Quiet blogging lately for a variety of reasons.
In today’s post, I’m going to spend some time parsing RegEM (Truncated Total Least Squares) methodology, in itself hardly a standard technique, but particularly quirky in the Mann et al 2008 implementation. In the analysis leading up to O’Donnell et al 2010, we ported the Tapio Schneider RegEM algorithm in R, and, in the process, modified and improved the algorithm to extract some important diagnostics, including the extraction of weights in the final step of the process – there’s an interesting backstory on this topic in connection with Mann et al 2009 (Science) but that’s for another day.
“Long Thin” “Infilling”
The “missing” data in a proxy reconstruction is nowhere close to being random – one of the key assumptions in the original RegEM literature. [Note: Pete says in a comment that “missing at random” in Rubin 1977 can encompass this sort of structure. I haven’t parsed Rubin 1977 to see whether this observation is correct, but even if it is, it’s irrelevant to the point of this post. The Schneider setup contemplated that the missing data was irregularly located in rows and columns of the matrix – hence the line by line calculation. In the case at hand, because there is a block matrix structure to the missingness, one can extract the linear algebra as described below.)
The diagram below shows the structure of missing data in the M08 setup – one column (the temperature to be estimated) is “missing”. Like MBH98-99, M08 is set up in “steps”: the proxy matrix in a given step is complete. The only thing being “infilled” is a long thin column vector of world or hemispheric temperature. This part of the setup is a little simpler than MBH98-99, where the “target” were 1-11 temperature principal components, which were used in turn to estimate hemispheric temperature. (There were major algebraic simplifications to this as discussed in previous CA posts, but that’s a different story.)

Figure 1. Diagram showing “missing” data in M08 setup for a given step.
Interaction of Long Thin with Tapio Schneider Algorithm
The non-randomness of the missing data enables a major simplification of the Tapio Schneider set-up – a simplification which sheds important light on the actual structure of the calculation.
The RegEM algorithm, in the Tapio Schneider implementation, doesn’t “know” in advance which data is missing in a given row and therefore calculates coefficients row-by-row. In the M08 setup for (say) the AD600 step, the same calculation is redundantly calculated row-by-row from AD600 to AD1850, even though it only needs to be done once.
Because there is only one set of coefficients, these coefficients can be interpreted as “weights” – a point previously made at CA on several occasions, including in the commentary on Steig et al and illustrated on maps, a technique employed at CA on a number of occasions.
Importantly, these coefficients can be used to yield estimates (and residuals) in the calibration period. In normal statistics, these estimates (and their residuals) are essential to the estimation of confidence intervals and uncertainty. However, in the M08 setup, Mann’s methodology replaced the estimates/fitted values with smoothed instrumental temperatures, thereby erasing essential statistical information. (Mann notoriously denied that climate scientists ever spliced temperature data with proxy reconstructions, even though this was an integral aspect of M08 RegEM.)
RegEM Notes
Following are technical notes on the individual steps documenting results of my parsing of the methodology, reported here because relatively little is known about the RegEM technique.
First, as indicated in the layout diagram, a complete proxy matrix Y of proxies available in a given step is combined with the target instrumental temperature x (this nomenclature used to remind that proxies are a function of temperature and not the other way round) to make an augmented matrix [Y;x].
In M08, the proxy matrix Y is previously scaled and centered over the entire step. This aspect of the data is not utilized in the M08 implementation of the Schneider algorithm (which re-scales and re-centers at each iteration though this is pointless in respect to the permanently centered and scaled proxy matrix.)
The re-scaling and re-centering of the instrumental column requires some effort to disentangle the net result of the Schneider algorithm in the special case.
In the first iteration (initialization), the instrumental data is centered by subtracting the mean μ_1 of available data (1850-1995) and infilled as 0 in order to have a complete matrix to get started. The instrumental column is then rescaled by dividing by the standard deviation of the column after infilling (σ_1). Since the infilled data is constant, this gives an artificially low standard deviation for this step – a point that I simply notice for now. Using white noise with the standard deviation of the observed data is an obvious alternative, but I have no reason to believe that it would affect the convergence.
