 Earlier this year I did a post on the amount of estimation done to the GHCN temperature record by GISS before generating zonal and global averages. A graphic I posted compared the amount of real temperature data with the amount of estimation over time. To read the graphic, consider 2000 as an example. As of February 7, 2008 there were 3159 station records in the GHCN data with an entry for the year 2000. Of those station records, 62% were complete and an annual average could be fully calculated. Another 29% were incomplete, but contained enough monthly data that the GISS estimation method kicked in. The final 9% were so incomplete that no estimation could be done.
Earlier this year I did a post on the amount of estimation done to the GHCN temperature record by GISS before generating zonal and global averages. A graphic I posted compared the amount of real temperature data with the amount of estimation over time. To read the graphic, consider 2000 as an example. As of February 7, 2008 there were 3159 station records in the GHCN data with an entry for the year 2000. Of those station records, 62% were complete and an annual average could be fully calculated. Another 29% were incomplete, but contained enough monthly data that the GISS estimation method kicked in. The final 9% were so incomplete that no estimation could be done.
What I did not explore at the time and would like to look more closely here is the accuracy of the estimation. One would hope with so much infilling going on that the accuracy would be rather high (I will leave the determination of “high accuracy” for a later time). Because I did not have real data to compare with the GISS estimations, I took another approach. I used the GISS method to estimate real temperature data as if that data were missing.
Recall that GISS never explicitly estimates missing monthly temperatures. What they do is estimate seasonal averages when one monthly temperature is missing but the other two are present. Similarly, an annual temperature can be estimated when one seasonal value is missing but the other three are present. Using this methodology GISS can estimate an annual temperature when as many as six monthly values are missing.
While no explicit monthly estimate is recorded by GISS, it certainly can be derived from the seasonal estimate. I have shown several times a one-line equation that exactly reproduces the GISS seasonal estimate. Leaving a subsequent derivation as an exercise for the reader, the implied monthly estimate can be found from that equation and is expressed as follows:
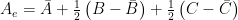
where the average values for A, B, and C are calculated from all valid entries for the given month in a particular station record.
Now to test the estimation accuracy. In Connecticut, December 2006 was warmer than normal, but February 2007 was colder than normal. Looking at the records for Hartford, CT, we see the following monthly and seasonal temperatures:
Dec 2006: 3.3
Jan 2007: -0.3
Feb 2007: -4.6
DJF: -0.5
If the December 2006 record were missing from Hartford, GISS would estimate a value of -0.7 C, which would yield a seasonal average of -1.9 C. Similarly, if February 2007 were missing, GISS would estimate it at 1.7 C and produce a seasonal average of 1.6 C. That’s a 4.0 degree miss for Dec, a 6.3 degree miss for February, and a 3.5 degree swing at the seasonal level.
The winter of 06-07 in Connecticut was a bit of an oddball. I really wanted to know what the typical error looked like. To do that, I performed the same calculation on all GHCN v2.mean records.
A real monthly value can be compared against its GISS estimate only when all three monthly values in the season are available. In my copy of GHCN v2.mean, there are approximately 6.25 million monthly values that meet that requirement. I went through each of the monthly values and simulated a GISS estimate, and from that estimate I subtracted the actual value to produce a delta temperature. A positive delta means that GISS would over-estimate the temperature and a negative delta means GISS would under-estimate the temperature.
Following is a histogram of the delta values collected. The x-axis is the value of the delta in degrees C. The y-axis is the percentage of records that had the specified delta value.
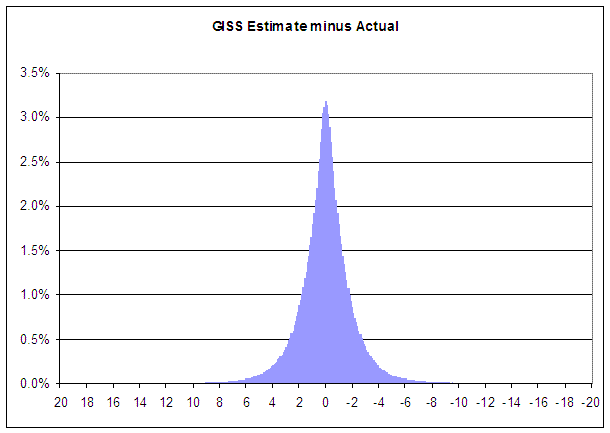
The fact that the simulation histogram looks like a normal distribution should not be surprising. This comes about because I need all three months in a season in order to simulate an estimate and a resulting delta. Recall that in the Hartford example above a large delta for December was followed by a similarly large delta for February, but of the opposite sign. Given the enormous sample size, the small differences in magnitude eventually even out.
