I’ve posted in the past on the mystery of MBH confidence interval calculations, especially the mysterious MBH99 confidence intervals (another Caramilk secret). In our NAS panel presentation and perhaps before, I’d speculated that MBH98 confidence intervals, rotundly described in MBH98 as “self-consistently estimated”, were nothing other than twice the standard error of the (overfitted) calibration period. (May 3, 2006: Eduardo Zorita supports this interpretation in comment below.) Reader Jean S, a post-doc in statistics, has sent in a very pretty proof of this.
Based on this proof and a couple of other comments from Jean S, we’ve corresponded back and forth on the MBH99 confidence interval mystery and have reduced the mystery to a few elements, where we invite new ideas.
Review
I made two posts on the topic last May here and here . Confidence intervals are described in MBH98 as follows:
The reconstructions have been demonstrated to be unbiased back in time, as the uncalibrated variance during the 20th century calibration period was shown to be consistent with a normal distribution (Figure 5) and with a white noise spectrum. Unbiased self-consistent estimates of the uncertainties in the reconstructions were consequently available based on the residual variance uncalibrated by increasingly sparse multiproxy networks back in time [this was shown to hold up for reconstructions back to about 1600.”
….
The histograms of calibration residuals were examined for possible heteroscedasticity, but were found to pass a x2 test for gaussian characteristics at reasonably high levels of significance (NH, 95% level; NINO3, 99% level). The spectra of the calibration residuals for these quantities were, furthermore, found to be approximately ‘white’, showing little evidence for preferred or deficiently resolved timescales in the calibration process.” Having established reasonably unbiased calibration residuals, we were able to calculate uncertainties in the reconstructions by assuming that the unresolved variance is gaussian distributed over time. This variance increases back in time (the increasingly sparse multiproxy network calibrates smaller fractions of variance), yielding error bars which expand back in time.
MBH98 Figure 5 didn’t actually show that “uncalibrated variance during the 20th century calibration period was shown to be consistent with a normal distribution”. It simply showed a muddy version of the MBH98 reconstruction together with (supposed) two-sigma confidence intervals.

Figure 1. MBH98 Figure 5b. Original Caption: For b raw data are shown up to 1995 and positive and negative 2j uncertainty limits are shown by the light dotted lines surrounding the solid reconstruction, calculated as described in the Methods section
MBH99 said:
In contrast to MBH98 where uncertainties were self-consistently estimated based on the observation of Gaussian residuals, we here take account of the spectrum of unresolved variance, separately treating unresolved components of variance in the secular (longer than the 79 year calibration interval in this case) and higher-frequency bands. To be conservative, we take into account the slight, though statistically insignificant inflation of unresolved secular variance for the post-AD 1600 reconstructions. This procedure yields composite uncertainties that are moderately larger than those estimated by MBH98, though none of the primary conclusions therein are altered.
Poor Jean S almost gagged on Mannian prose. (Interestingly, when the MBH99 “correction” to the confidence intervals was done, Mann did not notify Nature and issue a corrigendum at Nature. In fact, if you go to the 2004 Corrigendum, you will see that the MBH98 confidence intervals are re-iterated even though they were supposedly re-calculated in MBH99).
Last year, I showed the difference between the estimates in the two attempts in the following graphic.
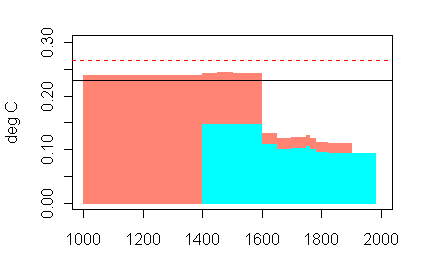
Figure 2. MBH98 and MBH99 sigma by calculation step. Cyan – MBH98; salmon – MBH99. Solid black – CRU std dev; dashed red -“sparse” instrumental std. dev.
At the time, I presumed that the difference was connected to this sentence about “separately treating unresolved components of variance in the secular (longer than the 79 year calibration interval in this case) and higher-frequency bands.”, but was then (and still am) unable to decode the rotund and uninformative language.
I re-visited the topic in December when I noted a similar phrase in Rutherford et al 2005 and surveyed some rotund Mannian literature such as Mann and Lees. This post is a handy reference for original quotations.
We referred to confidence interval issues at length in our NAS panel presentation as follows:
Confidence intervals in MBH98 (to which the term “self-consistent” is applied) are, as we understand it, calculated simply as twice the standard error from calibration period residuals. If there is overfitting (or spurious regression) in the calibration period, as appears almost certain, then calibration period residuals are likely to provide an extremely biased and over-confident estimate of confidence intervals.
For a sui generis procedure with little knowledge of its statistical properties, at a minimum, it seems to us that confidence intervals should be calculated from the verification period residuals – a procedure which was used in Mann and Rutherford [2002]. In this case, given that the verification r2 for the early steps is ~0, this procedure would, of course, have led to very wide confidence intervals and little to no reduction from natural variability, hence a complete inability to assess the statistical significance of warmth in the 1990s.
MBH99 acknowledged that there was significant low-frequency content in the spectrum of residuals i.e. highly autocorrelated residuals. Since at least Granger and Newbold [1974], econometricians have interpreted autocorrelated residuals as evidence of a misspecification. Instead, MBH99 purported to adjust the confidence interval calculations. However, no statistical reference is provided for this calculation. Neither we nor a time series specialist who we consulted on this matter have been able to figure out how this calculation was done. The use of calibration period residuals to estimate confidence intervals is followed in other multiproxy studies. In all cases, we see evidence of spurious relationships in the calibration period with serious out-of-sample behavior, raising in every case the spectre of over-optimistic estimation of the success of the reconstruction.
Jean S. re-opened the matter by sending me the following graph (slightly redrawn here by me) showing a link between MBH98 confidence intervals in each step and the calibration r^2 statistic (described by Mann as the calibration beta statistic). Jean S estimated the calibration sigma using the archived calibration r^2 statistics using the formula:
sigma = sqrt (1- r^2 [calibration]) * var (instrumental) )
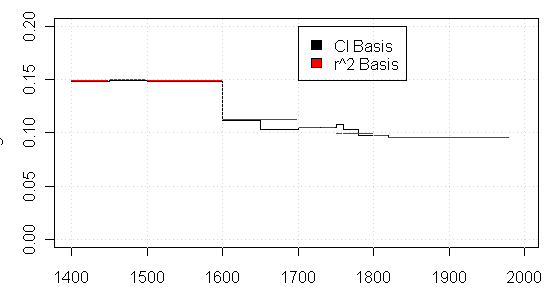
Figure 3. Comparison of observed MBH98 confidence interval to Jean S estimate. Black – from MBH98 archive; red- Jean S estimate using above formula and archived calibration R2 value. The instrumental, MBH98 reconstruction and MBH98 sigmas can be located in the following data set. Link (mirrored at WDCP and Nature). The r^2 [calibration] can be picked up here (formerly at the Nature SI, but now deleted there), where it is described as a “calibration beta” statistic.
Now I’d figured out/speculated that MBH98 confidence intervals were connected to calibration r^2 quite a while ago, but only now has Jean S figured out the exact connection. Jean S had expletives for Mannian terminology. I’ve cited a couple of his references below.
Since calibration residuals had been used by Mann in MBH98 to (1) calculate calibration r^2 and (2) 2-sigma confidence intervals, the connection between the two measures is what you expect. Since there is limited available (unspliced) detailed information on the individual MBH98 steps (the stepwise reconstructions still unarchived after all this commotion!!), each little bit of information on the steps is interesting and this was a nice use of the calibration r2 statistic.
The discrepancies in the graph are intriguing. Why is there a step at 1650 in the CI data set but not the r2 dataset? Does this pertain to an unreported AD1650 step? There’s other evidence of a 1650 step – one of the archived Reconstructed Principal Components (spliced) starts in 1650. So it’s quite possible that there’s an undocumented step. Does the archived information reflect results from two different runs – one with a 1650 step and one without a 1650 step? This also looks likely. Or maybe the reporting of one result was inaccurate. Hey, it’s the Hockey Team.
A similar situation arises with the period from 1750-1800. The r2 information shows 3 steps in this period, but the CI information shows one step. Did the CI calculation not use all the actual steps? Or were there different runs? Again, it’s impossible to tell. It’s the Hockey Team. There’s an odd little wrinkle in the 15th century, with an extra little unexpected bump as well.
A point that I made before, but still unresolved is: why do the confidence intervals INCREASE at certain steps with the addition of more proxies. Doesn’t that indicate that the new proxies have negative information? This would affect the AD1450 step where there’s a slight increase; and both at 1700 and 1750.
MBH99
With MBH98, at least it was possible to guess what they were doing. Now to MBH99 and another Caramilk secret. Aside from any details, the whole MBH99 confidence interval estimation process seems nutty. Autocorrelated residuals in econometrics are a sign of mis-specification. Mann uses the same information (which he calls low-frequency) to bump the confidence intervals up. While the calculation of the bump remains obscure, the point and validity of such a process is also far from obvious. No statistical reference is given in MBH99 for the procedure; I’ve looked diligently and have been unable to find anything remotely close. Suggestions are welcomed!!
You can download the MBH99 reconstruction with confidence interval data here Two columns are labelled “ignore”, as shown below. So let’s start with them. Remember how interesting are Mann’s CENSORED files.

First, if you compare the column MBH99$ignore2 to the MBH98$sigma (confidence interval version), the range is between 0.8123908-0.8123998. So these two are directly related. Why the ratio? Who knows? Jean S observes that this is close to sqrt(0.66) if that’s of any help. (As noted above, MBH98$sigma appears almost certainly to be nothing more than the standard error of calibration period residuals.)
If you compare MBH99$ignore2 to the MBH98$sigma (r2 version), you have a much wider range from 0.7435683-0.8814485. So MBH99$ignore2 is obtained from the MBH98 sigma somehow. Using this ratio and working backwards, we can derive the unreported calibration r^2 for the MBH99 first step at 0.39: is this significant? Well, if use 12 regressors to predict a series 79 years long with autocorrelation, I doubt it (but that’s a story for another day.) This is NOT the verification r^2, which will probably be about 0 for the AD1000 step as with the other steps, but I haven’t done the MBH99 calculations yet.
So MBH99$ignore2 relates to MBH98$sigma – what are the other columns? If you take the ratio of the MBH99$sigma to the MBH98$sigma, then there are only two “adjustments” – one for the period from 1400-1600 and one after 1600. The ratios are 1.187 and 1.643 respectively. Where do these come from? Who knows? I did this originally for the MBH98 comparison; Jean S responded that you could apply the above relationship between MBH98$sigma and the MBH99$ignore2 to extend this back to the first step. Using the constant, we get a ratio of 1.58 for the 1000-1399 step. These three values have something to do with the spectrum calculations of Mann and Less 1995, but what?

Figure 4. Top: black- MBH99 sigma; red – MBH98 sigma; bottom ratio of MBH99 sigma to MBH98 sigma (using the ignore2 to extend to 1000-1399).
A few comments from Jean S, as a statistics post-doc:
“these “climate scientists” seem to be a light year behind from my field in terms of understanding and using statistics, and their terminology is weird…
“what they are doing just does not make too much real sense (in the meaning of mathematics or statistics) … nor do I approve the thing.
“WTF!?!”
So I guess the “mask” is a complete ad-hoc, which is of course impossible to figure out. See what they say in MBH99, they don’t give any hint how they “take into account” different things (this usually means that procedure is completely ad-hoc). Also they say “to be conservative” which usually refers to some kind of ad-hoc number selection.
By the way, you should show all statisticians you happen to talk to Mann’s phrase “robustly estimated median” from caption~2 in MBH99. It must be one of the most unprecedentedly 😉 stupid phrases ever published in a scientific journal. Exactly this type of phrases I see from our under-grads with great ego but little understanding.
Update April 27, 2006: Jean S has emailed me to point out that the following holds exactly:
sum(MBH99$ignore1 ^2) + sum (MBH99$ignore2^2) = sum(MBH99$sigma^2)
So we have an orthogonal decomposition. Jean S proposes that this has something to do win the Mannian distinctive of “secular” frequencies. MBH99$ignore2^2 is almost exactly equal to (2/3)^2 * MBH98$sigma^2 in the overlap and is thus the standard error of the residuals weighted by 2/3 (or some high-frequency subset.) So it looks like some other series is weighted by 1/3 to get MBH99$ignore1. Ideas welcome. (End update).
May 6, 2006: Eduardo Zorita comments below re MBH99:
Well, the uncertainty limits in the paper (Fig 1) are 4 times smaller than in TAR, although they should be representing the same thing
Update: October 5, 2006
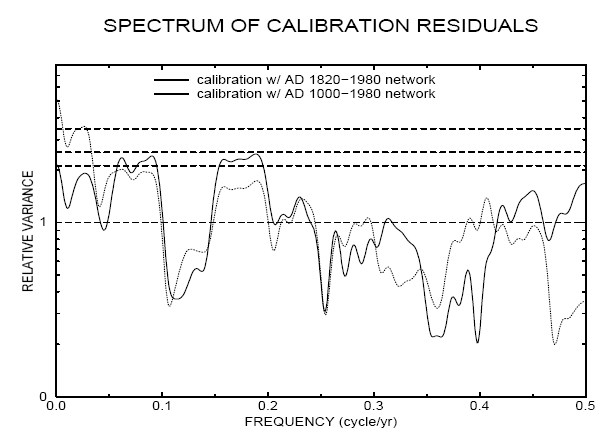
Jean S has observed that the MBH99 preprint (but not the final version) contained a graphic of the spectrum of residuals for the AD1820 and AD1000 networks (though as noted below, this may not be correct. Jean S’ digitization of the residuals is here AD1000 AD1820 . He used the Matlab routine for calculating MTM spectra script here , digital versions of spectra here AD1000 AD1820 . His emulation of MBH99 Figure 2 is here. Jean S’ emulation closely matches the corresponding figure from MBH99 preprint shown here.
Jean S’ emulation closely matches the corresponding figure from MBH99 preprint shown here.
Some new references:
- Allan Murphy: The Coefficients of Correlation and Determination as Measures of performance in Forecast Verification, Weather and Forecasting: Vol. 10, No. 4, pp. 681-688, December 1995.
- Michael Mann’s Lecture Notes for the course “Data Analysis in the Atmospheric Sciences”, available from here
Climategate postscript (Nov 3, 2023):
On July 31, 2003, (CG1 1059664704.txt) Tim Osborn wrote to Mann about the issue that Jean S addressed above:
I then looked at the file that I have been using for the uncertainties associated with MBH99 (see attachment), which I must have got from you some time ago. Column 1 is year, 2 is the “raw” standard error, 3 is 2*SE. But what are columns 4 and 5? I’ve been plotting column 4, labelled “1 sig (lowf)” when plotted your smoothed reconstruction, assuming that this is the error appropriate to low-pass filtered data. I’d also assumed that the last column “1 sig (highf)” was appropriate to high-pass filtered data. I also noticed that the sum of the squared high and low errors equalled the square of the raw error, which is nice.