This re-scaled and re-centered matrix is then input into a truncated total least squares (TTLS) setup – the algebra of which has been discussed in a previous CA post, but which will be reviewed briefly here. The first step is a singular value decomposition (SVD) of the augmented matrix, denoted in usual nomenclature:
(1)
![[Y,x] = USV^T](https://s0.wp.com/latex.php?latex=%5BY%2Cx%5D+%3D+USV%5ET++&bg=ffffff&fg=000&s=3&c=20201002)
The eigenvector matrix V is used in the TTLS calculation. See previous CA discussion here. Let’s suppose that there are p proxies and one instrumental series in the network. V will therefore have dimension (p+1) x (p+1).
The following two submatrices are extracted from V. 
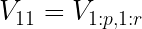


The TTLS coefficients for “x” (the instrumental column) are calculated as follows:

The coefficients are written in this format which is evocative of the algebra used to derive coefficients from other regression techniques. The TTLS estimate for “x” is then calculated in the usual way:

Benchmarking
Some time ago, UC extracted intermediates from Mann’s Matlab code for the nhnhscrihad case, which I’ve used here for benchmarking.
The above algorithm requires prior specification of the regularization parameter r. Specification of this sort of parameter has been a battleground issue in Steig et al 2009 and MBH98-99 (the number of retained principal components). M08 uses yet another procedure. (I’ll discuss this more on another occasion as it is convoluted; in today’s post, I’ll show below that, once again, specification of the regularization parameter can have an enormous impact on results.
Archived results for M08 are splices of individual steps again following a MBH98-99 practice. I’ve shown results here for the AD700 step – a period with some interesting properties previously observed some time ago by Jean S and UC here here, but not explained at the time.
The diagram below shows the first iteration step for the instrumental column (sd units). The starting values are shown in black (smoothed instrumental after 1850, 0 infilled before 1850). Note the extreme sd values of the instrumental target (arising from the smoothing). The first iteration is shown in red. Fitted values are shown in the calibration period (rather than overwriting in M08 style).

Figure 2. First Iteration of M08 RegEM AD700 nhnhscrihad
This is then re-scaled by multiplying by σ_1, the standard deviation of the temperature column in this iteration, and adding back μ_1, with the sum of squares of the residuals to the target calculated for this iteration:


In the next iteration, the missing values in the x=column of the augmented matrix [Y;x] are infilled with values from 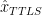
The difference between SSQ values of consecutive steps of the iteration declines. The Schneider (and M08) implementation ends when the difference in SSQ between steps falls below a prespecified tolerance or when a maximum number of iterations (say 500) is reached. The shape of the reconstruction doesn’t change very much after a certain point. My emulation rapidly gets to 4 nines correlation to the M08 intermediate (Matlab). Im not sure
|
Tolerance |
Step |
Correlation |
|
0.01 |
20 |
0.9997107 |
|
0.005 |
28 |
0.9998131 |
|
0.001 |
52 |
0.9998845 |
|
0.0001 |
277 |
0.9999623 |
|
0.00001 |
522 |
0.9999597 |
The reconstruction in the 52nd step is shown below – the difference between the emulation and the M08 intermediate post-1850 attributable to M08 splicing of instrumental data after 1850 with proxy data prior to 1850.

Figure 3. RegEM after 52nd step – AD700 nhnhscrihad
As noted at the outset, the weights can be extracted from each step. The diagram below shows coefficients for steps 1, 21,…, 101 for the nhnhscrihad network (a network that only uses NH proxies that pass “screening”. There are 14 proxies in this network – 4 of which are the Tiljander sediments; one (nv512) is a bristlecone.

Figure 4. Weights (coefficients) for each proxy in AD700 nhnhscrihad network.“
Curiously, the sign of one of the Tiljander proxies is reversed. This is not due to some deep interpretation of the proxies – all are oriented hockey stick up for this implementation – but due to some property of the algorithm, perhaps resulting from the fact that, as AMac has observed, the “four” Tiljander proxies are not linearly independent – there are really only three proxies. As a result, the net weight of the Tiljander proxies in this network (regpar=2) is negligible. The most heavily weighted proxies are two Curtis sediment proxies (with strong MWP) – thus the strong MWP relative to reconstructions more dominated by bristlecones.
Changing the regpar parameter
As noted by UC and Jean S some time ago, there is a major discontinuity in the nhnhscrihad reconstruction at AD600. The reason is that, at AD600, the Greenland O18 isotope record is added to the network. While there’s nothing particularly notable about the isotope series, its addition changes the regularization parameter from 1 in the AD500 step and earlier to 2 for AD600 and later. To illustrate the effect of regpar=1 as apples-and-apples as possible, I’ve recalculated the AD700 reconstruction shown here using regpar=1 instead of regpar=2 illustrated above.
