Has anyone tried to replicate Santer’s Table 1 and 3 results? It’s not as easy as it looks. What’s tricky is that the table looks pretty easy (and most of it is), but, if you assume that it’s done in a conventional way, you’ll get wrongfooted. In fairness, Santer provided an equation for the unconventional calculation, but it’s easy to miss what he did and I was unable to verify one of the legs for the unconventional method using profile likelihood methods on the UAH data. The difference is non-negligible (about 0.05 deg C/decade in the upper CI trend).
We’ve also had some debate between beaker and Lucia over whether there was a typo in Santer’s equation – Lucia saying no, beaker yes. Lucia said that she emailed Gavin seeking clarification, but she hasn’t reported back to my recollection. Anyway, I can now see what Santer is doing in Table III and can objectively confirm Lucia’s interpretation over beaker’s.
First, here’s Santer Table 1:

Now here it is in a digital format (collated from the pdf to make comparisons handy)
loc=”http://data.climateaudit.org/data/models/santer_2008_table1.dat”
santer=read.table(loc,skip=1)
names(santer)=c(“item”,”layer”,”trend”,”se”,”sd”,”r1″,”neff”)
row.names(santer)=paste(santer[,1],santer[,2],sep=”_”)
santer=santer[,3:ncol(santer)]
Next let’s collect the UAH series for 1979-99 on (using a script on file at CA), dividing the year scale by 10 (because Table 1 is in deg C/decade):
source(“http://data.climateaudit.org/scripts/spaghetti/msu.glb.txt”)
x=msu[,”Trpcs”];id=”UAH_T2LT”
temp=(time(x)>=1979)&(time(x)<2000)
x=ts(x[temp],start=c(1979,1),freq=12)
year=c(time(x))/10;N=length(x);N #252
Column 3 (“S.D.”) matches the obvious calculation almost exactly:
options(digits=3)
c(sd(x),santer[id,”sd”]) # 0.300 0.299
The OLS trend calculations are pretty close, but suggest that the UAH version used in Santer et al 2008 may not be a 2008 version.
fm= lm (x~year)
c(fm$coef[2],santer[id,”trend”]) # 0.0591 0.0600
The AR1 coefficients from the OLS residuals are a bit further apart than one would like – it may be due to a different version of the UAH data or to some difference between Santer’s arima algorithm and the R version. (This is the step where Gavin got wrongfooted over at Lucia’s, as he did arima calculations for Lucia on the original series x rather than the residuals, as he acknowledged when I pointed it out to him.)
r= arima (fm$residuals,order=c(1,0,0))$coef[1]; #
c(r,santer[id,”r1″]) # 0.888 0.891
This difference leads to a 3% difference in the N_eff:
neff= N * (1-r)/(1+r) ;
r1= santer[id,”r1″]
c(neff,N * (1-r1)/(1+r1) , santer[id,”neff”]) ; #15.0 14.5 14.5
Now for the part that’s a little bit tricky. Santer describes an adjustment of the number of degrees of freedom for autocorrelation according to the following equation:
![]()
My instinct in implementing this adjustment was to multiple the standard error of the slope from the linear regression model by sqrt(N/N_eff) as follows, but this left the result about 7% narrower than Santer:
c(sqrt(N/santer[id,”neff”])*summary(fm)$coef[2,”Std. Error”], santer[id,”se”] ) # 0.129 0.138
It took me quite a while to figure out where the difference lay. First, the standard error of the slope in the regression model can be described in first principles as the ssq of the residuals divided by the degrees of freedom (fm$df = N-2) and the ssq of the time intervals (ssx):
c(summary(fm)$coef[2,”Std. Error”],sqrt(sum(fm$residuals^2)/fm$df /ssx) )
# 0.031 0.031
Santer appears to calculate his slope SE from first principles, describing the operation as follows:

If the N_eff -2 is used for the adjustment instead of N_eff, the Santer standard error of the slope can be derived:
c( summary(fm)$coef[2,”Std. Error”] * sqrt( (N-2)/(santer[id,”neff”]-2)) , santer[id,”se”] )
# 0.139 0.138
Santer did not provide a statistical citation for the subtraction of 2 in this context, but was conscious enough of the issue to raise the matter in the SI (though not the article):
The “-2” in equation (5) requires explanation.
Indeed.
Speaking in general terms, I don’t like the idea of experimental statistical methods being used in contentious applied problems. After a short discussion in the SI, they argue that their method is not penalizing the Douglass results because their method tends to run slightly low and thereby give a higher N_eff than the data itself:
The small positive bias in rejection rates arises in part because r1, the sample value of the lag-1 autocorrelation coefficient (which is estimated from the regression residuals of the synthetic time series) is a biased estimate of the population value of a1 used in the AR-1 model (Nychka et al., 2000).
Unfortunately Nychka et al 2000 does not appear in the list of references and does not appear at Nychka’s list of publications. In the predecessor article (Santer et al JGR 2000), the corresponding academic reference was check-kited (Nychka et al, manuscript in preparation), but 8 years later, the check still seems not to have cleared. (I’ve written Nychka seeking clarification on this and will report further if anything changes.) [Update – we’ve tracked down Nychka et al 2000 through a 2007 citation to it as an unpublished manuscript. The link at UCAR is dead, but the article is available here (pdf). Even though the article has not appeared in the “peer reviewed” literature, it is a sensible technical report and has much of interest. It builds on Zwiers and von Storch (J Clim 1995), another sensible article. It’s not clear to me as of Oct 23 that the method in Santer et al 2008 is the same as the methods in Nychka et al 2000, but I’ll look at this. ]
In the running text, they purport to justify their procedure using a difference reference:
The key point to note here is that our paired trends test is slightly liberal – i.e., it is more likely to incorrectly reject hypothesis H1 (see Section 4)
Turning to section 4, it states:
Experiments with synthetic data reveal that the use of an AR-1 model for calculating N_eff tends to overestimate the true effective sample size (Zwiers and von Storch, 1995). This means that our d test is too liberal …
I attempted to test this claim by comparing the Santer CIs to the CIs calculated using the profile likelihood method described previously. The black colors show 1999 data – which is the only data discussed here. The dotted vertical lines show the 95% CI intervals calculated from profile likelihood. The black dots show the intervals calculated using a sqrt(N/N_eff) adjustment relative to the maximum likelihood slope under AR1 – which in this case appears to be less than the OLS slope. The black triangles show the Santer confidence intervals.

The Santer 95% upper CI is 0.051 deg C higher than my result (0.336 vs 0.285). This result is exactly opposite to the assertion in Santer’s SI, as the expanded confidence intervals would make it more difficult to show inconsistency (rather than less difficult.)
I think that one can see how the Santer method might actually over-estimate the AR1 coefficient of the residuals relative to the maximum likelihood method that I used. The Santer results are NOT maximum likelihood for the combination of trend and AR1 coefficient. They calculate the slope and then the AR1 coefficient given the slope, whereas I did a joint maximization over both the slope and AR1 coefficient using profile likelihoods. In the specific examples, the AR1 coeffficient of this method is less than the Santer (N_eff -2) coefficient. This makes sense – the slope in the combined ML result is not the same as the OLS slope; the differences are not huge, but neither are the differences in the AR1 coefficient. So I’m not persuaded by the Santer argument for a combined ML calculation, even if it holds when the calculations are done one at a time.
As noted before, with the inclusion of data up to 2008, the upper CI declines quite dramatically to 0.182 deg C/decade (as compared to Santer’s 0.336), a change which may not be irrelevant when one considers that the ensemble mean trend is 0.214 deg C/decade. As noted before, the change arises primarily from narrowing of the CI intervals owing to AR1 modeling, with changes in the trend estimate being surprisingly slight.