One phrase from this email thread will be familiar to readers – this is the notorious “dirty laundry” email. It’s about confidence intervals.
p.s. I know I probably don’t need to mention this, but just to insure absolutely clarify on this, I’m providing these for your own personal use, since you’re a trusted colleague. So please don’t pass this along to others without checking w/ me first. This is the sort of “dirty laundry” one doesn’t want to fall into the hands of those who might potentially try to distort things…
Osborn observed:
From MBH99 it sounds like post-1600 you assume uncorrelated gaussian calibration residuals. In which case you would expect the errors for a 40-year mean to be reduced by sqrt(40). This doesn’t seem to match the values in the attached file. Pre-1600 you take into account that the residuals are autocorrelated (red noise rather than white), so presumably the reduction is less than sqrt(40), but some factor (how do you compute this?).
Osborn’s question here corresponds to the question in my post in which I had observed different adjustments from 1400-1600 and after 1600. (“If you take the ratio of the MBH99$sigma to the MBH98$sigma, then there are only two “adjustments” – one for the period from 1400-1600 and one after 1600. The ratios are 1.187 and 1.643 respectively.”) According to Osborn’s comment here, Mann assumed “uncorrelated gaussian calibration residuals” after 1600, but before 1600, Mann recognized that residuals were autocorrelated.
Mann then provided two possible “explanations” of the MBH sigmas: either as a combination “low f[requency]” and “high f[requency]” uncertainties, or as standard deviation of calibration residuals using “effective” degrees of freedom:
The one-sigma *total* uncertainty is determined from adding the low f and high f components of uncertainty in quadrature. The low f and high f uncertainties aren’t uncertainties for a particular (e.g. 30 year or 40-year) running mean, they are band integrated estimates of uncertainties (high-frequency band from f=0 to f=0.02, low-frequency band from f=0.02 to f=0.5 cycle/year) taking into account the spectrum of the residual variance (the broadband or “white noise” mean of which is the nominal variance of the calibration residuals) Alternatively, one could calculate uncertainties for a particular timescale average using the standard deviation of the calibration residuals, and applying a square-root-N’ argument (where N’ is the effective degrees of freedom in the calibration residuals). I believed I did this at one point, and got similar results.
Osborn then asked Mann how he computed the values:
I now understand how you compute them in theory. I have two further questions though (sorry):
(1) how do you compute them in practise? Do you actually integrate the spectrum of the residuals?
(2) how would I estimate an uncertainty for a particular band of time scales (e.g. decadal to secular, f=0.0 to 0.1)?If integrating the spectrum of the residuals, I wonder whether integrating from f=0 to f=0.02 and then f=0.02 to (e.g.) f=0.1 (note this last limit has changed) would give me the right error for time scales of 10 years and longer (i.e. for a 10-yr low pass filter)?
The way I had planned to do this was to assume the residuals could be modelled as a first order autoregressive process, with lag-1 autocorrelation r1=0.0 after 1600 (essentially white) and r1=??? before 1600. Do you know what the lag-1 autocorrelation of the residuals is for the network that goes back to 1000 AD?





194 Comments
I agree that the Team’s writing is pretentious and vague (to the point of cloaking the work).
What is the implication if the confidence intervals as done by MBH are incorrect? Are correctly calculated intervals wider or narrower, and how are the “results” of MBH ’98 and ’99 affected?
If Jean S can do this, sounds like a very nice publishable note.
If the confidence intervals are calculated using r2, how does that square with Mann’s comments that calculating r2 would be silly and wasn’t done?
Steve,
Just for the record, I added paragraphing, corrected spelling, changed long urls into links (so that interested parties can click on them) added spaces and just generally tided up so it didn’t make my eyes water trying to follow the story. I’m sure I’m not the only one this happens to.
John A, sometimes the WordPress software deletes all paragraphs and removes paragraph spacing.I write with paragraphs and the way it looks now is about how I did it originally. I didn’t check the posted version as I went out after writing this. I also notice the paragraph deletions from time to time when I revisit old posts, that were once paragraphed. I usually re-insert the paragraphing. If you have any theories???
“If you have any theories???”
Increase in overal global mean tmepratures means the servers run hotter, and if they don’t have good ECC some bits are lost and there you go.
Hey, let’s be fair here; Dr. Mann is on the cutting edge of new statistical procedures. It looks like he teaches statistics, so surely he understands the subject?
Re #5
Steve,
My answer is don’t use WYSIWYG unless you need to put in tables or adjust the size of graphics. The WYSIWYG that we currenly have sucks.
The WYSIWYG editor in WordPress 2.0 is a lot better and the images are drag and drop.
You could try (since you’re a Windows man) to install w.bloggar which is a lot better for posting articles than the WordPress 1.5 editor.
Of course “sui generis” is a bit much. I think “new” works for me. Here’s a picture of someone who uses Latin: http://redwing.hutman.net/%7Emreed/warriorshtm/profundusmaximus.htm
I agree that sometimes these people contradict basic wisdoms of rational statistical thinking in general – such as the wisdom that the residuals should be noise.
In fact, the residuals should be noise whose color should be predictable theoretically.
Instead of considering autocorrelated residuals to be a problem of the mode, they upgrade it to a virtue. This is the very idea of global warming: one only looks at some 30-year or 100-year trends – low frequency modes – and ignores any disagreements at shorter scales, even though the high-frequency data are exactly those that should primarily verify whether an explanation/model is correct or not.
Incidentally, if you start to have statistics readers that are able to contribute significantly, you may create Open Source science. If there are some mechanical things that are time-consuming, you may sometimes try to put the data on your blog, briefly explain what should be done with it, and maybe sometime else will start to do the hard work. 😉
#9. Touché (or is that subject to the same criticism). New is not the mot juste – yeah, I know. The nuance is more oddball. But I take the poisnt since I criticize the Hockey Team for verbose and obscure language. We have a Separated at Birth here – compare http://redwing.hutman.net/%7Emreed/warriorshtm/profundusmaximus.htm to the picture here .
RE #11 –
This is the first time I’ve seen what Mann looks like. That’s NOT what I expected. For some reason, I had the image of Gaius Baltar from Battlestar Galactica.
The Mann picture page has a link to an article about a UVA graduate student who ie comparing tree rings to “weather records kept by James Madison and Thomas Jefferson.”
At least one person at UVA sees a link between tree rings and moisture.
Jim Erlandson: Don’t be simple. The stickers have never denied that moisture recons can be done. They use different trees for moisture from temp. See the principle of limiting factors:
(And you may argue that it is diffucult to get that in practice, but that’s a more sophisticated concept than your gibe.)
I’m still waiting for proof of this. I know it looks intuitively correct, but I need some DATA.
Jae:
Re 16: TCO, what is the “(sic) gibe” comment about? From the Encarta Dictionary …
w.
#14 TCO: I’ll try to be less glib with my gibes.
http://www.climateaudit.org/?p=617 Comment 29
One of the recurring themes on this site has been the difficulty in differentiating between moisture and temperature effects on ring width in proxies.
RE 14, TCO, as always, an interesting post. You say:
There are a variety of difficulties with this idea.
One is distinguishing the “primary environmental variable that is most limiting”. How do we know if tree X is responding to moisture or water in the year 1532?
Another is that the variables are not independent. With plenty of water, a tree can thrive at a temperature that will cause it to wilt and slow its growth if there is not enough water … is the limiting variable in this case water, or temperature?
Third is that the limiting variable may change from year to year, and from decade to decade. A long term drying trend can cause moisture to be an issue, where it has not been in the past and may not be in the future.
Fourth is that temperature and moisture are not the only possible reasons for variations in tree rings. Disease, fire, removal of neighbouring trees, insect infestation, cloud cover, late freezes, and changes in CO2 levels all can affect the ring width.
Finally, and perhaps most important, we have the “upside-down quadratic” shape of the response to temperature. Since the assumption is always that thin rings = cool and wide rings = warm, when the temperature gets too hot and the rings get narrow, this will be interpreted as a cool year. I see no theoretical way to discern between too hot and too cold. The net result of this error is to mis-interpret warm times as being much cooler than they actually were … see the MWP.
Because of all of these difficulties, I’d have to see some serious studies to determine if this “paleodendroclimatology” idea works at all … I haven’t seen anything yet that makes me think it’s any better than consulting goat entrails to predict the MWP temperature …
w.
Perfect response, Willis. Thank you. TCO is just being argumentative again, for the hell of it, I think.
Well, just to be contrary, let me give a way of avoiding the problems brought up. Since some areas are more likely to be precipitation limited that others, it should be possible to compare several areas in close proximity and determine when there was a lack of water and when not. This proxy can then be used to adjust the temperature proxies so that they are more closely a true temperature proxy. Unfortunately I’ve never heard of any of the climate reconstructions using different sets of trees to do such calibration. You don’t suppose it’s because it’s been tried in some OTHER censored file and didn’t give the desired results, do you?
What would you guys do without
Richard NixonTCO to kick around?# 17: see last part of post 13.
# 18: That’s cool about being less glib. And yeah…I know the themes, issues. I just don’t want you to lower yourself to the jae level of cackling at your opponent for not recognizing a concept and then having to crab away when the converse is shown with the gratitious observation (a shifting battle of issues) that they don’t deal with the issue adequately.
Willie:
1. Yeah, I agree that the principle is simple in concept but the acid test is how well it can be applied in practice. To examine that we need to dig into the specifics. (And we have to rise above the blockhead jae level of sideshow cackling. Heck, we don’t want the skeptic equivalent of Lynn do we?)
2. I think that you can make some judgements about likelihood of a proxy to be useful as a preferential indicator going back. It’s not like a total crapshoot and the laws of physics have completely changed. If you pick particular species, locations, etc. this gives you a good start. If you are worried about wandering into a “regime” that is untested, you can extrapolate back and see if the data is leading you to such a regime, do you follow me? I’m not saying it’s easy. Or even that it’s done. But this is how to think about it (if you are a thinker…)
3. In your example, “water”. Try thinking it through, stud.
4. You are repeating in this para…
5. Possible confounding factors is an issue in many types of field work, in sociology, etc. Are you saying to throw hands up and do no analysis? And there are some ways to bound and express the issues that you have concern with. For instance if their effects are random or correlated to the variable (temp) under concern. Try thinking.
6. I’m not so sure AT FRIGGING ALL, that the U-shape issue is the most important concern. A, granted. But most important? If it is so frigging dangerous and prevalent, why don’t we ever hear about it in the context of calibration/verification periods?
7. I agree much more needs to be done to build and to assess the foundations of the science. I remain concerned about an approach here that throws hands up without even knowing what is state of the science. It has warts, sure. But you all seem to not know where they are or to have really even examined the patient. I got a problem with that.
8. As further illumination, I suggest reading the dendro principles. You can find plenty to engage here and push on, but at least you won’t be jae-ian.
http://web.utk.edu/~grissino/principles.htm
#21: Yeah Dave, we are thinking along similar lines. I have made similar comnments in the past. A multiple regression.
Steve said:
This sounds amazing. I can’t believe it is true.
Intuitively, in order to be able to apply the confidence intervals from the calibrattion period to an out-of-sample prediction period, you would have to assume that moving out-of-sample adds ZERO addtional uncertainty to the analysis. It is just very hard to believe this is actually true. In time series analysis, the confidence intervals for out-of-sample predictions usually increase with the distance from the sample period.
Am I missing something here?
What would be the reasonable, vanilla method for determining confidence intervals?
re #7: I find it curious that the university, that has C.R. Rao among other interesting names in its Statistics faculty, arranges a special “Data Analysis in the Atmospheric Sciences” -course whose instructor is an associate professor from Department of Meteorology. Maybe they don’t teach “right stuff” in actual statistics courses 😉
#25
I think it is true. Look in Nature 392, page 786, right column, last paragraph
Re 23, TCO, thanks for your thoughtful response. I have referred to several of your points elsewhere (http://www.climateaudit.org/?p=650, posts 91, 99, 111, 114, 116, 118), particularly your comments about the upside-down u-shaped response to temperature, but I’d like to cover a few other issues here.
I said:
You replied:
Umm … that’s not an answer, that’s a restatement of the difficulty, which merely states that yes, it’s difficult. I don’t follow you when you say that if we’re going into an untested regime, we can “extrapolate back” … how will we even know if we’re headed into an untested regime? And what can we use to “extrapolate back” to see if we are headed into such a regime?
And most importantly, your “extrapolation” doesn’t answer the question about what was happening in 1532. Is a skinny ring in 1532 due to drought, or too high a temperature, or too low?
I said:
You replied:
Well, “stud”, I have thought it through, and perhaps you haven’t. Consider the following case:
One week, a tree is hot, but there’s water, and it grows fine.
Next week, no rain, same temperature, it doesn’t grow because it has too much heat for the water.
Following week, the temperature cools and the water is the same, so it’s growing well again.
Are you saying that there is some way to extract these different signals by looking at ring width? Are you saying that water is the only limiting factor?
If so, why does the tree grow well one week and poorly the next week, although the water is the exactly the same during the two weeks, and only the temperature is different?
I must confess, I don’t see how you can say that water is the limiting factor. Another statement of the exact same situation I described in my original post would be:
“At a low enough temperature, a tree can thrive with an amount of water that will cause it to wilt and slow its growth at a higher temperature … is the limiting variable in this case water, or temperature?”
… think it through, “stud” …
I said:
You replied:
Try thinking? Gosh, TCO, I’d never have thought of thinking … look, can you at least be civil here? Is there some reason that you have to be childish? Last time you said your ugly response was because you were posting drunk … if so, come back when you’re sober, because if drink is your excuse, then you’re a nasty, unpleasant drunk.
Yes, confounding factors exist in lots of fields. However, we are trying to assess the effect of unknown confounding factors that occurred hundreds of years ago … you can pretend it’s a trivial problem, but it’s not. I see that you claim the solutions exist for adjusting for these confounding factors … but I also notice that you don’t mention what the solutions are …
In a mixed stand of trees, for example, if the other trees in the stand are attacked by beetles and die, the remaining trees will grow much faster … but there may be no sign of the insect infestation in the trees of interest. Since you’re the thinker here, tell me how we can even determine if this has occurred by looking at the rings of the remaining trees three hundred years later, much less adjust for this confounding factor?
The result of all of this, of course, is the pathetically small R^2 of the overwhelming majority of tree ring correlations to temperature. The correlations seem to be typically on the order of 0.3 – 0.5, which of course means the R^2 is on the order of 0.09 – 0.25 … not impressive.
You say:
TCO, I’m not throwing my hands up. I’m asking for answers to specific problems. I’ve just listed exactly what and where some of the warts are, and what I get from you are platitudes that it’s all solvable, and claims I don’t know where the warts I just listed are located …
If it’s all as solvable as you say … why are the correlations so low?
w.