The difference between the two reconstructions is shown in the diagram below – black – the M08 intermediate, red – using regpar=1. At regpar=1, the reconstruction is a classic hockey stick, while at regpar=2, the reconstruction has an MWP.

Figure 5. AD700 nhnhscrihad with regpar=1 compared to M08 intermediate (black)
The next figure was posted up by UC here – it shows the M08 post-stepwise spliced reconstruction. The changeover from regpar=1 to regpar=2 is shown quite clearly with the discontinuity at AD600. Needless to say, the two inconsistent reconstructions are both said to be accurate within close Mannian confidence intervals.

The weights (coefficients) for the different proxies for regpar=1 are entirely different than for regpar=2, as shown below. The four Tiljander proxies are heavily weighted, as is the nv512 bristlecone series. The two Curtis sediment proxies and the Dongge speleothem are flipped upside down from the other case.

The differences are shown on a world map below.






47 Comments
“Missing At Random” (MAR) has a precise meaning in statistics, and that meaning is somewhat different from the plain English meaning. The plain English interpretation is described as “Missing Completely At Random” (MCAR).
Schneider’s paper assumes MAR, which is correct in this case, since missingness depends on time but not on temperature.
But due to AGW we observe only values that are very high. The missing values cannot be as high because there was no AGW in the past. If anthropogenic temperature changes are negligible, then Mann’s calibration method is OK.
From “Statistical Analysis with Missing Data 2nd ed” (Little and Rubin):
In this case age corresponds to year, and income to temperature. The temperature for 1051 will be missing with p=1 whether that temperature was 30C or -10C. Likewise, the temperature for 1951 is missing with p=0, no matter what value that temperature takes.
The data are MAR. Your argument only shows that they are not MCAR. Note that Schneider assumes MAR for RegEM, not MCAR.
I was more thinking this as a calibration exercise: if the missing values and observed values together form a random sample from a population then the procedure is quite clear. But then AGW assumption does not hold.
But Schneider puts it this way:
In the Mann08 case, are the correlations between anthropogenic temperature changes and the availability of data negligible ?
Obviously the correlations are not negligible, and therefore you cannot assume MCAR.
However, RegEM assumes MAR, not MCAR.
The Schneider quote is awkwardly phrased. “Correlations” should really be “conditional correlations”. If there are more missing values close to the North Pole, then missingness will be correlated with AGW. But as long as missingness is uncorrelated with AGW for any given latitude the data are still MAR.
Steve: you’re missing fundamental issues. Whether the missing data is MAR or MCAR, the structure of the setup means that unthinking application of the Schneider algorithm – as apparently done in M08 – results in millions of pointless calculations. That in itself is just inefficiency. However, it has a more insidious result (which occurs either in the Schneider algortihm or Mann implementatino ) – the overwriting of estimates in the instrumental period with instrumental values : the splice that Mann says never occurs.
In addition, the instability of results to regpar parameters shows once again the fundamental non-robustness of the data.
I was under the impression that “key assumptions” counted as “fundamental issues”.
Are you conceding the issue, or just avoiding it?
Steve – Mannian articles always raise interesting issues of statistical pathology that are not contemplated in the underlying literature. That proxy weights are sensitive to regpar is an amusing pathology.
I’ll take that to mean “avoiding”.
Steve: the data are not missing at random – in the sense that the location of missing data in the proxy matrix is strongly structured. This is self-evidently true and, from this, there are certain corollaries. The issue of whether the data is “MCAR” is different and wasn’t the point that I was addressing here.
The statistical references that you have in mind do not contemplate the pathologioes arising from the inconsistency between proxies that characterizes Mannian networks.
This is pea under the thimble stuff. You referred to a “key assumption” in RegEM: that the data were “missing at random”, as defined by Donald Rubin. Now you say that the data are not “missing at random” according to your own definition. That’s technically true; according to your own definition the data are not “missing at random”. But that’s completely irrelevant, since your definition is not the one used by Schneider and is not the standard definition used by statisticians. There may be “certain corollaries” from the fact that the data are not missing at random by your own ad-hoc definition, but “the assumptions behind RegEM don’t hold” is not one of them.