The above distribution tells us the probability that the GISS estimate will miss the actual value by a specific amount. Zooming in on the distribution, we see GISS should get it exactly right just over 3% of the time:
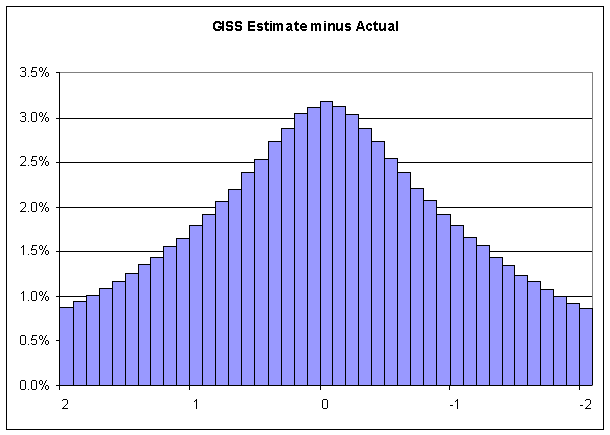
Following is a table of absolute values and their corresponding probabilities, through a delta value of 2.9 degrees:
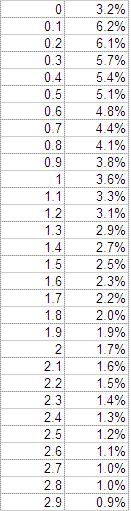
Referring to the table, the probability GISS will create an estimate within 0.4C of the actual value is 26.7%. A value between 0.5 C and 0.9 C has a 22.2% probability of occuring. Similarly, 1.0 C to 1.9 C is 26.5%, and 2.0 C to 2.9 C is 12.7%. There is about a 12% probability that the GISS estimate will be off by 3.0 C or more.





36 Comments
Does the shape of the histogram imply that there are no systematic biases, then, in one direction or the other, so that we have an unbiased estimator?
John,
I’ve been trying to figure out what data GHCN uses for Canada and the manipulations that happen to it before even NASA gets their hands on it. So far what I’ve got is that of 5258 Canadian stations that have daily data (ftp://ftp.ncdc.noaa.gov/pub/data/ghcn/daily/ghcnd-stations.txt), most of which are not current, somehow these are squeezed down (via Peterson and Rose) to 847 stations for the GHCN V2 monthly data (ftp://ftp.ncdc.noaa.gov/pub/data/ghcn/v2/v2.temperature.inv). Again a good chunk of the 847 are not up to date either.
Then GHCN monthly datasets are released as adjusted (which NOAA uses for its Global temperature figures via Smith and Reynolds) and un-adjusted which NASA uses via Hansen et al…
Am I getting close to reality??
The distribution plot is really interesting, and perhaps is worth a bit more contemplation. I wonder whether it is in fact “normal”, or whether it has a leptokurtic tendency. My reason for suspecting this is that it looks as if (from the zoomed in version) that the inflection points are remarkably close to the mean value compared with those for a normal curve.
If I’m right, what this might imply for the way in which the corrections are made I cannot suggest or even guess.
Just a thought.
Robin
You might plot cumulative probability, i.e., for an estimate to be off by less than (or greater than if you wish) x.
Unbiased estimators are nice and proper… but did the GISS algorithm factor in the variance from this estimation anywhere into measures of confidence?
Interesting. This analysis suggests that if missing values are randomly distributed, there would be no systemic error or bias. But I wonder if the actual missing values are random? While they certainly may be, as a social scientist I can think of a number of human reasons as well as some instrumental possibilities for temperature values not to get recorded for months that are extremely cold, and some, though fewer, possibilities for missing data from months that are extremely hot.