Table 3
This is an important table as the results from this table are ultimately applied to significance testing. As noted above, controversy arose between beaker and Lucia over exactly what Santer was doing. Lucia’s interpretation (also mine) was that the only difference between the Douglass and Santer tests was the inclusion of an error relating to the observations and that both studies used the standard error of the model means; beaker argued that the appropriate standard error was the population standard error and argued that this must have been Santer used (however they made a typo in their article.) I can now report that Lucia’s interpretation can be verified in the calculations.
First let’s collect some data for the Table III calculations.
d1=1.11;d1star=7.16 #from Table III
trend.model=santer[“Multi-model_mean_T2LT”,”trend”]; # 0.215
# this is a little higher than the multi-model mean of Douglass Table 1 (0.208)
sd.model=santer[“Inter-model_S.D._T2LT”,1]; #0.0920
# this is a little higher than the multi-model sd of Douglass Table 1 (0.0913)
trend.obs=santer[“UAH_T2LT”,”trend”];trend.obs # 0.06
se.obs=santer[“UAH_T2LT”,”se”];se.obs #0.138
# this is the adjusted Std. Error of the trend estimate
M=19 #from Santer
Next we can verify that Santer’s Table III d1star calculation for his Douglass emulation (presuming his methods):
c( (trend.model-trend.obs)/ (sd.model/sqrt(M-1)), d1star)
## 7.15 7.16 #replicates Table III
Now here is the calculation yielding Santer’s Table III d1 result, proving that they used the standard deviation of the model mean (the method decried by beaker):
c( (trend.model-trend.obs)/ sqrt( (sd.model/sqrt(M-1))^2 + se.obs^2), d1)
#1.11 1.11
At this point, we really don’t need to hear back from Gavin Schmidt on what he thinks that they did. We know what they did.





66 Comments
Mr.McIntyre, there is an editing typo, orphan phrases at bottom:
ecidedly unusual and deserv
es a little consideration. Tracking down the reason for the unusual part of the method is not that easy.
Al S.
I noticed this presentation which suggests that stratospheric temperatures have stopped cooling for the last decade or more and even when there is a cooling trend it is less than expected by the models:
http://ams.confex.com/ams/15isa14m/techprogram/paper_125889.htm
This strikes me as a rather signicant data point since the modellers always insist that stratospheric cooling is the “signature” of GHGs.
It seems to me that these stratospheric temperatures re-enforce the claim that the models over-predict the effect of GHGs.
Steve: Stratospheric cooling is something predicted by conventional physics and IMO convincing evidence that increased CO2 affects the upper atmosphere. The main issue that puzzles me is the physics of the lapse rate – I talked to Chris Essex about this in Erice and meant to post about it, when Mann et al 2008 came along. It’s OT on this thread.
I’ve added a section on Table III. This proves that Lucia’s exegesis of the Santer test was correct in regard to her dispute with beaker.
I’ve organized the above testing into a utility function, which compares to Santer Tables 1 and 3 as follows for AH T2LT:
Here are the virtual exact corresponding results for RSS T2LT:
You can see the d1 statistic used by Santer climbing rapidly as more data narrows the CI of the trend (emulation to 2008; Santer to 1999). I’m going to post on this.
The t-test benchmark:
SteveMcIntyre,
Gavin had replied “I don’t think it does – but I’ll check and get back to you. ”
So at least on first glance it looked ok to him.
The way equation (12) stands,
* In the limit that one runs a model an infinite number of times, the model predictions must fall inside the uncertainty range for the observation. That is, equation (12) becomes the method I have been using to test models. In fact, since I used AR(1), the method at my blog parallels the Santer method, except that I don’t include the SE of the models. (I was planning to add that now that I have located the model runs for GMST.)
* In the limit that the observations contain no uncertainty, the Santer method becomes the Douglas method. (But we know that.)
There is an issue I’m going to comment on as soon as I have some numbers together. It has to do with with treating all deviations from a linear trend as IID across runs. Guess which deviations from the linear trend are not independent across models runs. (Hint: Think Pinatubo & El Chicon.)
Lucia (#5),
I haven’t been following this thread very closely, but it seems to me that you are assuming that a model (of any kind) accurately depicts the real world which is not the case?
Jerry
Re: Gerald Browning (#6),
A couple of days back I said:
And now at #5 above Lucia said:
That cannot be correct for the general case. If it is taken to be correct, the analysis is not measuring what has intended to be measured.
For example, let’s say that my model always gives the results to be 97.5. Even after an infinite numbers of runs the results is still 97.5. If the measured data give 27.9+/- 0.07, there’s no way the predictions of my model will fall inside the uncertainty range for the observation.
There must be some additional assumptions behind the analysis method. Maybe the assumption is that the measured data and the model results belong to the same population? If this is the case, then it’s an assumption that cannot be justified unless some selection criteria have been applied to the models/codes/applications/users.
What am I missing here?
Re: Gerald Browning (#6),
Jerry–For the purpose of applying a statistical tests, I first assume the models are correct as the hypothesis to be tested. I then compare to data under the assumption the model is correct. If the results could happen only 1 in 20 times under these assumptions then I deem the original hypothesis false.
This is the classic frequentist test.
You can see Brigg’s comment here: William M Briggs (#29). He is correct to say frequentism is confusing because you test a hypothesis that is rarely the question you really wish to ask.
The philosophy of frequentism is you always start out by assuming that some theory is true, then you apply a statistical test. One of the difficulties is that you often need lots of data to prove something that is obviously false.
Re: Dan Hughes (#13),
You quoted this:
I didn’t say that well. What I mean is that equation (12) in Santer imples this:
In the limit that one runs an accurate model an infinite number of times, the prediction based on average of all model runs must fall inside the uncertainty range for the observation.
We can see this by examining equation (12)
If n_m-> infinity, the circled term vanishes. In that case, the denominator for d_1* is the standard error for the observations, with no contribution from the model standard deviation (because that’s divided by 1/n_m, and so the term vanishes.)
Also note that if the observations contained no error, the equation becomes the Douglas test. But we already knew that because all Santer did was add the observation error to the error Doublas accounted for.
Re: lucia (#14),
This is, btw, exactly equivalent to beaker’s infinite number of parallel Earths example.
And the Douglass test will still be wrong, as beaker and Santer et al pointed out, because it will reject too high a percentage of observed results, effectively 100% in the limiting case above. Measurement error is not the only uncertainty in the observed results. For an accurate model s{bo} = s{$$} and the test becomes beakers standard deviation test.
First attempt at LaTex to get the less than and greater than symbols. Probably won’t work.
Re: DeWitt Payne (#16),
Wrong. Lucia (and Roman M) are talking about models. Beaker was talking about the Earth’s historical temperature record itself being but one possible realization of an infinite number of possible Star Trek-like parallel universes, thus requiring that the historical record reflect the uncertainty of these chaotic parallel Earths.
Steve and Lucia have both demonstrated that Santer’s test uses the standard error, not the standard deviation. Are you saying that Santer is wrong, too?
Re: Mike B (#18),
So is beaker. Beaker used parallel Earths to represent the only possible models with perfect physics and hence perfect accuracy. Santer et al correctly uses the standard error of the model ensemble mean in their equation as does Douglass. In the limit of an infinite number of replications, however, as lucia pointed out above, that vanishes. If you actually look at equation 12 you see that the observation statistic is the standard deviation of the observation s{bo} (well strictly the square of the stdev or the variance) because there is only one and with n = 1 the standard error is equal to the standard deviation. That does not vanish even in the limit of perfect accuracy of measurement.