Steve: when you use quotations marks, you represent that you’re quoting. The phrase
“the assumptions behind RegEM don’t hold” is not used in my post or comments. The purpose of observing the non-randomness of the structure was to establish that the Schneider algorithm contemplated a setup far different than the one observed here.
In the M08 setup, the linear algebra can be extracted and weights calculated directly. It shows that there is no legitimate reason for overwriting proxy reconstructions data with temperature data as in the M08 setup.
I’d be surprised if this sort of setup is contemplated in Rubin. However, since this wasn’t at issue in the post, for greater certainty, I am not commenting on this aspect of this issue. The points raised in this post are important in their own right
Quotes are also used to indicate the use-mention distinction. The proposition was an accurate paraphrase of this:
Your implication that the Mann08 setup violates the assumptions behind RegEM remains false. The setup is quite clearly “missing at random” in the statistical sence — in fact, your Figure 1 is essentially the same as Figure 1.1a in Little and Rubin.
If your mistake is not central to your point, then why not just fix the error?
Maybe because it is not a mistake.
Suppose that we wanted to estimate the mean annual temperature at a weather station for the last 1000 years. I take an annual average from that station for each of those years and end up with a data set consisting of 900 missing values followed by the 100 available observed values for that station. According to your zero-one conditional probability argument, this sample is classified as MAR so that it should be possible to calculate a valid estimate of the mean annual temperature using only the observed values without further assumptions or information about the unobserved values. Do you agree?
Furthermore, in the example you give in the same comment, it is not correct to say that “In this case age corresponds to year, and income to temperature”. In fact, age corresponds to proxy which is used in the RegEM procedure along with temperature. Year does not play a direct role in that analysis as a separate variable.
What is important for RegEM is the relationship between proxy and temperature. The problem with year defining the mechanism for creating missing values is that the resulting dataset will be MNAR unless one makes an assumption that that relationship does not change in time (uniformitarian principle) or that the structure for any possible changes is known. In effect, the observed data are NOT sufficient and a model is needed to carry out a proper analysis.
[RomanM: Please note that I have corrected a typo in my comment after posting it. I inserted the word “not” in the phrase “Year does not play …”]
No, the data would need to be MCAR for that to work. MCAR is a much stronger assumption than MAR. Unfortunately, when non-statisticians hear “missing at random”, the intuitive concept they form corresponds more closely to MCAR than MAR.
Nitpick: I think you want Rubin 1976, not 1977. Although Little and Rubin 2004 would probably be a better reference.
Nitpick 2: Some of your VOG above hasn’t been bolded, which makes it unclear who’s saying what.
pete,
You seem to be an experienced statistician who could add value to this conversation. Instead of focusing on these nits and minor gotchas, why don’t you comment on Steve’s main assertion that Mann’s procedures result in the overwriting of estimates in the instrumental period with instrumental values. Do you believe this assertion is true, and if so what are the implications?
Steve’s writing style tends to emphasise snark over accuracy and clarity. That makes it a lot harder to engage constructively.
As far as I can tell, the main conclusion in this post is “[nb: paraphrase] if you increase the regularisation in RegEM, you get more regularisation”. I can’t really add anything to that.
The “overwriting” claims are just Orwellian snark. The only things “overwritten” are the NaNs used to indicate missing data.
In fact, what Steve is suggesting is that Mann should have overwritten the instrumental temperatures with temperatures estimated via RegEM. This is actually a good idea! But you can make it sound sinister by using a menacing verb like “overwrite”.
The overwriting is an important point. In conventional statistics, one compares the estimate(fitted) value to observations. The Mannian algorithm does not retrieve the fitted values in the instrumental period. Instead its output is a splice of the estimate in the pre-instrumental period and instrumental values in the instrumental period. Nor does the algorithm retrieve residuals. Analysis of residuals is fundamental to conventional statistics, but precluded in the Mannian algorithm.
In a Climategate email, Mann described the residuals from MBH98-99 as his “dirty laundry”. Perhaps this aspect of the M08 is an attempt to deal with this “problem”.
Comparing calibration period estimates to observations is an important point. But you obscure that point by pretending that there’s some sort of “overwriting” going on. As I said, snark over accuracy and clarity.
