In today’s post, Jean S and I are going to show that the paico reconstruction, as implemented in the present algorithm, is very closely approximated by a weighted average of the proxies, in which the weights are proportional to the number of measurements. Paico is a methodology introduced in Hanhijarvi et al 2013 (pdf here) and applied in PAGES2K (2013). It was discussed in several previous CA posts.
We are able to show this because we noticed that the contributions of each proxy to the final reconstruction can be closely estimated by half the difference between the reconstruction and reconstructions in which each series is flipped over, one by one. This sounds trivial, but it isn’t: the decomposition has some surprising properties. The method would not work for algorithms which ignore knowledge of the orientation of the proxy i.e. ones where it supposedly doesn’t “matter” whether the proxy is used upside down or not. In particular, the standard deviations of the contribution from each proxy vary by an order of magnitude, but in a way that has an interesting explanation. We presume that this decomposition technique is very familiar in other fields. The following post is the result of this joint work.
The Re-assembled Reconstruction
Before showing the decomposition, here is a comparison of the H13 pre-calibration reconstruction and the simple sum of 27 components, each calculated as half the difference between the H13 reconstruction and the reconstruction with each proxy inverted in order. They are not exactly the same (the correlation is 0.998) and the standard deviations are about 5% different.
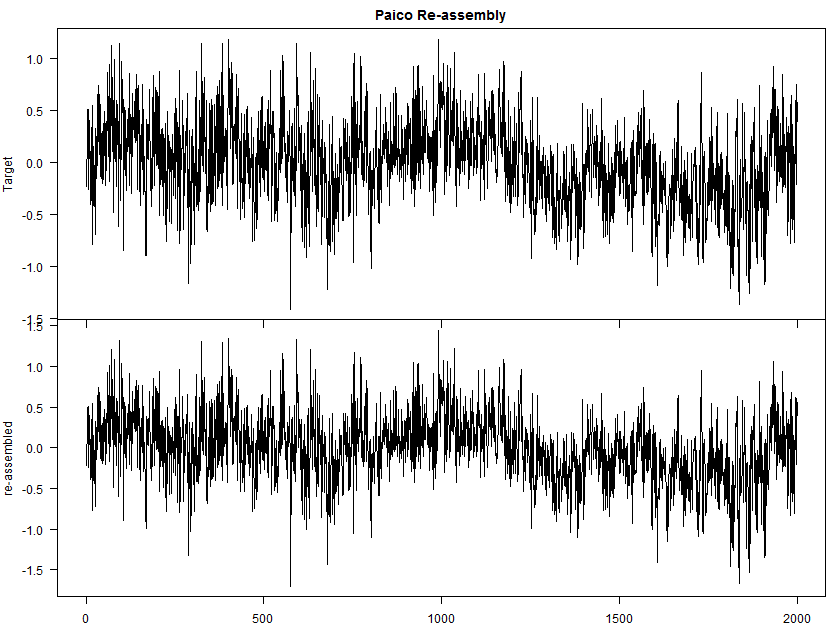
Figure 1. Pre-calibration Hanhijarvi reconstruction and as re-assembled from components.
Standard Deviation of Components
Somewhat unexpectedly (and this appears to be a peculiarity of how Hanhijarvi et al implemented their algorithm), the standard deviation of the components varied by more than an order of magnitude. (These standard deviations are pretty much equivalent to weights, since each component is related to the underlying proxy through a transformation that is “mostly” monotonic. The graph below shows a barplot of the standard deviations of each component in the decomposition.
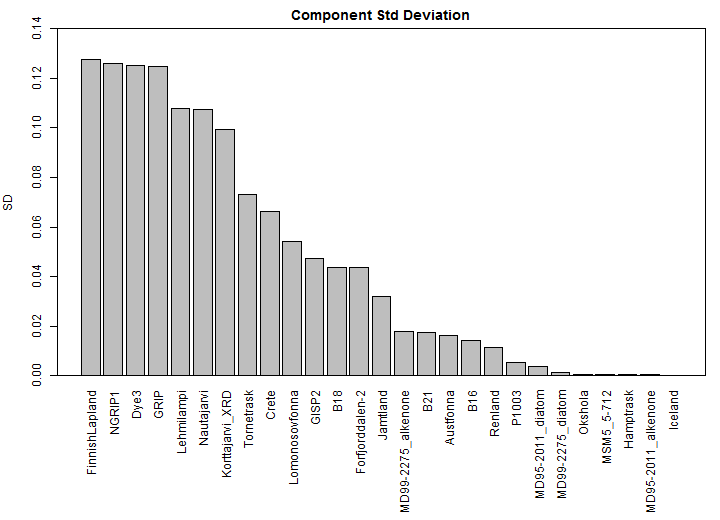
Figure 2. Standard deviation of individual proxy components in decomposition.
The series on the left in FIgure 2 above are the series with the most measurements and the series on the right are the ones with the least. The next figure shows the component standard deviation (weight) against the simple number of measurements for that proxy. The very low weights assigned to low-frequency appears to be a result of how Hanhijarvi et al implemented paico, rather than an intrinsic property of paico. Having said that, having looked at an absurd number of individual proxies over the last number of years, I am disinclined to overweight low-frequency proxies. For present purposes, we are merely diagnosing the properties of an opaque methodology, not recommending a solution. The relationship between weight and count has a slight quadratic shape, but, for practical purposes, the method is closely approximated even by weights calculated as a linear function of proxies.
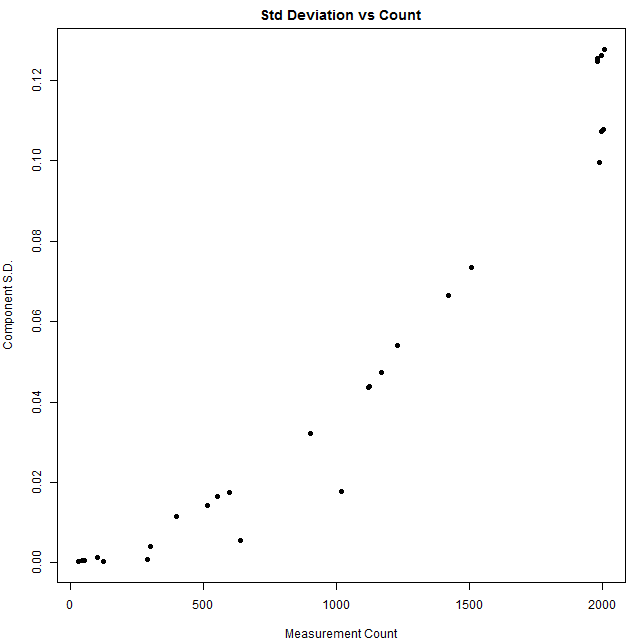
Figure 3. Scatter plot of component standard deviation against number of measurements for each proxy.