It would be extremely tedious, but I wonder about the possibility of cross checking stations with missing values against other stations in the same general region with that have recorded values, to see if there is any greater likelihood for data to go missing under certain types of temperature/weather regimes than others.
Most industries use NIST traceable standards:
http://www.nist.gov/
and use guage R&R:
http://www.sixsigmaspc.com/dictionary/RandR-repeatability-reproducibility.html
to insure measurements are done accurately. I guess it is too much to ask some government agencies to use the same methodologies as others. I guess it is beneath Hansen to even consider it? How can he announce XXXX year is the warmest in a milyon years with a straight face?
#1 Basil – The estimator is unbiased. You can actually see that as much from the equation as the graph.
#2 Fred – Funny you should bring up Canadian stations.
One of the things I did while debugging the program was look for really big negative or positive deltas, then go back to the original data to see if it made sense. In the process I ran across Mayo A in the Yukon (ID 40371965001). I simulated some very large deltas using this station data: -24.6, -21.2, +26.7, +21.5 to name but a few of the biggest values. In fact, this station owns the largest positive and negative simulated delta values in all of v2.mean.
In this case I think the problem is with the station data and not the estimation algorithm. The estimation algorithm’s lack of skill makes the station data problem more obvious.
Look at the temperatures for January 1981, January 1985. Those two values are what cause GISS to grossly over and underestimate the monthly values for the winter season in those two years.
Steve, perhaps a worthwhile exercise would be to examine a monthly frequency distribution of actual missing values… if, in actuality, there are twice as many missing March values as May values, then there will be a strong warming bias to the interpolation.
Personally, I think the most interesting point here is that there is a one in eight chance that GISS will be off over three degrees centigrade. That is a pretty big range of difference, combined with a significant probability chance. The GISS estimates are only twice as likely to be off a half degree. When the temperature variation tables are being graded by the tenth of a degree, if my variation based upon estimation is more likely to be off more than half a degree than within that half, the validity of the estimation is insufficient for use in my chart, statistically speaking. In good ol’ boy plain English, if the fish is bigger than the scale can measure, does it matter if it weighed one pound more than the scale could measure or ten?
#11 Keith,
Bingo. That is the point – the error can be quite large, and the probability it is over 1 degree C is greater than 50%.
Forgive my mathematical ignorance, but does this mean instead of smoothing, we could be amplifying swings (albeit in a unbiased manner)?
Should this be called Mr. Hansen’s Wild Ride?
Would it be fair to say that while climatologists need to use statistics to analyze their data (whether past or future climate projections) most (maybe all) of them simply aren’t very competent with statistics? It seems like the old saying about lies, damn lies and statistics applies way too often to data handling in “peer” reviewed papers that have considerable influence in policy making.
#9 Carl,
I don’t see any real evidence that the GISS estimation method would bias a month in one particular direction. What I do see is evidence that the uncertainty of the estimation varies greatly by month, with estimates for winter being far less certain than those for summer. Here is a table that should illustrate what I mean:
Values are in degrees C.
#14 That would be an extremely unfair overgeneralization. This blog focuses on finding errors and correcting them. It would be a serious mistake to judge a whole field based on a few dozen of the worst mistakes imaginable. That being said, there are some errors that do tend to be made over and over again by the same group of researchers. That group receives a lot of attention from Mr McIntyre because they have a proven track record of seeming to require greater scrutiny than other groups.
But don’t take my word for it. Read the Wegman report. If you are looking for general statements on statistical competency, that is probably the most authoritative skeptical voice you will find.
#15. Actually, didn’t you find a bias from this procedure in Step 2? As I recall, the introduction of the MCDW records in January led to a huge number of estimates for the prior December – estimates that were done stupidly and pointlessly using this method since in the mast majority of cases MCDW was a scribal variation of another series where the Dec record was available and, if an estimate were required to complete the MCDW quarter, there was a rational basis at hand, as opposed to the method actually used. Also, as I recall, because this estimate levered earlier estimates, a bias could not be eliminated out of hand, but needed to be examined.
