Here’s another interesting mystery in Mann et al 2008. Their SI table rtable1209 reports correlations to 1850-1995 instrumental temperature. The correlations reported in their PNAS SI Table SD1 sets all but 484 “significant” values to NA, so the r1209 table is more comprehensive. The instrumental version supposedly used in their calculations is now archived at WDCP (hooray), though it wasn’t archived in their Penn State SI, and this can be used to test reported correlations. In their SI, they report lat-longs of all 1209 series.
I calculated 1850-1995 correlations between proxies and corresponding gridcell values and compared to reported values, yielding the graphic below (color coded by proxy “type”). As you can see, many correlations match exactly up to rounding) – showing that the calculation is grabbing the “right” things for many of the series, but many don’t. There is also a remarkable pattern in the differences, which is evident as soon as you look at the graphic and which I’ll discuss below.

Figure 1. Scatter plot of calculated correlations from "infilled" 1209 series and corresponding gridcell temperatures
The pattern is this: if the Mann correlation is positive, then the reported value is equal to or greater than the value that I calculated; while if the Mann correlation is negative, the reported value is less than or equal to the value that I calculated. So if you multiple the difference by the sign of the Mann correlation, you get the following highly non-random pattern:

Figure 2. Difference between reported correlation and calculated correlation, multiplied by sign of Mann correlation
If one now looks at histograms of the correlation, one gets the following. The reported correlations are “hollowed out” around 0, yielding a somewhat trimodal distribution. The bump out on the high end of the correlations comes from the Luterbacher series, which use instrumental data. These are claimed in the 484 “significant” correlations, though they are unrepresentative of proxy series used in the MWP. There are also a lot of Briffa MXD gridded series in the 484.

Figure 3. Histograms of reported and calculated correlations
There’s a tricky little comment in the SI which I’m going to investigate in this connection:
To pass screening, a series was required to exhibit a statistically significant (P > 0.10) correlation with either one of the two closest instrumental surface temperature grid points
This would tend to hollow out the distribution as there are two chances at a “significant” correlation. So far, I haven’t figured out how (or whether) Mann adjusted his significance benchmark for this double dip and would be interested in any reader thoughts on this (see the SI.)





59 Comments
Hmmm … after going back and forth with Mann’s absolutely horrible code, I figured out that correlations are calculated in ‘propick.m’ (must be a short hand for ‘professional pick’ … amateurs should not try this at home 😉 ) from where the values are written into a file ‘info’.
save(‘/holocene/s1/zuz10/work1/temann/data/info’,’PPP’,’-ascii’)
This file is loaded in and saved to ‘rtable1209’ in the end of ‘MAKEPROXY.m’. Notice that Mann has essentially the same code repeated for all different correlation calculations (‘info’,’infol’,’infolater96′,’infollater96′)…
Anyone with any experience of programming should take a look at ‘propick.m’ … even with years of Matlab programming experience, it is almost impossible to understand what is going on even though the calculations are rather simple. Also pay attention to the codes commented out with %-sign.
Anyhow, it is seems to me that the correlation values reported in rtable1209 are not the correlations to the nearest grid cells. Instead the correlations reported are selected as indicated in the SI quote above, i.e., the ones with greater absolute correlation with respect to two closest grid cells.
JEan S, thanks for spotting where this is done. If you’re picking the max of two correlations (using signed absolute values), do you know what the “significance” really is? Did Mann use a one-pick benchmark>
Re: Steve McIntyre (#2),
What does this mean? AFAIK absolute values are by definition positive. I suppose it’s some technical meaning, but I’d rather have jumbo shrimp any day.
Re: Steve McIntyre (#2),
I don’t know. I find this whole idea of using several grid cells for testing “significant” correlation rather absurd. I thought they had somewhat given up this “teleconnection” idea, but this seems equally odd: it’s ok if Finnish trees do not respond to Finnish temperature if they happen to correlate with Swedish temperature… Strange trees growing in the Mann world.
BTW, how many of those 484 are “significant” with respect to the closest grid cell?
The statistical analysis that you are applying to this is great. Has anyone also considered applying forensic audit techniques to the data?
Eg: Benford’s Law
Just a guess, if you calculate the correlation between each series and the instrumental data for the gridcell it’s in, but also the series and the instrumental data for the next closest gridcell, and discard whichever has a lower absolute value, does that replicate Mann’s values?