Mann started it 🙂 I think we are progressing anyway. Let me cherry-pick one step from M08, and show the result with your code:
The problem of using calibration method that suffers from ‘loss of variance’ in this context is that they are good tools for generating hockey sticks. Not without help, as flat line is not a hockey stick. But if you somehow combine a flat line with instrumental data (or use various existing smoothing methods, see for example http://www.youtube.com/watch?v=pCgziFNo5Gk ), you’ll get a blade. But due to loss of variance*, we cannot really tell whether this kind of blades have existed in the past. That’s why the accompanying uncertainties need to be well derived and documented (who knows what was done in MBH99?). So there is a reason to worry about combining instrumental to the reconstruction. Worries change to a joyride once the uncertainties are handled correctly.
* Calibration example: ICE result is a matrix weighted average between CCE result and zero (Brown 82), hence the loss of variance. Less accurate proxies, more weight towards zero.
Italics tag should have been closed after “instrumental temperatures”. HTML and I are not getting along well today.
Just to clarify: whatever the time series (T, Nx1) to be estimated is,
I enter the incomplete data matrix (Y=[ T P ], Nx(p+1) ) to RegEM, where P are the proxies. Then, for the following cases (n less than N):
1) n samples in T are missing completely randomly
2) n samples in T are missing from the middle of the series
3) n samples in T are missing from the end of the series
the results will be similar?
All three cases are MAR; the first is also MCAR. Therefore all three cases would have appropriate missingness structures for RegEM.
That doesn’t mean you’ll get the same results (I assume you’re referring to the imputed values).
For this problem, the much simpler classical calibration (https://climateaudit.org/2007/07/05/multivariate-calibration/ ) works clearly better:
And as we know the process that generated the missing values, we could increase the accuracy further by using that information.
Is this problem with autocorrelation documented somewhere?
Pace of the blogosphere is too fast for me; to summarize
1) pete’s view is that high autocorrelation in the unknown X-series causes problems for RegEM. To me, the problem is not autocorrelation but training sample not being ‘like’ the rest of the data. I’d like to see what are the true underlying assumptions for RegEM to work. MAR vs. MCAR discussion didn’t increase my understanding enough.
2) In my example the classical calibration works much better ( http://www.climateaudit.info/data/uc/cce_regem2.png ), whether one uses pete’s CIs or not. I’d like to know when to switch from CCE to RegEM, do we need to run GCMs before selecting the calibration method?
1911.txt, Osborn:
I guess random walk pseudo-proxies were ruled out. If I get this right, ‘all the error in the proxies’ would lead to CCE ( minimize the errors in the direction they occur, Eisenhart 1939)
But something seems to go wrong with the case 3),
2)


3)
Code in here http://www.climateaudit.info/data/uc/test_regem.txt . Here the case 3) is an example of a situation where the ‘training sample’ is not a representative sample.
Hmm, thanks. As often is the case in climate science ‘novel’ stats are applied to dodgy data and when one delves into it ‘something seems to go wrong’. Which is not acknowledged. But hey, it’s only three years now since Mann08.
Nice UC.
Replication can be difficult when random number generation is involved. Luckily I found an example similar to yours by setting the seed to 2. Other seeds give less pathological cases.
I’ve modified the code a little here, so that you can see the fitted values during the calibration period.
As you can see (fingers crossed, this is my first attempt at posting an image here), the fitted values suffer from “variance loss” in both the reconstruction and the calibration periods. This is the “Reg” part of “RegEM” — if it can’t give you a good estimate, it will give you a small estimate instead (a smaller estimate will often have lower rmse than an unbiased but highly variable estimator).
In this case the combination of low calibration period variance results in a poor estimate. That’s not because any of the assumptions of RegEM are violated; it’s just a very hard case. RegEM is actually doing what it’s meant to do here — it’s telling you “I don’t know the answer”.
Note the too-narrow confidence intervals: the variance estimates are regularised too. This means low-rmse for the variance estimate, but gives us terrible coverage.
Link to image.
So RegEM gives a flat line with too-narrow confidence intervals (reminds me of hockey-sticks), but any assumptions are not violated. But if we interpret the assumptions as I or RomanM above, everything works fine.
The narrow confidence intervals are the result of your use of two-standard-error confidence intervals, which aren’t appropriate in this context.
If you use, for example, bias-corrected CI’s it looks like this.
I specifically said that the missing-at-random assumption is not violated. I wouldn’t be surprised if the very high autocorrelation in your setup causes problems for RegEM.
Would they be appropriate with MCAR assumption? Or, with the assumption that the training sample gives us information about the missing values prior to observing the proxy values?