Components
The next figure shows an example comparison for a single proxy between the underlying proxy (top panel) and the component calculated as half the difference between the H13 reconstruction and the reconstruction with the inverted proxy. The connection between the component and the underlying series is evident. But just when you’re about to conclude that it is a sort-of damped version of the underlying proxy, it throws off a uniquely low value in 1997. Two other series (Grudd2008, Helama2010) have offsetting high values, so it might be something to do with that.
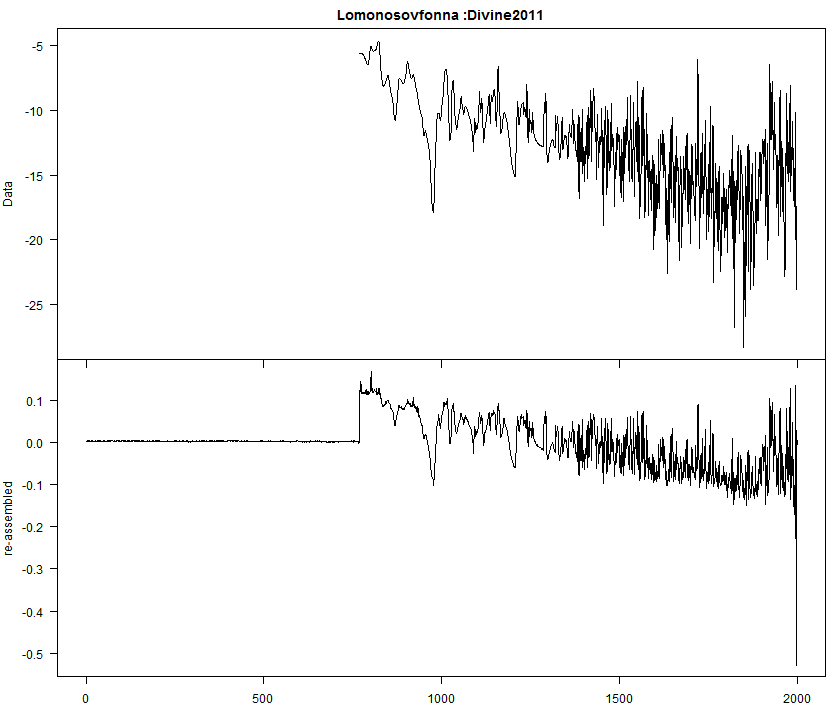 Figure 4. Comparison for a single proxy between the underlying proxy (top panel) and the component calculated as half the difference between the H13 reconstruction and the reconstruction with the inverted proxy.
Figure 4. Comparison for a single proxy between the underlying proxy (top panel) and the component calculated as half the difference between the H13 reconstruction and the reconstruction with the inverted proxy.
The next figure plots the component contribution against the original proxy value for this example. Mostly the component contribution is derived sort-of sigmoidally from the original measurement, but, as noted above, there are some puzzling oddballs.
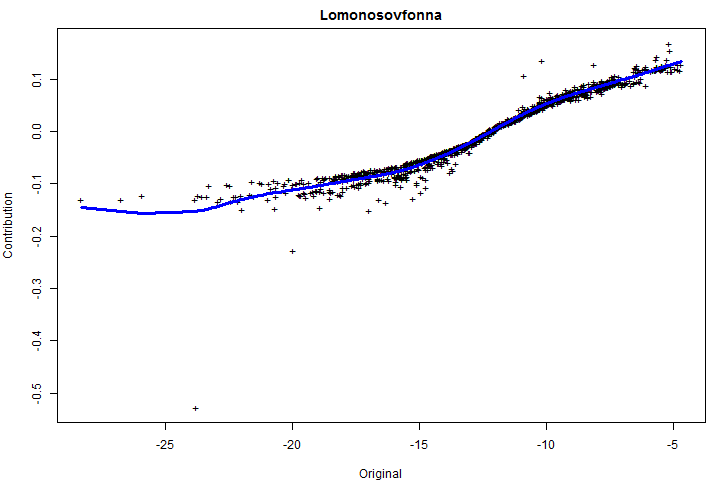 Figure 5. Component contribution against the original proxy value for this example.
Figure 5. Component contribution against the original proxy value for this example.
Approximation by Weighted Average
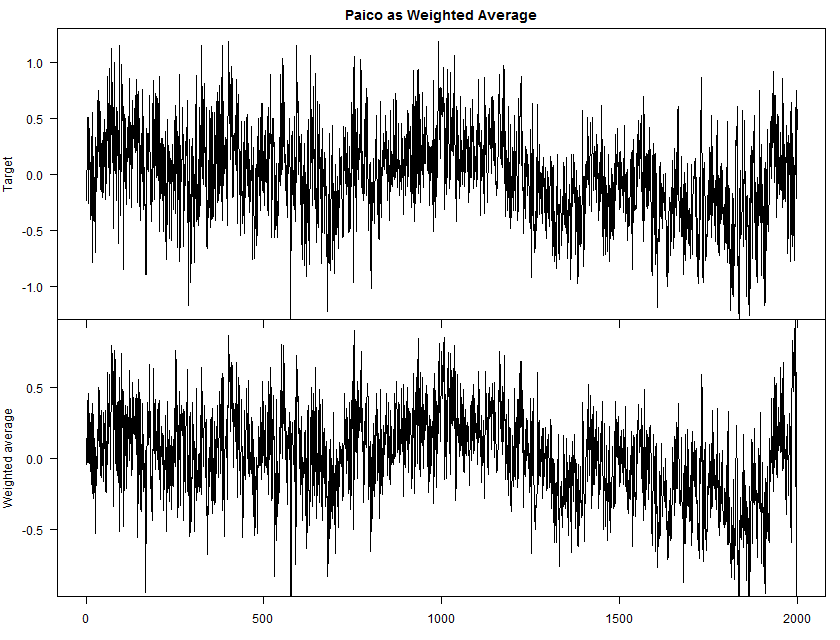
In this last figure, I’ve calculated a weighted average of the underlying proxies, weighted by the number of measurements, and compared the resulting reconstruction to the precalibrated paico reconstruction. The correspondence is extremely high, other than at the very end, where the population of proxies drops sharply, apparently leading to odd effects.
