiosonde record and there seems to be plenty of evidence that inhomogeneities are a real problem. So CA readers that are concerned about inhomogeneities in the surface record should not take the radiosonde record as written in stone, merely because they like the answer. Uncertainties in this record seem just as serious, if not more serious than uncertainties in the surface record.
I’ve done a quick assessment of the data, which has primarily involved figuring out how to download the data (which only goes to end 2006) and plotting the net adjustments in RAOBCORE 1.4 to the original data. (I haven’t located RAOBCORE 1.2 online yet.)
The difficulty that arises is that the recommended adjustments are typically of the same order of magnitude as the underlying trend and, in one case, larger than the underlying trend, such that the sign of the adjusted trend is different from the raw trend. First here is a figure showing the net adjustments for the tropics in deg C for the 4 levels (going high to low). In each case, the adjustments are implemented primarily in the 1985-2000 period, so one is not dealing with the far past. All records end in 2006 are not fully up-to-date.
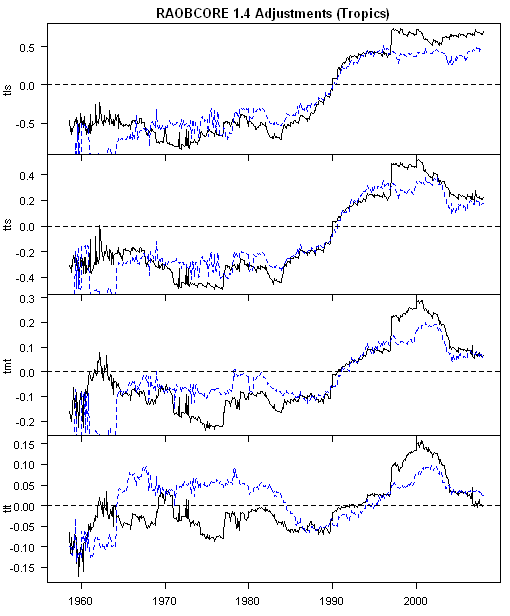
Figure 1. RAOBCORE (tropics) adjustments for 4 levels 1957-2006. Black – midnight; blue- noon.
Next here is a figure showing the original and RAOBCORE 1.4 trends for the tropics for the 4 levels (version 1.2 is not shown). The sign in the MSU3 level is reversed by the adjustment process.
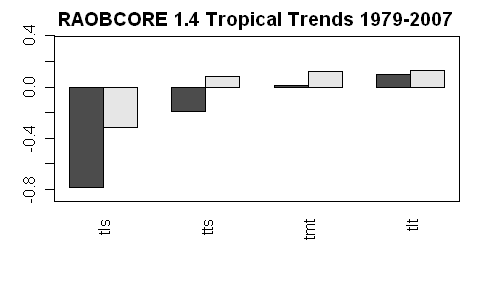
For completeness, here are plots showing the original and adjusted versions for the 4 levels.

It is evident from the above plots that the RAOBCORE adjustments are the same order of magnitude as the trend that people are seeking to determine.
Reference:
Haimberger L., 2007: Homogenization of Radiosonde Temperature Time Series Using Innovation Statistics. J. Climate, 20,1377- 1403 (April 2007) url





51 Comments
Steve there has been a discussion about this paper between Douglass and Schmidt that might interest you if you didn’t know of it:
David Douglas star posting at number 79
http://wmbriggs.com/blog/2008/04/08/why-multiple-climate-model-agreement-is-not-that-exciting/
Adjustment appears to the elixir of Climate Science.
3
I have to confess that I am very skeptical of ex post facto adjustments of experimental data.
They were never used in my considerable experience as a research scientist. If somebody screwed up (Note: careful experimentation is important in science), they would either print an errata or someone else would publish a paper with new data and an argument as to why it is better.
These adjustments smell more like attempts to remedy a theoretical-fit problem than a genuine need, but I’m a skeptic. If they are genuine, it suggests climate scientists are very careless with their measurement planning, instrumentation, and/or set-up.
