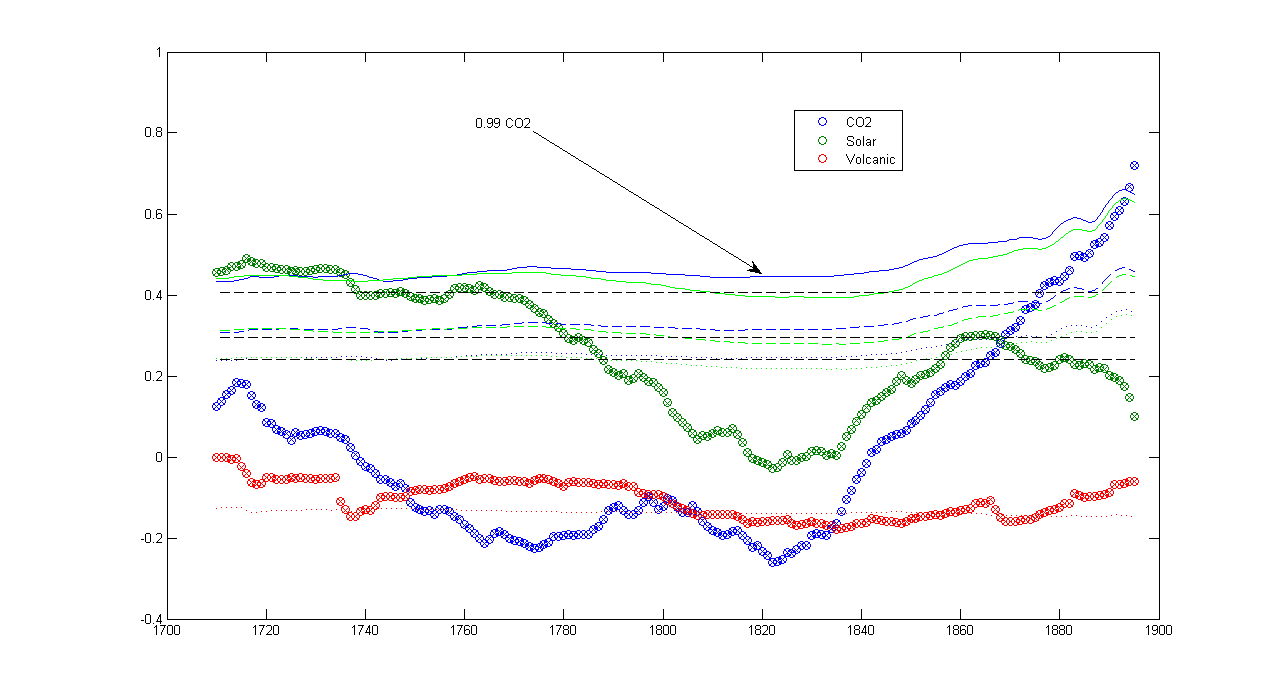
There’s an interesting knock-on effect from the collapse of MBH98 Figure 7 (see here and here). See update from UC in May 2011 below in which he did a “bit-true” replication.
We’ve spent a lot of time arguing about RE statistics versus r2 statistics. Now think about this dispute in the context of Figure 7. Mann "verifies" his reconstruction by claiming that it has a high RE statistic. In his case, this is calculated based on a 1902-1980 calibration period and a 1854-1901 verification period. The solar coefficients in Figure 7 were an implicit further vindication in the sense that the correlations of the Mann index to solar were shown to be positive with a particularly high correlation in the 19th century, so that this knit tightly to the verification periods.
But when you re-examine Mann’s solar coefficients, shown again below, in a 100-year window, which is a period that is sized more closely to the size of the calibration and verification periods, the 19th century solar coefficient collapses and we have a negative correlation between solar and the Mann index. If there’s a strong negative correlation between solar and the Mann index in the verification period, then maybe there’s something wrong with the Mann index in the verification period. I don’t view this as an incidental problem. A process of statistical “verification” is at the heart of Mann’s methodology and a figure showing negative correlations would have called that verification process into question.

There’s another interesting point when one re-examines the solar forcing graphic on the right. I’ve marked the average post-1950 solar level and the average pre-1900 solar level. Levitus and Hansen have been getting excited about a build-up of 0.2 wm-2 in the oceans going on for many years and attributed this to CO2. Multiply this by 4 to deal with sphere factors and you need 0.8 wm-2 radiance equivalent. Looks to me like 0.8 wm-2 is there with plenty to spare.
I know that there are lots of issues and much else. Here I’m really just reacting to information published by Mann in Nature and used to draw conclusions about forcing. I haven’t re-read Levitus or Hansen to see how they attribute the 0.2 wm-2 build-up to CO2 rather than solar, but simply looking at the forcing data used by Mann, I would have thought that it would be extremely difficult to exclude high late 20th century solar leading to a build-up in the oceans as a driving mechanism in late 20th century warmth. In a sense, the build-up in the ocean is more favorable to this view as opposed to less favorable.
None of this "matters" to Figure 7. It’s toast regardless. I’m just musing about solar because it’s a blog and the solar correlations are on the table.
UC adds [may 2011]
With window length of 201 I got bit-true emulation of Fig 7 correlations. Code in here. Seems to be OLS with everything standardized (is there a name for this?), not partial correlations. These can quite easily be larger than one.
The code includes non-Monte Carlo way to compute the ‘90%, 95%, 99%
significance levels’. The scaling part still needs help from CA statisticians, but I
suspect that the MBH98 statement ‘The associated confidence limits are approximately constant between sliding 200-year windows’ is there to add some HS-ness to the CO2 in the bottom panel:

(larger image )
This might be outdated topic (nostalgia isn’t what it used to be!). But in this kind of statistical attribution exercises I see a large gap between the attributions (natural factors cannot explain the recent warming!) and the ability to predict the future:





{kind=link}
181 Comments
Leaving aside the issue of Mann’s wordings and claims wrt a 100 year window, the 200 year window makes more sense than a 100 year one since it includes more data.
Leaving aside the issues of Mann’s incorrect methodology, cherry-picking, false claims of robustness, misleading descriptions, bad data, abysmal statistical control, his paragraphing and punctuation are excellent.
[sarcasm OFF]
The data is bad, TCO. It doesn’t matter how wide the windows are.
Sure. But that is a seperate criticism. If you read Chefen (or McK, can’t remember), he makes the specific point that this is an error of methodology. Don’t do that weaving thing that Steve does sometimes when I want to examine the criticisms one by one.
Changing from a 200 to 100 year window should not cause the correlations to collapse like that though. If the correlations are real then the change should be minor, at least until you get down to the different signal regime below 10 years-ish. That the correlations are so dependent on window choice indicates that either the correlation method is wrong or the signals are in fact not correlated.
You can say “it adds more data”, but that is neither a positive nor negative act without a good justification. After all, why not just correlate the *entire* data set then?
Here’s a question, what sort of signal will correlate randomly well or badly with a given other signal depending on the choice of window length?
#1, #3, TCO…
the simple linear logic of your statement in #1 then makes an argument for a 500 year window, or a 1000 year window, or 10,000…simply because it “contains more data” does NOT mean it is optimal. robustness may fall apart at 10 or 20 year windows (decadal fluctuations, anyone?), but 100 years should be sufficient if the data are any good.
This is posted for Chefen who’s having trouble with the filter:
Changing from a 200 to 100 year window should not cause the correlations to collapse like that though. If the correlations are real then the change should be minor, at least until you get down to the different signal regime below 10 years-ish. That the correlations are so dependent on window choice indicates that either the correlation method is wrong or the signals are in fact not correlated.
You can say "it adds more data", but that is neither a positive nor negative act without a good justification. After all, why not just correlate the *entire* data set then?
Here’s a question, what sort of signal will correlate randomly well or badly with a given other signal depending on the choice of window length?
TCO, I don’t think that the main issue is even whether a 100-year window or 200-year window is better. That’s something that properly informed readers could have decided. But he can’t say that the conclusions are “robust” to the window selection, if they aren’t. Maybe people would have looked at why there was a different relationship in different windows. Imagine doing this stuff in a prospectus.
