Eduardo Zorita and I are in the process of reconciling some results. We have taken one issue off the table – VZ implemented Mannian PCs accurately enough that this does not account for any differences between our results and theirs. So I take back some observations and I’ll place updates in appropriate places. In fairness to me, their description in GRL of what they did was perhaps language-challenged, shall we say; my interpretation of their description was the most reasonable one. Other than me, the description was probably not a problem for anyone else, but I was also probably the only one trying to figure out what they did from their description. This proves one more time the advantages of using source code for reconciliation.
By getting this issue off the table, we can try to focus on other issues perhaps accounting for the differences in results e.g. how the pseudoproxies are constructed – which was what we primarily discussed in our GRL article. In this respect, Eduardo has acknowledged that their reconstructions testing the impact of Mannian PCs in an ECHO-G context have high verification r scores in both cases, which certainly suggests to me, as we hypothesized, that their pseudoproxies did not accurately represent the dog’s breakfast of MBH proxies, where the high RE-low verification r2 combination is a distinctive signature that a simulation should replicate. Hopefully there will be more on this.
To benchmark our PC calculations, I posted up a 581×70 network of AR1=0.7 red noise and we exhanged PC results and source code using our respective methods. The following graphic shows our respective implementations of Mannian methods. There’s one small difference which I’ll describe separately in another post, because it’s amusing and because it’s relevant to the trended-nondetrended argument.
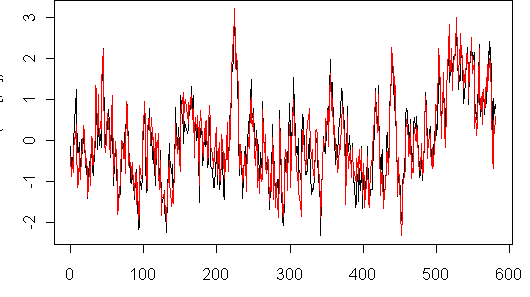
Black, red: Zorita and McIntyre implementations of Mannian PCs on benchmark red noise network.
So if we’re getting the same results on the same data, why have I thought that there was a problem? In their GRL paper, VZ said:
MM05 noted that MBH98 normalized their data unconventionally prior to the PCA, by centering the time series relative to the instrumental-period mean, 1902–1980, instead of relative to the whole available period. Why this was done is unclear. It is, however, not entirely uncommon in climate sciences…
MM05 performed a Monte Carlo study with a series of independent red-noise series; they centered their 1000 year-series relative to the mean of the last 100 years, and calculated the PCs based on the correlation matrix.
If you do PCs using the correlation matrix, you cancel out the impact of the decentering. What Eduardo had done was to de-center the data, making a new matrix X, and then calculated the matrix t(X) * X – which is not a covariance or correlation matrix. However, doing SVD on this matrix will yield Mannian results, although they are not "principal components" within the definition of Preisendorfer, as they are not an analysis of variance. So it’s the description of the method that’s at fault – and, of course, the original method is at fault. But the algorithm used for checking is OK at this step. So my editorial surmises that VZ had not implemented this step "correctly" – in the sense of correctly implementing an incorrect method – were themselves incorrect and I’m updating and annotating accordingly.
It’s possible that there’s an interaction between detrended calibration and the impact of spurious PC1s – intuitively that seems very plausible to me, and that’s on the agenda. Also I am 100% convinced that the VZ pseudoproxies don’t adequately consider "bad apples". This type of robustness analysis is what’s done in "robust statistics" – a very active field.





49 Comments
I found Zorita’s comment asking for a mathematical description of a bad apple to be very apt. Take that and run with it. (More than the r2/RE kerfuffufle: describe the shape of a curve that is a "bad apple"). If you think the method particularly mines for a particular shape, then describe that shape EXPLICITLY. You have hockey stick in the head, but I wonder if that is even the shape that the method most mines for. In any case, if hockey stick is what interests you, describe that.
And I remain a bit concerned as to how much specifically the acentric PCA infleunces the overall result once you include MORE THAN PC1 and once you feed through "rest of Mannomatic".
Steve: we simulated HS-shaped series in our GRL article and archived 100 of them at GRL. So there are some proxies to work with. But this will get sorted out.