Discussion
One of the many curiosities of 1000-year paleoclimate is their fascination with complicated and relatively opaque multivariate methods and their willingness to rely on relatively unproven methods for important empirical results. The paico methodology, whatever its merits, was about 1 minute old when adopted into the PAGES2K report and thence into IPCC AR5. I doubt that the PAGES2K authors intended to weight the proxies in their reconstruction by the number of measurements, but that’s what they did.
As a result, the low-resolution proxies, even the Igaliku series that I’ve severely criticized, actually do not matter very much to the final reconstruction. The main contributions to the final reconstruction come from Kaufman’s problematic varve series, tree rings (especially series from Briffa and Jacoby-D’Arrigo) and ice cores.
It therefore looks to me like the primary contributions to the large change from Arctic2K-2013 ro Arctic2K-2014 come from inverting Hvitarvatn. Secondary contributions from extending Lomonosovfonna, truncating Blue Lake and switching to a University of East Anglia version of Tornetrask. The weights of several tree ring series will also be reduced because they removed early portions with fewer than 10 cores in the 2014 version: this reduced the number of measurements and thus the weight of these series. Odd, but that’s the effect of this analysis.
While we’ve only applied this decomposition to the paico method, it strikes me that it would be useful for decomposing and analysing other opaque recent methodologies (LNA etc.) As noted above, the method won’t work with methods that ignore the sign of the proxy (as some Mannian variations), but it will be interesting to try it elsewhere. The method seems pretty obvious and both Jean S and presume that it is amply documented in other fields. However, we presume that the PAGES2K group did not consider this form of analysis or else the close relationship of the weights of the proxies to proxy counts would have been reported by now.
Finally, whenever I look at proxy reconstructions, I think that it is extremely important to examine the weights of each proxy. One of the uncredited accomplishments of McIntyre and McKitrick 2003 was its observation that weights of individual proxies could be extracted since MBH methods were all linear, subsequently discussed in several CA posts. (At the time, academic literature on the topic had taken the position that weights could not be extracted.) Whenever one of these opaque new methods is proposed, I think that the authors should consider the relationship between their method and proxy weights – at least to an approximation.





62 Comments
While this post reports on work done jointly with Jean S (who did all the paico extractions from Matlab), I haven’t vetted the writeup with him. This is fresh work and he may have some revisions.
Not that I am pretending to understand it but here is a paper describing teh method. it includes a pedagogical section with an intuitive explanation and justification of the method.
Click to access PaiCo.pdf
Steve: I’m aware of the paper, as we’ve been discussing it. Having said that, I should have linked to it in this post as well as the previous one. The paper does not include any of the observations made here.
Just a quick note for those “technical readers”, I’ll expand tomorrow if someone is interested. The weighting issue comes from their likehood function (eq. (6)): every pair has an equal weight in the likelihood function. Pairs are only calculated over each series, hence more observations, more pairs and more weight to the likelihood function. Simple as that.
thx
Every pair of observations, or consecutive only? If the former, you have a quadratic in number of data points.
Steve, Jean S., and other article contributors.
I have not commented here before, though I read all the posts. I simply want to say I have followed your blog for a number of years now, and I appreciate the work you do;
snip
Martin C.
Gilbert, AZ
Steve- thanks for the comment, but extra editorializing not within blog policy
Curious that the uncertainty at the end of the series, 2000AD, acellerates on the high side uncertainty but not the low uncertainty.
It’s in some way nice to play with this kind of analyses. Therefore I produced also a few graphs. I added 30 additional timeseries of PAGES2k Arctic to the Hanhijärvi et al 27. (I didn’t replace any they used, neither did I change the instrumental part.)
I had first in mind removing one timeseries at the time, but inverting the sign is so much easier to do, that I picked that idea of Jean S.
I’m not sure, what will happen to the figures, when I link them here, I hope they can be seen in the space allowed for them.
First a figure that summarizes all changes
Grey bars tell, how much the reconstruction has changed in inverting the sign. This is essentially the same information as given in the post for 27 proxies.
Orange bars tell, how much the difference of latest 100 years from the whole period has changed. Here we see that the Hritarvatn has added a lot to the estimated temperatures of the early period as removing it has a large negative effect (this is the sigh convention). The Yukon proxy has the strongest opposite effect.
These two cases are compared with the original result in this graph
Blue bars of the summarizing graph compare the latest 100 years to the 300 previous years. The largest deviations are shown in more detail here
It can be observed that the reconstruction of the recent past does not change much in any of these cases. Thus the largest uncertainties seem to be in more distant past. The large discrepancy with the North Atlantic analysis of Hanhijärvi et al is not explained by these comparisons.
Steve: in most reconstruction methods, there’s a calibration step in which the series are centered on a modern reference period. If series diverge in the modern period, this centering step will export the divergence to the past. It’s sometimes better to experiment with the data centered over the entire period, rather than after the final “calibration”.
And yes, mathematically the effect of inverting the series is a more elegant way of analysing than simply leaving it out. It’s one of those things that seems “obvious” once it’s on the table, but without the practical example of PAGES2K inverting Hvitarvatn, I don’t think that we would have stumbled on it. Jean S (and I) both presume that, as an analytic technique, this is so simple and elegant that it must be well-known somewhere, but probably under nomenclature that we aren’t familiar with. Do you know of prior uses of this technique in other fields?
Pekka, can you place your PAGES2K inverted series online in a csv or equivalent file as well? Also can you save your bar chart with more pixels for those of us with eroding eyesight?
Thx, Steve
I start by splitting the bar chart in two parts (I built it in Excel, and don’t know, how to make a more readable version in one piece).
Part 1 contains the original Hanhijärvi et al proxies name as they named them
Part 2 contains the 30 added proxies named as they are they are named in text files from the database (there may be one or two minor changes to that).
This zip-file contains the Excel-file I used to create the chart. I added there also the full reconstructed time series (original+57 with flipped data) in a csv-file.