Re: Mike B (#18),
I agree that Beaker’s approach is concerned about the chaotic or whatever content that results from a single rendition of an infinite number of possible earthly climates and it is that content that the models cannot predict.
I have another problem with what is attributed here to the Santer et al. (2008) paper. On my reading of the paper, I got the impression that the Santer authors labeled the Douglass approach wrong, for at least one reason, because they used the SEM and Santer uses the Stdev – why else would Santer et al. show the graph with the SEM of the model results and the Stdev? Were not the Santer authors merely showing a result for the Douglass comparison by assuming the (incorrect in their view) use of SEM and then adding in all their (claimed) improvements simply to show that such a procedure (using their claimed correct rendition of SEM which would be incorrect to use in the first place in their estimation) would not show a statistical difference between the model and observed results?
Re: Kenneth Fritsch (#20),
Figure 6A in Santer et al. bothers me too. It does not seem to agree with how they explain the test should be done. Neither they nor Douglass et al. use the standard deviation of the model ensembles, so why is it included in 6 A, B and C? And why aren’t there error bars on the observed points at different altitudes in 6A? Observation error bars are present in 6B and 6C.
Re: DeWitt Payne (#21),
Page 7 of Santer et al. (2008) summarizes the faults they see with Douglass et al. (2007) of which I have excerpted below.
Santer et al. claims that there are two components in the temperature trends for both the observed and modeled results, i.e. the forced component and the natural component. They talk about the natural component not being “perfectly” known.
The Santer authors also make a special point that using SEM for the statistical comparison is incorrect. I agree with DeWitt Payne that Santer et al. follows pretty much from the Beaker approach.
My problem is what happens with these comparisons when they are based on the ratios and differences of troposphere and surface trends such as was essentially what Douglass et al. did in their analyses. How much or many of these factors cancel? Or should theoretically cancel? I have also excerpted below from Santer et al a statement on using differences. I was surprised that Santer et al. spent so much time looking at troposphere temperature trends and not as differences of those trends with the surface trends and then finally goes into the differencing as more of an aside. Look in Table IV in Santer et al. at the rejection rate using UAH against the surface temperatures. I did not see any differencing with the radio sonde results and surface temperature trends even though with that measurement there is the entire altitude range to look at. Particularly puzzling since Santer et al. makes a claim for better “compliance” of modelled and observed results when including the newer radio sondes data.
Summary of Santer issues with Douglass:
Santer on differencing:
Any way I think we can thank Douglass et al. for provoking a response from Santer and cohorts so that we can obtain a visual (and truly consensus) picture of the disarray in model and observed results and to look for a comprehensive approach to the statistical comparison as suggested by Ross McKitrick – which now seems like a long time ago.
Re: Kenneth Fritsch (#29),
Don’t see how you reach this conclusion, Kenneth:
Beaker was convinced there was a typo in Santer, because the equation listed by Santer did not match the “beaker approach”.
Re: Mike B (#33),
The Santer paper states clearly that:
Beaker’s position was essentially the same.
The Santer paper states that the climate dependent variable depends on a forced component and a “natural” component. If that natural component is the same as Beaker’s unknown component of a single realization of the many possible realizations of an earthly climate then there is agreement there.
I find Beaker’s and Santer et al.’s analysis and approach very unsatisfying as it does not allow the separation of conjecture and solid evidence for the theory. Neither answer the question of what cancels on doing differences and ratios of the temperature trends for the troposphere and surface. Also their approaches could be extended in my view to that unkownable natural or single realization content nullifying the climate models as predictors of future climates (or past for that matter). They would only be able to say something about the forced part of the climate, but not the total realized climate.
Having said all that, I think the discussion of Santer et al here at CA has gone off the rails. What we need is a whole new approach to the satistical analysis much along the lines that Ross McKitrick was advocating. He closed by saying the last one out turn off the lights and I am beginning to see some meaning in that comment.
Re: Kenneth Fritsch (#20),
Interesting observation, Kenneth. One possible explanation is that at least one of the co-authors of Santer, et al 2008 don’t fully understand their own paper.
Re: DeWitt Payne (#16),
No. The Douglas test would not be wrong. The difficulty is when we start talking about the number of models approaching infinity and the observational error being zero, we are comparing 1/infinity to zero.
In reality, if the models are absolutely positively correct in the sense of being an average of all possible earthly values from some set, then in the limit N_m-> infinity, their average will match a perfect observation perfectly.
As we approach this theoretical destination of ultra-perfection, the Douglas test words fine– provided the observation really, truly are perfect.
The difficulties arise if the observation contains an error. In that case, as the number of models approaches infinity, the models converge on a value that is different from the observation by the amount of the error.
As a practical matter, when we are discussing climate, the “uncertainty” in the observation is not measurement uncertainty, it is stochastic uncertainty. So, with climate, we can’t get a perfect measurement of the trend based on one realization of a particular time period. Instead, we must estimate the uncertainty.
But the fact that we can’t get a “perfect” observation of the average over all possible realizations of earth weather (under whatever we define as “similar” circumstances”) doesn’t mean we can’t discuss the properties of Santer12 under the hypothetical circumstance where something particular feature of climate was both deterministic and measured perfectly.
I think Santer(12) does what it sets out to do just fine. However, many arguments arise out of estimating the uncertainty in the observations. These arguments are nearly impossible to resolve because there is no real “right” way to do that.
Re: lucia (#28),
One or both of us aren’t reading the other correctly. I’m beginning to feel beaker’s pain. I’ll try again. The mean of some variable in an ensemble of perfect model runs would converge on the mean of the population of all possible runs (bm) with vanishingly small standard error as the number of runs in the ensemble increases without limit. The mean of a number of measurements of the same variable in one realization would converge on the true value of that realization (bo) with vanishingly small standard error as the number of measurements increases without limit. However, the probability that bo and bm are identical at the limit is, I contend, also vanishingly small. Only in the non-chaotic case where there really was only one possible climate would the (perfect) models and the measurements always converge to the same value.
In apple terms, weigh every apple (defined to be non-identical to some degree) in a very large barrel to very high precision and calculate the mean. Pick one apple from the barrel and weigh it to equally high precision. If you use the Douglass et al. test and compare using only the standard error of the mean, you will, in the limit of an infinitely large barrel and infinitely precise measurement, always reject the hypothesis that the individual apple came from the same barrel. The measurement error for the individual apple and the standard error of the mean of all apples vanish, but the standard deviation of the weights of all the apples does not change and it is the standard deviation of the weights of all the apples in the barrel, that is s{bm}, not the standard error of the measurement of the weight of the individual apple that must be used for any rational test. A rational test being defined as a test that rejects the null hypothesis that all the apples are from the same populations at the 95% confidence level only 5% of the time.
Obviously, with the climate it’s not that simple, but the principle is the same. There must be variance in the observation that does not go away in the limit of perfect measurement because you are comparing the mean of a set of realizations with an individual realization that in the null hypothesis are from the same population. Also, the standard deviation of variable of interest in the model runs is the only way to estimate the (limiting) standard deviation of a given variable in a single realization.
Re: DeWitt Payne (#39),
Perhaps the reason why Santer et al, as Steve has shown, use the standard error test that beaker & company deride is that the proposed alternative is not coherent.