I’m lost. Is t(X) the same as X transpose ?
Steve: Yes. I don’t know how to use superscripts in the blog.
TCO, surely you should know how that works by now. The PCA tells you what weight to apply to particular proxies in the final reconstruction. If a particular proxy is especially important to getting the off-center PCA results then it will be highly weighed. If you have doubts of this then there’s no way around your having to actually go through the math on an example. Maybe someone here could make up 10 “proxies” consisting of 10 values each and an ‘instramental’ record of five values for the second half of the total record and show how it works. I wouldn’t mind seeing it myself, though I have no doubts on the general process.
Dave,
A. I follow all that. What does that have to do with my points?
B. The issue is “what is mined” and “how do we define it”. If the method preferentially mines hockey sticks (=bad apples), then we need to define that and prove that. What VZ showed was minimal construction of hockey stick by acentric PCA (versus centered PCA) with Echo-G inputs. Steve says fine, but with bad apples you get mining (and bad apples are different from echo-G). So fine: (1) define what a bad apple is, (2) show that it is present in the data field and (3) show how acentric versus centric PCA changes the mining of that “bad apple”.
C. Pursue the analysis all the way through the Mannomatic to see the actual effect. In particular DON’T do the Ross Mann (that was Freudian and my backspace is not working 🙂 ) crap of talking about PC1 exclusively! For all we know even with only a PC2, let alone “N” of them, the abnormal PC1 is counteracted. But it’s not just an issue of number of PCs, there is the rest of the Mannomatic which dilutes an effect from the PCA (other stuff gets averaged in).
TCO, by definition the weighing of proxies in lower PCs is less than that in higher PCs. Therefore they have less influence. The reason that Mann’s PC4 was influential in the final result using centered data is that the rest of the proxies operate as red noise (or white noise, whatever) leaving the bristlecones as the only trees standing, so to speak. Since they match up with the instrumental record, they still produce a lot of the final shape of the reconstruction once the whole shebang is calibrated. That’s why they’re bad apples, they infect the entire barrel of proxies when they’re present.
Dave:
A. My (and Zorita’s) points/questions is NOT around “what is mining”, it is around “what is a bad apple”. This should be mathematically described. If your definition of a bad apple is one that gets extra weight, fine. How do you define that? How is it different IN CHARACTERISTIC from the things that got less weight? If you want to use a posteiri definition, fine. But WHAT did you come up with? What is a mathematical description of the “type of object” that acentric PCA mines for?
B. All the retained PCs get equal weighting. PC1 is no more important than PC2 in terms of the Mannomatic. The only issue is what gets left in/out. But in all cases (even “not using Preisendorfer’s N”) there are more than one PC. So PC1 by itself is misleading.
Steve M.!
Please make a list of references you use in ALL your posts. I mean a list of used abbreviations (like VGTZ 2009 or whatever) AND a proper reference which includes the authors, year, periodical etc. This could be available to the right of this text whenever needed. I am extremely interested in all these discussions but I (unfortunately) do not remember all reference details when I read the posts. These references are of utmost importance to understand the contents. I have tried to collect prints of most of these prints for myself but now I am not sure that I have updated everything.
with best regards
Larry
BTW referring to the comment reply as VS06 is confusing as there is a more substantive VS paper that came out in 2006 and which we’ve discussed here (the one with “your reconstruction”). Zorita is not on that paper, btw.
You should try to write a paper together.
Best, Lubos
John adds: I added the LaTeX tags by hand. Hopefully this makes Jean’s argument easier to read
Steve (and Eduardo), I think the problem arised from the word "correlation matrix". It is ambiguous.
Let be random variables, and let (the mean, E is the expectation operator) and
Now the covariance matrix is always the matrix whose element is .
Sometimes correlation matrix is used as a synonymous to the covariance matrix, but usually, especially in statistics, it means the matrix of the correlation coefficients, i.e., the matrix whose element is
To add some more ambiguity, sometimes especially in engineering, the correlation matrix means the matrix whose (i,j):th element is (i.e., "noncentered covariance matrix"). If I understood correctly, the last one was the meaning what VZ used.