I transferred the data to Matlab structures using a Matlab function that I coded. Some parts of the transfer were done interactively in Matlab, but the function was of great help. I made also a few very simple changes to the function scripts that Hanhijärvi had written for doing the PaiCo analysis. The main purpose of those changes was to produce all 58 results in one run. After that I made the remaining part of the analysis interactively.
My calculation is based on 57 time series, not 59. I haven’t checked, whether I have lost two somewhere. It’s likely to differ also in other respects slightly from what PAGES 2k has produced.
Thanks! Could you also put your “data” input variable on line? Would save a lot of manual work from the people running these analysis.
My Matlab structure data.mat is here in a zip file.
That’s the only one used by PaiCo.
I add that the structure data has been extracted from the larger .mat file used by PaiCo. It should be possible to replace the original structure by this and just run PaiCo.
Pekka, as I read your graphic, the green line shows Hvitarvatn in the orientation of PAGES2K-2013 and the black line in the amended orientation of PAGES2K-2014. It looks like this single inversion explains most of the change between the two results (more or less as I had surmised once the paico weighting became evident).
Your chart, as I understand it, also points to the importance of Big Round Lake – a series that I’ve been discussing over and over; Briffa’s Yamal and the various D’Arrigo, Jacoby series. I’ve been re-examining the latter and will be posting on them.
Steve,
I’m not expert enough to say more than what the graphs tell directly.
What I consider most striking is the important role that Hvitarvatn has in the declining trend of the temperature over the whole period until the early 19th century.
Which makes it particularly odd that PAGES2K used it upside down. If you look at my related discussion of Big Round Lake, Baffin Island, you will see that it bears an extraordinary resemblance to the Hvitarvatn data, but is used in opposite orientation. This leaves one of two options: either there’s another shoe to drop with this reconstruction. Or the specialists have to provide a physical explanation of why Baffin Island and Iceland have symmetrically opposite climates for the past 1500 years. This ought to be of concern to ClimateBallers with an interest in physics, which some profess to have.
While I can’t remember any studies that have explicitly compared climate shifts in Iceland and Baffin’s Land, there are several that show very close correlation between climate change in Iceland and Greenland, which makes it even less likely that Baffin’s land would be opposite in phase.
Yes, the green line (‘Larsen2011’ Hvitarvatn) shows the effect of using that proxy as it was used in the original Pages2k (2013), and it seems to explain a large part (most?) of the difference.
Steve,
I understood the calibration, but my comment was based on the observation that the strongest divergence is in distant past (several hundred years or more). The situation differs strongly from the comparison of Hanhijärvi results with PAGES 2k Arctic as they start to deviate already in the first part of the 20th century.
Nice work Pekka! Just a quick question: are these based on the original PAGES2k data (2013) or the updated (2014) version? From the series names I’d guess the 2014 version (i.e. you used database v.1.1 from here).
Jean S,
I used the new database, but only for proxies that were not used by Hanhijärvi et al, because some of those proxies might have required additional work, as they were not annual and annually resolved. I didn’t dig further in on that.
Thus I kept all previous elements of data.proxy as they were and added 30 more.
Thanks, thatäs what I thought, just wanted to be sure before giving any interpretations.
Notice that the last step of PaiCo (calibration) is just mean-variance matching to the instrumental record (instrumental is not used before that). So from the analysis point of view, it makes sense to use the pre-calibration results (which is given in “result.uncalibSignal”).
Jean S, have you located any precedents for the “Sibelius transform” as a means of numerical analysis? This question is open to other readers.
Just a note on exposition. I suppose I’m a casual reader, so Mr. McIntyre probably doesn’t care whether people at my level can understand this. However, I do have some experience with technical writing, and I’m positive that many fewer readers would simply throw up their hands at the ambiguity in passages like “We are able to show this because we noticed that the contributions of each proxy to the final reconstruction can be closely estimated by half the difference between the reconstruction and reconstructions in which each series is flipped over, one by one. This sounds trivial, but it isn’t” if it were disambiguated by an equation.
Yes, I know that such an omission does not distinguish the head post from most stuff on the Web. But those who care to improve the productivity of their attempts at communication might consider the fact that a little more effort at one writer’s end would reduce the necessary effort for a large number of readers.
Steve: my equations tend to be R-code, but point taken.
The result is just a linear weighting of all the proxies with each of them multiplied by a weight or factor specific to itself. To find out the contribution of a proxy, invert it an rerun the calculation. The result of this is the same as the original reconstruction but with the contribution of the proxy of interest inverted.
So if the original reconstruction is R = Sum of Others + proxy. The new one is R = Sum of others – proxy.
So half the difference is the contribution of the proxy.
I pondered that sentence too, for a while, and concluded that what was meant was “We are able to show this because we noticed that the contribution of each proxy to the final reconstruction can be closely estimated by half the difference between the reconstruction and an alternative reconstruction in which that proxy is flipped over.” (This is the same meaning TAG ascribes to it, in the previous reply.) As for the subsequent sentence “This sounds trivial, but it isn’t”, that’s a nice tease. I think the idea is that this would be a trivial consequence (and would be exact) if paico were described as producing a weighted sum of the input series with weights not dependent on the values of any series — but since it is not described that way, this is not a trivial observation (and is not quite exact).
Here’s code to explain the calculation. I’ll put the data online tomorrow so interested readers can run the calculation.
#read in matrix of reconstructions with one-by-one flipped series (uncalibrated)
setwd("d:/climate/data/multiproxy/hanhijarvi/jean_s")
flip=read.csv("flipped_uncalib.txt")
dim(flip) #[1] 2001 28
flip=ts(flip[,2:28],start=0)
dimnames(flip)[[2]]=gsub("\\.","_",dimnames(flip)[[2]])
#read in reconstruction with unflipped series
target=ts( read.csv("h13orig.txt")[,2],start=0)
sdt=sd(target); sdt
#0.4172807
##calculate decomposition as half the difference between the original reconstruction and one-by-one flipped recons
contrib=0.5*(target-flip)
dimnames(contrib)[[2]]=dimnames(flip)[[2]]
#calculate estimate as row-sums of the decomposition
estimate=ts(apply(contrib,1,sum),start=0)
##correlation is almost exact
cor(estimate,target)
#0.9984834
# std deviation is similar but not exact
sd(estimate)
#[1] 0.4391186
#but the decomposition is far from trivial: there is an order-of-magnitude variation in the standard deviations
range(apply(contrib,2,sd,na.rm=T))
#[1] 0.0002708854 0.1277002916
Steve
It’s nearly 10 years since I first contacted you regarding setting up a weblog (to speedily rebut the slickly presented RealClimate.org)
And 10 years later, we still have paleoreconstructions of climate based on hitherto unknown statistical methods with poorly understood properties, that have themselves not been heard of by real statisticians nor reviewed in statistical literature, and used as the basis for wide-reaching scientific reports and global economic decisions.