It’s the same as verification statisitcs. Wahl and Ammann argue now that verification r2 is not a good measure for low-frequency reconstructions. I think their argument is a pile of junk and any real statistician would laugh at it. But they’re entitled to argue it. Tell the readers the bad news in the first place and let them decide. Don’t withhold the information.
The “window” is a moving average filter, right?
Mark
#7: Steve, read the first clause of my comment. I’m amazed how people here think that I am excusing something, when I didn’t say that I was excusing it. Even without the caveat, my point stands as an item for discussion on its own merits. But WITH IT, there is a need to remind me of what I’ve already noted?
I make a point saying, “leaving aside A, B has such and such properties”, and the response is “but wait, A, A, A!”. How can you have a sophisticated discussion? RC does this to an extreme extent. But people here do it too. It’s wrong. It shows a tendancy to view discussion in terms of advocacy rather then curiosity and truth seeking.
Chefen, Mark and Dave: Thanks for responding to the issue raised. Although I want to think a bit more about this. I still think the 200 years is better then the 100 (and 500 even better, but I’m open to being convinced of the opposite, for instance there are issues of seeing a change rapidly enough…actually this whole thing is very similar to the m,l, windows in VS06 (the real VS06, not what Steve calls VS06). (For instance look at all the criticism we’ve had of the too short verification/calibration periods–it’s amusing to see someone making the opposite point now.) As far as how much of a difference in window causes a difference in result and what that tells us, I think we need to think about different shapes of curves and to have some quantititive reason for saying that 200 to 100 needs to have similar behavior, but 200 to 10 different is ok–how do we better express this?
Steve and John: boo, hiss.
TCO Nobody cares which window you think is better, the MBH claim was that window size does not matter (“robust”), but it does matter. Therefore the claim does not hold.
I disagree TCO, because it is a “moving window”, I don’t think that the size of the window is nearly as important as the congruence between results from different window sizes. Correct me if I am wrong, but you are viewing the data in the window over certain time periods, and any significant variance between the results in, say, the 200 and 100 year windows does require explanation. The variance we apparently see suggests very strongly that either different processes are at work over the different time scales, or that no real correlation exists.
I know you are not supporting the 200 year window exclusively, but I do think you are de-emphasising the startling divergence of the results.
Now where is Tim Lambert when you want him, I hope he observes this issue and adds it to the list of errors (being polite) made by Mann et al. His post on this is going to get seriously large !
Ed: I’m just struggling to understand this intuitively. Is there a window size that makes more than another one? How much should 100-200 year windows agree, numerically? Is there perhaps a better way to describe the fragility of the conclusions than by susceptibility to changed window size? Some other metric or test? Intuitively, I think that Mann’s attribution efforts are very weak and sketchy and rest on some tissue paper. Yet, also intutitively, I support larger data sets for correlation studies than smaller ones. The only case in which this does not make sense is where one wants to really narrow into correlation as a function of time (really you want the instantaneous correlation in that case and the less averaging the better). But it’s a trade-off between accuracy of looking at the system changing wrt time, versus having more data. I’m just thinking here…
I guess in a perfect multiple correlation model, we would expect to have an equation that describes the behavior over time and that the correlation coefficients would not themselves be functions of time. That’s more what I’m used to seeing in response mapping in manufacturing. Might need a couple squared terms. But there are some good DOS programs that let you play with making a good model that minimizes remaining variance and you can play with how many parameters to use and how many df are left. Really, this is a very classic six sigma/DOE/sociology type problem. I wonder what one of them would make of the correlation studies here.
Why in the hell do you want Tim Lambert’s opinion. He doesn’t even understand this thread!
RE: #14. Well it is entertaining to watch him put his foot in it. 🙂
Re: 13. I would vary it from 1 to 300 and plot the change in correlations. How do you know 100 is not cherry picking?
TCO, regardless of exactly what features you’re trying to zoom in on the fact remains that the correlations should be fairly stable at similar time scales *until* you run into a feature of one of the signals. All the features of sigificance lie around the 10-year mark, there is the 11-year sunspot cycle in the solar data and the 10-year-ish switch over in power law behaviour of the temperature data. There isn’t really anything else of significance, particularly on the 100+ year level. So while the correlations may alter somewhat in going from a 100 to 200 to 300 year correlation, they definitely shouldn’t dramatically switch sign if the signals *truly* are correlated that well at 200 years. If they are actually uncorrelated then the behaviour would be expected to vary arbitrarily with window size, without any further knowledge.
You can reasonably suggest that the true dependence is non-linear and that is stuffing things up. But then where does the paper’s claim of “robustness” with window size come from?
TCO, as Chefen’s post makes clear, the “optimal” window size depends on the theory you are trying to test. I don’t think it is something that can be decided on statistical grounds alone. For example, if you theorized that the “true” relationship was linear with constant coefficients you would want as long a data set as possible to get the best fix on the values of the coefficients. On the other hand, if you thought the coefficients varied over time intervals as short as 10 years you would want narrow windows to pick up that variation. If the theory implies the relationship is non-linear, you shouldn’t be estimating linear models in the first place, and so on. The point here, however, is that these results were presented as “robust” evidence that (1) the temperature reconstruction makes sense and (2) that the relative importance of CO2 and solar, in particualr, for explaining that temperature time series varied over time in a way that supported the AGW hypothesis. We have seen from the earlier analysis that the purported temperature reconstruction cannot be supported as such — the supposed evidence that it tracked temperature well in the verification period does not hold up, the index is dominated by bristlecones although the evidence is that they are not a good temperature proxy, there were simple mistakes in data collection and collation that affected the reconstruction etc. Now we also find that the supposed final piece of “robust evidence” linking the reconstruction to CO2 and solar fluctuations is also bogus. One can get many alternative correlations that do not fit any knwon theory depending on how the statistical analysis is done, and no reason is given for the optimality of the 200-year window. Just a bogus claim that the window size does not matter — one gets the same “comforting” results for smaller window sizes too.
The thing is this looks like the tip of the attribution iceberg. Just taking one major attribution study, Crowley, Science 2000, “Causes of Climate Change over the Past 2000 Years” where CO2 is attributed by removing other effects, you find Mann’s reconstruction. So much for it ‘doesn’t matter’.
Its been argued that greater variance in the past 1000 years leads to higher CO2 sensitivity. But that is only if the variance is attributed to CO2. If the variance is attributed to Solar, then that explains more of the present variance, and CO2 less.
The end of Peter Hartley’s post (#18) is such a nice summary of these results that I want to give it a little more emphasis. So anyone strugling to understand the meaning of these latest results, and their relation to Steve’s earlier findings, I suggest you start from this:
#19. Take a look at my previous note on Hegerl et al 2003, one of the cornerstones. I haven’t explored this in detail, but noticed that it was hard to reconcile the claimed explained variance with the illustrated residuals. We discussed the confidence interval calculations in Hegerl et al Nature 2006 recently.
Now that we’ve diagnosed one attribution study, the decoding of the next one should be simpler. The trick is always that you have to look for elementary methods under inflated language.
We didn’t really unpack Hegerl et al 2006 yet – it would be worth checking out.
#21. Yes the Hegerl study started me on a few regressions. I had some interesting initial observations. Like very high solar correlation and low to non-existent GHG correlations with their reconstructions. One hurdle to replication is expertise with these complex models they use even though they are probably governed by elementary assumptions and relationships. Another thing you have to wade through is the (mis)representation. In Hegerl, because the pdf’s are skewed, there is a hugh difference between the climate sensitivity as determined by the mode, the mean and the 95 percentile. The mode for climate sensitivity, i.e. the most likely value for 2XCO2 is very low, but not much is made of it.
Any comments on the the implications to Mann and Michael Mann and Kerry Emanuel’s upcoming article in the American Geophysical Society’s EOS? Science Daily has an article about it at http://www.sciencedaily.com/releases/2006/05/060530175230.htm
Some key quotes include:
and
and
and
#22. The skew was one reason for plotting the volcanics shown above. That distribution hardly meets regression normality assumptions.
#24. Yes, and the quantification of warmth attributed to GHGs arises from a small remainder after subtracting out much larger quantities, over a relatively short time frame.
Re #23: With all eyes here focused on hockey sticks, occasionally in the distance a leviathan is seen to breach. Pay no attention.