Re #25, #28: Yes, it is true. MHB99 “confidence intervals” are even more interesting, they are derived from the standard error values with a (very simple) ad-hoc filtering. I have had correspondence with Steve about the procedure, and we are “almost there”. We have figured out the relationship of those “ignore these” columns, and I have a pretty good guess how they were formed. It would be interesting to guess the exact procedure, as it might explain, why this filtering was performed at all (i.e., why not to use the same values as in MBH98).
BTW, notice that they are not talking about “confidence intervals”, the phrase is “uncertainty limits” 😉
# 30
Perhaps do you also know why the uncertainty limits at multidecadal (40-year timescale in the IPCC TAR (Figure 2.21) are 3-4 times larger than in Gerber, Mann and others published 2 years later (Climate Dynamics 20, 281, 2003)?
I would like to know the answer.
re #31: Why don’t you ask Mann 🙂
Seriously, if you can pinpoint the problem more preceisly (I was able to locate the paper, but I didn’t immediately see the connection to Fig 2.21 in IPCC TAR), I may take a look. No guarantees though, this is “a hobby” for me and I’m actually rather busy with by own work right now.
Another thing, if you have an easy access to VZ04 simulations (and this is not too time consuming), could you do the following. Do your simulations the same way as in the paper(s), but in the proxy generation, instead of noise, simply substract (add) a CONSTANT term in the pre-caliberation time (
(#32 continued) Somehow I deleted the end. (I think you are not allowed to use smaller than sign). Here is the end:
…(pre 1902) and nothing in the caliberation time. Is the variation still reduced?
Well, the uncertainty limits in the paper (Fig 1) are 4 times smaller than in TAR, although they should be representing the same thing
TCO: Like I said, I just want to see some data and methodology that makes sense. Your wandering “logic” adds absolutely nothing to the science. Willis, you are still “right-on” in my book.
re #34: Sorry, I was checking (supposingly) wrong picture in IPCC TAR.
Anyhow, thanks a lot!! The description in the Figure caption may be the key to solve the final piece from MBH99 problem! Is there data available for that picture?
Wrong, Willie. It’s more than that. The concept of stands with limiting factors was included. With respect to quadraticy, the concept is that low frequency cycles will be displayed by increases in RW. If based on that, the temp changes to a regime that is outside the calibration extent, then you can worry about quadraticy. Try reading the last part of Burger and Cubasch and then think by analogy.
Re 37, [snip, c’mon Willis, let’s not feed this]
w.
PS – Do you really think your response answers my question about extrapolation? [snip
Willis,
Sorry, forgot the name. With respect to quadraticy: I’m not sure that you could tell the difference between a change to less of an extent from the change that occurs from moving out of observed conditions. It’s something that I would want to look at, think about. I don’t have “an answer” for you.
My point on limiting factor stands remains.
Re 38, many thanks to John A or Steve M for snipping my post, I was a bit short fused about my name getting abused again …
Re 39, thanks for the apology, TCO, and as always for the posting. I was reflecting this morning on what a privilege it is to be able to hold these types of discussions with knowledgeable and interesting people all over the world. What a wonderful time to be alive, my appreciation goes out to everyone in the game.
Regarding limiting factors, it seems to me that the limit is neither temperature nor water, but a combination of the two. I suspect we’re into a sematic question about what is a “limiting factor”.
There is a difference between the effects of temperature and water, however, because too much water is generally not immediately damaging to plants in the same way as too much temperature can damage them.
But both can be limits to growth, or to be more exact, it is the combination of the two. If temperatures are low, a plant can grow happily with very little water. But with the same amount of water, rising temperatures can cause first more and more, and then beyond a certain temperature, less and less growth, until in some cases growth can cease entirely.
If we plot temperature (horizontal axis) versus growth (vertical axis), we’ll find an upside-down quadratic of some sort. I know, TCO, that you are aware of the studies proving the existence of this non-linearity, as you have commented on them in the thread on this subject here. The effect of varying the amount of water is to shift this quadratic to the left or to the right. With less water, the growth rate will peak at a lower temperature, and with more water, the tree growth will peak at a higher temperature. In such a case, I’m not sure that “limiting factor” really means much.
While it may be possible to disentangle these two effects of temperature and water where we have accurate measurements of both, we never have such measurements for dendroclimatology out of the calibration period.
Thus, as I mentioned before, I see no way to determine whether a narrow tree ring in 1735 was caused by:
1) Enough water and too much temperature, or
2) Enough water and not enough temperature, or
3) Enough temperature and not enough water, or
4) A late frost, an early winter, a disease, or some other confounding factor, or
5) Some combination of 1-4 on different days of the year.
There is a claim that we can avoid, or at least limit, the confounding effect of moisture by choosing trees up near the treeline. The assumption is that these trees will be temperature-limited rather than water-limited.
The problem with this approach is that high elevations are often arid. This aridity, of course, increases the upside-down quadratic effect, as it takes much less temperature to get past the peak growth point.
I’m still looking for more information on the basic assumptions of paleoclimatology. Fritts used tree rings quite successfully to determine historical rainfall in an arid region, but that does not mean that we can do the same for temperature.
w.
TCO, I’ve found a very interesting paper called Cuphea Growth and Development: Responses to Temperature regarding the upside-down quadratic nature of plant response to temperature.
It shows that for Cuphea, the upside-down quadratic response is typical in all of the following:
“⠠ Leaf photosynthesis rate
“⠠ Water use efficiency
“⠠ Total dry matter accumulation rate (which is overall growth)
“⠠ Reproductive tissue (flowers & pods) dry weight
The study speaks of an “optimum temperature”, above or below which there is less growth or less efficiency. They show the equation for each of the different curves. All of the curves have the general form:
Growth rate = A + B*T – C*T^2
That is to say, an upside-down quadratic.
w.
Re: 40
Me too.
Jae, do a Google search and read the Ultimate Tree Ring site at a minimum. You complain that the research is not done to a tee, but you show ignorance of what advances have been made.
Willis,
I looked at your paper. Again, I think you are not considering the effect over a year of growth. If there are a few weeks in the summer, where growth goes down, don’t you expect it to be counterbalanced by the months in spring and fall where growth goes up? Don’t you see that it’s at least possible that this may be the case? What about for species that are at the extreme extent of growth (as the southernmost Australian trees that you cited) or trees at the treeline in altitude?
Re: #43
TCO, I think you may be missing the point here. It is exactly the “counterbalancing” that is the problem. Let’s imagine two trees, A and B. Both A and B experience “good” growth conditions during 1/2 of the growth year and grow 0.5 in ring width for that part of the year. In the middle of the year, tree A experiences *lower* temps for 1/2 the growth year and only grows 0.25 more, for a total of 0.75. Tree B, OTOH experiences *high* temps for 1/2 the growth year, such high temps that it passes over the “hump” of the inverted-U growth curve, and thus only grows 0.25 more. Thus, tree B also totals 0.75 growth for the year.
Joe Dendroguy comes along, cores both trees, and wants to reconstruct temperature for that year. Unfortunately, he is stuck: both tree A and tree B grew exactly the same amount, 0.75. We (godlike) observers know that in the case of A, there was a lower average yearly/seasonal temp than for B, but how is Dendroguy supposed to figure that out? Since there doesn’t seem to be any way, even in theory, for Dendroguy to assign a “correct” reconstructed temperature for this ring in trees A and B, how is temperature reconstruction supposed to work?
The point is that the inverted “U” growth curves mean that multiple different yearly average temps can result in exactly the same ring width (a many-to-one mapping). Since we only have the ring width to work with, how can we uniquely choose a single yearly average temp that produced it, since there are many valid possibilities (a one-to-many mapping)?
Well, Armand, and others, there are ways in theory to do this but it requires dendroguy and his fellows to supply us with additional info. In particular we need to know altitude, etc for the tree. We can assume that the higher you go the cooler the temperature. So if we find that as we go to higher trees the RWs get smaller, we can assume we’re on the cool side of the inverted U. If we get larger RWs then we can assume we’re on the warm side of the inverted U. Of course we’d need other info such as soil depth to let us work out precipitation.
Re 45, Dave, there’s a small problem or two. You say:
I’m not sure what the “etc.” in the “altitude, etc.” means, but leaving that aside for the moment:
1) Unfortunately, in addition to temperature dropping with increasing elevation as you point out, we can also assume that the higher you go, the more arid it is likely to be … and the less CO2 the air contains … and the more UV there is in the sunlight … and the more wind there is … and the less nutrients there are likely to be in the soil …
As a result, ring widths are likely to get smaller as you up regardless of temperature, and once again, we can’t decide which side of the inverted “u” we’re on.
2) The two trees may be at the same elevation, or the hotter one may even be higher, but more exposed to the sun, and less exposed to the wind.
So while it is likely that, as you say, “there are ways in theory to do this”, in practice they require much more information than we are likely to have regarding site conditions in 1735.
Re 43, TCO, the ring width is the sum of the growth over the year. If there are a couple of weeks when a tree doesn’t grow because it got too hot, it will have less total growth than the tree growing in the shade next door that didn’t get too hot.
Regards,
w.
Re: #45,46
Thanks for the good points, Willis! Dave, I can certainly imagine that if you sampled a fairly large number of trees (in the 100s) over a number of acres along some fairly uncomplicated altitudinal transects, you might be able to start teasing out an altitudinal (temp?) component; with the larger number of trees sampled, effects of position within a stand, local microclimates, etc might be minimized or averaged out to some degree. However, this requires sampling many trees, and detailed positional info for each tree in 3D as well as in the local topography. All of that seems to be lacking in typical dendro temp reconstruction studies. As I mentioned a long time back, how hard can it be to take a couple of dozen photos of the area, with Xs marking the sampled trees?
Really Willis, you shouldn’t give me such soft-balls to bat out of the park!
A tree doesn’t move up and down the slope. Therefore if it starts out in a given spot it stays there all it’s life. So the general aridity, the CO2 concentration, the direction it faces, etc. all remain the same. We’re not going to compare one year’s RW for a pair of trees and then throw everything away. We’re going to look at what happens in one area of a hillside with what happens at a higher or lower place over time. One set of trees low on a hillside may all agree in having relatively narrow RW for a decade or two. If we compare them to a set of rings from trees higher on the same hill and see that the higher rings don’t have near the relative decrease in RW we have good reason to decide that the cause is higher temperatures as it has moved the position of the lower trees down the descending, too hot side while the trees further up the hill are still in the flat area near the optimum.
I could go on, but I leave the rest as an exercise for the student.
Armand,
Of course you’re right, but I started out saying exactly that. What did you think,
meant, if not exactly what you said? And it doesn’t take hundreds of trees, we’re just trying to figure out on what side of the temperature optimum we’re on. Of course if people did laboratory studies of individual species of trees, it might be possible to tease out an absolute temperature, provided it was possible to allow for precipitation another way. I’m sure the info isn’t there to do it today, but someday it might be done.
Our problem with presentday dendroguy is that he hasn’t been given proper direction when it comes to what’s necessary in documenting cores properly.
Sorry, Dave, I wasn’t trying to disagree with you so much as “disagree” with current practice. However, it’s hard for me to imagine that one could distinguish between a “temp optimum” vs a “wind optimum” vs a “soil moisture optimum” vs an “air temp optimum” vs a “sunlight optimum” vs a “dewpoint optimum” etc without sampling hundreds of trees over a number of acres.
It seems to me that without further work, all we have is good reason to decide that the cause is altitude difference (I apologize if non-temp altitude-linked factors have already been excluded by the field).
Re 48: Dave, thanks for your thoughts. You say:
Say what? Aridity is constant? You never heard of a drought, or of changing rainfall patterns where one area gets more rain for a while and another nearby area gets less? While some things stay the same for a tree, others change. These changing things include, despite your claim above, the aridity. Why on earth would you assume that aridity doesn’t change?
In addition, the exposure of any tree to sunlight, wind, and UV all can change as other trees grow up around, or die out around, the tree in question. Over the longer term, the height of the tree can change its exposure to sunlight. The average wind direction can change for a period of decades (think PDO or NAO changes). Wind direction alone can change the temperature radically, and totally unpredictably, with one spot warming and another cooling.
In your example, you say that some trees have a relatively narrow RW “for a decade or so”, while trees up the hill don’t show the same change. You assume this is because of temperature, but off the top of my head I can think of a number of other quite common conditions that can cause the same result.
For example, it is quite possible that the upper trees trap moisture better, while the moisture runs off from the hillsides of the lower trees. Thus, the change in RW may have absolutely nothing to do with the temperature, but be solely related to the moisture available to each stand.
Or the trees in the lower stand may be getting shaded by a competitive species, one that subsequently dies out as the lower stand grows to maturity and finally shades them out.
Or the trees in the lower stand may be affected by a series of late spring freezing nights, while the upper stand is not freezing (remember that valleys generally freeze before ridges), so the upper stand grows better.
Or the average wind may have changed, affecting one stand of trees more than the other.
Or the relative humidity may have increased, leading to more foggy days for the lower stand but not the upper.
Or the clouds may have increased in an arid region, with the upper trees getting moisture directly from the clouds, while the lower trees get none.
Or the upper trees may be growing in rich soil and simply be less affected by adverse conditions because of their general health.
Or a decade of late season snowstorms leaves snow around the bases of the lower trees, but not the upper trees.
Or the upper trees get more sun, and the lower trees get more shade, so the upper trees are actually warmer than the lower trees … remember, higher doesn’t always mean cooler, it depends on the details of insolation and protection.
Or orographic clouds (those that form at the tops of hills) may shade the upper trees and keep them from overheating, while the lower trees are in full sunlight.
Now, you seem to think that teasing out the average temperature from this morass of variables is easy, you claim it’s a “softball” … that’s hubris of the traditional Greek variety. Trees are not thermometers, and even in the best case there is only poor correlation between growth and temperature.
Heck, we don’t even know all of the variables. I was reading an article today that said that some species of trees are very sensitive, not to the temperature per se, but to the size of the day-night temperature swing … how will that show up in your “softball” example, where we don’t know if the day-night swing of the upper trees is greater or less than the lower?
Yes, you are correct that we can get more information by sampling a transect of trees from top to bottom … but not much more, and we still cannot say on which side of the “hump” in the u-shaped response we are located. In part this is because it changes daily.
One day it is too hot for the trees at the bottom, the next day it is too cold, and the amount of growth is the same. How can we tell that situation from two days that are too hot, or two days that are too cold, or two days that are too dry, or too foggy, or too windy? The growth in all cases can be exactly the same, and taking a vertical transect won’t help us that much.
The naive belief in dendroclimatology is that trees at the top of the elevational range are “temperature limited”, and at the lower end they are “moisture limited”, but this is an artificial dichotomy which conceals some unpleasant facts for dendroclimatology:
1) there are a wide range of factors beside temperature and moisture that affect tree growth, and
2) there are a wide range of factors that make the temperature of an individual tree be different from the SAT, and
3) there are a wide range of factors that make the moisture available to an individual tree be different from the measured rainfall, and
4) none of these factors applies in isolation, in general they all can affect each other, either positively or negatively, and
5) all of these factors apply all of the time.
Softball, my ass …
w.
“Softball, my ass …”
Oi!!!!