Bender #16
Its the Wegman Report and Steve’s excellent reworking of so many influential papers that led me to say what I did in #14
#15 John
Just for completeness, could you determine how the values vary (if at all) by year?
Have I understood this correctly:
– For almost a third of the station records (29%) estimates are required and, more importantly, subsequently used.
– Approximately three quarters of these estimates are likely off by 0.5 degree C or more.
– And, using such large chunks if essentially random data, GISS calculates its temperature data with an accuracy of 0.01 degree?
A comment must have been deleted, so I am a bit out of synch here. I don’t think #15 bender is commenting on my #14!!!
#16 Steve – that is true that I found a small warming trend was introduced in Hansen Step 2 due to the application of the bias method, and that the estimation of December temperatures in the starting record seemed to be the culprit. In that case it looked like GISS underestimated that month more often than it overestimated it, and thus earlier records had to be cooled slightly when combining with the starting record.
By itself, though, I don’t see that the estimation method biases the temperature one way or the other, but it does make the result a lot less certain.
Re #19
1. With a large sample, the mean will not be affected.
2. The actual measurements are likely to be +/- 0.5 Degrees, so their SD will be around 0.3 Degrees. The corrections have a much larger SD of around 2 Degrees (I haven’t calculated it).
3. My conclusion is that the mean will not change, but using corrections increases the uncertainty of the mean.
I presume that the scientist making these corrections has calculated the increase in uncertainty, and published it in a peer reviewed paper. I wonder if anyone can direct me to that paper?
Re: #21
Well, suppose half of the measurements were valid, and the rest were estimated, in a similar (symmetric) manner.
Could we then happily say that the mean is not affected, nor the general validity of the conclusions?
Does it make any sense to state the monthly values with an accuracy of 0.01 degree?
John,
I found 54 stations with no data points missing 1906-2006. Calculated the standard deviation of the seasonal error when a selected month was missing at all stations. Comes out just over 1/3 of your monthly deviations.
Here is what I came up with.
Jan 1
Feb 1.01
Mar 0.88
Apr 0.67
May 0.73
Jun 0.51
Jul 0.42
Aug 0.47
Sep 0.63
Oct 0.66
Nov 0.71
Dec 1.05
Since they will estimate a missing season when calculating the yearly temperature, I suppose the yearly deviations would be proportionally smaller.
#23 Bob,
Nice.
I would agree in the case where exactly one month is missing in a given year, but remember that up to six months can be missing and GISS might still be able to estimate the yearly average. It does happen.
Also, as Steve alludes, December is the most frequently estimated month.
I’m starting to realize that what this blog is really about is statisticians in search of interesting problems.
Gunnar:
And a little respect for sound scientific practices!
Re: #9 Carl
Yes, I had the same thought with a different twist. There may be more likelyhood of missing data on cold/windy/stormy/snowed-in days than on a balmy winter days.
#19 Johan,
if we assume 1000 random estimateions with an error of 1 degree, and the error is randomly and normally distributed, the error in the average is:
individual error / sqrt(number measurements) = .03 degrees.
This won’t take into account any systematic errors/biases, such any tendancy for measurements to be more likely missing in snow storms etc.
If there is a systematic bias due to the ‘snow storm effect’, this may not effect the trend unless the bias changes over time. For instance if there are more or less snow storms now than 20 years ago, or if measurers today are more/less devoted and less/more likely to skip a measurement today in a snow storm than they were 20 years ago.
I think I can recall correctly that in the olden days we were taught
1. Do not assume that normal distribution statistics apply simply because a curve looks bell-shaped. Test the maths.
2. Aggregation of many observations will generally give a better precision estimate, but might say nothing about accuracy (bias) improvement.
3. Where possible, use standard units of measurement. Imagine that the ranges derived above could be anomalies versus a stipulated period, or Celcius, or degrees F, or degrees absolute. Each choice gives a different appearance to the plot.
Re the question of massaging of Canadian data before its is processed more. I have a paper “Updating Australia’s high-quality annual temperature dataset” by Paul Della-Marta, Dean Collins and Karl Braganza. Rec’d June 2003. Published Aust. Met. Mag. 53 (2004) 75-93. I have it in paper form only.