And its only noticed on weblogs.
It doesn’t actually feel like much has changed in that time (although personally I think Mann is about to have his comeuppance in court against Steyn).
Perhaps because academic science has little fear of the consequences of mistakes to its budget while the climate science spigot is still flowing.
Actually some things have changed: Climategate showed that the peer review system had been thoroughly undermined and perverted. It was one of the key events to bring to the surface how badly peer review was functioning
Now we have Retraction Watch and PubPeer, the latter of which I regard as a key part of the future of the scientific method.
But still highly-qualified people play the system to produce highly questionable results. It’s only a small piece of progress.
Steve: Ten years! I don’t know whether to thank you or curse you. 🙂 I don’t think that you can extrapolate from CLimategate to all of peer review. It’s too bad that Muir Russell failed so completely to actually examine the conduct of Jones et al within expected standards of peer review. Also I’d be astonished if Mann v Steyn proceeds to trial. I think that the combination of Mann’s fabricated claims about the scope of exoneration and the ACLU argument that people are entitled to contest the findings of governments will result in CEI and NR winning the SLAPP battle without Mann ever being deposed. This will be disappointing to those who wanted to see Mann deposed, but CEI and NR have other obligations.
But please, no discussion of Mann v Steyn on this thread.
Much gratefulness here, John A. How was it that you became aware of Steve’s work?
=========
Probably through his disrespectful treatment at RealClimate.
Thanks, JN, somehow I’d sped through JA’s first paragraph. Even more incredibly, somehow I’d labored under the misconception that CA preceded RC, possibly because RC seemed so reactionary to CA.
Not so incredible after all; it was reactive to the lethal critique of the icon. It’s a great woulda shoulda coulda. They coulda been contenduhs.
=========
Kim:
I can’t quite remember what it was that alerted me. I remember reading about Steve and Ross’s original work (called MM2003) via the late John Daly.
Then I heard about Steve and Ross’ impending blockbuster article to be published in GRL, and saw the launch of RealClimate (or Unrealclimate as I came to see it) in late 2004. I saw the grinding of axes and misinformation about Steve and Ross and thought ‘they’re going to get smothered in slime going through the glacially slow peer review process while Realclimate gets to take free hits’. So I contact Steve and implored him to setup a blog and the rest is (climate science) history.
Steve Mc:
Yes, I know I ruined your life by helping start up this blog ;-p but you started it by drilling the deep well of dreck known as the Mann Hockey Stick. You could have had a quiet retirement by now, but noooo…
Steve McIntyre, you’ve asked several times how much the PAGES reconstruction would change if “the other shoe were to drop”, i.e., if Kaufman et al fixed the other contaminated and/or upside-down proxies. Isn’t this something that you can try yourself? I had the impression that the data and paico code had been archived? Why wait for them?
Steve: they have an excellent archive in Matlab, but I am only fluent in R. If I were not doing anything else, I would figure out the Matlab. However, Jean S runs Matlab and we’ll get to it.
As I suppose you have noticed this is an ongoing work, which just took a huge leap forward, thanks to Pekka.
We needed to first figure out how to best quantify the effect of a single proxy as this is not simply a linear combination of the proxies. Second, Steve doesn’t have Matlab. Third, it is a lot of borig manual work of importing these proxies to PaiCo (once yoy’ve figured out how to do it). Fourth, I’ve been yesterday evening and today busy (apart from my normal family life) thinking the effect of weighting the low-freq proxies. So if you are really busy seeing the results, why don’t you do it yourself?
Some can, and some can’t. Those of us who can’t just buy popcorn and wait impatiently.
A dead fish is good for the sprouting corn. So I’ve heard.
=======
I enjoy observing these analyses in real time and fully realize that they are works in progress. This process is something for which internet communication is readily adaptable. If one had to wait for critical analysis to be peer reviewed and accepted for publication one could devour lots of popcorn.
From the paper describing the method under discussion on this thread titled “Pairwise comparisons to reconstruct mean temperature in the Arctic Atlantic Region over the last 2,000 years”, we have the following statements:
“The major assumption underpinning PaiCo is that there is a monotonically increasing function relating the proxies to the temporally averaged climate variables.”
“Therefore, we do not assume as much about the relation between a proxy record and the target climate variable as existing methods do, but still assume the proxies are informative about the underlying climate variable.”
Taken together these two statements indicate that it is assumed that a discernible temperature signal (“underlying climate variable”) is in the proxy responses. I say once that assumption is made and made without independent evidence one can show whatever reconstruction one wants by selecting proxy data and manipulating it. It would appear that the authors of this paper want us to accept the valid proxy response to temperature on faith and then get excited about new and better methods of manipulating that data. It would appear on skimming this paper that the method is simply a means of selecting proxies which have a good relationship, not necessarily linear, with the instrumental temperature record. It will thus have all the basic problems any ex post fact selection process has.
Having said all that I’ll sit back and follow the discussion of the method from the paper and what its effects on the reconstruction are.
“It would appear on skimming this paper that the method is simply a means of selecting proxies which have a good relationship, not necessarily linear, with the instrumental temperature record. It will thus have all the basic problems any ex post fact selection process has.”
On further reading of the paper my above statement is not correct. The authors apparently use a consensus vote by the proxies for each data point and without using the instrumental data.
“Here we introduce a new reconstruction method that uses the ordering of all pairs of proxy observations within each record to arrive at a consensus time series that best agrees with all proxy records. The resulting unitless composite time series is subsequently calibrated to the instrumental record to provide an estimate of past climate…
..Let f be a column vector that represents the time series of the target climate variable to be reconstructed. The values in f will represent the average of the climate variable over the geographical area the proxy records cover with equal weight for all proxy records.”
I have to read further and in more detail to satisfy myself how exactly the consensus reconstructed series was derived. The basic flaw of assuming the proxies have a discernible temperature signal without independent evidence remains.