This is a family show here.
As I said somewhere else, if you are serious about finding the basic relationships between ring width and climate, what you need is very high resolution climate data.
The solution seems obvious: look for weather stations that have been recording data for a few decades at least, and core some some trees in the immediate vicinity.
This will not be perfect, but it must give you a better chance of solid results than faffing around making guessing details of micro-climate a couple of centuries ago.
Dave, I went down and had dinner, and thought about the situation you had posited, viz:
I realized that, as bleak as I had painted the picture in responding to your example … it’s actually worse. Here’s the two reasons why.
1) Suppose for the moment that your claim is true, and that we can determine that the cause of the narrow ring widths of the lower trees, and the cause of the unchanged ring widths of the upper trees, is actually higher temperatures as you suggest above. The question then arises …
What was the temperature that resulted in that ring width? I mean, how do we correlate the narrower ring widths to an actual temperature? The trees up top don’t help, they’re in “the flat area near the optimum” so they’re giving us no information at all …
In particular, the location of the optimum is a function of water as well as temperature … with more water, the optimum temperature moves higher, and with less water, it moves lower … so how on earth can we figure the rise in temperature that relates to a certain drop in ring width?
Then suppose over the next years, the lower trees’ rings get wider … while it is tempting to think that this is because the temperature is cooling, it might equally be because the drought has ended … but if it is from dropping temperatures, what is the drop in temperature that relates to the increase in ring width?
2) The real problem, though, is that it is simplistic to say that the lower trees are on the “descending, too-hot side”, because obviously they are only too hot part of the time. The reality is that on any hot day, the tree spends part of the day below the optimal temperature, part of the day at the optimal temperature, and part of the day above the optimal temperature … I’m sure you see the difficulty. Over the year, it does the same, spending part of the year above, part below, and part at the optimal temperature. The eventual ring width is the sum of those growth patterns … but at the end of the year, there’s absolutely no way to say how much time that individual tree has spent above or below the optimum. As someone mentioned above, we have a many-to-one mapping, and from the eventual one (the ring width) we cannot determine the parts that made it up, how many hours or days were spent above or below optimum. This is not a problem between different trees in the stand. It is an irreversible degredation of the incoming information (temperature and water) within each tree, a one-way loss of signal information that cannot be retrieved. You can think of it as an average. Although we can take 365 individual values and get their average, if all we have is the average, there is no way that we can reconstruct the individual values.
Now consider the effect of the normal dendroclimatological interpretation of that tree’s growth, which is that wide rings = warm and narrow = cool. The inevitable result of this analysis will be that the hot hours of the day and the hot days of the year will be counted as cool hours and cool days, and we have no way to know how much that has happened, we have no way to calculate the size of that underestimation. About all we can say is that we’re pretty sure it was warmer than whatever answer we get … which isn’t that much help.
If you see a way around that softball … you’ve got better eyes than me.
w.
Re 52, thanks for the correction, Senor Viscous, what I meant to say was
“Softball, my fundamental orifice …”
w.
Guys, I agree 100% about altitude. In the case of bristlecones in particlar, the base dendro position is that the lower border bristlecones are P-limited but the upper border bristlecones are T-limited. Graumlich argued that there was a T*P interaction, which is obviously plausible, although the implications are not followed.
In paired locations, the ring widths of upper border bristlecones were wider than lower border bristlecones.
#53. fFreddy, what about Niwot Ridge? It’s about 45 minutes from UCAR world headquarters. It has high-altitude bristlecones and weather stations going back for years.
Here Woodhouse and Graybill got varying results and nearly 15 years later no one has reconciled them.
Armand: Certainly, I DID forsee the type of example that you gave. (Even in the example that I gave, one can see that the “couple weeks” of over-temp situation is analagous to the 25% in your example. Give me some credit.
I was just a bit more sophisticated and assumed that we can still extract lessons. For instance, consider if we are comparing year to year within a tree. If you want to consider something else, think about the quadratics that Willis posted (see his links) and consider the peak (it was ~25C). Well, how much of the year will temps be over that mark and how much under. From that you can see if (within a tree), the effect that concerns you is likely to cause RW to reverse direction. Capisce?
Steve:
A. It’s intriguing that the RW is higher at high altitude, but one can still imagine lots of cases where the trees are still “more” temp limited, even given that. (Germination limits versus growth limits, characteristics of precip limited versus temp limited, other effects, etc.) The acid test and where you should criticize is the correlation of temp (or other variable) to RW for the different posited limiting locations (within a stand). If the correlation of RW to temp at high altitude is 0.6 and that at low altitude is 0.3, surely that means the high altitude is a better temp rpoxy than the low (and we wouldn’t want to FUD it unfairly).
B. I’m STILL intrigued by your comment about higher RW at high altitude. Is that a common result? What are some references on it? Have botanists/dendro guys written on it? What do they think the cause? What refs do you have to show this effect? Is this a feature accross the slope (monotonically increasing with altitude)? Or just comparing the two endpoints?
And Armand, in your cases with A and B, it is likely that B will have a longer overall growth season. (If the overall climate is warmer). I’m not saying this will always happen, I’m saying that the method (assumption) will work when that does happen. Of course, if the growing season is the same and the only difference is that “change in the middle”, you won’t catch it. So that amount of noise will creep in. But it won’t ALL be noise. Because that kind of “warm year” is not the only kind of warm year.
P.s. Posited global warming effect is supposed to moderate winters more, summers less. And to raise temps more at high altitude/lattitude than the reverse. So extension of growing seasons rather than extreme, quadratic, summers seems more likely to be the effect that occurs.
#58. Look at the Bristlecone category and back a few posts and you’ll find the discussion. The point has not been made in the dendro literature to my knowledge. The evidence for the point came from examining measurement data archived at WDCP and is based on raw data. One of the disadvantages of the use of “chronologies” by the dendro jocks is their use of indices rather than measurements. This disguises the actual ring widths which are relevant in many circumstances.
Ok, that’s another publication that’s overdue, Steve. Oh…and don’t be too centered on the paleoclimatology implications. That’s something that makes the results interesting. But the basic paper is just one that observes how RW is larger at high altitude. BTW, you did not answer my question about endpoint comparison versus monotonic increase.
P.s. I think I remember that discussion. I don’t think there was that much more content/detail than the simple remark of the RW being larger at high altitude. (Hence my questions).
P.s.s. Might be a good topic for the dendro listserv.
Just a short note now. I’ve copied over half the thread and will try writing something lengthy later.
I realized I was being provocative in message 45 and even more so in 48, but you, I hope, understand that I’m not exactly anxious to WIN this debate. If it can be thoroughly and convincingly shown that there’s absolutely no way to extract a meaningful climate (expecially temperature) signal from tree ring proxies, this would be more than satisfactory to me. But the disadvantage of the lack of presence of knowledgable experts on dendroclimatology on this blog is that people get sloppy. They throw out ‘good enough’ arguments and everyone says, “Wow, you sure showed them!” when they did nothing of the sort. They just overlooked 90% of the good arguments on both sides. Now I’d like to be able to say that this was exactly what I intended, but I’m not that vain. I did consider your earlier message a ‘soft ball’, Willis. And your responses are much better. But they’re not perfect, and I intend to go at least one more round. To project where I think I’m going is that there’s a lot of confusing statistics of two sorts in this case. The first is statistics used to produce data and underlying the assumptions and methods used to do so and the second is the statistics of the data itself. There always has to be care to make sure the one sort isn’t affecting the other, but I think it’s possible to disentangle them sufficiently to ultimately reach a valid conclusion.
I would be very interested in having effective proxies and in learning what the algorithm is that enables effective proxies. We should find out where there are wrong assumptions and correct methods in those cases. But the goal is not to try to discredit methods per se. Just flawed ones. Actually we may find that the critical analysis will make us better able to figure out proxy methods that are effective. And that would be great. Knowledge is great. We should WANT to learn. Should want policy debates to be founded on best knowledge. Let the chips fall!
Willis
Do you hear a wooshing sound? 😉
It’ wasn’t the word, it was the phrase in total.
monotonic with altitude – I don’t know; I’ve wondered the same thing.
The altitude issue is one that really interests me as you know from my favorable comments on Millar et al 2006 and Naurzbaev et al 2004.
I wrote Rob Wilson not too long ago asking him if he knew of a dendro data set where the originators had recorded the altitude of individual cores so that this effect could be analyzed on its own. He said that he was unaware of any data set with that information. That’s one of the first things that geologists would keep track of. WDCP doesn’t even seem to have set up methods of archiving the info.
It certainly makes a lot of the data much less useful. Especially when you have significant altitude changes over time such as the Polar Urals. It’s one more bad thing about this field.
Well, write your imperfect-but-bound-to-move-the-field-along paper.
http://www.climateaudit.org/?p=478#comment-23294
A. I ran very quick search (Google scholar) and found nothing. So, you should publish. And NOT Nature or Science. Put it in a dendro journal.
B. Think you should invite Millar over here to see your remarks (and comment hopefully).
#43. Dammit, TCO, I am very familiar with that site, as well as having degrees in forestry and wood science. Willis makes some very good points here; I believe that there are just too many variables that affect tree growth to be able to discern a temperature signal 300 years ago. Trees are especially sensitive to moisture levels in areas of low annual precipitation. Thus, if we know an area is prone to periods of drought, it is probably pretty safe to use tree rings to measure the extent and severity of droughts (tree rings are great for studying droughts). Native trees in temperate zones are “programmed” to grow like hell in the spring when moisture is almost always available, and I don’t think temperature has much effect on this rapid growth spurt early in the spring (it probably just takes a few more days at lower temperatures, especially at the elevational/latitudinal limits of the growth range). You would think there would be a substantial amount of basic literature on temperature effects, but there is not. That is the basic problem with tree ring teemperature reconstructions; there is no good basic foundation to support the whole concept. Trees at the upper altitudinal/latitudinal limits of their growth ranges almost certainly behave just like the wildflowers there do–they don’t (stop blooming) (put on less wood) just because it is cooler; it just takes a little longer to do it.
I don’t have a problem with you complaining in more sophisticated terms after having looked at the best of what your opponents have to offer. I do have a problem with you running around like a ninny, acting like you’re the first one to have a brainstorm that the concept of confounding factors exists. And you are a main offender in this category…
Please correct me if I am wrong with this statement:
If one was to collect a large number of what are considered to be accurate temperature records going far enough back, and then core at least one tree DIRECTLY ADJACENT to the site of the temperature measurement (i.e. within a few meters, ideally), and perform correlation analysis, it should be possible to determine once and for all whether there is correlation between ring width/density and temperature, how good the correlation is, and how much it varies depending upon the tree species and other circumstances (altitude, precipitation, etc.)
If so, wouldn’t that be by far the best way to settle this argument once and for all?
And please allow me to add, given the straightforwardness of such a study [and despite the amount of work involved], a study like that which shows with high (>99%) confidence that the relationship exists and determines its properties should surely be a prerequisite for any study which uses tree rings as a temperature proxy?
After all there’s no use publishing 100 studies based on tree rings and then finding out later they were all based on flawed assumptions.
Please tell me that study has been performed?
Re #70, Nicholas
Hell, yes. While you’re at it, core all the trees around it that fit the standard dendro criteria for suitable candidates. See how well they correlate with each other to get an idea of non-climatic variability.
Yes, I guess that would be a good way to show whether previous studies which rely on this data were on solid ground or not. If that would not add much extra effort, then it would be a worthwhile addition. However I suspect doing what I suggested would be enough work as it is.
What I am thinking is, a large number of dendrochronolists should get together and split the task up. Each finds weather stations near where they live/work which have good records going back a while, and nearby trees, and organize to go there and take some cores. They all archive the data, then somebody (hopefully good at statistics) does a meta-analysis of all the data, along with the information about the type of trees, location, etc. and comes up with correlation figures for each category and overall. I think that would be a very useful project.
As I said, it’s so obvious (given that so many studies already rely on the temperature-ring correlation) I tend to think it must have already been done. Does anybody know whether it has?
Re: #69
Let those without sin throw the first stones…
Re:#70-73
Could be a fun project for amateurs, too (I’d be up for it!).
Sorry, TCO, I must be a bit thick today. What do I do after I “…consider if we are comparing year to year within a tree.”? Regarding a temp peak, since that is likely to change with changes in moisture and other factors, and temps change substantially even *during* a day, I’m not sure how to decompose ring-width into over-the-hump and under-the-hump portions without a very detailed local hourly temp/moisture/cloud/etc record.
TCO, I’d certainly appreciate it if you could spell out your general ideas in more detail for folks like me, who clearly aren’t as quick on the uptake. 🙂
One good thing about traditional dendroguys’ choice of trees near the limits of stand growth is that such a location suggests that the local microclimate is near an edge of the multidimensional tree-growth-response surface, and thus (at least locally on that surface) as far as you can get from a U-hump.
I think that studies showing a connection between precipitation and ring widths in arid sites tnd to hold up fairly well e.g. Cook et al. I’m not saying that precipitation reconstructions are flawed. I haven’t waded through them, but they mostly look better than MBH. If MBH is a reconstruction of anything, it might be a reccntruction of SW US precipitation.
In the case of bristlecones, Fritts 1969 is a quite detailed analysis of bristlecone growth, showing that soil moisture is the primary limiting factor in growth. There was a weather station in the White Mountains from 1951-1980 so that period is well covered. The first paper on CO2 fertlization considered this info – in addition to Graybill, it included luminaries Lamarche and Fritts.
There’s also a difference between short-term results and drift. For example, I’ve posted on the important sampling bias potentially resulting in big differences between modern and medieval samples. Where people have ocntrolled for altitude (Millar, Naurzbaev) they have reported high MWP temperatures not observed in the site chronologies. The drift issues seem to me to be the most important for issues that interest us.
RE 76, Aramand, your comments are interesting . However, I didn’t understand it when you said:
You need to remember that:
1) any given tree will likely go up, over the "u" hump, down the far side, back up to the top, and down the near side of the hump on any really hot summer day.
2) the upper limit of a stand growth may have nothing at all to do with temperature, but may be related to wind, UV, moisture, etc.
3) being "far" from the u-hump doesn’t help us, if we’re on the far side of the u-hump. It is not true that trees at the top of their range are not temperature limited for part of the year. I have observed this condition many times during hot summers in the Sierra Nevada mountains. The summers there are dry, and although the temperature is less at the altitude of the treeline, I have many times seen trees stressed and wilting from the temperatures. This is because, although the temperatures are lower, so is the moisture. This lack of moisture shifts the U-shaped hump to cooler regimes, so it can be easily exceeded on a hot day.
w.
Steve: Willis’ personal reminisce here is particlarly important because the foxtails come from theSierra Nevada and the bristlecones from the White Mts across the Owens Valley. A disproportionate number of “critical” proxies come from high arid sites. Graumlich 1991 is from the high Sierras emphasizing P*T interactions. All you have to do is see a picture of bristlecones beside big sagebrush to realize that this is no ordinary temperature limitation. You can actually map the gology quite accurately by seeing the change in vegetation from bristlecone to sagebrush. I’d love to see an ecological description of Jacoby’s Mongolia site. It’s at a somewhat similar latitude and I’ll bet that if you look closely, precipitation is a co-factor.