I’m with you Pat,
Either your data is good or it is bad.
If you are confident in your experimental procedure and methodology you state the level of accuracy and uncertainty in the data and propagate it through the calculations.
If at some point in the process you loose confidence in the data, due to either systematic or procedural errors, you start over. You don’t retroactively “adjust it” to fit your hypothesis.
RE 3 Yup. You collect your data. If you determine you have a data collection error, you fix
the instruments, you collect more data. Conclusions are delayed, programs are put on hold.
people get fired or reassigned to high school science liason.
The other option is challenger go with throttle up.
The Supreme Court is not sympathetic to cruel and unusual punishment.
Douglass at this link says the following about the choice of radiosonde verions:
Also here is what Gavin explains in the same thread about the use of SE and I think demonstrates beyond the pale that he does not understand how the SE is used. In, for example, a control chart one wants to determine whether the process is meeting a target and is set up to measure several samples that are averaged and the SE is used to determine whether that average falls within the limits for the target. He doesn’t get the concept that SE is used with a target and/or estimation of the true mean.
Finally I believe one of the posters at the thread linked above noted that the Douglas comparison using UAH data would have found the model average and standard error limits outside the observed UAH data.
It’s important to note that radiosondes are meteorological instruments historically built to gather meteorological-quality data, which is generally coarser than what climatologists need. The attempts to refine the upper-air data are in a sense like trying to pretty up a pig.
A sense of the problems, and methodology, can be gathered from papers linked here . Be prepared for comments like this:
and this
RE 6. pat. I will never forget the time a manager of defensive electronics got assigned to the high school liason program. The General came in for the review. and this guy danced around a particular “inconsistency” between the model and the data. Half way through his presentation, the
general turned to our management and said. “He is finished.get him off the stage” The poor guy kept talking, and finaly was convinced to take his seat. next month he was assigned to the high school liason program, as detailed in the company newsletter with all the nice photos. Thereafter, he retired, growing weary of the sweaty and ignorant youth.
9
Did he appeal to the CA(?) Supreme Court, based on the cruel and unusual clause?
We had an off-site presentation which the technical part of the team didn’t get there due to fog. One of the Sales guys had a copy of the slides and did his best. At one point, the customer asked “Is that to 1 sigma or 2 sigma?”. The sales guy responded “Which would you prefer?”.
I am curious about the relationship between error bars and data adjustments. If one establishes that there are issues with the data and you correct the data shouldn’t the error bars on the corrected data be widened to reflex the uncertainty associated with the adjustment?
IOW – Adding 0.5 degC adjustment to data should result in error bars that are at least 0.5 degC.
Does this make sense?
8 David
It’s hard to understand why the need for “homogenization”, especially when the whole point was to measure trends.
A well-planned and managed program would retain the same instrumentation for all measurements, so comparisons can be usefully made. In the infrequent event when switching instrumentation was necessary, the new version would be fully calibrated against the old version before making the switch.
These precautions are so obvious and elementary that one has to wonder about the competence of the people involved. But perhaps I don’t understand all the constraints involved…….
Pat, I think that their practices have improved and probably will provide good data going forward. Part of the historical problem is that different countries used different instrumentation and practiced different levels of care in processing the data. I seem to recall reading that data from some places is suspected to include falsified values (basically they never launched the instruments or launched at times other than those recorded). It’s a mess.
It has been highlighted in other threads, but how does this article square with the current discussion?
http://climatesci.org/2008/01/01/important-new-paper-using-limited-time-period-trends-as-a-means-to-determine-attribution-of-discrepancies-in-microwave-sounding-unit-derived-tropospheric-temperature-time-by-rmrandall-and-bm-herman/
As a payload sytems engineer for a major satellite manufacturer, I have played these data adjustment games in the past. However, it is only under one circumstance – the satellite is in orbit, it is malfunctioning, and during t-shooting we find the factory test data is inadequate or compromised. We can’t get the satellite back and we don’t have good data but we have to figure out something to keep our product operational.