Some quotes: On UHI correction “Ultimately a subjective decision was made for each station as to whether it was likely to have been influenced by urbanisation.” Point of illustration – this procedure, repeated many times, might have evened out the plus and minus precision deviations, but it might have done nothing for bias).
On station quality “However, at present, the information in the database is only reliable since the mid to late 1990s” (GS: This might have improved since).
On this thread “Some records contain(ed) many years in which annual mean values were estimated by Torok and Nicholls (1996) using a reference series based on highly correlated neighbour series”.
It is unfair to cite these comments out of context, but one might see some similarity with the procedures of the thread above. At last inquiry, I was invited to go to the BOM library to read the PhD thesis of S.J. Torok 1996 from Melbourne University. I gained the impression that much Australian temperature data handling is based on this thesis.
It seems to me that one interesting question is why they do the monthly average with the other two months in the quarter instead of the two adjacent months even if one is out of the quarter. This is effectively linear interpolation and could clearly be extended if 2 or more months in sequence are missing their data.
Relatedly there is the question of what happens if you do the average that way?
I can see that this could reduce the variance of the data. I’d be very curious to know if it also changed the accuracy. [Perhaps I need to figure out how to get the GISS data into R and run the tests unfortunately I’ve yet to get R working for me]
#27: Yes, that is the case, but the metadata to determine weather on a daily basis is not readily available. Another idea which is a bit easier but still problematic due to poor metadata would be to look at missing values by measurement instrument (mercury, MMTS). I’d think that missing values would be happening for different reasons between these two, and that there might be a stronger bias in one group or the other.
How many of the Canadian stations switched from observer readings to Automatic Weather Observing Stations (AWOS) during the period of record?
Tim,
I have no idea (re AWOS stations). That info is not readily available on the Env. Can. website(http://www.msc-smc.ec.gc.ca/_toc/index_e.html) . However, I have noticed a few stations that have QC issues, e.g. daily temperature readings with a 0.5 C of resolution ie. readings of X.0 or X.5.
CA has discussed GHCN and Canadian stations, particularly Dawson, YT here:
http://www.climateaudit.org/?p=1538 & http://www.climateaudit.org/?p=2772
There are four Dawson YT sites in the Canadian data set, three of which are used in the GHCN station list:
CA002100400 64.05 -139.43 320 DAWSON
CA002100LRP 64.05 -139.13 370 DAWSON
CA002100402 64.05 -139.13 370 DAWSON A GSN 71966
2100400 daily data starts in 1897 and ends in 1979 (http://www.climate.weatheroffice.ec.gc.ca/climateData/dailydata_e.html?timeframe=2&Prov=CA&StationID=1534)
2100LRP daily data starts in 1995 and is current (http://www.climate.weatheroffice.ec.gc.ca/climateData/dailydata_e.html?timeframe=2&Prov=CA&StationID=10194)
2100402 daily data starts in 1976 and ends in 2007 (http://www.climate.weatheroffice.ec.gc.ca/climateData/dailydata_e.html?timeframe=2&Prov=CA&StationID=1535) This is one of the stations that I noticed data issues with regards resolution. Starting June of ’95, the daily Tmin and Tmax readings are in X.0 or X.5.
I suspect 2100LRP and 2100402 are the same station but different equipment since Env. Can has given the LRP station the WMO ID# 71966 but GHCN is giving 2100402 the WMO ID# 71966.
Just a little confusing…
They made the shift back in the 1990s over the protests of some of the staff. The AWOS installed were so unreliable they hired people to check them. I know at Winnipeg a retired employee came in early every morning to compare the AWOS readings to calibrated thermometers. When NavCanada was formed and took over the airports they refused to accept the AWOS as unreliable which triggered a hearing in the Senate chaired by Senator Carney.
Can somebody post a URL where I can get my hands on the actual global station temperature data, not the gridded data? And the 1951..1980 normals that GISS compares against? And also the adjustment factors used? I want to get my hands dirty looking at this.
Steve: If you go to the “page” in the left frame entitled “Station Data”, I’ve collected many links. I have some scripts online as well in the scripts directory, but you’ll have to forage through them a bit.