For those who might not have followed this blog for long, I’ll try to explain what’s this issue with "Mannian PCA", and what’s PCA in general.
First, think instead of a random variables ‘s samples from random random processes, i.e., you have vectors (data)
denotes "time". It could be a tree ring proxy data, for instance.
Now defining the "sample expectation operator" (=average), as for instance the sample mean of would be
you get "sample versions" (or estimators) of the above quantities. Nothing is essentially changed from PCA point of view, so we can talk about covariance matrix and to mean actually the sample covariance matrix.
Now, in principal component analysis (PCA), the idea is roughly the following. You calculate the MxM covariance matrix C. Now the covariance matrix can be written as
where T is the transpose, U is an orthogonal matrix (, I is an identity matrix), D is a diagonal matrix matrix of eigenvalues (nonnegative numbers). Each column of C is called an eigenvector corresponding to an eigenvalue. Now take the eigenvector u (a column in U) corresponding to the largest eigenvalue.
Now the random variable
(i.e., obtained by projecting the ‘s with u) is called the first principal component (PC1). Similarly, taking the column corresponding to the second largest eigenvalue, you get the second principal component, and so on. So principal components are weighted linear combinations of the original variables.
These PC’s have some interesting properties. For instance, it can been shown that the variance of the PC1 (i.e. ) is largest for any unit (i.e., ) projection of ‘s.
Now, what Mann did. He calculated his PC’s, not from the covariance matrix, but from the "correlation matrix" in the above engineering sense! Not only that (there are few instances where that might make sense), (think the sample version) he calculated his "correlation matrix" with data from which he had substracted from ALL samples the mean of the 79 last samples and divided by the square root of variance of the last 79 samples! An unheard procedure, which they claim somehow to be valid. Also, in the original MBH paper, they claim to have done "standard PCA". However, it simple math to show that "Mannian PC’s" have none of the nice properties normal PC’s have. Since some of these properties are actually motivation for PCA, one is left to wonder why they used their own "PCA".
As the final comment, the (sample) PC’s can be calculated directly from the (centered) data matrix with singular value decomposition (SVD), and that’s why Steve is talking about SVD in the context of PCA.
Steve,
VOG comments get lost. I didn’t see your comment until now. My point remains. You have to define what a hockey stick is, mathematically. Maybe you did, in which case, the answer to Z’s Q in the other thread would be: Bad Apple= F(x, y) or something like that.
I believe in Hockey-stick jargon, that would be referred to as, “an innovative, new procedure.”
TCO, ok so call the weighing 1.000 vs 0.000 if that’s how it is. The point is that a proxy which matches the training interval closely, when it’s not an actually proxy is a bad apple. How do you tell if it’s an actual proxy or a bad apple? I’m not sure how that could be described mathematically. One aspect is whether both the low frequency and high frequency data match the training data. OTOH, for some sorts of statistical analysis a proxy might only match at low frequences and not at high frequencies. This is where an actual theory to work from is necessary. Once you have the theory, you can see how individual proxies match up to the theory after you’ve done the analysis.
Take “temperature telecommunications” which is apparently believed in by the Mannians. How exactly does a global temperature affect local RW in some trees when the yearly RWs don’t match the local temperatures? A theory might be that higher global temperatures would increase global precipitation and that therefore either local temperatures or local precipitation or both would be related to RW. But this would have mathematical consequences and tests of the theory could be performed in areas where both had been measured. If this doesn’t improve RW correlation to local variables then something must be wrong with the theory and it should be modified or rejected.
A sample equation could be RW(P,T,t) = k1*P(t)+ k2*T(t) +k3*P(t-1) where P, T & t are precipitation, temperature and time(yrs) respectively and the Ks are constants. Of course you have to have some independent way of measuring precipitation outside the instrumental era, but that’s another story.
Maybe other disciplines should look to Mann for insights. He is expanding the boundaries of applied statistics. Think what advances sociologists, marketers, political pollsters, hedge fund traders, economists, etc. could make if they would just look to paleoclimatology and the new methods being developed there.
Really Mann ought to do these guys a favor and prosyletyze a little. He should write up some articles for J. Appl. Stat., so that others can see what great creations he’s made.