In addition to the CO2-solar-temperature discussion here, Mann refered to Gerber e.a. in reaction on my remarks on RC about the range of variation (0.2-0.8 K) in the different millennium reconstructions. The Gerber climate-carbon model calculates changes in CO2 as reaction on temperature changes.
From different Antarctic ice cores, the change in CO2 level between MWP and LIA was some 10 ppmv. This should correspond to a variation in temperature over the same time span of ~0.8-1 K. The “standard” model Gerber used (2.5 K for 2xCO2, low solar forcing) underestimates the temperature variation over the last century, which points to either too low climate sensitivity (in general) or too high forcing for aerosols (according to the authors). Or too low sensitivity and/or forcing for solar (IMHO).
The MBH99 reconstruction fits good in the temperature trend of the standard model. But… all model runs (with low, standard, high climate sensitivity) show (very) low CO2 changes. Other experiments where solar forcing is increased (to 2.6 times minimum, that is the range of different estimates from solar reconstructions), do fit the CO2 change quite well (8.0-10.6 ppmv) for standard and high climate sensitivity of the model. But that also implies that the change in temperature between MWP and LIA (according to the model) is 0.74-1.0 K and the Esper (and later reconstructions: Moberg, Huang) fit the model results quite well, but MBH98 (and Jones ’98) trends show (too) low variation…
As there was some variation in CO2 levels between different ice cores, there is a range of possible good results. The range was chosen by the authors to include every result at a 4 sigma level (12 ppmv) of CO2. That excludes an experiment with 5 times solar, but includes MBH99 (marginally!).
Further remarks:
The Taylor Dome ice core was not included, its CO2 change over the MWP-LIA is ~9 ppmv, which should reduce the sigma level further. That makes that MBH99 and Jones98 are outliers…
Of course everything within the constraints of the model and the accuracy of ice core CO2 data (stomata data show much larger CO2 variations…).
Final note: all comments on the Gerber e.a. paper were deleted as “nonsense” by the RC moderator (whoever that may be)…
This leaves what left?
Re #23
Jason, according to the article:
Have a look at the IPCC graphs d) and h) for the areas of direct and indirect effect of sulfate aerosols from Europe and North America. The area of hurricane birth is marginally affected by North American aerosols and not by the European aerosols at all, due to prevailing Southwestern winds…
Further, as also Doug Hoyt pointed out before, the places with the highest ocean warming (not only the surface), are the places with the highest insolation, which increased with 2 W/m2 in only 15 years, due to changes in cloud cover. That points to natural (solar induced?) variations which are an order of magnitude larger than any changes caused by GHGs in the same period. See the comment of Wielicki and Chen and following pages…
Re #27,
Comments about the (global) temperature – ice core CO2 feedback were nicely discussed by Raypierre.
Steve,
MBH98 has been carved up piece by piece here. In fact, there have been so many comments regarding its errors that it’s nigh on impossible to get a feel for the number and extent of the problems.
Ed’s comments to the effect that Tim Lambert’s post on the list of errors must be getting substantial got me thinking – wouldn’t it be nice to have a post, with a two column table and in one, place the MBH claim, while in the other, place a link to the Climate Audit post(s) refuting it. That would be a really powerful way to summarise the body of work on this blog relating to that paper.
You could call it, “Is MBH98 Dead Yet?”, or maybe, “Come back here and take what’s coming to you! I’ll bite your legs off!”
#31. I guess you’r referring to the famous Monty Python scene where the Black Knight has all his arms and legs cut off and still keeps threatening. David Pannell wrote about a year ago and suggested the simile for the then status of this engagement. I guess it’s in the eye of the beholder because I recall William Connolley or some such using the same comparison but reversing the roles.
There’s a lot of things I should do.
Yep, that’s the one. Did William Connolley really do that? Honest? 😉
1. If the model shows correlation coefficients of factors varying as a function of time, then we’re not doing a good job of specifying the forcings in the system.
2. I still want some numerical feel for why and how much 100-200 may not differ and the reverse for 200-10. If you can’t give one, then maybe the differences are not significant.
3. Hartley: but A! but A!
TCO, as regards 1. and 2. you need to look back at comments #17 and #18. The answers are right there and can’t be made much simpler. You need to consider what exactly correlation coefficients are and think about how you’d expect them to behave given the properties of the data you have.
Here is a question for those with the technical ability, software, time and inclination (of which I have one of the four – I’ll leave you to guess which).
This problem appears to be asking for the application of the Johansen technique.
We have multiple time series and we have an unknown number of cointegrating relationships. Johansen would help us discover which ones matter, if any, and with what sort of causality. At the same time it was sepcifically designed to be used with non-stationary time series so will easily stride over the problems of finding correlated relationships in stochastically trended series such as these.
Steve, I am sure Ross would be familiar with Johansen and could do some analysis.
Chefen: Disagree. Answer to my question 2 is non-numeric. Give me something better. Something more Kelvin-like. More Box, Hunter, Hunter like. On 1, think about it for a second. If I have a jackhammer feeding into a harmonic oscillator of springs and dampers, does that change the relationship F=mA over time? No. If you understant the system, you can give a relationship that describes the behavior. Sure the solar cycle as a FORCING may be changing over time. But if you have modeled system behavior properly, that just feeds through your equation into output behavior.
If CO2 is more highly correlated with a 200 year window then a 100 year window then that could suggest; that the climatic response to C02 is slow. That is there is a time lag. However the slower the response of the climate to CO2 the less information there is to estimate that correlation. The rise in the correlation for the 200 year window towards the end of the millennium I think is problematic because it suggests that the response to CO2 might not be linear with the log of the CO2. However, this is all conjecture Mann’s results have been shown to be week.
Something confuses me about the CO2 graph. It says it is plotting the log of the CO2 but the curve looks exponential. If CO2 is rising exponentially shouldn’t the log of it give a straight line. If that is the log of CO2 then CO2 must be rising by e^((t-to)^4) or so. Has anyone verified this data?
re #39: John C, it says indeed in the figure that it’s “log CO2”, but it is actually the direct CO2 concentration (ppm), which is used (without logging) for the correlation calculations as Steve notes here. Don’t get confused so easily, the whole MBH98 is full of these “small” differencies between what is said what is actually done. 🙂
I don’t know if anyone is interested in this but with all the criticisms of Mann’s work I have been thinking if I could devise a more robust method of determining the correlation coefficients. My method starts by assuming that the signal is entirely noise. I use the estimate of the noise to whiten the regression problem (A.k.A weighted least means squares).
I then get an estimate of the regression coefficients and an estimate of the covariance of those regressions coefficients. I then try to estimate the autocorrelation of the noise by assuming the error in the residual is independent of the error in the temperature due to a random error in the regression parameters. With this assumption I estimate the correlation.
This gives me a new estimate of the error autocorrelation which I can use in the next iteration of the algorithm. This gave me the correlation coefficients:
0.3522 //co2
0.2262 //solar
-0.0901 //volcanic
With the covariance matrix
0.0431 -0.0247 0.0008
-0.0247 0.0363 -0.0002
0.0008 -0.0002 0.0045
Where the correlation coefficients relate how one standard deviation change in the parameter causes a standard deviation change in the temperature where the standard deviation is measured over the instrumental records.
The algorithm took about 3 iterations to converge. Using the normal distribution the 99% confidence intervals are given by:
0.2413 0.4631 //co2
0.1326 0.3197 //solar
-0.1017 -0.0784 //volcanic
Which is about:
0.1732 standard deviations
I am not sure how this method relates to standard statically techniques. If anyone knows of a standard technique that is similar or better please tell me. Some points of concern is that I was not able to use the MATLAB function xcorr to calculate the autocorrelation as it resulted in a non positive definite estimate of the covariance matrix. I am not sure if my method of calculating the correlation is more numerically robust but I know it is not as computationally efficient as the MATLAB method since the MATLAB method probably uses the fft.
Also I found most of my noise was very high frequency. I would of expected more low frequency noise. I plan to mathematically derive an expression for the confidence intervals for signal and noise with identical poles which are a single complex pare. I think this is a good worst case consideration and it is convenient because the bandwidth of both the signal and noise is well defined.