It would explain why his results are always >= yours, since he only discards the closest one (which you calculated) if the other one is of greater magnitude.
This seems like spurious correlation heaven. Hell, why not compare against ALL instrumental series and pick the one which correlates best? 🙂
Steve: They do that in the next step (“RegEM”).
If you add the four center columns of the histograms (those with correlations less than abs(0.1)) there are approximately 150 more if you only match to the nearest site rather than the max of the nearest two. That’s a big shift in the number of correlations that are significant.
propick = proxy pick?
I’ve never looked at matlab code before but looking at propick.m I parse it as follows. He calculates the distance between the proxy’s lat,long and the centre of each HadCRU box. He then sorts the HadCRU boxes in distance order and uses the two closest ones.
This is all rather clumsy (speaking here as a programmer rather than a scientist). In fact, he recalculates the instrumental stuff for every proxy. Oh, and the comments for which is the instrumental and which is the proxy are the wrong way round. All of this is in a chunk labelled ‘great circle distance’.
The bit I’m struggling with is how he prepares the instrumental data. Sorting of the HadCRU boxes only makes sense if some of those boxes have been omitted. (Otherwise you could just calculate the relevant boxes algebraically from the lat,long of the proxy. It appears that he takes the HadCRU data and throwing away some data values and infilling using RegEm. This produces a dataset called ‘instfilled’. This is in his data folder. Then in some more matlab code ‘doannsst.m’, he removes the data he has infilled. I assume we’ve got code and data here for several different approaches. Looking at the grid boxes listed in ‘enough’ and ‘toofew’, it seems there aren’t very many data points in the ‘enough’ list.
What I can’t see, is any sign that a proxy is rejected if there just isn’t a temperature record to compare to. So if the temperature is known in, say London and New York, but not anywhere in between, then a proxy taken from a drilling sample in the mid atlantic would be compared to see if it fitted either London or New York. If it fits either it gets included.
There are two lists of retained gridcells “enough” and not retained “toofew”. These are numbered big hand – S to N and little hand – dateline to dateline. This isn’t reported anywhere, but I’ve figured it out.
If one requires that the 2nd nearest gridcell be adjacent to the original gridcell, then one can have pretty simple algorithm: divide the gridcell in a St Andrew’s cross and the next nearest gridcell is determined by which quadrant the proxy location is in. I’ve done calculations on this basis already and get hollowing out features, corresponding to what we are observing.
Does anybody know if Mann adjusts for the effect of autocorrelation/persistence in both the proxy and temperature data? I mentioned elsewhere that the existence of high autocorrelation (or long-term persistence) can have a severe adverse effect on the significance of cross-correlation (which can be easily checked). If it is ignored, this effect in addition to the fact that proxies are compared with non-local grid cells, suggests spuruous cross-correlation.
Re: K. Hamed (#11),
If you reduced the degrees of freedom to correct for the effects of autocorrelation I would bet that NONE of the proxies would reach p = 0.1 significance, Mann’s arbitrary criterion for significance. Willis E, at one point, posted a method for correcting N to Neff (effective sample size). Should not be too hard to find.
Re: bender (#18),
Bender, in the Mann 2008 reconstruction the authors correct for AR1 and the p value they use goes to something between 0.12 to 0.13. As we see below the autocorrelation is probably more complicated than that. Interesting point that the paper announces they used p = 0.10 and then in the SI explain that that value was a nominal one.
I suspect Dr. Ben would have know all this and been able to rationalize it all in a sentence – or at most two.
Dave Dardinger #3 writes,
Steve’s phrase in #2 is admittedly too terse, but in the post he has shown that Mann is using the correlation with the larger absolute value, while retaining its sign.
Thus, Mann often gets the same value as the own-cell correlation, but sometimes a more positive value, sometimes a more negative value, and sometimes a sign switch, but in the latter case never to a smaller absolute value. This produces the “X” pattern in Steve’s Figure 1.
Steve’s Figure 3 right shows that there is essentially no systemmatic positive correlation between the proxies and own-cell temperature, except for the instrumental Luterbacher series that aren’t going to tell us anything about the MWP anyway. Figure 3 left shows that the selection procedure substantially distorts the distribution of the correlations, rendering the classical critical values for the correlation coefficient invalid.
Since Mann has jacked up the absolute values of his correlations with this procedure, and then thrown away the negative correlations, he spuriously appears to have more positive correlations than could have happened by chance, even aside from the effective sample size issue I mentioned in my comment 23 on the 9/5 “Proxy Screening by Correlation” thread.