In other words, we are desperate because we very well could lose hundreds of millions of dollars. I have a feeling the motivation of the climate science community is similar.
There is a tale of an error in the measured data regarding a rather important instrument. It seems that the data showed an error in the finish of a certain part. The technician that made the measurement was quite sure that the finished part was correct and the measurement device in error. So, he put a 5 cent washer in the measuring device which caused the measurement that he took to be consistent with what he knew was the state of the part being measured. The part was then stamped as quality assured and then the was integrated into the overall system. This system was then fully signed off on and shipped to the customer. When the system was launched and put on orbit, the scientists noticed a blurring of the optics. It seemed that the primary mirror was ground just slightly out of specification, a problem later traced to a flaw in the measuring device at Perkin Elmer. It cost NASA another billion dollars to fabricate an optical corrector for what you now have figured out is the Hubble space telescope.
This is what happens when people know that their preconceived notion is right and the instruments wrong.
And of course, during the post-mortem there will be a full failure review board convened with independent, external reviewers. Next time it will be done right without the need for firefighting heroics.
It would be much easier to forget about instruments alltogether and simply create the data as needed. This would avoid the problem of collecting data which was not in agreement with the researchers’ pre-conceived notions of what the data should look like. This would also save the problem of erasing the original data.
Douglass mentioned here:
http://www.climateaudit.org/?p=3058
An addendum to their paper which I have located here:
http://www.pas.rochester.edu/~douglass/papers/addendum_A%20comparison%20of%20tropical%20temperature%20trends%20with%20model_JOC1651%20s1-ln377204795844769-1939656818Hwf-88582685IdV9487614093772047PDF_HI0001
14 (JM): Actually, this is just to anybody: that link doesn’t work for me (indeed, I can’t get to Roger’s site period!) how about anybody else?
Steve, what about journal paper both on Douglas analysis and Raobcore adjustment?
The Douglass paper can be downloaded from:
Click to access DOUGLASPAPER.pdf
In 50+ years of dealing with cranky measuring instruments and trying to find the real data among the noise, I observed that error direction was random and unpredictable. How then is it that all the climate science “adjustments” are in the same direction, indicating that all this varied instrumentation erred in the same (opposite) direction?
And, I read the UAH post Andrew kindly provided in another thread about the adjustments of the satellite data. Therein was a description of the calibration routine. Now, the satellite derives temperature by looking at the frequency of microwave emission of the Oxygen molecule which is temperature dependent. But, calibration is by aiming at outer space (no Oxygen, temp = ?) and an internal black panel (no Oxygen, temp = ?). Really? Did I read the paper too fast?
Anyway, I now understand why all this weather data is subject to corrections. Dennis’ reminder above about the Hubble telescope fiasco is appropriate in more ways than just one. All these are NASA programs, with about the same level of credibility.
2, 3, 18, 23
Should data never be subject to revision/correction? Interesting dilemma for those bemoaning adjustments a priori yet calling for same in other areas. Quite similar to the phenomenon of slagging climate models in reference to longterm projections of mean temp increase while citing some of the same if they produce superficially agreeable to anti-AGW results on shorter timescales or other metrics.
All data are subject to revision. Isn’t indeed the premise of this blog dedicated to such?
Steve: Please lay off the editorializing. I think that I made a quite reasonable observation in the post that people who are concerned about inhomogeneities in the surface record can hardly cavil at the possibility of inhomogeneities in the radiosonde record merely because they like the results. I would characterize my own viewpoint on adjustments to data as this: if the size of the adjustments is equal to the size of the trend, then the adjustments need to be comprehensively documented and examined carefully. Not that “all data are subject to revision”. Indeed, if data is revised, it needs to be carefully marked and the original data preserved so that subsequent people can analyze the adjustment process. This means that the adjustment code needs to be published, not just loose sketches. It means that new adjustments need to be announced and their effect analyzed – unlike what Hansen did last September. I don’t view any of the radiosonde data as showing very much. Indeed, a real concern, one expressed by some posters, is whether the potential of this data set for monitoring changes has been botched by unrecorded inhomogeneities. The disquieting thing about the inhomogeneity adjustments in RAOBCORE is that so many have occurred during the IPCC period, when climate change issues were on the radar screen and care to ensure instrumentation continuity should have been on the minds of climate scientists.