Intuitively, weighting according to the number of measurements seems odd to me. That begs the question, what is the most sensible weighting? It would seem to me that you would weight something by just how closely related to temperature the proxy would be. Since tree proxies and highly influenced by other environmental factors they would not be heavily weighted. Was it on this blog I read that tree growth is constrained by the one thing that is in least supply (whether water, sunlight, good soil, etc)? So you might weigh them less than others. Varves have such a weak relationship to temperature I would weight them weakly. Ice cores I would weight heavily – it seems to me that they have the greatest direct relationship to temperature (they would also be related to wind and perhaps movement). Geography would also play a role.
Anyway, like you said, if the proxy is a temperature signal with noise, then the weighting should not matter. But since none of them will have a purely direct relationship to temperature, the weighting could provide a constraint on the influence of poor proxies vs good ones.
When this decomposition is applied to CPS, it provides some really interesting results. They show how CPS differs from an average in a remarkable way. Stay tuned.
What Steve and Jean S have written made me understand that the uncalibrated results of flipping one proxy at the time allow determining fully, how the reconstruction is built from the individual proxies. The following picture tells that for the Hanhijärvi et al analysis
The full analysis of 57 proxies is close to the corrected PAGES 2k PaiCo analysis (perhaps not fully identical, but close). It looks like this
The vertical scale is arbitrary as the the pictures are based on uncalibrated results.
Both are smoothened with Gaussian smoothing (standard deviation 25 years, scaled at the ends to 100%).
Full 2001 year PaiCo-modified versions of the proxies with and without smoothening as well as these pictures can be found as an Excel-file in this zip file.
Thanks for the graphs. It makes sense now.
There are several differences between the data I used and the updated PAGES 2k Arctic data set, because I kept the Hanhijärvi et al data unchanged and added the proxies not part of that.
One difference is that I didn’t remove Grudd2008 series from Torneträsk, when I added Melvin 2013 that replaces Grudd2008 in PAGES 2k.
Other differences are updates in several of the datasets used in Hanhijärvi et al. Most of these changes are in proxies that have very little weight in the analysis.
These differences cause effects in details, but basic conclusions do not change at all.
I add one comment to explain the area charts of my previous post (presently waiting moderation).
The bands are formed from the smoothed components of the uncalibrated composites by subtracting the minimum values. Thus each contribution is positive over the whole time range (zero at the point, where the minimum occurs).
It’s a bit difficult to figure out, which band is which, because several bands are so narrow that they are barely visible (if at all). The largest contributions to the Hanhijärvi et al case come from (starting from bottom)
– Divine2011
– Grudd2008
– HaltiaHovi2007
– Helama2010
– Ojala2005
– Tiljander2003
– Vinther2006 NGRIP
– Vinther2010 Dye
The Hanhijärvi series form roughly the bottom third of the PAGES 2k Arctic. From the other contributions the most visible are (bottom to top)
– Briffa2008 Avam-Taimyr
– Briffa2008 Yamal
– Larsen2011 Hvitarvatn
– Melvin2013 Tornetrask
– Vinther2008 Agassiz Ice Cap
Many other time series do also contribute significantly over part of time, e.g. in the warming signal since 1850.
From the text from the Hanhijarvi paper below I have the understanding that the pairwise comparisons are confined to within a given proxy series and are never between proxies. The algorithm orders the pairs for each proxy series with regard to which values are larger(smaller) and then compares that ordering across all the proxy series in order to apparently quantify the relative value of the changes for each incremental time step over the entire reconstruction time period.
“2.2 Intuition behind pairwise comparisons
We develop the intuition behind pairwise comparisons by first considering a special case of the general formalism of
Eq. (2). Let each proxy record and the target f have the same temporal structure and let the transfer functions be the identity, i.e., gk(x) = x for all k. In this case, each value of a proxy record is simply a noisy version of the corresponding target value. For a single pair of time points, the agreement between the proxy records over the ordering of the two corresponding observations within each proxy series is directly related to the difference between the target values. The more proxy time series feature a higher value for the first time point, the greater the value of the target at the first time point as compared to the second. Similarly, if the proxy series are about equally split between featuring the larger value at the first and second time points, then there is likely not much difference between the corresponding target values. Assuming Gaussian noise, we can use the amount of proxy agreement to calculate the relative difference between the pair of target values.”
If someone who has read and understands the paper and has a different take on what the authors are doing with their algorithm I would greatly appreciate being corrected.
I think you understood the idea of their intended (*) method. Here’s a recent review paper of the method used:
Click to access 1210.1016.pdf
There is also a review of R packages (Section 4) if someone wants to try the method.
(*) The jury is still out considering if their extension to different lengths and resolutions of proxies is valid (see the paragraphs starting in the end of p. 18 in the review).
Thanks, Jean S for the comment and reference. I still do not have my head completely around the method, but Pekka Pirila’s graph above certainly helps – and it’s pretty too.
It might be interesting to construct psuedo-proxies with varying signal-to-noise ratios (and possibly other artifacts) and see which proxies contribute the most signal to reconstructions of this type.
Warning
My Matlab scripts didn’t work correctly on all proxies. Therefore my results on the full PAGES 2k Arctic are erroneous. The errors may be large, but it will take some time to figure that out, because I’m busy for at least a day.
The results on Hanhijärvi data are not affected by these errors.
Due to the potential size of the errors I remove most of my files from the net.
I can now add that I had contaminated several proxies of fewer data points by some longer ones. I got the corrected calculation far enough to tell that the changes are clear, but not dramatical, but getting the new version out takes some time.
I have now reloaded most files. The remaining have been replaced by more informative later graphs and files.
The new versions are totally based on updated PAGES 2k Arctic database. No input data is taken from Hanhijärvi et al supplementary data (the method is, however, from there).
New graphics is also ordered alphabetically without consideration of the more limited set of the Hanhijärvi et al analysis. (I have, however, used the shortened names for proxies that where included in Hanhijärvi et al.)
I add two graphs to tell, how PaiCo modifies the proxies.
First Hvitarvatn
We see that the smoothed versions are similar, but not identical. (Neither the absolute values nor the scales can be compared, only the shapes can be compared.)