Bull’s eye, Steve!
Guys, thank you so much, you’ve provided me with the greatest laugh I’ve had all evening. Both the description of the tortuous method for finding the next nearest cell, and the idea of checking the correlation of the two nearest gridcell and choosing the best one, absolutely marvelous.
It did give me an interesting idea, however, of a way to check a historical reconstruction. This would be to shift all of the gridcells a couple to the right or left, re-do the proxies, and see if it makes any difference.
But I digress … many thanks for the good work.
On a closely related subject, do we know how he adjusted for autocorrelation in determining whether the correlations were significant? He says he did it, but using what method?
w.
PS – in my more whimsical moments, I amuse myself with the idea that Mann has designed this as an elaborate puzzle just to waste people’s time, featuring the most confusing conceivable combination of posted and removed and archived and changed originating datasets he could come up with, the largest possible collection of proxies including some absurdly ridiculous ones that I wouldn’t line a birdcage with, totally opaque code done in the most circuitous possible manner, statistical methods designed to make significance calculations impractical … so that it is not possible to do anything with most of it except to marvel at the calamitous complexity of the construction, to gawk at the monumental absurdity of thinking that one can recreate historical temperatures in this manner. I mean, how many person-hours are going to be blown rebutting this pseudo-scientific nonsense?
And in my less whimsical moments, I look forward to finding out a) how much weight is on the heaviest proxies and which one are they, and b) is the rain in Maine still falling in the Seine?
Is it correct that “statistically significant” correlation is determined over the entire period of these near by temperature records ?
What percentage of the “Mannr1209” correlations are exactly equal (up to a rounding error) to the “calculated 1209” correlations? If the answer is very close to 50%, then I would guess that the resolution to this puzzle has something to do with the fact that Mann compares the proxy to 2 gridcells (1/2=50%).
If it’s very different from 50%, my guess is very probably wrong.
Great site. The only one where you can watch and read Manniami Vice all day.
Here’s a little code to calculate the “next-nearest gridcell”. The code could probably be simplified a little even from this but it’s good enough. In effect, I divided the gridcell rectangle into a St Andrews cross and determined which quadrant the proxy was in. The next nearest gridcell is determined by this quadrant. You don’t need to search every gridcell in the entire globe. Because the numbering of gridcells is structured, you can identify the relative number of the next nearest gridcell. This procedure doesn’t search for remote gridcells. This covers 1167 out of 1209 gridcells, with the others being in Greenland or Antarctica.
For K. Hamed:
Wills on calculating Neff (effective sample size under autocorrelation)
A rule of thumb for AR1 processes (which these are not) is N_eff= N(1-rho)/(1+rho) where rho is AR1 coefficient. Modeled as ARMA(1,1) processes, the AR1 coefficient is higher than as pure AR1 coefficient. IMO, the distribution of correlation coefficients is more suggestive of the autocorrelation coefficient being greater than Mann assumes, since the distribution of correlation coefficients is wider than i.i.d. – something just as consistent with underestimated autocorrelation as with “significance” for some, but not all tree rings. In some ways, it is even more bizarre than MBH.
Re: Steve McIntyre (#20),
Yep, and this formula helps if more complex processes are in question.
Mann08 verifsigndecadal.m estimates rho from _calibration period_ instrumental. Interesting set of m-files we have here 😉
I’ve posted up a script which downloads and collates the instrumental data version archived by Mann at WDCP. See http://data.climateaudit.org/scripts/mann08/instrumental.txt . You’ll have to use R (but you should be !!). This script is a rather pretty example of R at work as it enables you to download zip files and use contents directly into an R session.
I’ve had to locate internal file names manually, but you don’t have to. I’m hoping that Nicholas (who’s a wizard at these things) will write an R function to locate file names and eliminate a manual step.
Please, excuse a mere physiologist who does use statistics to describe his experimental data and to decide whether an hypothesis is suported or not, but is far from an expert in the area. But should the statement in SI not be: p 0.10? Or is it “r” instead of “p”? (In which case the correlation may be statistically significant, but still does not have much of an explanatory value.)
To use p ≤ 0.05 as a cut-off point for significance is of course just a convention. But do all paleo-climate research use a less stringent convention than the one used in medical and physiological research?