The bandwidth is important because it is related to the correlation length which tells us how many independent verifications of the signal we have. I could also do some numerical tests to verify this observation.
function RX=JW_xcorr(a,b,varargin)
L=length(a);
RX=conv(a(end:-1:1),b);
adjust=zeros(size(RX));
adjust(:)=(abs((1:length(RX))-L)+1);
RX=RX./adjust/RX(L);
function y=normalConf(mu,P,conf)
if sum(size(P)>1)==1; P=diag(P); end
y=zeros(length(mu),2);
for i=1:length(mu)
low=(1-conf)/2;
delta=sqrt(2)*P(i,i)*erfinv(2*low-1);
y(i,:)=[(mu(i)-abs(delta)) (mu(i)+abs(delta))]
end
%%%%%%%%%%%%%Script to process the data bellow%%%%%%%%%%%
%%%%%%%%%%%%%Part I load the data%%%%%%%%%%%%%%%%%%%%%%%%
clear all;
%%%%%%%%%%%%%%%%Part One load The Data%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
nhmean; %Load the mean temperature data
fig7_co2; %Load the Co2 data.
m_fig7_solar; %load the solar data
m_fig7_volcanic; %load the volcanic data
tspan=[1611 1980]; %The range of overlapping temperature
%values
t=tspan(1):tspan(2);
%%%%%%%%%Part II Normilize and center the data%%%%%%%%%%%%%%%%%%%%%
[I1 J1]=find((m_co2>=tspan(1))&(m_co2=tspan(1))&(mtemp=tspan(1))&(m_solar=tspan(1))&(m_volcanic
Hmmm…..All my code wasn’t pasted. The rest of the script:
%%%%%%%%%%%%%%%%Part II Normilize and center the data%%%%%%%%%%%%%%%%%%%%%
[I1 J1]=find((m_co2>=tspan(1))&(m_co2=tspan(1))&(mtemp=tspan(1))&(m_solar=tspan(1))&(m_volcanic
grrr…….looks like I can’t paste my code. I guess you’ll have to wait untill I do it on gocities.
John C , I think that WordPress considers the slash sign as an operator and gets mixed up with the code.
My code is now posted here:
http://geocities.com/s243a/warm/
I’ll upload the figures in a second.
Okay, the figures are now added. The figures were generated by MATLAB
John A, fix the sidebar.
The problem is not people posting long links, the problem is your sidebar. Fix the computer program, not the user behavior.
This is the only blog with this problem, that I have seen.
It’s not Microsoft’s fault either and Internet Explorer is NOT an obscure application.
Originally I was wondering why Michal Mann was plotting the correlation vs time since if the system is stationary the correlation should be constant with time and you should get a better estimate using more data. I know Michael Mann’s argument is that most of the data there is too much noise to show any significant correlation but I don’t buy this argument. What Steve has shown is that Mann’s correlation estimate is not robust to low frequency noise.
I think that it is an interesting question if the correlation changes with time but I think that a more important question is why. If we are just interested in the correlation between temperature and carbon dioxide we may have an expression like:
t(i)=(c(i)(1+s(i)+v(i)+t(i))a(i)
t temperature
c carbon diocide
s solar
v volcanic
t temperature
where a(i) is the linear correlation coefficient and (1+s(i)+v(i)+t(i))a(i) is our nonlinear coefficient which we use to estimate the relationship of the correlation with time. Once we have a suitable estimate of correlation with time along with the error bounds we can make better claims as to how reasonable the proposition of a tipping point is.
John C., IMHO the real problem in MBH98 is not how the correlation is estimated, the real problem is that the correlations are more or less spurious (MBH98 is not representative of the temperature history). So I don’t fully get where you are heading to?
In any case, it might be useful (if you have some spare time) to calculate the correlations with respect to different “spaghetti reconstructions”… it would be interesting to see if they share anything in common! Another interesting testing would be to correlate the individual proxies with those forcings. This might give some indication to what degree they serve as whatever type of proxy.
I pointed this out a while ago. Correlations changing with time imply that we don’t have a good understanding of the system. There is some other factor driving the changes. I don’t really think it’s acceptible or meaningful to have correlations change over time.
Not at all. It implies that the statistics are really that: non-stationary. I.e. the forcings change over time. We can understand a system just fine in the face of non-stationary statistics, but that does not mean we can track it.
Mark
re 52
Exactly. This has bugged me for over a year now. If tree rings (or any other proxy series) are to be used as “thermometers,” then EACH damn series should correlate with temperatures IN THE SAME GRIDCELL. When only one or two selected groups of trees correlate only with “global temperature” (e.g., certain bristlecone trees), then something is really amiss. How can these guys keep a straight face?
The rest of the world is not capable of understanding the implications of a lack of correlation to local temperatures vs. global temperatures.
Mark
52. Which means something else is changing in the system. There is some variable that is not being accounted for. A non-stationary system becomes stationary once we specify all of the things that drive the behavior.
Like, a whole bunch of variables, in the case of tree ring data. Precipitation, sunlight/shade, nutrients, CO2, to name a few. Can you ever claim that living things will exhibit stationarity?
I think you need to do things like age-normalizing and the like. Think that there are a lot of confounding variables. In the long term, would not lose hope that we can find ways to get the information by combining different proxies mathematically (more equations helps solve more unknowns) or by finding new proxies (better forensics in a sense). Sometimes, I get the impression that people here don’t want to know what the behavior was in the past. Just because Mannian methods are not sufficient or have been overplayed, would not lose hope that we can’t figure something out. Look at all the advances that science has made in the last 100 years: isotopes, thermoluminscence, computer analysis and statistical methods, DNA, etc. etc. We may find a way to answer the questions.
TCO: I agree. I like the treeline approach.
#52 (Jean) I think we can resolve spurious correlations and once we are able to do that either with some standard method or one that we derive then we can go further and try to answer the question of if the statistics are stationary and weather we can identify the nonlinearities that result in non stationary statistics.
I am not sure about if standard statistics methods exist but I think it is a good learning exercise for met to derive my own. In the link I posted above I calculated the autocorrelation wrong but it was a good learning experience. I have just hypothesized that complex poles and non positive poles in the autocorrelation indicate less degrees of freedom in the measurements.
Or in other words given a time series Y of length N that has an autocorrelation with non positive real poles then there exist no linear transformation T such that:
W=T Y
and W is a white noise time series of length N.
Thus to whiten the signal we must find a T that reduces the dimensionality of Y. Intuitively this makes sense as the more deterministic the signal is the narrower in bandwidth it will be. Or equivalent the closer the poles will be to the unit circle in the discrete case and the positive real axis in the continuous case.
Statistics cannot be used to prove how likely a deterministic model fits a signal, it can only can be used to estimate a likelihood region where the poles of the signal can be found. This is because only random independent measurements give information and there is no way to separate a purely deterministic signal into random independent measurements.
re # 57:
Uh, not necessarily true. If we can actually back-out all the variables and remove their impact, then perhaps you can create a stationary data out of non-stationary data. I suppose that’s what you mean when you say “There is some variable that is not being accounted for.”? Unfortunately, this cannot work if there are non-linearities, i.e. even if you know what all the variables are, you can’t back out non-linear effects and the data remain non-stationary.
I think it is hampered even further by interdependence between variables as well (which I think will manifest as a non-linearity).
Mark
That’s a good point. Also, what happens if a tree gets damaged for a while, say during an extreme drought, how long does it take before the tree is again “normal?”
Mark
Interdependance is handled by joint factors.
#52 good points. At first I wondered if what you said was always true but then I realized that what is of primary importance is not if our measurements have stationary statistics but rather what is important is if the model parameters we are trying to estimate have stationary statistics. If the statistics of our measurement are stationary that just makes the job easier and I guess implies the system is likely linear.
If we assume the model is linear then non stationary regression coefficients implies the model is different at different times. The less stationary the regression coefficients are the less the model at one time has to do with the model at another point in time. This has many implications including:
-there is less information to identify the model since it is only valid over a short period of time
-identification of model parameters at one time may have nothing to do with model parameters at another time. For example in the case of tree rings identification of proxies in the instrumental period may have nothing to do with temperatures 1000 years ago.