13. The “bad apple” can too be described mathematically. Steve is making an argument that the method mines for a shape. Then he makes the argument that this shape is different from Echo-G pseudo-proxies. Shapes can be described mathematically.
Well, Jean S, I think you managed to go over the heads of about 90% of the readers here. OTOH, I suspect it’s only important for 10% of the people to understand anyway. I actually feel pretty good that I was able to follow more than half of it.
re #17. Ok. You may also try this, this, or this. They won’t discuss Mannian PCA though 😉
re #2: Steve, it is common to use (La)TeX syntax, since that’s the system most mathematical papers are written with. So superscripts are ^ and subscripts _ . Also LaTeX commands start with the backslash, so you see people write Greek letters as \alpha etc., and the sum sign where the index k goes from 1 to n is written as \sum_{k=1}^n . LaTeX is something you should learn additional to R (in order to be a real statistician ;), click here for a nice LaTeX tutorial.
Re #18, Jean S
Thank you for the links. Reading time …
John A – A while back, you were talking about trying a plug-in that would permit more use of mathematical symbology. This would be really useful – I find reading maths in ascii only rather hard. Have you had any joy in finding an appropriate solution ?
(Sorry in advance …)
Oh no, you have to be a CLIMATE SCIENTIST to be able to grasp and apply these new and innovative procedures.
Re #(several), TCO
Let W be the set of ring widths in a tree core. The mean value is MuW.
Let V, a subset of W, be the set of ring widths that correspond to the verification period. The mean value is MuV.
The MBH system will assigns weights to any given tree core as a function of (MuV-MuW)^2 .
As Dave asks, how do you know if it’s a bad apple ?
I guess you would assume that MBH is right in asserting that temperatures over the last millenium are Hockey stick shaped, magically create temperature records for a one hundred year verification period from 1250-1350, say, and see if the MBH method still gives the same results.
It doesn’t, of course – it is going to start focusing on those tree cores whose ring widths in the period 1250-1350 are substantially different from the remainder.
#11. TCO, in our 2005 papers – remember them, we defined a “Hockey Stick Index” as the 1902-1980 mean – minus the long-term mean divided by the long temd standard deviation. It’s not a fancy definition but it enabled us to show histograms from simulations with the curious bimodal distribution illustrated in our GRL article that surprised many people.
TCO,
I think there is a big difference between what we might term a “bad apple” and the amplification of hockey-stick series through the unusual PCA methodology.
A “good apple” proxy is one that conforms to a certain signal + noise model. The methodologies make certain assumptions about the proxies along these lines. But since we don’t necessarily know what the underlying signal is, it can be difficult to demonstrate that a particular series is a “bad apple” per se.
The hockey stick mining is a different issue altogether. Hockey stick mining occurs when there are certain relationships between the mean of a series, the mean of the training period and the mean of the non-training period of that same series. When these differ, they are effectively translated into a component of the variance, causing an amplification of the “variance explained”. Good apples, bad apples and random noise can be influenced by this amplification.
The reality is most likely that there are some horrible interactions between all of these things that are going to be incredibly difficult to unpick.
I also disagree that the R2/RE issue is a sideshow. If you get solid verification statistics, then you can treat the methodology as a black box, even if you don’t understand what it is doing, it’s getting temperature out somehow. Claiming significance this way makes it very easy to blow off everything else with a wave of the hand just saying that others don’t understand. “Statistical significance” is really about showing that what has occurred was unlikely to have happened by chance alone. It is clear that the R2/RE values seen by Mann are really quite likely to have happened by chance alone.
#23: well, fine. That’s the answer to Z’s question. I still think it was quite apt and appropriate for him (or me) to demand that you mathematically describe what you mean.
I dislike a bit using the term “bad apple” btw, since it can (ref #24) confound the issues of “wrong proxies, bad input data” versus a particular shape. It’s irrelevant if the apple is “bad” or “good”. The point is that acentric versus centric does not produce much of a difference with echo-G type input. you make the contention that it does with “hockey stick shaped” input. The issue is the interaction of the method with a particular type of input. “badness” is a confusing concept. MECE, MECE.