Re: MikGen (#24),
I have had the same essential puzzlements about this use of p instead of r or r^2. They obviously used p = 0.1 or p = something between 0.12 and 0.13 – if an AR1 correction is made. The paper also mentions associated r values which really does not make sense to me. Like you, I would think that one could obtain a very low value for p (with a large n) and with an associated r that could be something a little more than zero.
My explanation of using p = 0.10 (nominal) and ignoring associated r values is that that method presents itself as more opportunistic for cherry picking proxies. I think Mann et al. are past masters at “inventing” these criteria and do it because nobody in the field will call them on it.
First post and it didn’t make sense. Well, all beginning is difficult.
The SI statement reads: p “greater than” 0.1, but shouldn’t it be p “less than” 0.1?
Sorry for not making sense in post #24. It should read p less than 0.10.
G’day – another lurker. Can someone explain how a “peer reviewer” could have conducted any “peer reviewing” if expert statisticians like yourselves have had to go all CSI to figure out his paper? Or is it just a fancy name for spell checking?
#25. Hey, this is much easier CSI than previously. Sometimes it takes years to get the data used in a study and in some studies, it still isn’t available. Mann has received lots of criticism and, at this point, has little choice to put his data and code out there, but it’s available and offers a foothold. Others prefer o avoid analysis by simply stonewalling and never giving a foothold for analysis.
#24, 27. I’m pretty sure that I know what he’s doing here. He’s using a distribution for the correlation coefficient and establishing benchmarks for p=.1 and p =.05. For example, he says:
If you calculate the 90th percentile of a distribution with 1/sqrt(N),, you get this number:
He might be working with the Fisher transformation, which is around unity in this range:
By adding a bit of autocorrelation, the d.f. are reduced, the s.d. increases as does the benchmark.
The issues lie in whether the assumptions are reasonable – there is much hair on the Luterbacher and Briffa MXD proxies in particular.
tanh( qnorm(.95, sd=1/sqrt(140))) #[1] 0.1381269
tanh( qnorm(.9, sd=1/sqrt(140))) #[1] 0.1078893
I generally use the method of Quenouille for correcting for complex autocorrelation. It examines the correlation at all lags. Like other methods, it calculates an “effective N”.
The formula is:
where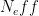 is the effective number of data points, r and s are the two series, and
is the effective number of data points, r and s are the two series, and  and
and 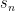 are the lag(n) autocorrelations of the two series.
are the lag(n) autocorrelations of the two series.
Has anyone figured out yet what method Mann used to account for autocorrelation?
w.
Well, I note that in my previous post, Latex has put in
8230;
in place of the
…
that my Latex translator gives me.
w.
Mann says:
The following two values are approximately equal:
So it appears to me that Mann is using some rule of thumb reducing Neff to 110. Whee does this come from? Who knows?
The acf’s (spectra) of the proxies are all over the place. Some have enormous autocorrelation, some virtually none.
Re: Steve McIntyre (#31),
So the correlation should be evaluated case-by-case, shouldn’t it? i.e. we should not be adopting a one-value-fits-all cutoff.
Re: Steve McIntyre (#31), Re: Willis Eschenbach (#32),
Well, let’s see those commented lines in the code (‘propick.m’):
% k3=find(rtable1(:,1)==n2);
% k3=find(rtable1(:,1)==n2-fix(n2/20)); %04//19/05 degrees of freedom
% k4=find(rtable1(1,:)==CL);
% if abs(rr(1,2))>rtable1(k3,k4)
if abs(rr(1,2))>=0.0 % select entire proxies
% if abs(rr(1,2))>0.14 % mike’s others
%————————————————————–
% if (rr(1,2))>0.14 % mike’s tree +, (one sided, N=140, 95%)
% if (rr(1,2))>0.109 % mike’s tree +, (one sided, N=140, 90%)
%————————————————————–
‘rtable1’ is not defined anywhere, but apparently contains tabulated (!!!) P-values, ‘CL’ is not defined anywhere, ‘rr(1,2)’ is the correlation coefficient and ‘n2’ is the number of data samples (are there any missing values in this point?, the loop just before the quoted code is checking for values which are not equal to -9999), and ‘fix’ rounds to the nearest integers towards zero. So we only need to know from where this n2/20 is coming from…
Steve, thanks for the info. I also was surprised at the wide range in both the autocorrelation and the Hurst exponent of the proxies.
I also saw that quote of Mann’s, and didn’t understand it at all. You interpret it as meaning he used an average Neff of 110. I took it as average of all of the proxy correlations each with its own Neff.