TCO, joint factors are not separable using PCA, MCA or ICA.
Mark
So what? Did he (or does he need to) do PCA for the 3 forcing analysis? Just do basic multiple correlation. Joint factors (x1 times x2) can be handled just like an x3 or an x28. It’s a confounding factor either way. Go read Box, Hunter, Hunter for guidance on when introduction of additional factors is warrented (it is a trade-off between degrees of freedom and fitting all the variance). This stuff is like super-basic. Minitab will do this in a jiffy.
Someone here (Steve M?) made some remark about Mann not having a polynomial least squares ability when I talked about looking at the higher order factors. I was like, duh. Just put x in one column of excel, y in the other, make a column for x squared. Do the damn linear regression of xsq versus y. Any moron with excel can do that.
This stuff is like college undergraduate design of experiments stuff. Oh…and if you had modeled a system of forcings in any basic engineering class or in a manufacturing plant that does six sigma and gone ahead and blithely and unconcernedly just made the correlations for all the forcings be functions of time, people would laugh at you! That that was your result. That it didn’t even bother you. You don’t know the system then! You don’t even know it phenomenologically.
63. If you read the tree lit, there are individual studies where they look at previous year effects on this year (this moves towards the damaging understanding). It’s not a new thought at all. I think part of the issue comes though if you use data in a Mannian approach that just mushes everything together. However, if you use individual reconstructions (that have already taken this effect into consideration), rather then more basic data, this may resolve some of that issue.
My point, TCO, is that you cannot separate them if you do not have a-priori information. I.e. you can pull out the joint (dependent) vars, but you cannot discern the difference between them.
Of course, PCA does not tell you which source is which anyway. FWIW, I’m finding ICA to be more interesting. Higher order statistics are cool.
Mark
You can look at joint var as well as each independant factor. Adding x1x2 into the modeling (and leaving x1 and x2 there) is handled the same way as if you had added in an x3. This is a very normal process in DOE.
I’ve been banging my head over the estimation problem trying to derive an expression for the probability function that includes both the error in the estimate of the mean and the error in the estimate of the autocorrelation values.
Then it occurred to me that they are not independent. You can map N estimates of the error in the mean to N estimates of error in the higher order statistics. Consequently you can get a probability distribution in terms of the error in the mean or the error in the higher order statistics or the static’s but not both simultaneously.
Since we generally assume the error in the mean is Gaussian we express the probability distribution in terms of the error in the mean as as opposed to the error in the higher order statistics since it is a much more mathematically tractable estimation problem. This brings me back to the Gaussian likely hood function:
Click to access JGaussian.pdf
P(x|y,r(k delta_t))=(1/((2*pi*det(P))^(n/2)))exp(-(1/2)*(y-Ax)’inv(P)(y-AX))
P[i,j]=r(delta_t*(i-j))
r(delta_t*(i-j)) is the discrete autocorrelation function of the error in the mean
Notice I wrote the likelihood function in terms of a conditional probability function. The actual probability function is given by the chain rule:
P(x,y, r(k delta_t))=P(x|y,r(k delta_t))P(y,r(k delta_t))
The idea of maximum likelihood is that the actual solution
P(y,r(k delta_t)) is near the maximum of the probability distribution. The likelihood function is an estimate of the probability distribution. Given no knowledge of the mean and autocorrelation a reasonable assumption (priori information) is that P(y,r(k delta_t)) is a uniform distribution in which case the maxium of the probability distribution is given by the maximum of P(x|y,r(k delta_t)). The use of prior information P(y,r(k delta_t)) in an estimation problem is known as Bayesian estimation.
An interesting question is how robust is maximum likelihood estimation to changes in P(y,r(k delta_t)). It is my opinion if P(x|y,r(k delta_t)) is narrow and the estimate using P(x|y,r(k delta_t)) yields an estimate that lies within a few standard deviations of the maximum of P(y,r(k delta_t)) then the estimate will be robust. I think that most reasonable assumptions of P(y,r(k delta_t)) will yield a robust maximum likelihood estimator of P(x,y, r(k delta_t)).
The only likely probablamatic case I can think of is a probability distribution P(y,r(k delta_t)) that has two maximums which are a much greater distance apart then the width of the likelihood function. However I am still not sure if this case is problemamatic because if the conditional probability function is sufficiently narrow then the weighting of P(y,r(k delta_t)) may not effect the maximum. I am going to try out maximum likelyhood and see if my computer can handel it. I am then going to see if I can use it to compute the confidence intervals of the correlation coefficients of temperature drivers over the period of instrumental data. To compute the confidence intervals I am going to assume that P(y,r(k delta_t)) is a uniform distribution. I may later try to refine this knowing the distribution properties of the higher order statistics.
CO2 Negative Correlation w/ Temp! I tried to different techniques on Mann’s data for MBH98. With regular least squares I got a positive correlation coefficients with solar:
0.3187 //CO2
0.2676 //Solar
-0.1131 //volcanic
I then used an iterative technique where I iteratively estimated the error covariance the fit from the autocorrelation of the residual. When it converged the power spectrum of the previous iteration was the same as the iteration before it. I got the following correlation coefficients:
0.4667 //CO2
-0.1077 //Solar
-0.0797 //volcanic
Clearly this latter result is wrong but why should it give a different answer then the previous technique? If you look at the plots of solar and CO2, the CO2 curve looks like a smoothed version of the solar curve. Since the CO2 curve is less noisy and the higher frequency parts of the solar curve don’t appear to match the temperature curve well, the regression prefers to fit the low frequency “hockey stick like shape” of the CO2 then the low frequency hockey stick like shape of the sloar forcing curve. If the CO2 gives too much of a hockey stick and the solar gives not enough of a hockey stick the regression can fit the hockey stick by making the solar correlation negative and the CO2 correlation extra positive.
What I think is wrong is since the low frequency noise is easily fit by both the CO2 curve and the low frequency parts of the solar curve, the residual underestimates the error in the low frequency part of the spectrum. As a consequence in the next iteration the regression algorithm overweight the importance in the low frequency parts of the signal in distinguishing between the two curves. Since the low frequency parts of the CO2 curve and solar curve are nearly collinear the estimation is particularly sensitive to low frequency noise. I think this shows some of the pitfalls of trying to estimate the error from the residual and perhaps gives a clue as why the MBH98 estimate of the correlation is not robust.
re 55
Proxies are more accurate than thermometers. That’s the only explanation for 2-sigmas of MBH99. Maybe it is possible to use the same proxies to obtain all the other unknowns (than temperature) for 1000-1980.
Estimating w/ Unknown Noise
So I don’t get too adhoc and incoherent I decided to search the web fore estimation techniques that make no assumptions about the noise. This link is the best I’ve found:
http://cnx.org/content/m11285/latest/
It looks promising but I don’t fully understand it. I think when possible these techniques should be tried.
Negative Power Spectrim :0
I’ ve been trying some to estimate the auto correlation of the residual and I noticed that it leads to a negative power spectrum. I don’t understand way but there seems to be a known solution to the problem:
http://www.engineering.usu.edu/classes/ece/7680/lecture13/node1.html
The idea is to maximize the entropy of the signal and it doesn’t even assume Gaussian noise. I noticed Steve has discussed the power spectrum of the residual with respect to some of Mann’s papers. I wonder if Steve or the opposing Hockey stick team have tried using these techniques to estimate the power spectrum.
GENERALIZED MAXIMUM ENTROPY ESTIMATION OF SPATIAL AUTOREGRESSIVE MODELS
Click to access spatial_entropy_marsh_mittelhammer.pdf
“Abstract: We formulate generalized maximum entropy estimators for the general linear
model and the censored regression model when there is first order spatial autoregression
in the dependent variable and residuals. Monte Carlo experiments are provided to
compare the performance of spatial entropy estimators in small and medium sized
samples relative to classical estimators. Finally, the estimators are applied to a model
allocating agricultural disaster payments across regions.”
I have a hunch that this paper will tell me what I need to know to properly apply regression to the case where the statistics of the error are not known in advance. I’ll say more once I have done reading it.
Are Solar and DVI based on proxies as well? And NH is proxy + instrumental. Lots of issues, indeed..