Re: #78
1) Maybe, maybe not. It all depends on how “far” it is to the top of the hump. This needs more investigation.
2) I agree – that’s why I talked about the multidimensional growth response surface. The issue of separating the various influences on growth and the issue of U-humps are separate; I was just commenting on the U-hump aspect. Even if, by starting “far” away from a U-hump, you can avoid having conditions cross a hump frequently or at all, I agree that it is unlikely that you will be moving only along a single dimension (temp in this case).
3) Sure it does, as long as we don’t *cross* a hump. All we’re looking for is to have growth change monotonically with environmental variables. For purposes of correlation, I’d be just as happy with growth increasing with decreasing temp. Specific locations may be bad or good; I was just pointing out that choosing trees near the edge of their growth zone increases the chances of being near an “edge” of the growth-response surface. It certainly doesn’t guarantee that, or guarantee that the nearest hump is far enough “away” to make the tree useful for whatever environmental variable you want to study.
With reference to Nicholas’ proposal to sample trees adjacent to a weather station, surely the results would only be valid for that particular place, and probably for that particular species in that location. It would still be an excellent experiment with valuable data, but probably a range of such experiments would be necessary.
Re 79, Armand, you say being far from a hump helps … ” Sure it does, as long as we don’t *cross* a hump.”
But my point is, there’s no way to be on the far side of a temperature hump without crossing the hump to get there … and that happens on a day by day basis. No tree lives on the far side of a temperature hump, unless they’ve outlawed night-time or something and I didn’t notice …
w.
Re: #81
Willis, I can certainly imagine a seed falling on a spot where *both* daily high and low temps are “on the far side” of a temp hump. The plant will still grow, it just means that the lower the temp, the faster it will grow (as long as conditions remain on the far side of the hump). Now, I agree that such a location is probably unusual, but often in science it’s most useful to focus on the extremes of a distribution. I also agree that it may be easier to find edge locations on the low-temp side of the growth response surface. I was just trying to generalize a bit and point out that all else being equal, it doesn’t really matter if you’re on a low-temp or hi-temp (or low-moisture or high-moisture, etc) side of a hump, what matters is (a) how far from the hump you are and (b) do the typical variations in microclimate bring you near (or over) the hump.
Not sure what you mean by outlawing night-time, unless you just mean daily low temps are typically at night.
Re #81, Willis
The location of the humps for any given species is, presumably a function of genetics and evolution, which is kinda slow.
What about trees that evolved in one place and have been taken somewhere else by humans ?
I was thinking of Kew Gardens, which is a place in London where the Victorians tried to grow examples of all intereting flora from all over the Empire. However, that probably tries to reproduce the native environment to some extent, so it may not be the best example.
But I’m sure there must have been some barmy Victorian who decided that he simply had to take pine trees (?) from his native Scotland and grow them on his plantation in Malaysia, or some such. I would have thought these would spend most of their time on the far side of the temperature hump.
Re 83, fFreddy and Armand, now you’re stretching it.
Yes, I can theoretically conceive of a situation where every day, winter, and summer, a tree is on the far side of a hump. Difficult, but possible.
But we’re talking about dendroclimatology, which uses stands of trees that have been where they are for hundreds of years … otherwise they’d be useless for our purposes.
Those trees have to cross the hump to get to the far side, and they do so on a day-by-day basis. Heck, you can see it in your garden, where a plant will be fine in the morning, and be wilting by the afternoon. Like the trees, it’s had to cross the hump to get there.
Finally, it is worth remembering that the optimum temperature, the top of the hump, is not fixed. Its location is a function of (among other things) the day-by-day availability of water.
w.
Until someone does some basic studies wherein most variables can be controlled, like greenhouse studies, it is likely not possible to determine whether temperature (however that is expressed–average, max, degree-hours, etc) has any significant effect on tree growth. It is simply incredible that so much climatic research is based on the very questionabale assumptions about relationships between growth and temperature. I think studies of tree line altitudes would be far more supportable and would yield much better data on long-term temperature variations. Some of the data necessary for such studies is probably available.
Re 85, jae, thanks for your post. However, you overstate the case when you claim that we don’t know if temperature has any significant effect on tree growth. Of course it does, any farmer can tell you that … but that’s not the question.
The question is, is that effect linear enough and large enough to use trees as a thermometer with any success?
That, we definitely don’t know.
s.
Armand: I think you figured it mostly out. Willis is still confused regarding seasonal and even daily humps and thinks that because a tree might spend 2 % of it’s time on the wrong side of a hump, that RW increase will reverse overall in annual terms. The “two weeks” comment was a reference to an earlier discussion where I pointed out to Willis that RW will not get smaller if temps increase a degree overall throughout the year for a tree that spends the hottest two weeks “over the hump” since there is so much of the year where it’s on the right side of the hump (plus onset of growth itself would be earlier).
Willis: quadraticy was raised as an issue ON it’s own. And it exists as an issue ON it’s own. Even with excess water for whatever temp, we will get a hump eventually. Stop…don’t reply. Think about it. Seriously.
TCO, I do think it is you that should do the “thinking”. You do seem to be wilfully misunderstanding the point I believe that Willis is making. That is, examine your assumptions, they are not as obvious as you seem to think, not as easily defined. Don’t reply, think about it first.
Wrong.
Re 89 — The insight … the wit … the devastating reply that crushes the opponent through the sheer weight of logic … a breathtaking display of erudition, I am beside myself with awe.
w.
PS Re 87, TCO, what do you mean, “don’t reply”. Who the !@#$%^ are you to tell people whether to reply?
I have thought about it, TCO. Temps do not increase “a degree overall throughout the year”. A much more common scenario will be something like a hot spell during the growing season. I have posted a link showing trees that stop growing entirely during the hot spell. Do you truly think this won’t affect the ring width?
Your claim seems to be that the decrease from being over the hump will be offset by the increase when it is not over the hump, which is certainly one possible scenario.
But follow the story out to the end.
What you don’t seem to have thought about is even that if that is the case, or even if it only spends 2% of its time over the hump, the ring width will be narrower than it would be if the response were linear … which is the whole point. Not that the ring width would necessarily narrow … but it will not be as wide as it would be if the response were linear.
Think about it …
w.
Worth a reread, TCO — this is my point, too. I also think we’ll have a much more productive discussion if we refrain from explaining what other people think and stop treating them like children.
Just sayin’
(see? I’ve been chanelling Dano!)
Willis, you note
I guess I had in mind situations where day/night temp variation is relatively small, like fFreddy’s Malaysia, or (seemingly) endless hot summers in Boston (come to think of it, what’s the day/night variation in Fiji?). I’m happy to have a counterexample (however rare), but to bow to your greater real-plant expertise and agree that in the real world it’s rare to find trees remaining on the far side of the temp hump.
“what’s the day/night variation in Fiji?”
I’m guessing extremely pleasant changing to gorgeous, with a hint of cool breeze and a 95% chance of sunny, changing to beautiful skies with a big moon and sparse cloudiness.
Oi you in Boston Armand?
My wife’s a Colorado Master Gardener, and a biologist (mostly marine but lately more plants). I described some of this discussion to her and she was… in shock. These questions about hi/lo growth and temperature are not unknown… except apparently to dendroclimatologists.
She can’t imagine how they ever got going on using RW as a proxy for temperature. As Willis says, there’s just wayyyyy too many confounding factors. Any farmer or passionate gardner can tell you this, from painful experience. Plant growth measured on large scales, is not a good temperature proxy.
Here is some helpful background material on temperature factors in plant growth, including trees. There’s a chart showing a tree hardiness/temp history relationship, which is a similar set of data to what’s being discussed in this thread.
Here’s a nice chart showing measured temp/performance curves for seed germination. I’m told these charts are incredibly common and well known by gardners. Seed germination is another aspect of plant life that follows the same “bell curve” rules Willis is describing. Apparently, many seed catalogs contain such curves for every species sold.
This also contains helpful info.
Many plants seem to have a “top of the curve” around 85F. That’s only valid under perfectly controlled growing conditions for all other factors, of which there are many!
Please, please do not assume that just because a tree’s in a never-above-85-degrees-climate, that it’s safely on one side of the “hump.” There are STILL lots of confounding factors. To quote the above reference, for just one of the cases they provide:
“Most important, the AHS Plant Heat-Zone ratings assume that adequate water is supplied to the roots of the plant at all times. The accuracy of the zone coding can be substantially distorted by a lack of water, even for a brief period in the life of the plant.”
Out of curiousity what is your wife’s opinion on increased atmospheric CO2 on Tree/plant growth?
In short what effect would a 30% increase in CO2 have on tree growth, all other things being equal on average.
#95, I doubt she has an informed opinion. But I’ll check…
It’s far more interesting to her, to look at banana slug ranges or marine transects and you’ll get better info 😉
OK, time for sleep (at long last…)
A reading of Mr Pete’s links gives a good idea of the complexities that dog a close relationship between ring width and temperature.
#95, have you seen this article on it?
http://www.pnas.org/cgi/content/abstract/103/17/6571
Element interactions limit soil carbon storage
Kees-Jan van Groenigen*, Johan Six*, Bruce A. Hungate§, Marie-Anne de Graaff*,Nico van Breemen, and Chris van Kessel*
Rising levels of atmospheric CO2 are thought to increase C sinks in terrestrial ecosystems. The potential of these sinks to mitigate CO2 emissions, however, may be constrained by nutrients. By using metaanalysis, we found that elevated CO2 only causes accumulation of soil C when N is added at rates well above typical atmospheric N inputs. Similarly, elevated CO2 only enhances N2 fixation, the major natural process providing soil N input, when other nutrients (e.g., phosphorus, molybdenum, and potassium) are added. Hence, soil C sequestration under elevated CO2 is constrained both directly by N availability and indirectly by nutrients needed to support N2 fixation.
Re #70 Nicholas,
Weather station sensors may sometimes be near trees, but they are not supposed to be. IIRC, the distance between the sensors and anything else is to be at least 150% of the height of that anything. If that anything grows higher than the height of the sensors, as trees may do, consistency of readings of the sensors deteriorate more over the years.
Re: #95
Sid,
Regarding CO2 and plant growth, a very interesting study reported on sciencedaily in the past week. An extract:-
The full story is here.
If true (and consistent across a majority of plant species), I would think this has interesting implications for tree ring proxy studies and global climate models, to the extent that they factor CO2 into their calculations.
I would note that this study says nothing about whether or not temperature is altered by CO2 levels, nor how plants’ growth might respond to increased temperature.
It does, however, dispute the notion that CO2 levels can directly impact plant growth. Not only that, it does it in a far more scientific manner than the statistical artifacts which masquerade as “science” in the climatology sphere these days.
Regardless of the HS cheer-squad’s snobbish assertions that their heros are all scientists, while the critics are amateurs, the “Hockey-Stick Papers” remain statistical, not scientific, endeavours.
This paper shows real experimental, observational science, designed to test a hypothesis.
Both AGW supporters and skeptics, alike, have used the assumption of increased plant growth due to wider CO2 availability, to bolster their arguments. The implications of this study are so fundamental, that it will (or should) turn these arguments on their head.
Blog readers might like to add to the list, but here are a few of the implications which I see flowing from this study (if it’s proven correct for most species):-
– All GCM’s will need substantial reworking, because one of the global carbon absorption mechanisms assumed to be at work doesn’t exist – there is a far larger carbon sink in operation out there than we had ever assumed was the case, which is sucking up the CO2 we thought trees were consuming.
– This may explain the disconnect between 20th Century CO2 vs. tree ring proxies. Namely, increased CO2 doesn’t trigger increased tree growth, therefore the disparity is hardly surprising.
– CO2 produced by man may well be exceeding the capacity of the remaining carbon sinks to absorb it, because one of the most flexible control mechanisms – plants increasing their absorption rates – doesn’t exist.
Your additions to this speculation is welcome.
I would add one final point, however. CO2 in the atmosphere represents two-fifths of sweet FA, as regards the overall constituents of the atmosphere. Two times SFA is still…SFA.
I don’t know. THere have been plenty of studies that show increased growth, as well as resistance to high tempratures, and drought with elevated CO2. This flies in the face of just about everything done in the field.
I aint no biologist, but I reckon they got a lot of proving to do.
Re: #100 You really need to read the material by the Idsos on their CO2science.org site. They have many articles on the interaction between CO2 levels and precipitation, etc. Regardless of what people think about their POV re Global Warming, this is what they’ve worked on their whole careers and they have many peer-reviewed articles on FACE studies. Indeed, going to their site just now, the current editorial is precisely a debunking of one N-limited CO2 fertilization study.
Re. 100
I think there was some embellishment in the ScienceDaily article.
As ET (or Ed) Sid said, I believe there are numerous studies documenting increased growth with elevated CO2.
From the abstract, the authors do not appear to make any claims in their paper regarding vegetation growth related to CO2. In the article, however, one of the authors says:
This indicates to me an obvious method by which elevated CO2 would increase plant growth. And more plant growth means more CO2 uptake (even if the leaf stomata are partially closed).
The 2nd paragraph that you quote from the article appears to be from the author of the ScienceDaily article, not from the paper itself. As far as I can tell from the abstract, the paper only tries to describe the mechanism by which plants regulate their CO2 input, not make any general conclusions regarding growth vs. CO2.
While we’re on the CO2 subject, there is one this which has always struck me as inconsistent in the “greenhouse” argument, as it relates to CO2.
The Sun is the only source of the greenhouse effect (ignoring heating from the Earth’s interior). If CO2 keeps energy in, due to its reflective properties, why doesn’t it also keep an equal amount of energy out of the atmosphere?
In other words, why do climatologists assume that the atmosphere traps more heat, than it reflects? Is there any proof that it does this?
Consider: There is only one serious source of heat considered in climatology today – the Sun [internal Earth heat is considered a very minor contributor].
There are two chocies, when considering increased temp’s – either the Sun is providing more heat, or we are “retaining” more of its unchanging heat.
The AGW’s concentrate on a single grenhouse gas constituent as being the cause of the warming – CO2.
This is the case, even though it makes up between 200 and 400 PPM of the atmosphere. It seems that CO2 has magical properties, which can massively sway the climate, compared with the other 999,800 to 999,600 PPM of elements which make up the balance of the atmosphere.
Let’s put this in context – wherever there is a space with 200 CO2 molecules, there are 999,800 molecules of something else.
The AGW’s don’t suggest that any of the other major consituents are changing, just that the ratio of CO2 is moving from 200:999,800 to 400:999,600. This will cause disaster, pestilence, famine and other unspeakable tragedies.
More than anything, an increase of 0.002% (from 200 to 400PPM) of one greenhouse gas is supposed to increase global temp’s by many orders of magnitude more than simple, pedestrian CO2’s physical profile suggests it would be capable of (increasing temps from 14 to 15 degrees = a 7% increase, for example).