In addition, many of the datasets are non-normal, some wildly so. Some look like power law distributions, others look like badly skewed normal distributions, some are reasonable except for a few wildly different points, they’re all over the place.
I’ll do some more investigation. I do note that from his description, it seems like he:
a) established a correlation cutoff (from one of two gridcells vs the proxy) of 0.10. (To my bozo first look at this procedure, it seems like if there is a 1 in 10 chance of the first one occurring randomly, and one in ten of the second one occurring randomly, then the change of one or the other occurring randomly is 1 – (1-0.1)*(1-0.1) = 1 – 0.81 = 0.19, call it 0.20 … not much of a cutoff. But of course, that assumes no a priori knowledge. Our a priori knowledge is that it is the Mann himself doing this, and the only reason he would do it is because the correlation with just the correct gridcell was so bad that out of the 1209, he couldn’t find enough “temperature proxies” to fill up the choir, so the situation is probably worse … but I digress.)
b) chose the proxies based on that cutoff.
c) calculated the average correlation of that set of proxies after adjusting for autocorrelation, and
d) ignored the result and kept all the proxies that passed at 0.10.
Of course, this likely means that some of the proxies were a ways over 0.10 … I’ll look more to see what I can find. Has anyone come across the part of the code where he actually calculates the Neff?
Keep up the good fight,
w.
Re: Willis Eschenbach (#32),
I am working on Kendall’s tau (distribution-free rank correlation). I will post some results later.
Tabulated p values? Egad. Talk about steam powered …
But I don’t see anywhere in there that he is calculating Neff, unless it’s where he calculates the two alternate values for k3, one with Neff set arbitrarily at 19/20 of N …
% k3=find(rtable1(:,1)==n2-fix(n2/20)); %04//19/05 degrees of freedom
The laughter continues …
Thanks for the interesting info, K.
w.
Re: Willis Eschenbach (#38),
I would like to remind that the “effective number of independent observations” is not only a function of the autocorrelation. It essentially depends on the statistic we are calculating/testing. So the effective number for the case of the variance of the mean for example is different from that for variance of the variance, different from that for cross-correlation, trend, or any other statistic.
As a result, the degree to which any test is affected will vary depending on the how the variance of the test statistic is affected (inflated) by autocorrelation.
Check: [Bayley, G.V., Hammersley, J.M., (1946). The ‘effective’ number of independent observations in an autocorrelated time series, J. Royal Stat. Soc., 8 (2), 184-197.]
Re: Willis Eschenbach (#38),
I naturally meant that the critical values are tabulated in ‘rtable1’ (not p-values) (sorry).
Of course, it is possible that Mann (he’s not telling) is using some sophisticated test and the calculation of the critical
values is a cubersome task and therefore stored in a table. However, until someone finds the code or explenation, I’ll be assuming that this is the standard elementary test (CL might be “confidence level”) with a table copied from somewhere (and with additional ad-hoc modifications for the autocorrelation). There is definitely no need for tables when using Matlab is such a case.
BTW, for those new to Mannian world, this is a typical problem facing anyone trying to replicate Mann’s work. He’s using three paragraphs in the SI (read it!) to explain the screening procedure but still fails to explain which test has been used. Instead, a lot of numbers (most of which anyone could calcultate if the exact test was known) and plenty of handwaving and speculation are given. Added insult to injury is that these calculations are nowhere to be found in the code which sopposedly contains “everything”.
Re: Jean S (#40),
So what’s the deal? Giving him the benefit of the doubt, it would appear he, or whoever he’s delegated the job to haven’t actually tried running the code put in the SI and therefore it’s not a turn-key situation. Sometimes when Steve M has posted R-code the same problem arises, but he has the advantage of having homeboys to actually try it out and find such problems and let Steve M correct them quickly. You’d think the team could set up some sort of in-house testing group, but as Steve always says, “Hey, it’s the team.”
Re: Dave Dardinger (#41),
The deal is that IMO you either provide descriptions that allow replication or the code. Preferably both. If one does not have either, one can not replicate. It is not matter of the code being “turn-key”, it is the absense of the code.
Re: Hu McCulloch (#44),
Yes, under BV normal assumption it is exact (Kendall’s I, §16.36).