#24: Re/R2 is NOT sideshow with respect to the overall discussion of MBH. It IS a sideshow to the issue of forcing Steve to answer Z’s question (or mine) asking for a mathematical description of the “shape” which Steve (un-neutrally) calls a “bad apple”.
#23: I know it’s in your paper. I just think you ought to have repeated the description to answer Z’s question. You need to be pinned down as to what your definition of “bad apple” is.
Steve that is some really fantastic web /virtual collaboration you are engaged in. I like your process. It is the wave of the future.
Re #25
TCO, I don’t think I did “confound” the issue as I read it. I described two separate issues and said there was a non-trivial interplay between them.
I could be wrong, but I don’t see how a mathematical definition of the “hockey-stick”ness of a proxy would help advance the understanding of the problem in the vSZ context. The vSZ model of MBH98 takes as an input a mathematical model of a tree (in effect). The simplistic model being used at the moment is tree ring size = temperature + noise, with a statistical model of noise. This is clearly a very simplistic model, and, as the R2/RE issue shows, an inadequate model to describe what is going on. But determining what a replacement model would need to be is like asking someone to determine the function behind random numbers just by looking at them.
#25. TCO, please stop using tiresome language like suggesting that anyone needs to “force” me to answer a question. I’m generous in replying to questions. I’ve attempted in the past to define HS-shaped series and will work with that definition. I’ve simulated red noise HS-showed series and used these in simulations. I’ve archived them. If that proves insufficient, then I’ll try again. But chill the language that this is somehow being dragged out of me.
We used the term "bad apple" in a specific sense in our Reply to VZ to show the impact of one or two series under Mannian PCA. Mann called the bristlecone HS shape the "dominant component of variance". There are a lot of bristlecone sites in this network since they live a long time and were favorites of early collectors. But you could trim back from 14 to only 2 bristlecone sites and these 2 sites made up the PC1 and Sheep Mountain by itself was the PC2 and Presiendorfer Rule N "significant". If the HS-shape is carried forward into the regression module, it imparts a HS -shape to the reconstruction.
So in robustness terms – to illustrate how the method works – you could have only one bristlecone HS site (Sheep Mountain) and this one site could dominate the reconstruction. It becomes the PC2 in the PC phase; and then in the regression phase, which has a second data mining, it gets overweighted and imprints the reconstruction.
Where VZ go astray in their criticism of us is that they don’t simulate crappy proxies. Their pseudoproxies are too "good" and a single HS series can’t affect it. We’ll see how things go, but I’m optimistic that Eduardo and I are going to agree on empirical calculations.
Steve,
To use superscripts and subscripts put in special tags which you can see by editing this comment.
JohnA
Edit: I put these tags in originally and the software removed them. I then edited the comment and they’ve stayed. Go figure
#31. ?????
Steve:
If you’ve mathematically described the definition of “bad apple” great, all the easier than for you to repeat it explicitly as a math formula. (It’s not just me, Z asked.)
“Bad apple” remains a potentially confusing term. A shape descriptor: “skewed” or “hockey stick” or the like would be better.
Just because the PC1 is impressively impacted does not mean that the overall reconstruction is impressively (or perhaps even at all) impacted.
P.s. I respect you.
You’re completely missing the relationship between the NOAMER PC1 and the reconstruction. The NOAMER PC1 directly and impressively impact the Mannian reconstruction. That was common ground between Mann and ourselves in the aftermath of MM03, where the difference between the MM03 graphic and MBH98 was traced by Mann to the NOAMER PC1. Look at MBH 2003 (Internet). Because it was common ground, we perhaps didn’t exhaustively discuss the point, but the issue is not in dispute.
A. What/where is MBH 2003 (Internet)? I can’t find it on Google or this site.
B. I’m not missing the point that PC1 is a part of the overall reconstruction and influences it. But they’re not synonymous. For GENERAL investigations, you need to check methodology impacts (e.g. acentric PCA or even some new issue) on the end product reconstruction. Otherwise, if you only look at PC1, you might over (or under) emphasize the impact of the concern you are examining. Heck, if we try hard enough, maybe we can find some “lever” to pull where the “increase HSishness of PC1” is completely counteracted by some impact on PC2 (or other PCs). Bottom line is that the PC1 is an intermediate. That’s why John Hunter gigged you in Feb 2005.