The second example is Lake Igaliku
Here we see that the annual reconstruction looks strange. The values of the Lake Igaliku time series have been specified to represent periods that do not cover the whole period. The intervening years are on represented by any data point according to the file of the PAGES 2k Arctic database. It turns out that a value very close to zero is given for all these periods. Applying 50 year smoothing (Gaussian of standard deviation 25) leads to a smoothed curve that has clear similarities with the original data with the exception of the most recent point (the outlier discussed on this site), which does not affect strongly the smoothed PaiCo result.
It’s possible that the input data should be presented in a different way, but this is what results from the way that seems the natural one for me.
The final result of the full reconstruction is not significantly affected bu Lake Igaliku data. The values on the left hand axis are comparable in that. Thus The influence of Hvitarvatn is about 2000 times stronger than that of Lake Igaliku.
Steve: pekka, thanks for this. The shape of the Igaliku and similar series seems to be built on a step function and the weights, as I had surmised in respect to Hanhijarvi paico, are a (perhaps near-quadratic) function of the number of measurements.
Sorry for being off-topic, but I have to share something I find hilarious. A few days ago I was asked if I had any comments on a paper. When I skimmed through it, the only thing which jumped out at me was a remark about the screening fallacy which was somewhat inaccurate. I commented on that, and there was some pleasant back and forth about it.
Then Jim Bouldin decided to defend screening. I have a post about some of his involvement, but what really matters is just a single tweet. It is hilarious:
Remember folks. There is no way to create a temperature reconstruction without screening proxies. Not a one.
Having played to some extent with PaiCo I’m starting to doubt, whether it is of any real value in the analysis of proxies. It’s supposed advantages seem to be illusory and its known weaknesses real.
The two main justifications given for PaiCo are
1) Capability to handle a nonlinear relationship between the variable studied (signal variable) and the proxy variable.
2) Capability to handle varying temporal resolutions.
The claim (1) is true only if the amplitude of noise is at each point proportional to the amplitude of variation of the signal variable. Noise that has a constant amplitude for the proxy variable at all values of the signal variable makes PaiCo a linear method over most of the range of variability. It has, in addition, a non-linear property of it’s own that affects the handling of extreme values. How this non-linearity affects the outcome is not fully predictable. It suppresses outliers, but that can equally well be good or bad.
The point (2) is also true only in a technical sense. We see from my results of Lake Igaliku (in an earlier comment), how that takes place with the code available from Hanhijärvi supplementary data. In that case the number of years each original proxy value refers to varies. The most recent points refers to 4.3 years around 1971, while the earliest point shown refers to a period of 27 years around AD 130. Both the actual value and the length of the period affect the outcome. It’s highly questionable, whether the way PaiCo interprets the data is justifiable.
Hanhijärvi et al handled variable periods differently. The text files that they used on the proxies did not include data on the span of the period each value corresponds to. Therefore they determined the periods, when interpreting those text files. To take an example Sirjup2011 gives values for years 1920.2, 1928, and 1931.8. Based on that they decided that the year 1928 refers actually to the period 1924.1 – 1929.9. At the ends of the full period they added time to make the final values represent symmetric periods around the nominal years. Looking at the Lake Igaliku case the approach they used is very hard to justify, while it may be more reasonable in other cases.
The new PAGES 2k Arctic material includes explicit periods for non-annual proxy series, my recent calculation used those periods.
Concerning the known weaknesses the paper of Hanhijärvi et al states:
I agree on that.
As I started this comment I agree on the stated weaknesses, but I consider claimed advantages to be largely illusory.
A minor comment on PAGES 2k Arctic data.
When writing the above comment I decided to check, how the period I mentioned of Serjup2011 is handled in updated files. What I found was surprising
#depth_cm depthUpper_cm depthLower_cm year_AD yearYoung_AD yearOld_AD d18O_permil
12.55 12.30 12.80 1932.700 1934.250 1931.150 1.2692
13.05 12.80 13.30 1929.600 1931.150 1928.050 1.3190
13.05 12.80 13.30 1929.600 1931.150 1928.050 1.1790
14.05 13.80 14.30 1923.400 1924.950 1921.850 1.2687
There’s clearly an error. The line that starts 13.05 should surely read
13.55 13.30 13.80 1926.500 1928.050 1924.950 1.1790
(The chronology is given as linear over depths 11.55 – 15.05 cm)
Preparing the new version must have involved some manual work that has led to this error.
Steve: the error is in the original data as well see ftp://ftp.ncdc.noaa.gov/pub/data/paleo/paleocean/by_contributor/sejrup2010/sejrup2010.txt
As discussed above the weights the proxies get in PaiCo vary greatly. Thus the effective number of independent proxies is less than the total number. When we consider the contribution of the proxies to the signal (rather than noise) we can define the effective number of proxies as
(sum of standard deviations of PaiCo components)^2 / (sum of variances of PaiCo components)
In order to base that mainly on the contribution to signal the calculation is done with the smoothed data.
This formula gives an effective N = 22.3 (out of original 56) for updated PAGES 2k Arctic, and N = 12.8 (out of 27) for Hanhijärvi et al. (Using annual component time series, where noise is strong gives 26.0 and 12.9 respectively.)
There are two additional errors in Serjup2011 data (bolded lines):
Also “Kaufman 2012 Lone Spruce Pond” has an error
and “Clegg 2011 Hudson Lake”:
I continue to have a difficult time taking these temperature reconstruction methods seriously after looking more closely at the proxies that are used for the reconstructions. In the North Atlantic Arctic (NAA) temperature reconstruction under discussion at this thread, I have graphed 26 of the 27 proxy series from 1000-2007 (not shown) and calculated a correlation for the first difference of all pairs of these 26 proxies. I did not use the Calvo2002 proxy, since it did not have data in the overlap period of 1600-1972 that I used to standardize the proxies series into standard deviation units. The correlation matrix is presented/linked below. The NAs in the correlation matrix where one would expect a calculated r value are there when more than 4 pairwise common data points were not available. I made no attempt in graphing or correlation to show the “proper” orientation of the proxy response to temperature. The proxies are named in the correlation matrix table. While I am far from certain, I assume here that varve thickness, diatoms, tree ring, alkenone, chironomid proxies show increasing values with temperature increases while ice core d18O, formaminifer dO18, sediment density, organic accumulation and ice cover proxy values show the opposite relationship. The cross correlations shown duplicated correlations such that it is easier to read across the matrix to see all the pair correlations with the proxy in the leftmost column.