1) Suppose we had the ensemble of parallel Earths a la beaker. Each allegedly has a different temperature history because of sensitive dependence to initial conditions. Now somebody claims to access this ensemble to produce a prediction for our own planet (Earth One, for all DC comics fans). This individual reports to us not the ensemble of histories, but what purports to be the mean history from the ensemble. (Obviously, this report is similar to what our average of real-world climate models claims to bring to the table.)
We want to know if our rappoteur has gotten it right, i.e. truly averaged the ensemble of parallel Earths, or whether he’s just pulled some trajectory out of his hat. One test we might try is to compare the reported trajectory to the history here on Earth One to see how closely they match. In order to do that we will have to construct a test statistic on whatever properties of the history we deem relevant.
But we can only do that if we have some idea of the SIZE of the variations caused by sensitive dependence to initial conditions. If the “chaotic” effect were small, then we would require the reported trajectory to match the actual history rather closely. If the “chaos” effect were very large, then we would not be able to reject any trajectory reported to us as coming from the ensemble, but of course then the ensemble would be useless for forecasting on Earth One and the whole modeling exercise would be pointless.
Unfortunately, we have no way of knowing how big the sensitive dependence on initial conditions is, and hence we have no basis for comparison. From a decision theory point of view, however, we only care about these models if the “chaos” problem isn’t very big. If the problem is really big, no model has any hope of ever getting anything right, no matter how well it mimics the Earth. The only way forward is to start with the optimisitic assumption that useful modeling is possible; the most straightforward way to do that is to suppose that the “chaos” problem is zero. And that is what it appears both authors have in fact done in the end.
2) If you object to assuming that chaos is zero and want to plug in some other number to apporximate irreducible climate variance, what number should you choose? The ensemble of real-world climate models is not a population of parallel Earths–it is itself a kind of composite model–and so the variations within it offer no clue about sensitive dependence to initial conditions.
3) The variance among real-world climate models is presumably not due in any large measure to sensitive dependence on initial conditions. Hence, even if you think of each model as a separate and imperfect parallel Earth you should not use the veriation in their outputs as a measure of this irreducible variation.
So the test statistic upheld by beaker, et al, doesn’t seem to be a very good one.
Re: srp (#47),
You have more or less reasoned the problem as I have done. Actually on further thought the Santer et al. equation 12 does in effect what I suggested to Beaker and that is to use the SEM approach with an adjustment for the estimation of the unknown content for the observed single realization ot the earth’s climate.
My impression of the Beaker concept was as you suggest that it has an unknown for the single realization content – or at least Beaker was not about to offer an estimation of the magnitude of the content. That the Santer authors would not use a concept based on the Beaker approach is hardly surprising, since it would render their climate models only good for the forced part (with all its error and uncertainties) of the climate equation and leave a big unknown for the single realization content.
Anyway, onward and upward with RM approach.
Re: DeWitt Payne (#39),
Why do you think this? If models are correct, then the models converge to the perfect observation and bo=bm.
So, (bo-bm)=0. As we create a perfect observation,the standard error of bo goes to zero, the normalized difference, (b0-bm)/(standard error for difference) is 0/0. This value needs to stay roughly below 2 to “not falisfy” when we are using a 95% confidence level.
But even if the “bo” is perfect, and has no error, the standard error associated with any finite number of model runs prevents any problems. bm approaches the correct value “bo”– but at the same rate as the standard error. You have to write the thing out and use L’hopitals rule to see what happens.
Re: lucia (#48),
Lucia, this is the treatment I wanted to show when Beaker and DeWitt claimed, in effect, that one would never use SEM for making these statistical comparisons. Do you have a reference to your calculations using the L’hopitals rule or could you spell it out here or at your place?
Re: Kenneth Fritsch (#49),
No. I don’t. So here’s what I think:
Let me use 〈b_m〉for a sample average. s{〈b_m〉} for the standard deviation of sample averages and «bm» for the true mean.
With regard to the average over all models, if a model is known to converge to “«bm»” and but each realization differs from «bm» because of ‘noise’ of any sort, then we we expect the average over a sample of “N” realization will be b〈b_m〉=«bm» and the standard deviation of that averaged quantity will be SE(N)= s{〈b_m〉}/sqrt (N); (I’m showing the dependence on Number explicitely.)
If the true mean of the observable the models wish to predict happens to be some known deterministic value we denote with bo, then «bm»=bo
When we do the t-test, we calculate a value
(〈b_m〉- bo)/ SE(N)
Where SE is our estimate of the standard error in the measurement of 〈b_m〉 based on N measurements.
But recall, the expected value of (〈b_m〉- bo) is SE(N)!
The expected value of this quantity is 1. Since N->infinity, it is normally distributed. The 95% cut-off is at ±1.96!
There isn’t any problem with the test when bo is something that happens to be deterministic and is known with no error. All that happens is the paired t-test because the easier ordinary t-test, which is well understood.
The only difficulty in this problem is that when doing climate problems, people may forget there is uncertainty in the observable. That wouldn’t be a difficulty if the uncertainty in the observable were very small relative to the uncertainty in the average over an ensemble of runs. Unfortunately, it’s large.
When we do the test, we want to compare like to like.
If we are comparing to the observable to the average over the ensemble of models we need to imagine beakers infinite number of parlalel universes and estimate the uncertainty in b_o. (Or, if the major issue was measurement uncertainty, we need to include that.) The Douglas test was trying to make this comparisons, so it needed to include that uncertainty. They didn’t and that was an error, and since that uncertainty in large compared to the SE for the models it mattered.
“H2” in Santer asks if the average of model results matches the average over all beakers “parallel” earths. The paired t-test is correct for that question– just as it would be correct for comparing the mean of one batch of widgets to another batch of widgets. That uses SE.
Re: lucia (#52),
Lucia, I agree with what you say here about tropospheric temperature trends when viewed alone, but what, in effect, Douglass et al. (2007) were doing was looking at a difference between tropospheric and surface temperature trends for climate models and observed results, i.e. comparing ratios. What are or should be the cancelling effects when differences and ratios are used? No one has attempted to answer this question to my satisfaction much less answered it.
I also do not believe we have talked much here about the relatively short shrift Santer et al. gives differencing in their paper nor have we dealt with Santer’s differencing comparison of UAH observed and the model results and the number of rejections of the H1 hypothesis.
One question for the group. Everone always assumes a linear trend,
but what if the trend is not linear?
Jerry
#7. doubtless all sorts of things, but the differences are probably not material for these stats over this period. For now, we’ re just playing the ball where it lies and seeing what Santer and his team are doing.
Smit et al 2007 (Coastal Engineering) cite Nychka et al 2000 as follows:
Santer turns out to be a coauthor and the manuscript was never published. No wonder I couldn’t locate it. There are thousands of statistical references. Surely Santer could have found a published 3rd party reference as opposed to their own unpublished article – meritorious tho it may be.
Re: Steve McIntyre (#9),
Steve,
I think that the (1-r)/(1+r) correction is only approximate. If I am not mistaken, this paper gives more exact formulas for short time series:
Matalas, N.C., and Sankarasubramanian, A., (2003). Effect of persistence on trend detection via regression. Water Resour. Res., 39(12) 1342, doi: 10.1029/2003WR002292.
Nychka et al (2000)-manuscript is here (pdf).
Why they didn’t use Mann’s robust noise parameter estimation ?
Mann, M.E., Lees. J., Robust Estimation of Background Noise and Signal Detection in Climatic Time Series, Climatic Change, 33, 409-445, 1996. http://www.meteo.psu.edu/~mann/Mann/articles/articles.html
Noise persistence of those data sets seem to be unphysically long 🙂
#10. Google really is amazing for finding things, isn’t it? Nothing turns up for Nychka 2000 except the citation to the unpublished manuscript in the 2007 article, which gives a name, which then finds it on Citeseer. With the name in hand, the manuscript is listed as Technical Report at UCAR, but the link there is dead.