15 Jeff
I can understand that. But the fact that this equipment is so expensive should mean that there is extra effort to make sure the instrument is properly calibrated before use.
Isn’t there any data from balloons and well-calibrated conventional thermometry?
25 Jon
If the data are bad, they should be replaced by new data, not “adjusted”. “Adjustment” is too prone to personal bias, already an issue in science even with unadjusted data.
#11 Raven, In theory, yes. Calibrations have error in them and adjustments increase error. In practice, nobody actually does anything about this.
@25
My comments were directed at specific posts for a reason. How can you find my post objectionable while countless comments implicitly or explicitly accusing scientists of outright fraud go untouched? Interesting choice of moderation.
Steve: I’ve made it clear that such accusations of “fraud” are against blog rules and, far from leaving such posts “untouched”, I make a practice of deleting such posts. In the earlier days of the blog, I made a point of not deleting anything, but I changed that policy and will enforce these rules. You say that there are “countless” posts “explicitly” accusing scientists of “outright fraud”. Such accusations are against the policies here. I would appreciate it if you would identify even a few of the posts or comments in question so that I can attend to them. If there are “countless” such posts, it should be easy to find a few of them.
Some other usages of “inconsistent” in IPCC AR4 chapter 9″
CCSP uses the term “discrepancies” on some occasions where IPCC (and Douglass) used “inconsistent”, commenting on the precise issue in question here:
Off the top of my head, bender at 363 in the tropical troposphere thread. The allusion to 1984 speaks for itself. Post 2 in this thread is fairly obvious.
Of course I could be mistaken. All of these posts could implying something other than scientific misconduct. All of the disparaging comments about Mann, Schmidt, Hansen, the IPCC, and the wider community are in no way to be interpreted as implications of misconduct?
None of your examples are “explicit” accusations of fraud. I don’t see that the comment in #2 comes anywhere close to making such a statement. The 1984 quotation didn’t contain an “explicit” accusation of fraud, but is a type of venting that I ask people not to do and I’ve exercised moderation rights to delete it. Bender’s 363 is certainly not an explicit accusation of fraud, but is perhaps venting and snippable under blog rules. But none of these are “countless” “explicit” accusations of “fraud”. Indeed, the word does not occur in the posts. You’ll have to do better than this to support your accusation.
The only person to recently make an explicit allegation of fraud on this board was Phil against a skeptic (which I’ve deleted.)
One can make critical comments, even “disparage” people without that necessarily implying “misconduct” or even “fraud”. I make a point of avoiding the imputation of motives as much as possible. We observed, for example, that Mann withheld adverse verification r2 results. I intentionally did not apply any labels to this. I merely reported the facts. If the facts are unpleasant, then that’s the fault of the author, not mine.
I’ve said on a number of occasions that “misconduct” and “fraud” are quite different things and no purpose is served by conflating the two as you are doing here. Yes, I filed an academic misconduct complaint against Caspar Ammann. Or Ammann and Wahl issuing a press release stating that all our results were “unfounded” when their calculations of the verification statistics in the Table in MM2005a (reported only after the academic misconduct complaint) proved to be virtually identical to ours? Is this a practice that you endorse?
#30
Excuse me??!! You’ll have to defend or retract that statement, my friend. I suggest retracting it. I have never accused anyone of what you say I did. Not in #363, not anywhere.
snip – bender, calm down.
I said explicit or implicit and bender’s comment is on the explicit side. Please explain to me how the 1984 allusion could be construed as anything other than a deliberate implication of misconduct.