#77 I suppose all the non temperature components of the proxi are suppose to cancel out when you fit the data to the proxies. Since many or the drivers are correlated I don’t think this is guarantied to happen.
45 :
Your method is bit hard to follow, maybe because people tend to have
different definitions for signal and noise. Is the MBH98 ‘multivariate
regression method’ LS solution for the model
mtemp= a*CO2+b*solar+c*volcanic+noise ?
i.e. your ‘no noise assumption fit’. And what is time-dependent correlation of MBH98? Sometimes the Earth responds to Solar and sometimes to CO2?
#79 Oh, gosh, given the lack of responses on this thread I didn’t think anyone was following it. Anyway, you have the right definition of the temperature signal plus noise. Sometimes, people try to fit deterministic signals to a best fit and use a least squares criterion. This is effectively the same as fitting a stochastic signal but assuming white noise with a standard deviation of one. There are several methods of deriving weighted least means squares and they all give the same solution. The standard methods are: finding the Cramer Roa lower bound, minimizing maximum likelihood, or whitening the least squares error equation then Appling the normal least squares solution to the whitened equation.
I haven’t updated that link since I posted it because I haven’t been satisfied with the results. I’ll take a look at it now and respond further.
Later today, I’ll clean up the code some in the link there will be new figures and this will be my introduction:
“The Climate scientist that make headlines often use adhoc statistical methods in order justify there presupposed views without doing the necessary statistical analysis to either test there hypothesis or justify their methods. One assumption used by Michael Mann in one of his papers is that the error can be estimated from the residual. In the following we will iteratively use this assumption to try to improve the estimator and show how it leads to an erroneous result. By proof by contradiction we will say that Mann’s assumption is invalid.
There have been several techniques in statistics that attempt to find solutions to estimation without knowledge of prior statistics. They even point out that estimation of the true autocorrelation via the autocorrelation of the measurement data is inefficient and can lead to biased results. Worse then that the estimation of the power spectrum can lead to negative power values for the power spectrum as a result of windowing. This is a consequence of the window not exceeding the coherence length of the noise.
I will later address these techniques once I read more but believe that entropy may be a neglected constraint. I conjecture that if we fix the entropy based on the total noise power then try to find the optimal estimate of the noise based on this constraint, then absurd conclusions like negative power spectrum will be resolved. Entropy is a measure of how random a system is. Truly random systems will have a flat power spectrum and therefore a high entropy relative to the power.
“
Thinking more about coherence length I recalled that the coherence length is inversely proportional to the width of the power spectrum peak, thus narrow peaks cannot be estimated over a limited window. This tells me that a good estimate of the power spectrum will not have overly narrow peaks. Thus for the iterative technique to work of it must constrain the power spectrum to certain smoothness properties based on the window length.
Re 81: Right on! Though perhaps a bit too diplomatic. Many Climate Scientists, brilliant though they may be, inhabit the closed form world of Physics. In this world, if the equations say it happened, it happened and there is no need for empirical verification. Statistics also are not required; “We’re beyond the need for that” seems to be the attitude of some modelers at least. End of discussion. This sort of mindset does not tend to produce good researchers. (And the good ones doing the solid research don’t produce headlines.)
Will be very busy at work but will try to revisit this blog and thread as much as I can. Thanks for your comment, John.
#81. John Cr, I haven’t been keeping up for obvious reasons, but intend to do so.
Re #81: Good stuff John. However, you might want to address the spelling errors, word omissions etc if you don’t want to be exposed to the related credibility risk.
#85 I’m not worried. I’m far from ready to publish. I am just at the brain storming stage and have much to learn about estimation when the statistics of the noise aren’t known. I am curious though about how Mann estimates the power spectrum of the residual as I am finding out it is not a trivial problem.
I guess, I won’t be cleaning up the link I posted above with corrections to the code figures and a new introduction today. I have been instead fiddling a bit with the power spectrum and auto correlation estimation. I want to see if I can do better at estimating the true auto correlation then just auto-correlating the data.
My current approach involves auto-correlating the data, taking the fft, taking the magnitude of each frequency value, taking the inverse fft, then smoothing in the frequency domain by multiplying by a sinc function in the time domain. It sounds ad hoc so I want to compare the result with just auto-corelating the data.
I know iteratively trying to improve your estimate via estimating the noise by taking the auto-correlating of the data yields erroneous results. I am not sure if you can improve your estimate by using the smoothing feature I proposed above in the iterative loop. I want to compare the results for curiosity. Weather I take it to the next level of statistical testing though motie carlo analysis will depend if I believe it is a better use of my time to test and validate my ad-hoc technique or read about established techniques as I posted above.
Click to access spatial_entropy_marsh_mittelhammer.pdf
#86. John Cr, I’ve not attempted to replicate Mann’s power spectrum of residuals, but he has written on spectra outside of MBH98 in earlier work and I presume that he uses such methods – see Mann and Park 1995. I would guess that he calculates 6 spectra using orthogonal windows (6 different Slepian tapers); then he calculates eigenspectra.
In the calibration period, because there is already a very high degree of overfitting – his method is close to being a regression of temperature on 22-112 near-orthogonal series – and the starting series are highly autocorrelated. Thus simple tests for white noise are not necessarily very powerful.
One way to test the algorithm is to simulate the NH_temp data, e.g.:
noise=randn(386,1)/10;
co2s=(co2(:,2)-290)/180;
solars=(solar(:,2)-1365)/12;
s_temp=co2s+solars+noise;
and use the s_temp instead of NH_temp in the algorithm. MBH98 algorithm seems to show changing correlation even in this case. Normalize/standardize problem.
#88 I agree simulation is a good test method. What kind of noise did you assume in you simulation? Anyway, it occurred to me today that in weighted least mean squares there is a tradeoff between the bias introduced in the non modeled parameters (e.g. un-modeled red noise) and estimator efficiency (via a whitening filter). The correlation length of the noise tells us how many independent measurements we have. We can try to remove the correlation via a whitening filter to improve the efficiency but there is an uncertainty in the initial states of the noise dynamics. The longer the correlation length due to those states (time constant) the more measurements are biased by this initial estimate. Bias errors are bad because they will add up linearly in the whitening filter instead of in quadrature. We can try to remove these bias errors by modeling them as noise states but this also reduces our degrees of freedom and thus may not improve our effective number of independent measurements.
JC,
It’s not that people don’t want to follow this thread. It’s just that the language is sufficiently opaque that you’re not going to get a lot of bites. I understand the need to be brief. But if you’re too brief, the writing can end up so dense as to be impenetrable to anyone but the narrowest of audiences. If the purpose of these posts is simply to document a brainstorm, where you are more or less your own audience (at least for awhile), maybe label it as such, and be patient in waiting for a reply? Just a thought. Otherwise … keep at it!
Will try to follow, but it will have to be in pulses, as time permits. Meanwhile, maximum clarity will ensure maximum breadth of response, maximum information exchange, and a rapid rate of progress.
Consider posting an R script, where the imprecision of english language packaging is stripped away, leaving only unambiguous mathematical expressions. A turnkey script is something anyone can contribute to. It is something that can be readily audited. And if we can’t improve upon it, at least we might be able to learn something from it.
Hopefully, it will be clearer sooner. I am making progress on estimating the correlation of CO2. My iterative estimation of the noise seems to be working because the peaks in the power spectrum stay in the same location after several iterations. It takes about 5 iterations to converge. The regression coefficients of the solar seem to decrease by half of what it was doing non weighted regression well the CO2 seems to stay about the same. I expected the solar regression coefficient to catch up to the CO2. However, the power spectrum has three dominate peaks and if I model those with an autoregressive model the situation may change. I also haven’t tried working out the confidence intervals.
Keep in mind I am using Mann’s data and my techniques can’t correct for errors in the data.
I just tried fitting the temperature data to an ARMA model. Since there were 3 polls pairs, I used 6 delays for the auto regressive part. I used 2 delays for each input. My thinking was to keep the transfer function proper in the case that each complex pole pair was due to each input. More then likely though the poles are due to the sunspot cycles or weather patters.
The matrix was near singular so in my initial iteration I added a constant to each diagonal element so that that the condition number didn’t exceed 100. This first iteration give me a nearly exact fit. The power of the peaks in the power spectrum of the error were less then 10^-3. As a comparison non weighted least squares without modeling the noise dynamics gives a power for the peaks of 30.