Even though it hasn’t appeared in the vaunted peer reviewed literature, Nychka et al 2000 seems like a pretty sensible article – I wonder why it didn’t go forward. So far I can’t find how the formula presented in Nychka et al 2000 is used in Santer et al 2008 or where the minus-2 tweak in the Santer adjustment is justified in Nychka et al 2000 (but I’ve just started on this and am reading as I post this.)
The other interesting question from all of this – and it’s a fairly large question to say the least – is that all these experiments are being done on synthetic AR1 series and conclusions from these simulations seem to be presented in a less nuanced fashion than I’d prefer. For example, I know from US tree ring data, that it is decidedly not AR1, such series are almost always ARMA(1,1) to very high significance and the AR1 component is typically much (often hugely) higher in such a model – whether that’s because of forcing or “noise” is a thorny problem. But if the noise were ARMA(1,1) of this type and it were simulated through AR1 estimates, the AR1 based simulations are not necessarily very helpful and that doesn’t seem to be made clear.
Why am I not surprised. The expression in the second curly brackets should be less than b sub m greater than. That is, the standard deviation of the observation is equal to the standard deviation of the model.
I made this statement on the Santer et al thread but Santer should not be using autocorrelation on measured data. They are trying to fit a linear trend that cannot be assumed. They should average measured data sets and provide errors but the variation that is observed will be a real observation (depending on the data set integrity/modelling issues of RSS as Steve mentioned before). This on the face of it is a more complicated function. If one were to assume in nature there exists an intrinsic variation (which has been captured by measurement) then the model outputs should converge to this actual data trend. Now there may be an offset but the variation with time is the same. Then its a matter of addressing why there is an offset etc.
So on the face of it the structure to the ENSO observations should in the first iteration be taken as fact. This means that you are not describing a linear trend but considering the difference of two points over a fixed time interval after the process has completed. Discussion of degrees/decade is meaningless as it implies that between these two points you can assign a value which you can’t.
As for the models they assume that there is a ym = phi_m + noise meaning and that the long term trend is to reduce to a linear time-independent function (autocorrelation effects should disappear as the ENSO noise should reduce. This is as stated in posts above). So in essence what you have is the intersection of a linear trend over the period with a higher order variation (real data) at two points (Jan 1979 and Dec 1999). Clearly they are not the same thing. In mathematical terms you have two separate convergences not the same function. Convergence to the same function is only possible if you adequately model the ENSO trend.
Effort then should be made to model the ENSO trend.
Re: MC (#22),
I don’t think so. You can’t assume that if the climate is chaotic, which seems likely. There may be one or multiple attractors, but the probability that any realization is identical to any attractor is vanishingly small. The apples don’t just appear to differ because of measurement error, they are in fact not identical.
Re: DeWitt Payne (#23), Ok I agree that the climate could be an attractor of which we do not have sufficient information on and so cannot predict the future. What we can say though is that in these papers the models AND nature are assumed to attract to a straight line as they do not model the ENSO. Furthermore the models are thought to represent variations within the actual allowed variations of nature, hence the belief that the averaging of many models tends to what is present in nature. This is incorrect as the processes of the weather must form at least a finite and unique set of values which is a smaller subset of random variations. Otherwise there would be no patterns to the weather and there would be no chaotic variation either. It automatically follows then the probability of a model output being one of these sets at random reduces and hence some bounding of the model variation needs to be made. This bounding will lead to convergence of model to nature. At the moment they are trying to fit nature to model.
The assumption is that y(m) = phi(m) + noise(m) and in the limit as m tends to infintity y(m) becomes phi(m) which in the Santer paper is a straight line. With this they then go on to show that there is large autocorrelation in the measured data and that with a linear trend regression there are very large confidence intervals. They have just proved the autocorrelation theory that’s all but the ‘hidden’ variation that is typical of autocorrelation is plain to see. Its the non-linear variation as measured. They have forced a linear trend on the data because this is the limit of the models.
But they do not go onto to state the obvious that the models at the moment, being only capable of producing linear trends are inadequate at matching observation with any substantial confidence (80% or more would be good). They say yes they match (in essence ‘what are you all harping on about’). They have however made a bad assumption at the start. This paper should be about why current models are limited and what is needed to improve them, which should result in a better correlation of model to measured data, not to a linear trend.
#22. I agree with your point. The trend residuals have much in common with the ENSO index (Tahiti minus Darwin.)
Here’s an interesting difference: the trend residuals are AR1=.87 with a highly insignificant MA1 coefficient. However, the ENSO index has a very significant MA1 term. Modeled as AR1 only, the AR1 coefficient is a big under-estimate of the “true” coefficient. The arima fit is AR1=.87, MA1 = -0.44, a point that I discussed a couple of years ago in connection with spurious regression, as Perron observed problems in this sort of structure in econometrics problems.
The AR1 coefficients of the two series are extremely close, but there’s a big difference in the MA1 term. Presumably there’s a connection of some sort.
Steve, #4, writes,
1.72 is the 1-tailed critical value. With 21.3 DOF, the 2-tailed critical value for a 2-sided 95% confidence interval is 2.08 (the .975 quantile of the distribution). Wouldn’t a 2-sided test be appropriate here, since there is no a priori reason to think that the trend, if any, is up?
I would have thought that there was an a priori reason to think so since that is what’s being argued about? But in any event, the 90% two-sided would be more or less the same.
I like to try things for myself, using other software. The correction recipe Neff = Ni * (1-r)/(1+r), presumably is used to modify the confidence intervals for estimation of uncertainties in a standard linear regression, effectively deflating the DF. (If I’m writing nonsense /please/ tell me! )
A difficulty I encounter is in calculating r1 – which I understand to be the 1st order autocorrelation coefficient of the residuals from the linear regression – /when the times series under examination contains Missing Values/ , something that is very common in real world temperature series. For example, if one looks at data for coastal Greenland it is common for data from the depths of winter to be missing. The possible reason for this is that it was too cold for anyone to make the necessary observations, and who can castigate them for that?. What happens is that there is often /NO/ data with values below -20C, merely missing values. How can I compute a reasonable value for r1 under these circumstances?
What should I do? Just infill -20 or -21, attempt ML estimates with censored values, or just apply myself to something else entirely 😉
Advice solicited by
Robin
Steve and Lucia, excellent work. However, I’m confused here. The formula y’all are associating with Nychka is
.
Neff = N * (1-r)/(1+r)
.
where “r” is the lag(1) autocorrelation.
However, that’s not the formula I find here, where they say:
So … if you are going to use the “Nychka method”, I’d think you need to include the 0.68 term. Otherwise, you are using Mitchell’s method.
What am I missing here?
w.
I’m merely trying to replicate their method by results than I can prove – rather than what they say that they did. I can replicate their results with the minus-2. Although they cite Nychka, they don’t actually say that they used it. They rely on Nychka’s findings as a form of reassurance. Neither does it appear to be precisely Mitchell’s method because of the minus-two – assuming that this is a point of difference with the Mitchell method (which it may or not be, or which may depend on the implementation). IF it’s a variation, the net CI is a little wider than pure Mitchell and narrower than Nychka, which is very pronounced in AR ranges as high as these.
Kenneth, you’re over-influenced by beaker’s exegesis of Santer. Regardless of what people think that Santer did, I can precisely replicate Santer Table 1 and Table 3 on the basis that the only difference between them and Douglass is the inclusion of term of uncertainty in the observations. So this part of the discussion is settled.