I wasn’t referring to your personal posts or other actions. I think that you have a good opportunity here to contribute positively and your conversations with Curry lead me to believe you are ultimately going to follow that route. I have no problem with you bringing as much scrutiny to bear on any aspect of the science you wish to.
Jon says:
Have you heard of the term ‘confirmation bias’? It is a trap that even the most diligent scientist can fall into. Scientists should be skeptical and always ask themselves whether they are trying to impose their beliefs on the data instead of allowing the data to tell them what their beliefs should be.
The potential for confirmation bias is painfully obvious to those not involved in the process. Especially when we see dataset after dataset being revised in ways that always preserve the original hypotheses. Such lopsided adjustments are not proof that the climate science community has a big problem with confirmation bias but it does raise enough suspicions to justify a concern.
For this reason, the climate science community has an obligation to confront the issue confirmation bias directly on and demonstrate to the wider community that their methods are sound. This requires full disclosure of the adjustment algorithms in a way that allows others to verify that they can come up with the same numbers. It also means that errors must always be reported with the data lest people get the impression that the data is more certain than it is.
Failing to address the issue of confirmation bias will result in accusations of fraud. If people in the climate science community don’t like those accusations then they should address the legimate concerns regarding confimation bias directly and honestly. Expressions of outrage and insistence of infallibility will only increase suspicion.
Incidently, I have no reason to believe that corporate executives regularily engage in fraud when it comes to reporting their results. However, I would never accept their word alone and would never consider investing in a company that refused to have their financial numbers audited (assuming that was an option). I see no difference between investing in a stock based on financial data and making massive public investments based on scientific data. The same standards of external audit and review must apply to both.
Is anyone here as amazed and somewhat perplexed as I am that Gavin Schmidt does not appreciate the statistical tool using the standard error of the mean, SEM, to compare averages or an average with true mean estimate of it or a target value? Should not it be obvious that if one were comparing a twenty third climate model to the previous 22 models one would use the standard deviation and not the standard error of the mean to determine whether that twenty third model was outside the distribution of the previous twenty two. On the other hand, should it not be just as obvious that if one is comparing the mean of twenty models to a target value or in this case the instrumental results one would use the standard error of the mean, SEM.
Take an alternate case where one group of climate models results were to be compared to another group of models let us say because of a difference in methodology between the groups. The averages of the two groups would be compared by taking the number of samples used to determine of the averages of the two groups into consideration in calculating a standard deviation (SEM like). What is so difficult for Gavin Schmidt to understand about that. We could argue separately that climate models do not fit well for such a statistical test, but that is not what Gavin Schmidt is arguing.
I noticed on rereading the Douglas paper that the authors commented about other papers (one coauthored by Karl) that used the range of the climate models in comparing model output to observed data and apparently some of these models had outliers that did not realistically reproduce the surface temperature trends. So I guess that these papers set the precedent for a certain group of climate scientists to throw together an array of climate models, measure the range regardless of obvious outliers and then treat the observed data as just another model result. I think fatal errors would be appropriately used to describe that approach.
At Matt Briggs’ blog, Gavin Schmidt accused Douglass et al of having received v1.4 data and not reporting it:
Douglass denied that they had been sent v1.4 data:
He added the following:
Jon said:
“I would characterize my own viewpoint on adjustments to data as this: if the size of the adjustments is equal to the size of the trend, then the adjustments need to be comprehensively documented and examined carefully.”
Hi Jon,
I would suggest that if the adjustments are anywhere near the same size as the trend, you need a better measurement system. There’s a lot of statistical process control literature available (for manufacturing) that outlines this kind of thing and the magnitude of errors that can be tolerated. I’ve been through a lot of the training and enough process reviews to know this wouldn’t fly if you were manufacturing widgets. It’s difficult to understand why it should be adequate for something as important as this.
From my experience, uncontrolled variation is significantly influencing the measured data. It is remarkably risky to assume (and highly unlikely that) the data can adequately be corrected for errors of the magnitude representd. I cannot think of any good examples in engineering where we would accept this level of error in the measurement system vs. the trend. My analyst would tell me the measurement system couldn’t be trusted and not to draw any conclusions before improving the measurement system.