Therefore the ARMA model significantly reduced the error. Unfortunately when I tried to use this new estimate of the error in the next iteration the algorithm diverged giving peaks in the error power spectrum of 10^5. I think I can solve this problem by using an optimization loop to find the optimal value to add to the diagonal of the matrix I invert in my computation of the pseudo inverse.
For those curious the pseudo inverse is computed as follows:
inv(A’ A) A’
Where ” denotes transpose
A is the data matrix. For instance one column is the value of carbon dioxide and another column represents the solar divers, other columns represent the auto regressive parts and other columns represent the moving average part.
Adding to the diagonal effectively treats the columns of the data matrix as signal plus white noise and the diagonal matrix added to A’A represents the white noise in the columns of A. Although the value of the columns of A may be known precisely the noise could represent uncertainty in our model. The effect of adding a diagonal matrix to A’A is to smooth the response. This technique of adding a constant to the diagonal has many applications. For instance it is used in iterative inverse solvers such as used in the program P spice. It is also a common technique used in model predictive controls.
cont. #79:
It seems that inv(A’*A)*A’*nh, replicates MBH98 results more accurately than http://data.climateaudit.org/scripts/chefen.jeans.txt code (no divergence at the end of the data). Tried to remove CO2 using this model and the whole data set, the solar data does not explain the residual very well. Climate science is fun. I think I’ll join the Team.
86: just take fft and multiply by conjugate, there’s the PSD. Gets too complex otherwise.
At some point, this topic needs to be pulled together in 500 words and submitted to Nature.
Yeah and when you do that, take a careful Sean Connery look to make sure that you don’t go a bridge too far. Cheffen already did. But had the Co-Jones to admit it.
Here is the code if someone is interested:
http://www.geocities.com/uc_edit/full_fig7.txt
Are the input files also posted somewhere? i.e.:
fig7-co2.txt
fig7-corrs.txt
fig7-nh.txt
fig7-solar.txt
fig7-volcanic.txt
See the scripts linked here
What?! You openly allow people to access data, and you share your scripts?! Don’t you know that that’s a threat to your monopoly on the scientific process? You’re mad! You’re setting a dangerous precedent! 🙂
But seriously. I am surprised how much good material there is buried here in these threads. Do you have a system for collating or scanning through them all? I’ve used the search tool; I’m wondering if there’s some other more systematic way to view what all is here. e.g. I have a hard time remembering under which thread a particular comment was posted. And once a thread is off the ‘hot list’ (happens often under heavy posting), then I have a hard time sifting through the older threads. Any advice?
(You may delete 2nd para, unless you think other readers will find the answer useful.)
The categories are useful and I use them.
If you google climateaudit+kenya or something like that, you can usually find a relevant post. I’ve been lazy about including hyperlinks as I go which is now frustrating that I didn’t do it at the time.
As an admin, there are search functions for posts and comments, which I often use to track things down. But that doesn’t seem to be available to readers or at least I don’t know how to accommodate it.
There are probably some ways of improving the indexing, but I’ll have to check with John A on that.
Steve
Setting up an FTP site would probably be the best/easiest.
Usually if you point the browser to the directory of the FTP site it will list everything letting people find it themselves.
I’m sure you are aware of this, but probably didn’t make the connection here. The necesarry neurons are probably taken up with the memory of a Lil Kim video.
JC, I definitely do not want to discourage you from carrying on with your innovative work. In fact, I think I will start paying a little closer attention to what you are doing. It is starting to look interesting (as I slowly wade my way though this thread).
I just want to point out that this attitude can be somewhat dangerous. It validates my earlier remark when I described the Mannomatic as an hoc invention (and MBH98 as the unlikely product of a blind watch-maker). Innovating is great fun. Until you get burned. So, if you can, be careful.
In general, CA must be careful that a “good learning exercise” for one does not turn out to be a hard lesson for all. We have seen how innovation by a novice statistician can lead to a serious credibility loss. Let THAT be the lesson we learn from.
That being said, JC is obviously a MATLAB whiz, and that is a very good thing. Keep it up JC. (Can we start him a scratch-pad thread off to the side where he can feel free to brainstorm?)
Sure.
Johm Creighton, if you want to collate some of your posts and email it to me, I’ll post it up as a topic, so that people can keep better track/
Steve, I might check tonight to see what I might want to move.
Bender not to worry, I think my thought process is converging on something standard.
http://www.csc.fi/cschelp/sovellukset/stat/sas/sasdoc/sashtml/ets/chap8/sect3.htm
In the link above the error and the regression parameters are simultaneously estimated. How do you do this? Well, here is my guess. (When I read it I “ll see if I have the same method a better method or a worse method.) Treat each error as another measurement in the regression problem:
[y]=[A I][ x]
[0]=[0 I][e]
With an expected residual covariance of:
[I 0]
[0 I]
This can be solved using weighted least mean squares
Once x is estimated, estimate we estimate
P=E[(Y-AX) (Y-AX)’]
And compute the cholesky factorization of P
S S’=P
This gives us a new regression problem becomes:
[y]=[A S][ x]
[0]=[0 S][e2]
With an expected covariance in the residual of:
[P 0]
[0 P]
Subsequent iterations go as follows:
P(n)=E[(Y – A X(n)) (Y – A X(n))’]
S(n)S(n)’=P(n)
[y]=[A S(n)][ x(n+1)]
[0]=[0 S(n)][e2(n+1)]
With an expected error in the residual of:
[P(n) 0 ]
[0 P(n)]
We keep repeating using weighted least mean squares until P(n) and x(n) converge. Hopefully, by this weekend I can show some results If I don’t play too much Tony Hawlk pro skater. Lol Well, I got to go roller balding now.
Welcome to the team the UC 🙂 You can estimate the power spectrum the way you suggest but it will give a nosier estimate unless you average several windows. It can also give a biased estimate. In the data Mann’s used for estimating the correlations, the number of measurements isn’t so large that I can’t compute the auto correlation directly by definition but the optimization you suggest should be use when computer time is more critical.
Re #104 multiple regression with autocorrelated error
JC, you’re precious. And I’m not kidding. But there is a difference between “how you do this” and “how a statistician would write the code in MATLAB so that a normal human could do this”.
Your link suggests you want to do multiple regression with autocorrelated error. If that’s all you want to do, don’t need to re-invent the wheel. Use the arima() function in R. The xreg parameter in arima() is used to specify the matrix of regressors.
What we are after are turnkey scripts that TCO could run, preferably using software that anybody can download for free, and whose routines are scrupulously verified to the point that they don’t raise an eyebrow in peer review. That’s R.
I still have not digested all you’ve written, so be patient. My comment pertains only to the link you provided. (I do enjoy seeing your approach as it develops.)
#105 I typed help arima on my version of MATLAB and I couldn’t find any documation about this routine. I searched arima+MATLAB on google and I didn’t find any code right away. Maybe I’m reinventing the wheel but I still think it is a good learning exercise. I learn best when I can anticipate what I am about to learn. If I get it working on MATLAB I can try righting a visual basic macro for it so people can use it in excel. Or better yet maybe I can find some code someone already written that is free.
# 104: IMO, if the noise part is strongly correlated over time, we need to change the model. And the simple-fft method in my code shows that the residuals have strong low-freq components (you are right, it can be noisy, but fits for this purpose). That is, linear model with i.i.d driving noise can be rejected. Maybe there is additional unknown forcing, or responses to CO2 and Solar are non-linear and delayed. My guess is that nh reconstruction has large low-frequency errors.
#106 Google arima+R
#107 You already know there are other forcings, intermediary regulatory processes, lag effects, threshold effects & possible nonlinearities. So you know a priori your model is mis-specified. [This model does not include heat stored in the oceans. I’m no climatologist, but I presume this could be a significant part of the equation.] So you know there is going to be low-frequency signal that is going to be lumped in with the residuals and assumed to be part of the noise. So it’s a fair bet your final statement is correct.
Re #41
Given above, why would you start by assuming THAT? (I know: because it’s helpful to your learning process. … Carry on.)