The beaker stuff is interesting but completely irrelevant to differences as between Santer and Douglass. Maybe that’s what they should have done, maybe it would be a better approach, but it isn’t what they actually did. It’s possible that some of the Santer authors had a difference concept of what was in the article – Gavin Schmidt’s presentation is along the lines of beaker’s and this has dominated exegesis. But facts are facts. The form of calculation has been settled by replicating Table 1 and Table 3 results – we now know what they did, no need to speculate any more.
Steve, thanks for the answer. Did you try it with the actual Nychka method (including the 0.68 term) to see how that came out?
w.
#37. At the high AR1 coefficients, the intervals are very wide and much wider than I got using profile likelihoods. I haven’t incorporated these calcs into graphics yet. I wonder what the Nychka method yields when applied to trend significance (e.g. the calcs in IPC AR4 chapter 3.) Nychka et al 2000, which is a very useful and practical article, gives an adverse report on max likelihood results in terms of performance – so they don’t appear to be a magic bullet.
In the case of real measurements of the real Earth, it appears that Santer et al. assumes that the measurement variance is much larger than the population variance so the contribution from the population variance to the total variance can be ignored.
#39. Keep in mind that both Santer and Douglass do the same thing other than an error term for observations. So let me re-state your image to perhaps correspond more precisely to the actual procedures, as opposed to what people think the procedures should be:
You observe:
Fair enough. As you and beaker clearly observe, a sensible test would not have the properties of the Douglass test.
But in my example, the only reason why the Santer test appears to have improved properties is that the hurdle of the Douglass test is avoided by blurring the measurement. They argue in effect – the measurement is so imprecise that maybe we hit the bullseye.
But is Santer correcting what you believe to be wrong? He goes along with the Douglass test in the part that you dislike (the overly small bullseye), but then says that the measurement of the individual apple is so poor that you can’t say that we didn’t hit the bullseye. That’s a different issue. And in that case, you’d turn your attention to using all possible information on the individual apple e.g. up-to-date measurements, but this they didn’t do.
Re: Steve McIntyre (#41),
No. They’re finessing it by apparently assuming that the within sample (individual realization) measurement variance is much larger than the between sample variance so the between sample variance can be ignored. That’s fine as long as it’s true, but it will be wrong in the limit of perfect measurement or a long enough time span to reduce the within sample variance to a value comparable to or less than the between sample variance. In fact, as you point out, they have, for whatever reason, restricted the observational data set in a way that maximizes the measurement variance.
Re: lucia (#52),
Yes. I think that’s what I was trying to say.
In a lighter vein, if you don’t like parallel universes, how about a Hitchhiker’s Guide to the Galaxy version? Say the Magratheans built a lot of Earths instead of just one to calculate the great question of life, the universe and everything to which the answer is 42.
Re: DeWitt Payne (#53),
Worse, Santer et al. will likely, as the limit of perfect model and measurement is approached, overestimate the variability of bo because the residuals may not be just noise, as was pointed out by MC above.
#42. you have to start by figuring out what they did, as opposed to what people e.g. beaker think that they did because that’s how he would have done it.
#42. Again, Kenneth, you have to watch what they do. Look at the first term under the root sign in equation 12 and compare to the definition of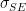 in equation 10 – the terms are identical. If use of
in equation 10 – the terms are identical. If use of 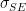 is “incorrect”, then why did they use it in equation 12 (albeit in disguise as it were)? Their only practical difference, as I’ve said over and over, is the second term under the root sign for observation variability – nothing to do with the beaker point.
is “incorrect”, then why did they use it in equation 12 (albeit in disguise as it were)? Their only practical difference, as I’ve said over and over, is the second term under the root sign for observation variability – nothing to do with the beaker point.
Re: Steve McIntyre (#44),
I went back and carefully read again the Santer et al. comments and looking for nuanced meanings that would have lead me to believe that Santer was doing a modification of Douglass SEM approach, but not agreeing with the basic concept of using the SEM and this time I have to agree with you, Steve M.
Santer uses Stdev for his statistical comparison of observed and versus individual modeled results, but unless the Santer authors come back with a claim that they were only using the modified Douglass approach to show that the Douglass approach with SEM, while wrong, will not show a significant difference if modified per Santer, then indeed Beaker was incorrect in his conjecture on the use of stdev and not SEM to compare the means (and so evidently was Gavin Schmidt’s explanation, although I suspect he will be able to ex post explain why he was right). Also if Santer et al. is serious about equation 12 and the simple use of the stdev of the observed results to modify the SEM approach then Beaker’s conjecture on the unknown content of a single realization of earth’s many possible climates seems incompatible with the Santer et al. approach — as the stdev of observed results is knowable.
All I can say is bad Beaker bad and bad Kenneth bad for assuming that the statement by Santer et al. in not using the SEM approach should have been taken at face value. Having said that I continue to think that Santer et al. is deficient in its approach and that we should look for a more comprehensive approaches that avoid the averaging of model (or observed) results altogether as for example the Ross McKitrick suggested approach.
Re: Kenneth Fritsch (#45),
Don’t be so hard on yourself, Kenneth. I still contend that there is a distinct possibility that some of the co-authors of the Santer paper don’t understand certain aspects of the statistical testing, and that it was poorly proofed. You can hardly be faulted for making the same mistake as a co-author!
Dan Hughes (#13),
As usual we are in agreement. 🙂
There is no accurate numerical model of the atmosphere and there never will be. I have pointed out that the convective adjustment process is an attempt to keep a large scale (hydrostatic) numerical model from developing small scales of motion. Once that is done, all numerical analysis theory goes out the window. In fact the hydrostatic system is ill posed and the nonhydrostatic system has fast exponential growth, so there will never be an accurate model of the atmosphere (a convergent model in the terms of numerical analysis).
Jerry
Let’s step back a bit, take a breath of fresh air, and ask a few simple questions:
(1) Can it be stated with reasonable confidence that atmospheric temperature trends have flattened over the last ten years?
(2) As measured in ppm content within the atmosphere, can it be stated with reasonable confidence that CO2 growth trends over the last ten years have at least matched pre-1998 growth trends?
(3) Assuming the answers to both questions are yes, can it also be stated with reasonable confidence that the appearance of a flattening trend in atmospheric temperatures remains consistent with a climatic system that is postulated to be highly sensitive to a steadily rising trend in CO2 content?
If the answer to all three questions is yes, then where do we stand in terms of making some kind of rational sense of the Santer-Douglass debate?
Steve: (1) With high AR1 “noise”, a system with an underlying trend can flatten out for a while. Given the high AR1 features that actually exist, one cannot say that any underlying trends has flattened out. (2) Yes. (3) Answer to both questions is not yes.
I’ve thought some more on this and think that I’ve finally got myself to understanding the issue in the sort of practical way that I need to reduce a problem to in order to think that I understand it.
Let’s simplify by supposing that we had 49 runs from the same model, which yielded a trend plus high AR1 “turbulence” – let’s call it that, rather than “noise”. As we get more runs, we can specify the mean performance of the model with increasing certainty – all parties agree on that. Let’s pick a simple statistic to apply to a given run – the OLS trend. We can calculate the OLS trend of a given run exactly and obtain a distribution of OLS trends. Let’s say that the distribution of OLS trends is more or less normal. We can “model” the models as themselves being the target with a closely defined center deadeye bullseye and an outer bullseye (2 sd).