Re: Hu McCulloch (#45),
Steve —
How many of the non-Luterbacher correlations (both local and best-of-two) are actually positive? It looks from your graphs here and in your 9/5 post that it is very close to 50%. Regardless of how the effective sample size “Neff” was computed or guesstimated, a significant majority of the correlations should be positive if the data set has any explanatory power at all.
The 71 Luterbacher series do appear to have a strong positive correlation with temperature, but if in fact these are at least partly instrumental, this should not come as a big surprise.
#41. Dave, one big difference is that my recent code is either turnkey or near-turnkey. As a result, people can cut and paste and try it. The most common hangup is a reference to something that’s sitting on my machine and such things are easily remedied. By making it easy for people to run things and get results, people will run them. Mann’s code never works as is.
Also the reason why people complain so much about hte programming style is that it makes it much harder than it should be to figure out the calculations. Plus the archived code isn’t complete anyway.
Re: Steve McIntyre (#43),
&
Re: Jean S (#46),
I realize that the material Mann supplied is not turn-key. The question is why not at least have someone try it to see if there are missing items? If your tester finds some files not included in the SI which should be, then they can be added. You wouldn’t necessarily have to make it turn-key, but that would probably be a good goal to work towards. It shouldn’t take very long for a good grad student to work it out if all the original data and code was made available at the SI or not.
BTW, I’m sure you’re aware I’m postulating a researcher who actually does want his work verified.
Re: Dave Dardinger (#47), as a software engineer and not a published scientist, I’d consider it mandatory to make things like the SI be effectively turnkey, aside from (reasonable) tool and library prerequisites.
In any case I remain shocked that no peer reviewer is apparently both independent of the authors and attempting to make sense of the SI. Clearly from the continuing fun being had here, all peer reviewers who read the SI were already intimately familiar with the data and didn’t need to grope around in the dark. I will freely admit to assuming that the set of all peer reviewers who read the SI appears likely to be the Empty Set….
Re Jean S, #40,
The reference you give for the standard critical value for r, http://faculty.vassar.edu/lowry/ch4apx.html, says that this transform of r is only approximately distributed Student t with n-2 DOF, and then only provided n .GT. 6.
However, my understanding is that if the two variables have a BV normal distribution with unknown variances, this formula in fact exactly has the Student t distribution. It would only be approximate if the conditional distribution(s) had non-linear means or were non-gaussian, or if one used large-sample short cuts like dropping the (1-r^2) term, replacing n-2 with n, or replacing the Student t distribution with the Gaussian. Do you see any other reason it might not be exact?
In any event, I mentioned earlier that some of the critical values they report appear to use some of these relatively harmless short-cuts. A far bigger problem is that they may have overstated the true sample size of sparse series like Punta Laguna (just to take Steve’s illustrative example), as I mentioned in that comment, even aside from the pure serial correlation issue.
Although Steve’s 9/5 graph shows that most of the correlations for the 484 proxies that survived screening are positive, and this would have to be the case if a one-tailed test were used for non-negative only correlations as described in the SI, Steve’s graph shows that a few are somehow negative.
Scanning Mann’s 1209ProxyNames.XLS file, one example that jumps out with a solidly negative correlation is #330 (on line 331), Chiune et al grape harvest dates in Burgundy, 1370-2003. Presumably an early harvest means warmer weather, so did Mann in fact apply an a priori tentatively negative sign to such proxies, instead of assuming all must be positive as stated in the SI? If so, where does one find the a priori sign assumptions?
Further to my earlier post (#37), I have performed Kendall’s tau rank correlation test with and without correction for autocorrelation (my own method, unpublished yet) between the proxies and the global instrumental record (I have yet to obtain and work on the gridded data). The results may, nevertheless, be of interest:
The whole 140-year period: at the 10% level 565 proxies have significant rank correlation (398 + and 167-) before autocorrelation correction, while only 365 proxies (278+ and 87-) are significant after correction.
However, to exclude the effect of possible infilling of the recent data and avoid the sharp trend and the divergence problem I also tested the period 1850 to 1931 (which shows almost no trend). In that period, at the 10% level 484 proxies (268+ and 216-) have significant correlation before autocorrelation correction, while only 271 proxies (172+ and 99-) are significant after correction.
It seems that autocorrelation in this would at least question the significance of 35 to 45% of the selected proxies.
RE Jean S #46 (quoting Mann 08 text):
Thanks, Jean! My assumption in #45 that all “should” be positive was clearly wrong.
Would treering MXD’s be a priori positive, or two-sided?