This is what I’m looking for, can you update the code so I can try it with Mann’s data?
What if we just combine the assumptions (your missing-at-random + Roman’s
it should be possible to calculate a valid estimate of the mean annual temperature using only the observed values without further assumptions or information about the unobserved values.
then we don’t need to worry about high autocorrelation, i.e. add further assumptions?
You can only “calculate a valid estimate of the mean annual temperature using only the observed values without further assumptions or information about the unobserved values.” if the missing data are MCAR.
Code is still here. Latest revision does ad-hoc bias corrected CIs.
2SE CI’s are only really appropriate when your estimate is unbiased and approximately normal. Even with an MCAR setup they’d be too narrow if you used them with RegEM.
I couldn’t get your code to run in Octave, but I’ll make another attempt in the morning.
Fascinating, instructive, astonishing. Many thanks.
Some data sets have had selective removal of anomalous values from the instrumented period, similar to some treatments of the nugget effect in ore grade estimation. It will not be possible to derive a correct value to insert for a missing value if the correct value has been vanished. Also, assumptions about the distribution of such missing values cannot be made if the required a priori information – like cutoff point – has also been vanished. There are even data sets where missing values are more prevalent around Christmas holidays, when the regional temperature is usually close to one extreme or another.
Thus, there are cases where missingness depends on either time or temperature or both.
We seem to be working at a level where the craftiness of past observers in creating plausible synthetic infills is being matched by the skill of those reconstructing after the event. Who will win? In a sense, it matters less by the day, because a good proxy calibration requires a robust temperature change trend and we have not seen much of that for 15 years or so.
As W. Larson noted, a fascinating peek under the hood. I’ll offer a remark on how many impossible things it’s possible to believe before breakfast.
I recently recognized that the four “Tiljander proxies” are in no way four proxies. Actually there are only two. For her 2003 paper, Tiljander and her colleagues measured the thickness of each annual varve. Each year thus has a “thickness” entry in millimeters. Next, these workers measured the X-Ray density of a section cut lenthwise along the drill core and trimmed to 2 mm in thickness. “XRD” is the absorbance of this thickness of varve (dehydrated and epoxy-impregnated) to X-Rays, digitized from scans of exposed X-Ray film. XRD is measured in “absorbance”, a dimensionless unit on a logarithmic scale.
Here is the simple algebraic formula for “lightsum”:
Lightsum = Thickness * XRD * 0.003937
Here is the simple algebraic formula for “darksum”:
Thickness = Lightsum + (( 255/254 ) * Darksum )
For the AD700 segement: Note in Steve’s Fig. 4 that when regpar is set to 2 (because the Greenland dO18 record is used), three of the Tiljander
proxiesseries are weighted positively, while the fourth is weighted negatively.Note that Fig. 5 shows that when regpar = 1, all four of the Tiljander series are weighed postitively.
From the figures, I can’t tell which of the Tiljander series is the “rogue” flipper. But it hardly matters. Given the simple algebraic derivation of lightsum and darksum, this finding is another flashing red light that something is terribly amiss in Mann08’s procedures.
Let’s suppose the flipper is “lightsum.” So: in the Eighth Century, mineral accumulation in a southern Finnish lake correlates positively with increasing temperatures, but only when oxygen isotopes from Greenland glaciers are ignored (regpar = 1). The instant dO18 enters the mind of the paleoclimatologist, mineral accumulation inverts to a negative correlation with temperature.
Preposterous.
IRRC, Tiljander proxies were corrupted in recent periods.This was well known and clearly indicated when the data was published.
The earlier part of the series was to some extent a potentially valid proxy. The later part was garbage and documented to have an inverse trend due recent disturbances in the milieu.
The two parts show opposite correlations to temperature. The overall correlation must be small.
It is easy to see in this context and with the constant shifting of means and reference period how the correlation could flip from -ve to +ve.
If the non disrupted , valid part of the Til. series is used, I see no reason why it would flip.
Any competent scientist would instantly see this as a sign something was badly wrong. Assuming of course said scientist even looked to see what his data mangling was doing and whether it made sense.