If I adopt this viewpoint, then I can do useful simulations – and, as an approach, if someone writes word essays about parallel universes that do not give me anything that I can simulate, my eyes glaze over. But in the above approach, you can “model” the models by adding high AR1 noise to given trends and see what happens. Maybe that’s what’s missing here.
Now to the observations. Our metric from the model runs is OLS trend – a simple humdrum statistic. So we do the same calculation on observations. Now Santer says – well, you’ve got lots of AR1 noise in the observed record and this could be consistent with a wide range of “true” trends. We say – so what? We’ve already allowed for that in our simulations by creating a distribution of OLS trends from our models.
Instead of drawing a big circle around the observed OLS trend and seeing whether the ensemble mean trend falls within the observed OLS trend, we do the opposite, we draw a circle around the ensemble mean trend and see whether the observed OLS trend is within the circle. What you can’t do IMO is draw big circles around both the target ensemble mean trend and the observed OLS trend and draw comfort if there’s a small zone of overlap.
I’ve done simulations to implement this and will report on this. As it happens, in this particular case, by chance, the observed OLS trend inclusive of up to date information is outside the 97.5% percentile.
But, as others have observed, I don’t entirely understand why the divergence has to get this far off the rails before people feel obliged to pay attention to it. If you were running a chemical plant, you wouldn’t wait until things diverged this badly.
The problem for modelers is, of course, that the dispute between UAH and RSS remains unresolved after over a decade. If the UAH observations are the valid ones, then surely the bias in the models has to be dealt with. If RSS is right, then it’s not an issue.
IMO it is absolutely ludicrous that modelers should be held up while RSS and UAH battle one another for decades without resolution. IF I were running the shop, I’d hire an independent engineering firm to wade through the parameterizations and provide an engineering-type report so that third parties relying on the data could govern themselves accordingly.
Re: Steve McIntyre (#56),
Since making some missteps in my comprehenson of Santer et al. I have been going back and rereading the paper in baby steps. In doing so I believe I understand your approach outlined in your post to be essentially that used by Santer, for hypothesis H1, with the exception of your consideration that one needs only to account for OLS noise once.
I believe I have read your opinion of the radio sonde data in previous posts, but that certainly is another source of data for comparison and has the additional value of allowing comparisons over the entire altitude range. The MSU data sources have the limitation of doing an “averaging” over the altitude range and that could potentially lead to a problem/situation that the Santer authors reveal: the tropsphere to surface temperature trends averaged over the entire globe agree well – which, of course would tend to diffuse the tropics issue.
Also the “improved compatibility” of the surface to troposphere temperature trends in the tropics is owed by the Santer authors to the 4 newer data adjustment data sets of radio sonde measurements that they added to their paper over what Douglass et al. had shown. Having said that they seemed to concentrate nearly exclusively on the MSU measurements.
When one compares the curve shapes of these “more compatible” (because of their higher tropsphere temperature trends in parts of the altitude range) radio sonde measurement adjustments to the curve shape of the average model results over the entire altitude range one can only gasp.
Re: Steve McIntyre (#56),
Steve – a couple of thoughts come to mind. First of all, are your simulations based on trend + AR(1) noise? Or are you simulating an AR(1) process with trend + white noise?
Second, I realize the interest in all parties on focusing on trends; it is afterall the most “politically” relevant statistic that can be easily related to a mass audience. But wouldn’t in be better to focus on the best model for your simulation rather than one that is expedient, at least to see what the results are? You’ve mentioned before an ARMA(1,1) process, and you could easily adapt your simulation approach to build confidence regions around the parameter estimates for that type of model as well.
Not that I’m trying to assign you work or anything…just a thought.:)
Let’s see if I understand the recent discussions here and elsewhere.
First some scientists devise a system of continuous equations that are some kind of approximate description of the transient response of the Climate of Earth. For the most part these equations are buried away in an opaque Black Box.
Then these same scientists devise some numerical methods to solve the equation systems they devised above. For the most part these methods are wrapped around the Black Box above and then together put into another Black Box.
Next the scientists produce computer codes that ‘solve’ the numerical methods devised in the previous step. And in a similar fashion, the previous Black Boxes get stuffed into yet another Black Box. It’s getting really hard to know exactly what’s in these boxes. We do know, however, that the ‘solution’ methods have yet to provide numbers that are independent of the discrete approximations to the continuous equations.
Then we gather up a bunch of these Black Boxes having essentially unknown contents and pair therm with a bunch of application methods and users. And by the way the application methods and users are as equally opaque as the Black Boxes that they put to furiously calculating.
The above system comes up with a bunch of calculated numbers by various unknown combinations of the Black Boxes, application methods, and users. It is not reported how or why the particular bunch of numbers is chosen to be representative of the transient response of the Climate of Earth. Additionally we aren’t completely sure if the numbers represent predictions, or projections, or what-ifs, or estimates of the future response of Earth. But hey, we got a bunch of numbers so let’s do something with them.
We observe that both the bunch of calculated numbers and the ‘data’ have wiggles imposed onto a general trend. Based on no demonstrated information at all, we assume that the wiggles in the calculated numbers arise solely from the models of physical phenomena and processes contained in the Black Boxes. And we assume that the calculated wiggles are realistic representations of the actual Climate of Earth.
Plus, while we are looking at temporal and spatial scales that are Climate we call the calculated wiggles weather noise or turbulence. Forgetting that what we’re looking at is already one humongous average; it’s the scale of the planet for an entire year, for gosh sakes. Even as the know that the Black Boxes do not attempt to resolve weather. And even more we know that the Black Boxes have yet to accurately/correctly resolve any physical phenomena and processes. And finally even more, we know that the more important physical phenomena and processes relative to Climate are not described from first principles.
It is well known for close to a hundred years that any of the first four steps listed above in the procedures are all equally capable of producing wiggles in calculated numbers that are solely due to problems in those steps. These wiggles have nothing whatsoever to do with any physical phenomena and processes. No investigations are conducted to determine the actual source(s) of the wiggles in the calculated numbers.
Right off the bat we can plainly see that the Black Box calculated numbers don’t look anything like the data. Let me repeat that. We can plainly see that the Black Box calculated numbers don’t look anything like the data. The Black Boxes cannot yet reproduce the transient response of even planet-wide average quantities.
Now we are having discussions about how the bunch of calculated numbers “compares” with the “measured” response of Earth. It turns out that we aren’t sure how to make the comparisons. And some methods allow for the possibility that the more that the bunch of calculated numbers deviates from ‘data’ the more consistent the bunch of numbers becomes.
Plus we also know that the measured data have in fact been processed through a system similar to that described above. The reported data are in fact results of processing the actual measurements by other opaque Black Box models, solution methods, application methods, and users.
In the process of our discussions we encounter phrases like apples-to-apples.
At this point I wouldn’t stick my hand into the bunch of calculated numbers thinking I would grab an apple.
This is not my Engineering. And I would like to think that it’s not anyone’s Science.
I contend that the very critical and absolutely necessary first step in any comparison exercise is to determine precisely what’s in each and every Black Box before we can even begin to discuss the apples-to-apples issue.
#59. Dan, let’s not get into broader issues of climate models on these threads – let’s stay to the narrow issues of what Santer is doing, as that’s hard enough for now.
#60. ENSO has a definite ARMA(1,1) signature as do many series. Interestingly the MSU data does not have a significant MA1 term, but it’s AR1 term is virtually identical to the AR1 term in the ESNO index modeled as ARMA(1,1). What does this mean? Dunno. I think that AR1 is fine for this analysis, but that’s a bit one-off as IMO it’s assumed far too quickly in most cases.