Now, as I have admitted before, I’m not a scientist, but I cannot see (even with the much-vaunted “fedback” and “forcing” mechanisms promoted by the AGW disciples, how an increase of 0.002% in CO2 = 7%+ increase in temp’s.
Re: # 101 to 103
Yes, I must admit, this article was a suprise to me. I concur with your skepticism (or, at least, hesitancy to accept, its results on face value), as it is outside the usual hypothesis.
However, what they have done is a very scientific experiment [sampling tree rings is NOT scientific – it’s purely statistical and its relevance is based on its coincidence with temperature changes]. The authors of this paper have shown that if a plant is exposed to “gorging” conditions, it decides to limit its intake. It’s a very simple experiment to replicate and, if it proves to be replicable, it changes many important variables.
My main point is that it is science, not statistics and models.
Brad:
At the end of the day, the energy in=energy out. It’s just that it does it at a new, higher temperature. The increased CO2 is posited to act more as a barrier to reradiated light than incoming light. This heats the system up until it reaches a new equilibrium (since other radiative losses increase at the higher temp). I mean, a conventional greenhouse gives higher temps also! So it’s at least possible somehow!
Who cares how small the amount of CO2 is? Consider what happens to a nuclear reactor when a tiny steam film (departure from nucleate boiling) is created on the surface of a fuel rod. The answer is rise from 500 to 2000DEG+ temps in milliseconds and failure of the element, causing rupture of fission products into the coolant.
Oh my, Brad. Back to basics on the greenhouse effect for you!
Solar energy in the form of visible light is absorbed by the earth’s surface (though some is reflected as measured by the albedo which is just a fancy word for how much energy is absorbed vs how much reflected.) This absorbed energy heats the surface and it then emits thermal infrared (IR). Now CO2 in the atmosphere absorbs IR of certain frequences but transmits visible light. Therefore it won’t absorb or reflect the visible light incoming but will absorb the IR coming from the surface. Water vapor does the same thing though most of the frequences it absorbs at are different frequencies than those of CO2. The IR absorbed by CO2 and H2O heats the atmosphere and the atmosphere then sends some IR back the the surface heating it more than it would be heated without the greenhouse gasses (there are some theoretical complications here I won’t get into just now).
Since there’s a ton more water vapor than CO2 in the atmosphere (even though it’s not as effective in absorbing as CO2 [this is measured by the extinction coefficient at a given frequency]), most of the greenhouse effect comes from water vapor. Exactly what % of greenhouse effect to assign to H2O vs CO2 is a matter of how you want to look at things and too complicated for a primer. Leave it to say that increasing CO2 will increase absorption of IR and this will warm the atmosphere which will send more IR both toward space and to the surface. Actually, since the total amount of energy arriving and leaving the earth must balance over time, this results in the higher parts of the atmosphere cooling. That way they emit a lower amount of IR to space and things balance. But the lower atmosphere first and the surface second must heat up.
The real issue between warmers and skeptics is whether the additional heating of the surface will result in more H20 evaporating resulting in more absorption in the atmosphere from H20 in a positive feedback situation. Of course this will happen at first, but the question is what happens to the additional H20 emitted. Ultimately it has to rain out, and in the meantime it surely has to be present as droplets in clouds at some point. And clouds can reflect the visible light from the sun on the one hand and absorb or reflect IR from the earth on the other.
What is the actual balance? The dirty little secret of the whole AGW discussion is that nobody knows with any accuracy. Until we do, all the models, which have this dropped into them as a parameter (or a number of parameters), are no better with their results than the number fed to them.
And there you have it, as best I can explain the greenhouse effect.
“The real issue between warmers and skeptics is whether the additional heating of the surface will result in more H20 evaporating resulting in more absorption in the atmosphere from H20 in a positive feedback situation.”
A slight addition to that would be what, if any, is the limiting factor to such a feedback. There is plenty of evidence and research that Greenhouse warming is limited based upon solar input. Diminshing returns and all that.
Well, sure, ET, the feedback has to be less than the input else the earth would be unstable with respect to water vapor and we’d be living on Venus instead of Earth. So a water feedback greater than the amount of the initial CO2 forcing should be impossible.
Not what I’m saying. Suffice to say you did hit on the point that the AGW’ers fail to recognize. They honestly fear us running away to Venus like conditions. Completely ignoring the fact that at some point water starts to work against you, and work hard against you at that.
I think you’ll find that there is littel water inthe atmospher of venus, I still disagree that venus is like it is because of CO2, I blame it’s proximity to the radiator more so.
Venus is hotter than Mercury…
re 86: Willis: sorry I didn’t say what I meant to say. Of course, growth is affected by temperature. What I meant to say is that it is doubtful that small CHANGES in “average yearly temperature” will be reflected in tree ring growth rates.
Re: # 100 and other comments on CO2’s effect on growth. Come on, already: there are HUNDREDS of studies that show that plant growth is stimulated by increasing CO2. Including many very controlled studies, wherein all variables except CO2 are held constant.
111
On average. Look at rotational speeds and the average temprature on each face(mainly due to lack of atmosphere).
The face of mercury that is towards the sun is signifigantly warmer than venus, the side that faces away is signfigantly cooler than venus. Venus sustains a higher Average temrpature only because it still retains an atmosphere.
There ya go. Shows how an atmosphere raises temp.
Re:#100,105
As BKC has already pointed out, the article Brad referred to has nothing to do with determining *whether or not* CO2 concentration changes increase or decrease plant growth or leave it unchanged.
All it does is help clarify the molecular *mechanism* of how CO2 concentration affects stomatal opening size.
Constantly amazed by the depth of discussion on these absolutely critical details at CA. Who knew this thread existed? So many questions to answer … so little time. Thanks for posting the link to this thread, Jean S.
Why don’t you found a Journal: J. Mann. Crit. 🙂
Step 1. Establish an industrial chair in paleoclimatology at a willing host university.
Step 2. Have her establish & edit the “New Paleoclimatologist”. (Why not? There’s already a “New Phytologist”)
Step 3. Enjoy the fireworks.
There is so much discussed here it would be silly to try to reply to everything. As a general comment: it’s amazing how all of you are right, and yet none of you has got the answer.
Tree ring responses are local, in time and in space. That means they exhibit instantaneous responses which are impossible to measure – as time is always moving, and conditions are always changing. So why do dendro people even bother? Willie? Because of scaling and integration. Generalized, or asymptotic, response functions do exist because average (long-term) limitations do exist, and these can be estimated, despite all Willie’s caveats. The problem, as Willie points out, is that the asymptotic responses are weak, largely because the limitating factors vary from time to time, such that the uniformatarian principle is frequently violated. Violated at multiple time scaels, from daily, to annual, to decadal, to centennial, to millenial. The more dynamic the environment, the worse the violation. That is why people often choose sliding windows, to focus on eras when the environment might have been stable. If the window is wide enough to contain lots of data points, but small enough so that environemtnal conditions are stable, then you can estimate (“calibrate”) the various local sensitivity coefficients for periods where you have predictor data. When you do not have these data, you are no longer calibrating, but reconstructing
Now listen, you can’t take a single data stream and decompose it into its varous inputs. THAT’s the problem. That’s why dendro people do univariate reconstructions. That’s why they cherry-pick sites. They try to obtain samples where the asymptotic response matches the local response of the 20th century, and they try to reconstruct the single-most limiting variable, in the long-run. They live and die by this fundamental limitation.
I’m not sure if this thread died because the questions are all answered to your satisfaction, or because you ran out of steam, or got diverted … but they are good questions. And most of them have answers.
The big answer is this: response function analysis is not as robust as some people make it out to be. When you do a responsible accounting of error and propagation of error, the uncertainty on these sensitivity coefficients balloons.
If I can put words in TCO’s mouth, he is asking: “Given all the apparent problems with dendroclimatology, how can some of this be put to use? Must we chuck the BCP data? Or is there a way to use it … responsibly?” I believe his intuition is correct. Willie’s pointed out a ton of real problems. TCO is asking “Yes, but how does this help us understand what the truth is about what paleo data really have to say?”
And that is why the term “uncertainty envelope” is in many ways more appropriate than “confidence interval”, Jean S. Because it is not just a matter of putting bounds on an estimated mean via a standard error. The “mean” is not actually ESTIMATED (by sampling). It is COMPUTED. It is a computation subject to a long chain of possible errors of INFERENCE. Which are vastly different from errors of SAMPLING. Mainly in that they PROPAGATE from calculation to calculation. Focus on THAT. That is paleo’s Achilles heel.
I dare not write another word. My time is up.
I’ve moved the following comments by UC to this post:
Name: UC | E-mail: URI: http://www.geocities.com/uc_edit/ |
#138
Yes, MBH9X CIs are a bit confusing:
MBH98:
The spectra of the calibration residuals for these quantities were, furthermore, found to be approximately “white’, showing little evidence for preferred or deficiently resolved timescales in the calibration process. Having established reasonably unbiased calibration residuals, we were able to calculate uncertainties in the reconstructions by assuming that the unresolved variance is gaussian distributed over time.
MBH99:
In contrast to MBH98 where uncertainties were self-consistently estimated based on the observation of Gaussian residuals, we here take account of the spectrum of unresolved variance, separately treating unresolved components of variance in the secular (longer than the 79 year calibration interval in this case) and higher-frequency bands. To be conservative, we take into account the slight, though statistically insignificant in inflation of unresolved secular variance for the post-AD 1600 reconstructions.
Calibration residuals. That’s not good, but won’t hurt to look into it. They fit proxy records to average temperature, i.e.
where matrix P contains proxies, is a vector of annual temperatures and is the noise vector. True (or approximately true) is known only for the verification and calibration period j=a…b. Calibration residuals are
In MBH98 they find out that looks white (uncorrelated over time). This is generalized, i.e. it is assumed that is white for the whole period. If this holds, sample std of times two would be a good estimate of 2-sigma values. These grow back in time, as they should, so is probably computed with sparser P for earlier periods (all in the above are my guesses).
In MBH99 they find out that is not white (non-flat spectrum, high low-freq component, Figure 2). In other
words, proxy noise is red. I haven’t found supplementary material for MBH99, so the magnitude of redness remains open. MBH99 just
states that “five-fold increase in unresolved variance is observed at secular frequencies’, my guess is that it equals one-lag
autocorrelation of 0.5-0.6. But Figure 2 does not say anything about the absolute variance! All we know is that 2-sigmas in MBH98 were
about 0.3 and in MBH99 they are about 0.5. I think it is impossible to figure out how they’ve done it without supplementary material. In
addition, it would be easier to follow if they had used these definitions when talking about stats:
Gaussian process: A stochastic process is Gaussian if its finite
dimensional distributions are Gaussian. Gaussian density function is
White random sequence: all the are mutually
independent. As a result, knowing the realization of
in no way helps in predicting what x will be in
future.
iid: independent, identically distributed. If a sequence is iid it
is white.
Gaussian process is not necessarily white, and white process is not necessarily Gaussian or iid.
Steve: I’ve tried to fix the Latex.
Posted Sep 29, 9:53 AM | Edit Comment | Delete Comment “¢’¬? Edit Post “Warmest in a Millll-yun Years” | View Post
Name: UC | | URI: http://www.geocities.com/uc_edit/ |
Sorry guys, didn’t work Pdf in here, if someone is interested.
Posted Sep 29, 9:56 AM | Edit Comment | Delete Comment “¢’¬? Edit Post “Warmest in a Millll-yun Years” | View Post
Short version for busy people (without equations):MBH99 figure 2 shows only relative variance. And the y-axis scaling is confusing. It is impossible to tell how red those (12-proxy) calibration residuals are. It is impossible to tell what is the total variance of calibration residuals. Thus, it is impossible to figure out how they computed that 0.5 C 2-sigma.
MBH in Nature, 2006:
The subsequent confusion about uncertainties was the result of poor communication by others, who used our
temperature reconstruction without the reservations that we had stated clearly.
Posted Sep 30, 2:27 AM | Edit Comment | Delete Comment “¢’¬? Edit Post “Warmest in a Millll-yun Years” | View Post
No, can’t explain anything without equations. Let’s derive that 0.67. Power spectrum of AR1 (e.g. Mann Lees 96 paper):
Relative variance is obtained by removing that S0 term. Now, in MBH99, at zero-frequency we have five times the white noise. White noise p=0 gives S(f)=1, makes sense. Now we need to solve p with S(f)=5, S0=0 and f=0. That is easy:
And clearly p=2/3, about 0.67.
Posted Sep 30, 10:07 AM | Edit Comment | Delete Comment “¢’¬? Edit Post “Warmest in a Millll-yun Years” | View Post
#170Thanks for the link, the raw data surely helps! But I’m still not sure if we can compute that 0.5 C without seeing the full 12-proxy reconstruction. Weighting by 2/3 is mentioned, but does it have a theoretical basis even if redness is p=2/3? Maybe that is because they use RE and not RMS. RMS would catch that extra variance due to redness without any extra tricks, right? (if the sample window is large enough). Still a bit confused.
Oh, IMHO, UC, as a Ph.D. student, you should not look too closely to Mann&Lees 96, it may give you too many bad ideas
OK;) Median smoothing of spectrum will remove that peak right away. So, “background noise’ can never be very red.
Posted Oct 2, 10:31 PM | Edit Comment | Delete Comment “¢’¬? Edit Post “Warmest in a Millll-yun Years” | View Post
#120 The equations are missing, makes the text very confusing 😉
Anyway, can’t figure it out. (We have time, 10 years is short time in science ..)
Some intermediate results
Mann Lees 1996:

…
..and one question:
MBH99:
Are these unrelated?
#121. I’ll move the equations – don’t know why they didn’t transfer. The “verification resolved variance” from its value would have to be an RE statistic, although elsewhere it would be a verification r2 statistic. The terminology is so bizarre, isn’t it.
I took another look at the topic yesterday, trying once again to figure out what the MBH99 ignore1 column is. Maybe Gerry North’s request to Mann will glean some insight on this. It would be fun to figure out first.
It’s pathetic and a “distortion of the record” when Wahl and Ammann say they’ve “replicated” MBH when they didn’t even make an effort to figure out these confidence intervals.
re #121: UC, I’m also working again on these issues … you got me interested again 😉 I have some fresh ideas, which I, unfortunately, do not have time to fully test before next week.
Anyhow, I think you should take a look also at the MBH99 preprint, the link is available here. It has some changes w.r.t. to the final version, which may be of help in decoding Mannspeak. I think the key lies in understanding the sentence:
I can barely understand English, not to speak of Mannspeak, so I haven’t figured out what are the “factors noted above” … any help appreciated here.