The methodology used in the NAA paper is based on year over year changes within an individual proxy and thus I judge that using the first difference for correlation (which gives year over year changes without detrending) in looking at these proxies is in order.
The NAA paper makes assumptions about the nature of the proxies: The proxies respond to temperature in a monotonic manner although not necessarily linearly and the temperature changes of the region studied are independent of individual proxy location. Comparing the instrumental records of HadCRUT4 for the 5X5 degree gridded areas of region from 50W to 30 E and 60N to 90N would appear to bear out the latter assumption as the temperature difference changes were small.
While I would not suggest that proxies for temperature reconstructions can be properly selected without a prior criteria with a physical basis, if the proxy data are available, I would prefer that the authors of these reconstructions at least give details about the relationships of the individual proxies to each other and to the instrumental record. Ideally one would require that the proxies correlate from one type to another. The cross correlation table shows, however, that reasonable first difference correlations are mainly found within a type of proxy , e.g. tree rings and dO18 proxies. That observation might well mean that some of these proxies are not valid temperature indicators or at the least not very good ones. Proxies that agree within type would further require determining whether those proxy are indeed responding to temperature or to other variables in like manner. To that end I did correlations of 24 proxies with the annual HadCrut4 temperatures over the period of time in common. That table which appears on the right side of the previous table presented/linked below shows that the 4 tree proxies with abundant data show good significant correlation of the first difference of the proxy response to the first difference of the temperature series. The only other proxy with a significant correlation of this type was a dO18 proxy. That proxy with only 8 data points should probably not been considered and was only shown for completeness.
The next hurdle that would need to be surmounted for an individual proxy to be considered even a good ex post facto proxy is for the proxy to show good decadal coherence with the instrumental record and good decadal and centennial coherence with each other in the historical reconstruction period. To that end I plotted the 4 tree ring proxy series and the June, July and August HadCrut4 temperatures for the 5X5 grid of the proxy location with a smoothing spline such that one can observe differences in trends over decadal ranges for the instrumental comparisons and over decadal and centennial ranges for the within proxy comparisons. It should be noted here that temperature reconstructions are carried out primarily to compare amplitudes of decadal and centennial changes in the past to that in the modern warming period and thus a proxy that shows good high frequency correlations might not be considered valid for looking at these important lower frequency changes. It should be further noted that these lower frequencies changes need to be scrutinized as quantified measures. As it turns out the instrumental and standardized proxy series are on nearly the same scales because the standard deviation of the instrumental series are very close to 1. Also it should be noted that the within proxy lower frequency graphs the smooth.spline function in R with df=9 and spar=default for centennial comparisons and with df=9 and spar=0.5 for the decadal comparisons.
In scrutinizing the graphs of these lower frequency changes presented/linked below I find significant differences between the proxy and instrumental series and even more so within the proxy series going back in time. I’ll leave it to the reader to make their own judgments about proxy validity as thermometers on observing these graphs.
Kenneth –
I was trying to count the fraction of “p<0.05" cells, knowing that 5% of the cells would pass even if there was no relation. I got a figure around 7%. But there were some cases, e.g. proxy 24 vs. proxy 26, in which the correlation was marked significant in one cell but not in the conjugate cell (proxy 26 vs. 24). Is there some asymmetry in the p-value calculation which causes this?
HaroldW, thanks for the find – and, no, there should be no assymetry. The error was due to my own sloppiness. I did an eyeball check with another table with the p.values and I find now that I not only missed in my original count the one side of the pair you noted but also the one side of the pairs 2,19 and 8,23 and 20,24 which had p.values of 0.04, 0.02 and 0.01, respectively. Also please note that I limited the significance to those pairs with a correlation higher than 0.10 and there were pairs with correlations in that excluded range that had p.values less than 0.05.
I have no doubts that there are proxies like tree rings and dO18 that track climate variables (but not necessarily temperature alone) on a year over year basis with a significant correlation within proxy type. There are also some significant correlations, fewer in number, between proxy types and would therefore expect to see the portion of significant pairs, over all proxies, that is higher than 5%. The point then becomes can these proxies track temperature on a year over year basis. It is there that the significant correlations of the tree ring proxies with the instrumental record indicates that the tree ring proxies have that capability, albeit with a noisy signal.
I repeat here that the critical measure for these tree ring proxies then becomes how well the responses track temperature on the lower decadal and centennial frequency scales and is that measure that my graphs with the spline smooths were meant to show.
It should be noted that when enough of these proxies are combined, as in a composite plus scale and without selection based on tracking the instrumental record, the result can look and be modeled on the basis of a series of red and white noise – even though some of the proxies can have significant high frequency correlations with temperature in the instrumental period.
As I recall, Rob Wilson, a leading dendro paleoclimatologist, would point to how well tree rings responded to and could be used as markers for known large volcanic events in the past. He would use that relationship as evidence that these proxies were valid temperature proxies. Tree rings are valid as useful thermometers only to the extent that there is a proportional and quantitative response to the lowered temperature. That this is often not the case is seen by comparing those amplitudes in response to these events for tree ring data from locations in close proximity. That observation is similar to what I judge I see with the tree ring proxies in the NAA reconstruction.
In my above posts I showed that of all the 27 proxies used in the North Atlantic Arctic temperature reconstruction, the only ones that held up under a criteria of significant correlations of first differences within proxy type and instrumental temperature (and had reasonable amounts of data) were the 4 tree ring proxies. I need to note that those relationships are not sufficient for proxies being valid historical thermometers because the critical reason for doing reconstructions is comparing the decadal and longer trends in modern warming period to similar warming/cooling period trends in the reconstructed past. As noted in my previous posts the four tree ring proxies show deficiencies in this final test. I also repeat here that I do not consider an ex post facto criteria for proxy selection valid, but, given the reconstruction authors choice to go that way, that at least we should know the details of these relationships of the individual proxies used in the reconstruction.
Here I wanted to compare a composite of the standardized four tree ring proxies with the NAA reconstruction. Since I did not have the final data results from the NAA reconstruction, the comparison shown in the presentation/link below is of my composite of the tree ring proxies and a copy I made of the NAA reconstruction and attempted to adjust to correspond to the time scale of my composite. I think the similarity between the two are striking.
One Trackback
[…] the previous post on “Paico Decomposition”, Jean S and I showed that the effective weights of each proxy […]