Gerry
#24,
Of course data can/should be subject to revision when it is shown to be wrong. However, there is a responsibility that goes along with those revisions. Namely, you can’t adjust the data silently, then excoriate someone who publishes a paper based on data that was previously published and then silently updated, which seems to happen a lot.
Even part of the blog entry from Steve mentions this in an alternate fashion…
Another case in point was a recent thread about a paper published by Rob Wilson et al, where he used data provided directly to him and Steve used a version from the ITRB database. There were differences between the two, leading to different results.
These are major issues in climate science, and have been discussed repeatedly on so many threads you can’t even keep track anymore.
As Steve pointed out in #31 above
In the stock market, pharmaceutical world, mining, etc., withholding adverse results could lead to [snip] even when they make statements like this…
snip
I think it is important to notice the relative openness of the adjustment processes used for and discussions about the radiosondes temperature data sets as compared to the counterparts in surface data sets. One should also be keenly aware of the homogeneity adjustments being made and why they are made.
Firstly for the surface record homogeneity adjustments are made on a station basis that would affect only a small part of the total data set while those, as I see them, made for the radiosondes would have a larger effect on the total data set.
The major issue in either case is making a homogeneity adjustment based on a coinciding change in instrumentation or methodology or making them based simply on finding statically significant break or change points in the time series. I believe the intent of the latest version of GHCN was to look at the time series by station for any break points and make more or less automatic adjustments. We know there are breakpoints in the combined surface temperature series and that the station by station approach for homogeneity adjustment to the total series would obviously negate what are probably real break points. There are probably then real break points in the station data that may not be discriminated in the newer approach for homogeneity adjustment.
As I recall the homogeneity adjustments for the radiosonde series were made based on break points and corroborating evidence that a coinciding change was made and in light of whether it made physical sense. Regardless it is these criteria that I think should be discussed in this thread along with a follow up analysis of the reasons given by Douglas for not using the most currently corrected radiosonde data set. It should be much less difficult than doing the analysis for the surface data sets.
Re #39: Jonathan Schafer: Re your last quote. I am starting to collect statements like that where influential AGW advocates argue the need to exaggerate the problems so that the public can be mobilised. I have examples from Stephen Schneider and Al Gore. Can you please attribute that quote. Thank you.
Jon @24
the use of “outlier” models by deniers to support the NO WARMING meme is more to irritate people like Gavin than to imply the SKILL shown by those particular models. There is no argument they will accept to get across to them that they simply do NOT have enough understanding of this extremely complex system to allow their work to be used for policy, or anything other than continued research. Using their own tools against them becomes a desperation move in irony. If the models are so loosely built that they can validate everything from no warming to catastrophic warming, what is the value??
Even if the modelers could have one model do “runs” that reasonably matched temps across the globe and elevations, it still would not PROVE they have the values and signs attributed to the correct components of the system.
The fact that the modelers trade on the idea that a particular model is able to show one segment of the climate reasonably totally mystifies me. What it shows is that the values and/or signs are misapplied and that they can “tune” the model to replicate a known phenomenon. This actually falsifies the model as a whole!!
#41
An interview with accidental movie star Al Gore
Steve, this maybe nitpicking, but I think it is important to maintain the most moderate language possible in discussing disagreements between scientists (whether they deserve it or not). I don’t think it is reasonable to describe Gavin’s criticism regarding RAOBCORE 1.4 as excoriation (“verbal flaying”, “scathing criticism, invective”) as far as I can see he made the criticism in very moderate terms in the RC article on the Douglass post.
However, if Douglass et al were not given the RAOBCORE 1.4 data and were unaware of it (if they knew of data that might be in better agreement with the models they were duty bound in my opinion to obtain it and include it in the analysis, with whatever caveats they see fit), then the criticsm is invalid in the first place, and should be withdrawn (with an appolgy for the misunderstanding).