The Anadalusia/Serengeti precipitation record is an “historical record”, yet is accepted despite its negative sign, so this can’t quite be a complete list of the assumed signs. There doesn’t seem to be a field for this important factor on the XLS listing of 1209 proxies.
It makes a substantial difference for K. Hamed’s calculation in #49 which, if either, sign is expected. Furthermore, Kendall’s tau as used by K. does not take into account the “best of two” procedure that pre-picks cherries with big correlations. If adjacent gridcells were prefectly correlated, this would not make a difference, but Steve’s figures show they are not.
Re: Hu McCulloch (#50),
This is correct, I used a one-sided test for all proxies in #49. A two-sided test would eliminate even more proxies.
Re: 49 -51.
Don’t forget that 71 Luterbacher series have temp data included. Also the 95 accepted Schweingruber have 38 years of infilled high correlation data on the end.
re 30, 40,
Puzzled I am,
has a Student-t distribution on (n-2) dof, and
how do I transform t-test to be based on r only ?
(Why I am asking, I need statistically significant slopes to build satisfactory CIs for calibration.. )
((Some proxies that enter gridboxcps (i=1885, i=1932) do not pass any of those r criterions Mann mentions.
))
I am not sure if I understand your question, but I think the answer is found looking at the statistic given in the Jean S (#40) standard elementary test” reference. In the case of testing for correlation equal to zero (or equivalently when the slope β = 0), that statistic is (using a little algebra) identical to the one you give and has an exact t-distribution. If β is not zero, then it is not possible to “transform the t-test to be based on r only”.
The t statistic formula can be inverted as
where df = n-2 to calculate critical values for proxy acceptance. I suspect that that is what was supposedly done (using a table?) and then commented out of the program. I calculated the values using Matlab (not copyrighted – can be used without attribution 😉 ):
The corresponding critical values given in the SI were
.42, .34, .13, .11.
The values calculated by Matlab correspond to exact distribution values that are contained in tables in statistical text books, so perhaps Prof. Mann could provide an explanation of where the values for 8 and 13 df come from. By the way, did anyone notice that, in several places in the SI, the word “degrees” was replaced by the symbol for degrees (as in angle), e.g. “n = 8^o of freedom? Ah … CliSci stat notation!
There was another item in the SI that I found particularly bothersome:
Since a spurious proxy will pass the test when its absolute value exceeds the critical value, this means that such false proxies will be accepted not 13% of the time, but twice that or 26% of the time (13% on the positive side plus 13% more on the negative side). Anyone who has taken elementary statistics would realize that the significance level of a two-sided test (done on the proxies) is double that of the one-sided test when the same critical value is used. So according to the calculations in the SI, there could likely be as many as 300 proxies that have gotten in “by chance alone” and are uncorrelated with the temperature.
Re: RomanM (#54),
Thanks, exactly what I was looking for. Same test applies, whether x is stochastic (analysis of joint distribution of x and y ) or not (analysis carried out conditionally, given x ).
..IOW, we don’t need to make distributional assumptions about temperature (x).
Re: RomanM (#54),
Maybe he applied Monte Carlo to get those values?
Anyway, for i=1885 r=-0.02 and for i=1932 r=-0.005, they shouldn’t enter gridboxcps.m. Maybe the selection between two closest grid points saves them ? In addition, there are 3 other series, (i =978, )
)
1813, 1859 ) where the information content is too weak to construct 95 % CI ( using Brown’s
Note that the equation above is the same as Eq 8 in here, when q=1 and p=1. Now, let’s take first series in AD1000 step of gridboxcps, i=670 (*)
http://signals.auditblogs.com/files/2008/10/zi670.txt
and corresponding grid instrumental,
http://signals.auditblogs.com/files/2008/10/xi670.txt
n=146, so t = tinv(0.975,146-2) = 1.98 . Some other values are needed,
Resulting local reconstruction with 95 % CI is:
As you can see, intervals computed this way are not very short. For year 1000 ( Z=-1.43 ), it is -8.6 … 0.52 C
(*) glon(i)= -72.5000, glat(i) -43.5000, name ?
#53. UC, Mann appears to do the following – he calculates Fisher’s tanh((1-r)/(1+r)) on the basis that this is normal with df=1/sqrt(N-2). This yielded his reported r benchmarks using the percentiles of the normal distribution.
readme updated in http://www.meteo.psu.edu/~mann/supplements/MultiproxyMeans07/code/codecps/Readme.txt