P. Solar, your recollection (Oct 17, 2011 at 10:19 AM) on the contamination of the Tiljander data series is correct. Tiljander03 cautioned against using them as a proxy for climate after 1720, due to land-use changes, local road-building, eutrophication of Lake Korttajarvi, and the like. Mann08’s authors recognized this issue; it’s discussed in their SI. Then they used the data as-is through 1985 anyway. (They used RegEM to extrapolate the data through the end of the calibration period in 1995 — a seemingly unjustified step.)
> The earlier part of the series was to some extent a potentially valid proxy.
Tiljander03’s authors thought lightsum, darksum, and XRD were proxies for temperature; they presented plausible arguments to that effect. Your recollections are again right: Mann08 orients darksum consistently with respect to Tiljander03, while lightsum and XRD are used in an upside-down orientation. Mann08’s authors and certain apologists refuse to concede this point, though it is unambiguously true.
My own view is that there is no compelling support for Tiljander03’s notion that lightsum, darksum, or XRD are temperature proxies. There are other, shorter-duration signals from Southern Finland that do appear to be proxies for temperature. For periods of overlap, Tiljander’s candidates correlate poorly with them.
So the Tiljander data series likely have little to say about temperature for the pre-1720 period — and each has a climate-irrelevant post-1850 Hockey Stick upswing attached. This makes it easier to see how they can correlate positively to other data series for 100-year segments of the reconstruction period under certain assumptions, while exhibiting negative correlations if different assumptions are made.
It seems likely that this feature is shared with other low-to-nil-signal temperature “proxies.”
For any particular proxy over the past 100 years (the calibration period) we can know the local temperature history, but this local history need not be consistent with the global temperature history, because local climates can be lagged or anti-phase with global trends. That is, some local records show no trend or even cooling the past 100 yrs. RegEM calibrates that these relations will hold into the past by making the coefficients on such proxies low or negative in relation to the global record of temperature, but this need not be true–that is, a particular locality need not always have the same relation over the past 2000 yrs to global temperature. It is an assumption that is unverified. In my paper (which was too “simple” for the Team to like–and of course got the wrong answer) I used proxies that had been calibrated to local temperature histories–even if they showed cooling over the calibration period the calibration is ok. From these, each proxy could be converted directly to a temperature history and then averaged in some way. Yes, way too simple, but no deep pit of fancy poorly-understood math to fall into. No regularization parameter to give arbitrary answers.
Loehle, C. 2007. A 2000 Year Global Temperature Reconstruction based on Non-Treering Proxy Data. Energy & Environment 18:1049-1058.
Another thing that bothers me is this need to develop reconstructions for different time periods. I understand that proxies do not all go back in time the same distance, but if the different steps (1700, 1600 etc) do not give the same curve in the overlap period this seems to invalidate the entire procedure IMO.
“The above algorithm requires prior specification of the regularization parameter r. Specification of this sort of parameter has been a battleground issue in Steig et al 2009 and MBH98-99 (the number of retained principal components). M08 uses yet another procedure. (I’ll discuss this more on another occasion as it is convoluted; in today’s post, I’ll show below that, once again, specification of the regularization parameter can have an enormous impact on results.”
I can only conjecture that the reason for the lack of sensitivity testing in some of these climate science papers, and particularly the Mann authored ones, is that the authors judge that their papers results are only confirming a more or less foregone conclusion – given the consensus thinking. If, in some cases, such as this one, they had done what one would expect good scientists to do, i.e. report what results are obtained from using different prior specifications when the selection process could be considered arbitrary, I wonder how they would have rationalized their selections.
Steig’s rationalization for his parameter selections on Antarctica warming came across as weak and particularly so in the light of O’Donnell et al 2010. In Steig’s role, as reviewer of O(10) and defender of his paper, he appeared to me at times to be arguing that the “correct” parameter choice had to be the one that warmed West Antarctica the most.
Please pardon me if my comments sometimes come from left field a little.
I’ve read the Mia Tiljander paper a few times. The immediate difficulty is that the sediment record cannot be calibrated against an absolute temperature, because after 1720 – before the thermometer period started – she cautions against use of properties because of disturbance. The best that can be done is to compare periods before 1720 and to speculate that one period might have been relatively hotter or colder than another based on the chosen indices; but it is not possible to put a temperature figure next to the difference in an absolute sense. Therefore, it matters not if data are inverted. It matters that they should not be used at all for quantitative work.