BTW, I would not consider you as having any personal responsibility to defend any paper (other than your own). The impartial and impersonal nature of auditing (including CA) is one of its great strengths!
beaker, re #44
most readers of this blog will agree that moderate language is to be preferred. You should also be aware that this blog is an oasis of moderation compared to what goes on elsewhere.
For example, on William Briggs blog, Gavin directly accused Douglass of deliberately ignoring data that “did not support their thesis”, an unmistakeable allegation of scientific dishonesty. When challenged on this and asked to apologise, his response in essence was ‘who me? I have no opinion’. The important thing about this was that it came from one of the leading lights of the debate, one of the ‘tone setters’.
In this case, ‘excoriation’ is a perfectly appropriate term to describe Gavin’s attack.
Commenters like jon expect, and generally receive, a fair and courteous hearing on this blog, then go onto other blogs and describe people here in the most contemptuous terms.
Last year, when this blog was nominated for Best Science Blog, pro-AGW commenters on competing sites repeatedly used the foulest language imaginable to descibe this blog and the people who comment here.
In my opinion, while ‘immoderation’ comes from both sides of the debate, it comes predominantly from one side not the other.
Steve McIntyre should be congratulated for maintaining a decent tone on his blog; unfortunately the evidence from the Web is that this is very difficult to do.
“Excoriate” – to denounce or berate severely.
Gavin states that Douglass et al have a “lack of appreciation of short term statistics”. He called the paper “fundamentally flawed”. He alleged that the authors made an elementary statistical error (which they ironically purported to illustrate by expanding the error bars on the models – a step that I understand you to agree is itself incorrect.)
They stated at realclimate:
and again at Briggs:
After Douglass denied receiving this data, Schmidt repeated the allegation in even more strident terms:
Douglass again denied receiving the data and requested an apology. Schmidt did not apologize. Nor did he even mention at realclimate, where he had also made this allegation, that Douglass had denied receiving the data.
In Douglass’ shoes, I would regard the exchange as a very severe denunciation. If Douglass’ claim not to have received the other data version is true (and I don’t know who’s right and who’s wrong), then I would sympathize with him being angry.
Beaker (44):
Douglass explains why 1.2 was chosen in the addendum that Andrew provides a link for in post 19.
A small note on systematic versus statistical errors:
In high energy physics, where my experience lies, we always display statistical and systematic errors separately, in a row, as for example: 5.3 +/- 0.2 stat. +0.5 -0.2 systematic. It is understood that these errors cannot be combined and treated as one statistical error. If combined they are added linearly.
Perusing all these climatology model outputs my strong feeling is that if this methodology were used, the errors would make the models’ projections meaningless, what with all this post and meta adjustments to data.
Steve, sorry I didn’t realise that more strident criticism had been made elsewhere.
I am not going to post on the science issues or what trend is “right” here but I do want to strongly correct a factual error.
Radiosonde measurements have never ever been made for climate. Period. Full stop. End of discussion. Climate does not have an observing budget and no measurements are actually made FOR climate – we just use measurements that were made for forecasting.
Worse still in the case of radiosondes they are expendable instruments (wave goodbye at launch). Therefore each measurement is made by a different individual instrument. Worse still the models changed from the 1950s when they were several kgs and roughly 50cm diameter pieces that wouldn’t look out of place in a sci-fi flick. Nowadays I can hold the sonde comfortably in one hand and it weighs of the order 100g. That’s not all – ground equipment changes, changes in observer, changes in processing algorithm … do I really need to continue?
Anyone who wants to therefore seriously question the need to homogenise these records and then with a straight face argue that the surface record (which is imperfect but at least has instruments that remain in place and can be checked) needs adjustments has clearly missed their calling and should be standing for political office.
“Either your data is good or it is bad.”
Douglass et al obviously think the radiosonde data is not too good, otherwise they would not have incorporated the adjusted data from RAOBCORE in their own paper.