I’m also in process of digitalizing graphs (residuals) in Figure 2a, which was removed from the final publication. I can already say for pretty sure that the solid line is not what it is supposed to be (NH residuals at AD1820 step), which makes also the corresponding graph in the spectrum figure (Figure 2 in the final MBH99) to be under suspicion … yet another Mannystery it seems…
#122
I googled ‘resolved variance’, and got 2 pages of climate science -related links. (and this is not an accusation, just means that these terms are hard to figure out for others). It sounds like r2 to me, but Mann supplement says:
#123
Thks, got it. Let’s not worry about time, no deadlines. I belong to the ‘fist-language-not-English’ group, and I find MBH99
very hard to understand
But my biggest concern is that if p=2/3 for calibration residuals, that’s red. (Is it possible to change the color of the word ‘red’ to red?)
2° English-speakers are often better than 1° English-speakers at detecting smooth-sounding rhetorical catch-phrases that don’t compute – precisely because they don’t translate well! (To a 1° English-speaker’s ear these phrases are chosen exactly for their effect on their audience: they sound more like pleasant music than unambiguous, reproducible math.)
Which is the other reason turnkey scripts are ideal: they’re culturally sensitive & politically correct.
Does “secular” mean “irrespective of spectral denomination”? So that “secular variance” is variance and “resolved variance” is variance in a particular frequency range?
I think that secular variance is something to do with trend.
I think secular variance is simply the first coefficient in his MultiTaper spectrum estimate (i.e., the “DC coefficient”), see Mann&Lees (1996). There is a toolkit available for calculating the estimate, but I was unable to download it.
Steve, you could put here the residual series I sent you. So if someone gets the MultiTaper Method to work (can download the toolkit or finds other implementations), we could verify if the plotted spectrums (Figure 2/MBH99) match to the residuals.
Good night, North-America, I call it a day and go to sleep 🙂
MTM guide:
Shouldn’t it be , the Nyquist frequency, is the highest frequency that can be resolved for sampling interval
, the Nyquist frequency, is the highest frequency that can be resolved for sampling interval  ?
?
yes
#130 Ok, just checking if I remeber these things right (not a serious problem, Mann uses it correctly later)
Steve:
I think I’m catching up with this. This is related to the problem shown in here (RE, RMSE, etc. are no good if somebody smooths too much)
Let’s write it down in equations:
i.e. reconstructed value at year i equals the true value + noise. Now, if the noise is zero-mean, and autocorrelated, it is not necessarily a problem. But I think this example shows what the real problem is:
Case 1) reconstruction is just the mean of x.
Case 2) n is white noise process,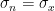 .
.
RE is zero in both cases, right (on the average)? But only in the case 1) the residuals will be correlated in time. Case 1 is actually
which means that
and this means that noise and signal are not independent! Due to this negative correlation, the variance of the reconstruction underestimates the variance of the signal. In the case 1) the reconstruction overestimates the variance of the signal. If we have case 1) and start low-pass filtering the reconstruction, the final limit will be case 2 (only zero-frequency left). Now, how do we choose the low-pass filter so that reconstruction will not underestimate or overestimate the variability of the signal??
#123
That MBH99 pre-print includes a figure of calibration residuals in time domain. That’s exactly what I needed.. This gets interesting.
Digtized residuals are here http://data.climateaudit.org/data/MBH99/MBH99_AD1820_res1.txt
#133
Something wrong with the link (with and without “)
#130-133
So, if residuals and temperature signals are correlated, it means that error is partly a function of temperature. That would mean large errors when temperature rises rapidly (you’ll guess what problem that is), or when temperature decreases rapidly. It would also mean that 2-sigmas are quite hard to construct..
#134. Fixed. Also, courtesy of Jean S, here are AD1000 residuals digitized from the preprint http://data.climateaudit.org/data/MBH99/MBH99_AD1000_res1.txt
re #133: Like I said, they are supposed to be… but at least AD1820 does not seem to match with the residuals calculated directly from the series (calculate also RE, it does not match with the reported, whereas RE calculated from the series residuals does match). So I really do not know what they actually are…
It would be useful if you could calculate the MTM spectrum (see #128) from the residuals, then we would at least know if the residuals correspond to the spectrum figure (which was not removed from the final paper). My preliminary experiments with other spectrum estimators seem to indicate that this is indeed the case.
How hard would it be to emulate the MTM calculation in R? As far as I can tell, what they do is to calculate 6 spectra with different windows (Slepian tapers) and then take an “eigenspectrun”. I don’t know what the statistical properties of this contruct are, but it shouldn’t be all that hard to replicate if it doesn’t download.
BTW can either of you explain the values on the y-axis of their Relative Variance graphic. The scale looks logarithmic, but there’s a value of 0 at the origin. ???
Re #138
Too hard for me. (I have been wanting just such a tool for ~8 years.) The source codes are not accessible, which always bothered me. The irony is that it is not until today that I see and understand the name associated with that software.
#127
Secular means “centennial”
#138
I hope that MTM is not another ad-hoc smoother. Here is something, but don’t take it too seriously.
I think y-axis is logarithmic, and distorted by those significance levels, and with 0 at the origin.
No worries, I was able to reproduce the spectrum figure from the digitalized residuals 🙂 So the “correct” residuals are plotted in the preprint … which makes us really wonder what the heck are those residuals…
Actually this is a bit embarasing: Steve’s request (#138) for code made me think that I faintly recalled having seen Mann’s original Fortran MTM codes somewhere (which I did not download at time as I do not understand Fortran). Well, I tried to locate those codes as I know Steve reads fluently Fortran, and I came accross this page … my own Matlab has an implementation… why didn’t I check it carefully earlier!
Anyhow, I wrap up my research now for this week. I’ll clean up my code, and send it to Steve along with the figure and spectrum estimates, and Steve can put them here if anyone needs them. I’ll be back on these issues on Monday.
There is some details on MTM (pre-Mann) in Park and Lees 1995. Relevant urls:
pdf http://earth.geology.yale.edu/%7Ejjpark/LeesPark_1995.pdf
code http://earth.geology.yale.edu/%7Ejjpark/mtm/MTM.tar
PArk website http://earth.geology.yale.edu/~jjpark/#Publications
#142
🙂 found it! so,
[Pxx,W]=pmtm(res/std(res),3,79,1);
semilogy(W,Pxx)
and then some additional smoothing, and that’s it ?
re #144: I was using the product parameter 2, and I think you should divide by the mean (not std), white noise has a flat spectrum… No smoothing needed, but the first and the last coefficient should be ignored (some implementation issues I suppose??).
I just sent my files to Steve, there seems to be some problems with our mailing system, but I suppose he’ll have them today (Canadian time) anyhow… 🙂
Now the real question is, where did those residuals come from?!?
re #144: Oh, and of course you make the division when plotting, i.e., the input series is raw, not normalized.
#145. To be precise for any passers-by, the source of the residuals is Jean S’ new Mann mystery. There’s still the original mystery of how to calculate MBH99 confidence intervals.
I’va added an update in the text linking to digital versions of the spectrum and showing Jean S’s replication of the MTM spectrum given the residuals.
We’re analyzing figures from preprints that never made it into final papers? What will that get us?
TCO, if the original article contains no explanation of the methodology or citation for the methodology; if the methodology is seemingly not known in the literature; then you try to decode from little snippets of information. To deal with the Hockey Team, you have to get footholds here and there. Look, NO third party knows how these calculations were done. von Storch doesn’t know either. We asked the NAS panel to clarify this but they didn’t. I don’t mean to be impolite, but we’re exploring here. If you want to watch this thread, fine, but give us a little space s.v.p.
re #148: No, TCO, that’s not the case. The same spectrum figure went to the final (Figure 2), and supposingly the uncertainties in MBH99 have something to do with the figure. The figure Steve included above is actually from the print version of MBH99 not from the preprint (Figure2b). It was important to find out that the spectrum actually comes from the residuals (plotted only in the preprint, Figure 2a), so we now know that those residuals should have something to do with the actual uncertainties in MBH99.
However, instead of solving the MBH99 uncertainty problem, this seems to have created another mystery. Namely, it seems that those residuals are not what they are supposed to be, i.e., caliberation residuals (difference in caliberation period between the proxy reconstruction at that step and the instrumental data).
Instead of asking questions with a subtle tone, why don’t you try to figure out where did those residuals come from?
Instead of asking questions with a subtle tone, why don’t you try to figure out where did those residuals come from?
That’s a joke right?
149: I was fully anticipated that answer might be “looking for clues to understand something in the as-published paper”. Just wanted to know if that was the case or if were criticising something that had been edited out.
Re #151
No. It was a quick post by a non-English speaker. What he meant was “TCO, you are a lazy, unhelpful dog. Please go away unless you can contribute materially to the discussion.” Which would have been mean. TCO’s only barking at us to make sure we’re shepherded in the right direction.
#150
Why not? Maybe they are calibration residuals that are negatively correlated with calibration signal (c about -0.25). And then #131 would explain the rest 😉 But need to know how they define residuals, is it or
or  ?
?
BTW, 2 X sample std of residuals is quite close to MBH99 2-sigmas, not exactly but quite close!
#154. The MBH98 ci is 2xMBH98 standard error (from overfitted model but that’s another topic). The post-1600 MBBH99 Ci is increasde only a little, but by a uniform amount from MBH98 results; before 1600, the 99 CI are quite a bit larger than the 98 CIs.
#155
2*sqrt((1/79)*mbh99_ad1000_res1’*mbh99_ad1000_res1)
ans =
0.4622
only 0.02 to go for MBH99 0.48
instrumental+residuals=reconstruction or
instrumental-residuals=reconstruction, depending on the definition.
Infilled Instrumental Data (NH) doesn’t work, neither plus nor minus. Where is the actual instrumental data used in MBH98? Or, where did those residuals come from?!?
Something is wrong here. Something wrong with that time-domain residual data or MBH99 reconstructions are low-pass filtered after the error analysis phase..
Ignore this: Assume two independent, zero mean random processes, x and n. Let![E[x^2]=\sigma _x ^2=1/64](https://s0.wp.com/latex.php?latex=E%5Bx%5E2%5D%3D%5Csigma+_x+%5E2%3D1%2F64+&bg=ffffff&fg=000&s=0&c=20201002) and
and ![E[n^2]=\sigma _n ^2=1/16](https://s0.wp.com/latex.php?latex=E%5Bn%5E2%5D%3D%5Csigma+_n+%5E2%3D1%2F16+&bg=ffffff&fg=000&s=0&c=20201002) . Then
. Then ![E[(x+n)^2]=1/64+ 1/16](https://s0.wp.com/latex.php?latex=E%5B%28x%2Bn%29%5E2%5D%3D1%2F64%2B+1%2F16+&bg=ffffff&fg=000&s=0&c=20201002) . Take a look at MBH99 Fig 3., years 1000-1600. The variance of the reconstruction (x+n) is about 1/100, and the CIs imply that
. Take a look at MBH99 Fig 3., years 1000-1600. The variance of the reconstruction (x+n) is about 1/100, and the CIs imply that 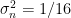 .
.
Although it is certainly interesting, I am not sure what would be the final result of this analysis. Perhaps that the ci were wrongly estimated in MBH98 and MBH99?
I think it would be more useful, andh helpful, to discuss how the ci should have been estimated in a proper way.
agreed. What do you think?
If E[xn]=0, calibration period is long compared to noise correlation time, and driving noise is Gaussian, then there is nothing wrong with 2 X RMSE CIs. But in the case of MBH99, I have no idea how the ci should have been estimated in a proper way.
#159. Hi, Eduardo,
figuring out some of these calculations is a bit like doing a crossword puzzle and you’ve got much of it filled in, but you’re trying to finish it. No harm in that. I started this as a type of crossword puzzle and that continues to be a primary motivation.
At another level, it’s extremely objectionable that the CIs so far can’t be replicated by some pretty competent people trying pretty hard especially when Wahl and Ammann proclaimed to the world that they have “replicated” MBH results (of course, they didn’t touch on CIs).
So bound the problem, for yourself by doing it the right way and seeing what the difference is.
Hi Steve,
I cannot understand either where the ci may come from, specially when there are several around in the literature, e.g. compare the ci at 40 year timescale reported in the IPCC and in Gerber et al Climate Dynamics. So, no objection to that.
My comment was somewhat self-serving, I admit. Quite a few people are trying to put forward new reconstructions, and it would be nice to know beforehand which is the correct method, just to avoid critical comments in CA.. Well, more seriously, I think this could be a topic in which CA could contribute to advance in the methodology that we are trying to use.
Actually I think it would be a very valuable exercise, even if the objective remains cross-word puzzling. Often approaching a problem from different angles gives insights. In addition, it would help to show if this is an ambiguous area. IOW (I don’t know if this is the case) is this a problem where it is hard to say what the right solution is, easy to criticize any choice?
#164. Fair enough. To some extent, I feel like a one-eyed man in the sense that I’m aware of problems (or at least I believe that there are problems) which practitioners are blithely ignoring or pretending not to exist. Solving problems is a different kettle of fish. It’s something that I’d like to do but may not succeed in doing. (Just because you can’t prove a theorem doesn’t mean that your identification of a flaw in someone else’s proof isn’t valid or worth putting on the table.)
To some extent, all I can do is to interest some younger applied statisticians and econometricians in what I believe to be very interesting problems. The interest shown at this blog by Jean S, UC and bender is something that I take particular satisfaction in. It is a sad commentary on present day academic politics that these talented young scholars are unable to participate here under their own names without fear of reprisals for heresy. I’ve received a couple of invitations to present lectures this fall – both from statistics departments, rather than climate science departments.
Obviously one simple expedient is to stop using calibration period residuals for CI estimation. We recommended that in our NAS presentation and they included that in their recommendations in somewhat veiled language (without mentioning us on this point.) Of course this brings the seemingly despised verification period r2 into play as this is obviously linked directly to CI estimation through the verification period residuals. My own guess is that the small-subset reconstructions are all compromised statistically byt “data snooping” and that there are no statistical methods for calculating confidence intervals from dfata sets chosen according to the methods of (say) Hegerl et al or Osborn and Briffa.
should one use the “verification period residuals” or the overall period. Given that the whole division between calibration and verification is rather troubling (unless it is an out of sample verification) how should one proceed?
re #164/#167: Eduardo, as I’m sure you understand, there is no such a thing as the correct method… it all depends. In general, the initial idea of MBH — dividing the instrumental record into the calibration and verification periods — is a good one. There are lot of things you could do better even on the general level though; most obvious being that you should experiment with other divisions of your data, take, e.g., every second sample for calibration and every second for verification. That’s BTW one idea you can find in B&C, now rejected, manuscript that was not IMO highlighted enough. Overall this verification division idea is a good scientific practice. From which we come to (#161):
Since this is not stressed here IMO enough I say it plain and clear: estimating the confidence levels from the calibration period is WRONG and should never be done. This fights against the very idea of dividing your instrumental data into two periods… the reason why you do your division is to check how well your method is working (i.e., if your obtained fit is true or spurious aka overlearning). As long as you have more proxies than the length of your calibration period, you can make a perfect fit with linear regression, and in MBH9(8) style you would then have zero uncertainty…
As a general note (to #164) I say one more thing. IMO people should really give up this “teleconnection” idea in temperature reconstructions as there is no way, a priori, to tell if a “temperature pattern” is “large scale” or “purely local”. Teleconnection in this context is IMO a climatic version of telepathy: a tree in Madrid simply does not care about temperature in Beijing. So instead of taking a bunch of proxies and fitting those with whatever method to some general temperature fields, one should really first fit proxies to the local temperatures and then combine those local temperature estimates into the NH temperature estimate or whatever your target is. I think this should be obvious to anyone if you think that instead of proxies you had 1000 years of measurement data: you do not really want Hamburg series to influence Texas-grid cell, do you?