Hitherto, I had been wondering about how proxy calibration would work if the relevant temperature was essentially invariant. If T = a constant, then P = a constant (where P = the property for the proxy). This is not quite a useless situation, because it allows an estimate of noise or extent of confounding variables. Having decided (as did Roy Spencer in a recent paper) that there is more information content at a time of temperature change, I thought that a temperature gradient was a necesssary and sufficient condition on which to base a proxy exercise. On futher thought, I now think that it is necessary but insufficient. One can envisage a monotonic equation T = a*fn(P) + b that fails. Think of tree rings that grow thicker when T is higher, but in a non-linear way, such that growth rate is a function of the difference in temperature from time to time. (e.g. growth after a frigid term is more than growth after a hot term). This is a simplified example to lead to the suggestion that certain proxy calibrations might need to be done on differentials of properties, rather than on the raw properties. It raises matters like feedback and these in turn feed back into the dissection of RegEM here.
Geoff Sherrington (Oct 18, 2011 at 12:14 AM) —
I agree, for the reasons you outline.
Tiljander-in-Mann08 also illustrates a separate pitfall in this regard. To produce multiproxy reconstructions, authors have to select which data series will serve as proxies. The pre-1850 values of some candidate series are modestly affected by temperature, with other known and unknown factors causing most of the observed variation. The pre-1850 values of other candidates are unrelated to temperature. For a member of this latter set, the observed correlation between series values and temperature during the calibration period is spurious (Yule, 1926) with respect to the relationships of series value and temperature during the reconstruction period.
Authors cannot know which candidate proxies fit into which category. If they did know, they’d be able to exclude the spuriously correlated ones.
The effect relying on a calibration period with rising temperatures is that some “junk” series with post-1850 trends that are upward-trending will be accepted into the reconstruction. Other “junk” series with downward-trending ends will be accepted, but in an inverted orientation. To the extent that these curves have a “hockey stick” shape,” both types of series will tend to “push down” the proxy-derived temperature values for the reconstruction period.
If temperatures had been cooling since 1850, such “junk” series would have produced the opposite effect — a too-high set of temperature values for the reconstruction period.
But that’s not the actual situation.
From a geological and physical-geographical view point, the sedimentary record cannot possibly be considered a reasonable proxy of temperature. Sedimentation is a result of the degree to which contributing slopes are subject to erosion. That in turn can be the result of among other things vegetation cover or rainfall changes, or, as in the case of Tiljander, of destabilization due to human activity. These in turn might be proxies of local temperature, which in turn might be a proxy of regional and or global weather patterns.
That makes a sedimentation sequence at best a proxy of a proxy of – possibly – a proxy. Any correlation with an estimate of global temperature at all has a very decent possibility of being entirely accidental. Based upon what we know at present it is quite as reasonable to see the expansion and contraction of human civilization as driven by climate, which inverts the causal argument of AGW, but would offer a much longer correlation period.
John–
For me, at least, very interesting contributions here from you (although possibly OT, but let SM snip away if he so chooses–it’s ok with me). I especially like your idea of “the expansion and contraction of human civilization” as a “proxy” (note the quotation marks there) of temperature variance. Of course there could well be, or is, a temperature component in it, but how could one tease that out? Maybe it could be done to some extent. If it could be done, then, as you said, it offers a much longer proxy record (although you said “correlation period” rather than “proxy record”–I need to be alert that “correlation period” is NOT the same as “calibration period”). Thanks.
I don’t have the time to look under the hood of RegEM so perhaps someone who has can explain how RegEM produces uncertainty estimates (e.g. standard errors) for estimated coefficients and predictions. More missing values = more uncertainty and wider prediction bands. I think this is more interesting than the estimates themselves.
RegEM produces standard errors for predictions from the estimated covariance matrix of the residuals arising from the truncated EOFs. This is scaled up by any >1 inflation factor (normally, however, set just to 1) to allow for other sources of error, and adjusted for lost degrees of freedom. With inflate=1, actual prediction errors are usually substantially above the RegEM estiamte, in my experience.
Ryan O and I have done a lot of work on RegEM and found some mathematical issues with it, particularly the TTLS variant.
More generally, TTLS regression is not a very stable method and predictions using it should be treated with circumspection. Selection of the optimum truncation level is not easy even where there is only one pattern of missingness. One of the greatest experts on TTLS, Prof van Huffel, doesn’t recommend using TTLS to make predictions of unknown values, as opposed to estimating regression coefficients. Ridge regression RegEM, which likewise allows for errors in the predictor as well as predictand variables, is much more stable.