Re: Steve McIntyre (#61),
ok Steve, I put it over here. Snip the one above at will.
Thanks again for all your hard work. And others, too.
Steve (#9) has identified Nychka, Buchberger, Wigley, Santer, Taylor and Jones, (2000) as NCAR technical paper “Confidence intervals for trend estimates with autocorrelated observations”, and Jean S (#10) has provided a link at http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.33.7829&rep1&type=pdf
This is in fact a very interesting paper, that relates to my own recent research interest on how to compute confidence intervals for OLS parameter estimates when errors are serially correlated. See my “Median Unbiased Estimates of Higher Order Autoregressive Processes…” (2008), at http://www.econ.ohio-state.edu/jhm/papers/MUARM1S.pdf, which extends Don Andrews’ “Exactly Median-Unbiased Estimates of First Order Autoregressive/Unit Root Processes,” Econometrica 1993.
Nychka, … Santer et al (2000) show that both MLE confidence intervals (using MLE estimates of the AR(1) and regression coefficients and then the LR to form CIs as implemented by Steve) and “classical” 95% confidence intervals (adjusting OLS CI’s according to “adjusted sample size” ne = n(1-rhohat)/(1+rhohat), where rhohat is the estimated AR(1) coefficient using the OLS residuals) for a time trend slope coefficient have coverage that falls far far short of 95%, especially when the true rho approaches 1. They also show that either is a lot better than “naive” CI’s that take no account of serial correlation, and that “classical” uniformly outperforms MLE.
They propose an “adjusted” effective sample size adjustment, ne = n*(1-rhohat-.68/sqrt(n))/(1+rhohat+.68/sqrt(n)), that they show has better coverage than even the “classical” CI, This adjustment may not be perfect, but it is at least a far cry better than the Newey-West “HAC” standard errors that are almost universally used to undercorrect for serial correlation in the econometric literature.
Although the 2000 paper should not be the last word on the subject, it still contains a lot of useful information that I think still deserves to be published somewhere.
In fact, the Nychka et al graphs show that the coverage of even their “adjusted” 95% CIs falls well short of 95%, indicating that they have not yet found the right functional form. There probably is no simple true functional form, so that the correct “effective sample size” ne(n, rhohat)should probably just be given as a table lookup of values that happen to give the right coverage, at say 95%. This can be found numerically by simulation. Although it poses some interesting numerical problems of finding, for each n, a continuous function ne(n, rhohat) of the continuous variable rhohat, I don’t think these problems are insurmountable.
I don’t understand all the data issues in the Santer … Nychka et al 2008 IJC paper, but for what it’s worth, they say they correct for serial correlation with the “classical” ne = n*(1-rhohat)/(1+rhohat) formula (their equation (6), rather than with the improved Nycha, … Santer et al 2000 “adjusted formula”. By the admission of no less than 5 of their 17 coauthors, they are therefore substantially undercorrecting for serial correlation. This means that they have too small CI’s, and are overrejecting the hypothesis of equality of trend slopes (as well as of zero trend slopes!).
But what the heck, it’s only …
Andrews’ 1993 approach is to median-unbias the AR(1) coefficient by simulation to obtain rhohatMU, and then to plug this into the classical matrix covariance formula, which is equivalent to using ne = n(1-rhohatMU)/(1+rhohatMU) in large samples. Since the adjustment is nonlinear in rho, mean-unbiasing rhohat will not median unbias the adjustment. Nevertheless, median-unbiasing rhohat will yield median-unbiased monotonic functions of rhohat.
This isn’t quite as precise as correcing the coverage directly, as Nychka, … Sanger et al do. However, precisely correcting say 95% CIs will in general not quite correct say the 99% or 90% CIs. A perfect adjustment would simply replace the traditional Student t tables with alternative critical values that are multiples of the OLS SE’s that depend on both sample size and critical value. But correcting the 95% CI as in Nychka, … Sanger et al attempt to do is at least a big step in the right direction.
In my paper, I extend Andrews 1993 to correct for higher order AR processes in the residuals of a general OLS regression. My approach is admittedly probably too cumbersome to ever catch on, but I think it deserves some attention. I’ve just sent it to the JEDC.
The “classical” (1-rhohat)/(1+rhohat) adjustment is, as I believe I recall from discussion on CA last year, due ultimately to Quenouille’s 1952 book. Quaint, but still a lot better than nothing, or Newey-West HAC!
The Lee and Lund Biometrika 2004 paper cited by K Hamed (#11) refers to Nychka et al (2000) extensively, but unfortunately fails to list it in the references, apparently because it was unpublished. I disapprove of this practice — important papers deserve to be cited, even if they are just working papers! (That is to say, many of my own indexed economics citations are to unpublished papers…)
The Matalas and Sankarasubramanian 2003 Water Reseouces Research paper cited by Lucia on her webpage contains further good information. However, I find the Nychka et al 2000 paper to be more useful.
Re: Hu McCulloch (#64),
So what you are saying is that the uncertainty of any warming trend (and alternatively with the possibility of a cooling trend) in the tropics over the past 30 years should be even greater than determined in Santer et al. (2008).
That appears to me to make the proposition that Santer et al. implies, i.e. with warming (AGW) in the tropics, the ratio of troposphere to surface temperature trends should be greater than 1, even more unworkable since the warming part is gravely and statistically in question.
By the way, what would the use of annual data, in place of the monthly used in Santer et al., do to eliminate the need for the AR correction and to the calcualtion of a standard deviation or SEM and/or the use of the differences between the surface and troposphere temperature trends?
Re Ken Fritsch #65,
That’s about right. Santer, Nychka et al (2008) should have paid attention to the excellent (if perhaps not definitive) Nychka, Santer et al (2000)!
Annual data would greatly reduce the nominal sample size, but at the same time would probably greatly reduce the serial correlation, and therefore the need to adjust the effective sample size to be far smaller than the nominal sample size. So you probably wouldn’t lose much by just going to annual data.
Re: Hu McCulloch (#66),
Hu, I looked at using annual data on another thread (linked to my 2 posts below). Annual data did indeed decrease the all important adjusted trend standard deviation. It appears to me that Santer et al. selected the optimum conditions for obtaining a large trend standard deviation by choosing the monthly over the annual data and the 1979-1999 time period over the 1979-2007 (or at least to 1979-2006) time period.
I am also looking at the monthly data for the globe and zonal regions of the globe for determining the adjusted trend standard deviation and thus far it appears that the tropics zone is rather unique in having the AR1 correlation sufficiently large so as to have a large influence on the resulting trend standard deviation adjustment.
Re: Kenneth Fritsch (#30), Re: Kenneth Fritsch (#32),
On your post Oct 22 2008 Replicating Santer Tables 1 and 3
Trying to duplicate your numbers but I cannot get the data.
http://data.climateaudit.org/data/models/santer_2008_table1
http://data.climateaudit.org/scripts/spaghetti/msu.glb.txt
Not on your site anymore. Could you send the second file (I can always type the first) to the email address above.
Thanks
Georges
[RomanM: The site has been rearranged. Try using
http://www.climateaudit.info/data/ as a starting point for data
and
http://www.climateaudit.info/scripts/ for scripts.
For example look at: http://www.climateaudit.info/data/models/ for the Santer file.
2 Trackbacks
[…] Steve McIntyre established that equation (12) Santer17 (pdf ) does not contain a typo, I decided to apply the […]
[…] Steve McIntyre resolved the first question: Santer used “SE”. This is reported in Replicating Santer Tables 1 and 3. The tables can only be replicated using SE, not SD. This doesn’t help readers who still […]