#168
Yes, you are right, should change calibration to verification in #161. But if those (#136) really are the residuals, we can’t blame them for overfitting! Have you tried to compute RE with these?
This division to secular and higher frequency bands is really interesting. For the FFT, N=79, and sampling rate is 1 1/a. Frequency resolution is then 1/N, 1/79. One possible way to divide to secular and higher bands would be to take the first bin of FFT to one group and others to the ‘higher-band’. Let’s make a silly version of the division:
Raw FFT from the residuals showed that the first bin is 9-times the white noise level. Corresponding AR1 coefficient p would be approximately 0.8. The relative increase of variance due to this p is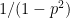 . We want to divide the variance:
. We want to divide the variance:

And
 .
.
But then
 .
.
And this actually holds up to year 1400.
For the post 1600 period, p=1/3 would match. For the 1400-1600 period p with 0.82 would match. I don’t know if these make any sense.
re #170: Well, that’s pretty similar what has been my latest guess for MBH99 uncertainties! 🙂 Could you check that with (at least for 1820 step) with the spectral values above (take mean of first 3 coefficient, 2nd coefficient, or something like that for the secular part) but more importantly compare (if you didn’t do that already) those \sigma_{L/HF} values to those “ignore these columns”. My guess is that the first column is LF and the second is HF 🙂
Yes, 1000-1400 is a very good match with p=0.8, 9 times white noise. 1400-present is still a mystery. But this is not very easy task, there are many MBH9X supplementary material pages in the web, and I’ve seen two different raw data sets and two different MBH98 reconstructions..
Jean S, your emulation does not reach the two-fold (1820) and five-fold (1000) 0-frequency levels. Did you detrend the data? 😉 (Adding -0.0015 C/a trend would fix the problem.)
UC, you are right it does not. No, I did not, as it would a stupid thing to do and it would remove an important climatic signal 😉 Seriously, I don’t think it is detrending here (I tried, didn’t help). The thing is that there are additional parameters involved. E.g., increasing the FFT length raises those 0-levels. Moreover, I think the actual spectrum estimate is median filtered (that is what they did in Mann&Lees(1996), which seems to be the reference). So instead of leaving the first and the last values out (as I did in my code), I think the correct thing to do is to median filter the estimates.
So there are other parameters to figure out if you want to make an exact replication, I’m not claiming that my emulation gives exactly the same values. But the shape is so close that I’m convinced that it was those residuals plotted that gave the spectrum figure, which was the main thing I was interested. Now I only need to figure out where those residuals came from 😉 If you really need the exact values of the spectra, I think the easist way is to digitalize the original figure. Any volunteers? TCO?
But what if those residuals are already detrended (in time-domain plot)? Add
t=linspace(0.05,-0.05,79)’;
residualsAD1000=residualsAD1000+t;
residualsAD1820=residualsAD1820+t;
to your code, and that’s almost exact match. 5-fold and 2-fold.
I hope they didn’t. That MTM already does a lot of smoothing..
Yes. And good question! For example, if you compute the residuals using data from
http://www.ncdc.noaa.gov/paleo/ei/ei_reconsa.html
they are kind of less-than-white-noise at near-zero freq.. Compare those to residualsAD1820.
Need to take a break from climate science, but I have one more question. (Maybe we need to hire somebody who’s been involved in climate science longer than us to solve this) MBH99:
Do they mean that they just divide the residual power spectrum to 2 parts, LF and HF? And then sum those two parts to obtain variance estimate? That wouldn’t make sense,
Or do they mean that they add something to the calibration residual RMS, due to unresolved variance at LF band? Makes more sense, the sample size is short, so it does not necessarily represent the total error variance. But what would be a good value to add?
Long-term variability in the El Niño/Southern Oscillation and associated teleconnections (2000) by MBH mentions this uncertainty issue shortly:
Hmm, interesting, what is Mann et al. 1998b, more detailed analysis ahead ??
Doh, didn’t help. They refer to MBH99.. And this MBH00 continues:
This must mean 2XRMSE (calibration) method for obtaining 2-sigmas. MBH99 CIs are a challenging mystery. And those residuals from the pre-pre-print are not the ones shown in later papers.. Try this script, it produces this kind of figure .
More interesting stuff ahead:
Read http://www.ncdc.noaa.gov/paleo/ei/ei_reconsa.html and check Figure 7 (again, fig. no 7 is interesting 🙂
Caption Figure 7:
and in the text
i.e. they use don’t use the well-known nhmean reconstruction for the pre-1902 period. They use noisier reconstruction. Why is that? Let’s have a look, we have script linked in 177, so easy to see the difference:
The blue line is the famous nhmean. Green is long instrumental. Black dots show this ‘sparse reconstruction’. I computed REs, the sparse reconstruction is less accurate. RE for full reconstruction verification is 0.69, just like they report. RE for this sparse reconstruction is only 0.57. Now, what is going on?
My guess (if I’m wrong, all apologies to MBH):
The full reconstruction seems to underestimate the temperature during the long instrumental. And if you read #131, you know that it is not a good thing. It means that signal and residuals have negative correlation. It means that error is a function of temperature (*). And, it doesn’t look good, if reconstruction underestimates the true temperatures. Someone might the think that the whole reconstruction underestimates the past temperatures!!
(*) i.e. MBH9x reconstructions are accurate, given that there were no large temperature variations in the past. I agree with this.
Here’s link to the figure , if it doesn’t show up.
re #178: I could not exactly understand what you mean, but I followed the links… and this is getting really interesting 😉
Follow your first link, and see the Figure 7 AND the data files linked next to it (“sparse instrumential” and “dense instrumential”). Notice also from the top of the page the link to MBH98 data (“mannnhem.dat”).
“mannnhem” indeed contains the MBH98 data (reconstruction, intrumental 1902->, and uncertainty intervals) (as obtained from other sources).
First, notice that both “dense” and “sparse” files contain data labels something like “rec” and inst/obs. Plotting those you can exactly produce the Figure~7 (if you omit the “sparse” values for post 1902 period). So both files contains intrumental and reconstruction data labelled “sparse” and “dense”.
Now, let’s compare those to “mannnhem”. You see that MBH98 matches those from the “dense” file. But now plot the residuals (recon-instrumental) and compare to the scanned values from the preprint:
reconstruction values from “dense” (i.e. MBH98) – instrumental values from “sparse” = almost perfect match! (I scanned them pretty well, didn’t I 🙂 ) So one problem solved… we now know where those residuals are coming from!
So now it’s time to figure out what are those values in the “sparse” file and which combination of the reconstructions vs. instrumental was actually used for calculating RE values and the “uncertainty levels”.
#180 (contd) Of course, assuming that AD1000 residuals where done the same way as AD1820 residuals, we can now create AD1000-step reconstruction for the period 1902-1980 perfectly, looks pretty interesting 😉
UC’s script is here .
The MBH reconstruction for the “sparse” gridcells is a little different than for the NH as a whole. In the early portions, it is only a re-scaling since there is only one temperature PC, but in later steps can deviate slightly from that.
re #177: Sorry, I did not notice that you had actually tested that data.
If you replace the lines
in UC’s code (#177/#182) with
you get the confirmation what I said in #180.
I think I also have some new information about those RE values. I’ll try to wrap up my findings later today.
Jean S, good scanning accuracy:
mean of errors= 0.0021 C RMSE=0.0031 C, Max error 0.014 C, RE=0.99967
🙂
Anyway, I’m not prepared to pursue my line of inquiry any longer as I think this is getting too silly!
1) MBH99 residuals (Figure 2) are based on Reconstruction – Sparse Temperature, period 1902-1980. Reconstruction is the same that we’ve seen in many publications. I think Sparse Temperature instrument locations are listed in here http://holocene.meteo.psu.edu/shared/research/MANNETAL98/INSTRUMENTAL/gridpoints-ver.loc
and I plotted them in here
http://www.geocities.com/uc_edit/NH_loc/locations.html
2) I get reported calibration RE (http://www.ncdc.noaa.gov/paleo/ei/stats-supp-annual.html) value using Full Reconstruction – Full Temperature (1902-1980)=0.755. And reported verification RE using Sparse Reconstruction – Sparse Temp (1854-1901) divided by Sparse Temp – mean of Full Temp during 1902-1980 =0.6886. Could it be more complicated?
That is, MBH99 Figure 2 residuals are only used to somehow derive those larger CIs. They are computed using Sparse Temperature as a reference. Reported Calibration RE (0.76) is computed using Full Temperature.
3) Sparse Temperature has larger variance than Full Temperature (spatial sampling, u know). My point in #178 is that it seems that in those ‘figures to public’ they choose the reconstructions that match the temporal variance of the instrumental temperature. Even though, according to RE (their selection for an accuracy measure), the shown reconstruction would be less accurate.
4) Is nhem-sparse.dat SPARSE GRID RECON ‘Sparse Proxies calibrated using Sparse Temperatures’ or ‘Full Proxies calibrated using Sparse Temperatures’??
5) Everybody understands that Sparse Instrumental is quite noisy, right? So, when it is used in verification, we do not compare true_temperature vs. reconstruction. We compare true_temperature+ instrumental_noise vs. reconstruction.
6) 2XSTD for Sparse minus Dense Instrumental is 0.3 C (1902-1980). MBH98 reconstruction is more accurate than Sparse Instrumental. Sparse Instrumental contains some 219 thermometers.
Thanks UC! I’m really busy grading some exams today, so could you check these things, please 🙂
Here’s what I think: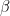 in MBH98, there is no centering! How about if we do not center our instrumental values… I get 0.7551 for caliberation and 0.6886 for verification, which round nicely to the reported values. This would give much simpler explenation for the rather big “reduction” in (verification) RE values repoted in Wahl&Ammann (see Table 1) for which they offer an ad-hoc explenation (Appendix 4).
in MBH98, there is no centering! How about if we do not center our instrumental values… I get 0.7551 for caliberation and 0.6886 for verification, which round nicely to the reported values. This would give much simpler explenation for the rather big “reduction” in (verification) RE values repoted in Wahl&Ammann (see Table 1) for which they offer an ad-hoc explenation (Appendix 4).
-I suppose 0.6886 in 2) (#184) is not actually verification RE reported… For calculating that verification RE you should really use mean of sparse Temp 1902-1980. I know… now the value drops to 0.6838 which is not the reported (0.69).
-However, check the definition of
Summary: I think Mann did not actually calculate RE-values but his own (“resolved variance”), which is not always the same thing!
(“resolved variance”), which is not always the same thing!
Yes,
mean(nhde(1:79,3)) % nhem-dense.dat
ans =
-1.26582278449519e-009
I guess Mann’s Beta assumes that calibration reference is always centered. And I can’t figure out what WA Appendix 4 actually says..
So, is it true that MBH99 CIs (and Figure 2) are computed using sparse temperature as reference, and reported REs are computed using full temperature as reference?
Jean S and UC, if you get time, look at the new CPD paper.
bump. This must have gone offline during our crash crisis.
Since there seems to be some new interest on these issues, I try to summarize for the new readers what is known. Steve, UC, and others could add things I forget to mention.
1) MBH98 CI sigma (s98) is simply RMSE between the reconstruction and the instrumental temperature in the calibration period. This can be verified from the supplementary information table to MBH98 which reports Mann’s “betas”, i.e. RE-statistics. As always with MBH, nothing is perfect: you get perfectly the values for all other steps except for 1750/1760/1780, which all have reported betas of 0.74. I think in this case it is simply a mistake in the table. Notice also that the instrumental series used is the dense (see below).
2) Now, MBH99 CIs are different from MBH98. The key here is to notice that the file contains two columns labeled “Ignore these”. The relation between MBH99 sigma (s99) and the ignore columns (I1, I2) is simply s99^2=I1^2+I2^2. IMO, understanding what are these ignore columns is the key to understanding the whole mystery. The relations to s98: I2^2/s98^2=0.66 (perfectly), but I1^2/s98^2 is bi-level with the cut off time 1600. Before 1600 the ralation is about 2.04 and after about 0.7480.
3) There exists a submission version of MBH99 still available in the WayBack machine. This paper has some additional figures. It has a plot of the residuals (figure 2a) for AD1000 and AD1820 steps. I scanned those (available here). It was noticed earlier that AD1820 step residuals are with respect to the “sparse” version of the instrumental series. Now we have been able to reverse engineer (perfectly) the MBH99 AD1000 step, so it is possible to confirm that also those AD1000 residuals are with respect to the sparse intrumental series. Futhermore, we have been able to reproduce the calibration spectrum figure (figure 2 in MBH99, figure 2b in the submission version), see discussion in this thread/the script in the above link. This shows that CIs of MBH99 might have something to with sparse residuals as the discussion of CIs in MBH99 refers to the figure 2.
We have clues from MBH99:
and from that submission version
Maybe reviewer found something wrong with term Gaussian statistics , and they corrected it to Gaussian residuals (not much better, autocorrelation is the key issue actually).. In addition, the reviewer thought that this is so simple and we have limited space, so cut down it a bit.
Anyway, secular band is inflated, maybe they expand 79-bin FFT’s first bin to equal 1000-bin FFT frequency band, and assume that noise power is flat in that frequency band. Simply take the variance of residuals (sparse) and multiply it by 5*1000/(83*79), and you’ll get (almost) IGNORE1. Remaining part is the non-inflated variance, but there’s now overlap in the first frequency bin (after DC). Thus, you need to multiply the non-inflated variance by 2/3, because someone assumed that 1/3 of it was in the first band originally. I’m not sure if I should put a smiley here or not.
Of course the use of sparse residuals must be a mistake. If someone intentionally decreases residual autocorrelation by using wrong reference data.. Hey, that’s scientific misconduct, manipulation of research processes. Wikipedia:
The Team should very very fast inform us, where do we go wrong?
Myles Allen (Oxford) told Briffa and Juckes in 2005 (when working up a new funding proposal) that he had “tried and failed” to work through MBH error analysis. Isn’t it (long past) time for the climate science “community” to insist that this kind of fiasco be resolved? Either require the original co-authors to publicly present a full and accurate accounting of what they did, or else publicly demand that papers be retracted.
2005: Myles Allen states he could not understand Mann’s error analysis either from directly discussing with him or from trying to reverse-engineer
[emphasis added]
” Isn’t it (long past) time for the climate science “community” to insist that this kind of fiasco be resolved?”
Telling people how MBH99 confidence intervals were calculated? I think that is a trade secret.
Using well-known methods (CCE) to calibration and error analysis would not fit the agenda
With reference to Nicholas’ proposal to sample trees adjacent to a weather station, surely the results would only be valid for that particular place