Look at http://www.climateaudit.org/?page_id=354 for the URL.
#35. Of course I know that it’s an intermediate. But the examination of it in particular began only after it had been identified as the ingredient that accounted for the difference in high MM03. You know, the supposed "throwing out" of proxies that we keep hearing about. MM03 resulted in the identification of the MBH reconstruction standing or falling on the NOAMER PC1; that’s why it’s been a battleground issue. But I didn’t pick this issue. Mann was the one who identified it. Again, for someone coming in the middle, the issue may seem unmotivated, but it wa always perfectly clear to Mann.
Also for what it’s worth, I did the simulations with a network of white noise to prove the point that Hunter was inquiring about. I posted that up in May some time. I used this approach in the new simulations on the RE statistic, published in Reply to Huybers. These are quite relevant simulations since they destroy the RE benchmark applied in Wahl and Ammann. The Wahl and Ammann submission to GRL purporting to refute these calculations was rejected.
I’m not saying that you don’t know that PC1 is an intermediate. I’m saying that you (and Ross) often skip by this issue in discussion. That’s why John had a legitimate gripe in FEB2005 about an assertion that you made. It’s not a test of what you know or a question of “have you ever touched second base”. You have to touch it on every trip around the bases. Otherwise, it doesn’t count as a home run. It’s not logically sound to refer to PC1 when what we care about is the overall hockeystick.
Look step back for a second. Imagine that I have changed some part of the MBH reconstruction (data, method, whatever). I show you that the PC1 got a more extreme hockey shape stick to it as a result of my change. Do you KNOW (like you would bet your ass on it) that the overall reconstruction will become more hockey stickish? I mean I bet that I could somehow (with reverse engineering if I had to) come up with some knob to tweak that would increase the HS contribution from PC1, but decrease it even more in PC2. In any case, the degree of change of the PC1 will be different than the degree of change of the reconstruction.
#36: I found what you’re talking about. (It’s called MBH2004 btw).
A. (From reading) Mann clearly makes a caveat here that looking at PC1 is for purposes of simplicity in some particular examinations and in particular wrt the impact on 1400-1500 values. He doesn’t give you carte blanche for any knob you turn or analysis you run or point you argue to conflate PC1 and the overall reconstruction. And in any case, what he’s doing here is correct to explicitly explain that he is looking at PC1 versus the overall. He clearly explains his simplification. You (or Ross) sometimes gloss over the difference.
B. Citing agreement of your “opponent” doesn’t make it correct, Steve. Even if the Yankees let the Blue Jays go past second base without touching it, the umpire won’t. And I don’t trust these Yankees to know the rules anyhow…
You’re getting very boring, TCO. Stop hectoring Steve and go learn something about PCA. Read the links from Jean S in #18 above.
Agreed. I’m sick of the point.
I’m going to leave the blog (not for this reason…just need to get more work done).
I’ve edited Jean S’s comment for LaTeX, so hopefully it should be easier to read.
Re #42, John A
John, does this provide a route to making the sup/sub/etc tags work ?
Let’s see if this works
Yes.
Excellent. Thanks, John.
At the risk of being greedy, any chance of allowing the img tag, so we can do the latex stuff ?
lessthan img src=”/cgi-bin/mimetex.cgi?\mu_i=E[X_i]”/ greaterthan
Only so long as it’s not abused. I’ll look at it tomorrow.
Hughes has been heard to say that he believes that the statement about the “warmest decade in 1000 years” was correct with probability 66 percent.
http://julesandjames.blogspot.com/2006/04/hockey-stick-wars-round-xxvii.html#comments
Not much.
The 66% comment is interesting. You’ve got 100 decades in a millenia. So a 66% odds on one of those 100 being the premier one is impressive. Now we actually have 20 decades of observed records (about). So if that decade is the warmest of those 20, making a coment that it is the warmest of 200 is a bit less impressive. Perhaps still impressive though. Need some math inserted here. Some little person do that please. I’m more of a strategy guy…