#108 : My final statement is independent of the former statements 😉 Other issues imply that NH reconstruction has no ‘statistical skill’ and it usually leads to low-frequency errors.
It seems to me that fig-7corrs are estimates of linear regression parameters (LS), not partial correlations. And that explains the divergence when http://data.climateaudit.org/scripts/chefen.jeans.txt is used.
re #109, and others: Thanks for the hard work, UC, JC & bender! I’ll check those once I’m back from the holidays. If you feel need to keep busy on research, I suggest you take a look on MBH99 confidence intervals 😉 I’m sure it is (again) something very simple, but what exactly?!??! The key would be to understand how those “ignore these columns” are obtained… try reading Mann’s descriptions if they would give you some ideas… Notice also that they have also third (!!!) “confidence intervals” for the same reconstruction (post 1400) given in (with another description):
Gerber, S., Joos, F., Bruegger, P.P., Stocker, T.F., Mann, M.E., Sitch, S., Constraining Temperature Variations over the last Millennium by Comparing Simulated and Observed Atmospheric CO2, Climate Dynamics, 20, 281-299, 2003.
You may well be right on this issue. I though that they are partial correlations, as those gave
pretty good fit compared to ordinary correlations. Based on Mann’s description, they may well be regeression parameters, or actually almost anything 🙂 :
A brief side comment on how uncertainty is portrayed in EVERY ONE of these reconstructions. The graphs are deceptive, possibly intentionally so. And many, many good people are being deceived, whether they know it or not. I think most people are looking at the thread of a curve in the centre of the interval, thinking that IS the recontruction. It is NOT. It is only one part of it. What you should be looking at are the margins of the confidence envelope, thinking about the myriad possibilities that could fit inside that envelope.
An honest way of portraying this reality would be to have the mean curve (the one running through the centre of the envelope) getting fainter and fainter as the confidence interval widens the further you go back in time. That way your eye is drawn, as it should be, to the envelope margins.
North specifically made a passing reference to this problem in the proceedings, when he pointed out that the background color on one of the reconstruciton graphics was intentionally made darker and darker as you go back in time. (I don’t recall the name of the report.) That addresses the visual problem, but in a non-quantitative way. I think the darkness of the centreline should be proportional to the width of the confidence envelope at each point in time. THEN you will see the convergent truth that is represented at the intersection of all these reconstructions: a great fat band of uncertainty.
#110: Yep, hard to track what is going on; the story continues:
Now, as we have the model we can use years 1610-1760 to calibrate the system and reconstruct whole 1610-present (CO2, Solar and Volcanic as proxies). Calibration residuals look OK. http://www.geocities.com/uc_edit/rc1.jpg 🙂
“‘My method starts by assuming that the signal is entirely noise’
Given above, why would you start by assuming THAT? (I know: because it’s helpful to your learning process. … Carry on.) ”
With the algorithm I am envisioning
http://www.climateaudit.org/?p=692#comment-39007
I don’t think that is a necessary assumption. I expect it to converge to the same value regardless of the initial assumption of the noise. But for a robustness I can try initializing it with the assumption that the signal is all noise and with the assumption that the noise is white with a standard deviation of one and see if I get the same results.
I see your point.
See, this is the problem with posting every detailed thought. I thought you were suggesting it was somehow a helpful assumption to start with. Maybe not “necessary”, but somehow “better” in a substantive way. My attitude is: if it’s “not a necessary assumption”, why tell us about it? I guess because you write stream-of-consciousness style? Fine, but it makes it hard for us to separate wheat from chaff.
Never mind. It’s really a minor issue. Use the blog as you will. Looking forward to the result.
#115, I am not sure a useful algorithm can’t be derived on the basis of that assumption. However, I abandoned that approach. Anyway, I was thinking about error bars today and what they mean if you are both estimating, the natural response, the forced response due to error and the forced response due to known forcing effects all simultaneously.
Joint Gausian’s are such that you have hyper ellipses with a constant value in the pdf. The shape of the ellipse is defined by the eign vectors and eign values of the covariance matrix. The N standard deviation ellipse in the coordinates space defined by linear combinations of the eignvectors centered about the mean value of the estimate vector (the estimate vector is made up of the estimates of the parameters and errors) is defined as follows:
N=(v1)^2/lambda1+…+(vn)^2/lambdan
Where vn is the amount we deviate from the mean (the mean is the estimate vector) in the direction of the nth eigenvector and lambdan is the nth eigen value.
There exists a transformation that transforms our space of possible estimates (includes estimations of the parameters and errors) to our eigen coordinate space. There exists another transformation that transforms our space of possible estimates to our measurement space measurement space (includes actual measurements augmented with the expected value of the error (the expected value of the errors is zero)).
We define the N standard deviation error bars for a given coordinate in our measurement space as the maximum and minimum possible estimate of that coordinate that lies on the N standard deviation hyper ellipse given by:
N=(v1)^2/lambda1+…+(vn)^2/lambdan
I suspect non of the following are always at the center of these error bars: the fit including initial conditions, known forcing and estimated error forcing; the fit including only known forcing centered vertically within the error bas as best as possible; the actual temperature measurements.
Another question is, are these error bars smoother then the temperature measurements and any of the fits described in the last paragraph. I conjecture they are.
On the subject of gain. The correlation coefficients are only a really good measure of gain if the output equals a constant multiplied by the input. Other types of gain include the DC gain, the maximum peak frequency gain, the matched input gain, and the describing function gain.
I will define the describing function gain as follows:
Average of (E[y y_bar]/sigma_x) over the time interval of interest
Where y is the actual output, y_bar is the output response due to input x and signa_x is the standard deviation of input x. I may try to come up with a better definition later.
#116 Sorry, again hard to follow, maybe it’s just me. But I’d like to know as well what those error bars actually mean. Multinormal distributions are out, try to plot CO2 vs. NH or Solar vs. NH. and you’ll see why. IMO ‘forcing’ refers to functional relationship, not to statistical relationship.
Re #118. Yes. Forcing by factors A, B, C on process X just means the effects a, b, c are independent. When modeling the effects in a statistical model, one would start by assuming the forcings are additive: X=A+B+C, but obviouly that is the simplest possible model, no lags, nonlinearities, interactions, non-stationarities, etc.
Not sure how your comment relates to #116, but then again not sure where #116 is going either. (But you gotta admit: it is going.)
#118 The error bars represent the range of values that can be obtained with plausible model fits (fits to parameters end errors). That is we consider a confidence region of fits based on the statistics and we plot the supremum (least upper bound) and infimum (greatest lower bound) of all these fits.
This gives us an idea of how much of our model prediction we can rely on and how much is due to chance.
# 119 , # 120 Don’t worry, we’ll get in tune soon. One more missing link: how are the fig7-corrs.dat confidence intervals computed? Is there a script somewhere?
You mean how did Mann do it?
Steve has a few posts on that. Click on the link on the side bar that say statistics. You should see a few topics on it as you go though the pages.
I’ve discussed MBH confidence intervals for the reconstruction, try the sidebar MBH – Replication and scroll down. So far, Jean S and I have been unable to decode MBH99 confidence intervals nor has von Storch nor anyone else. We didn’t look at confidence intervals for the regression. Given the collinearity of the solar and CO2 forcing and the instability of correlation by window size, one would assume that the confidence intervals for Mann’s correlation coefficients should be enormous – but no one’s checked this point yet to my knowledge. Why don’t you see what you turn up?
# 123
Sure, I can try. Not exactly the numbers in MBH98 but close:
http://www.geocities.com/uc_edit/mbh98/confidence.html
I am not sure if I am on the way to anything good yet. In the ARMA model I used a four pole model and three zeros for each input. In the figure bellow, the solid line is the fit using my method, the dotted line is the fit using regression on a simple linear model (no lags), and the dots are the temperature measurements. My fit is better but it is not fair comparison because I am using a higher order model.
http://www.geocities.com/s243a/warm/index.htm
Another interesting plot is a plot I did of the DC gain:
The model seems to say that the equilibrium response of the climate to a DC (0 frequency a constant signal) of either solar or CO2 of one standard deviation would change the temperature by an amount that is only about 10% of the amount we have seen the climate vary over the best 1000 years.
This is only very preliminary work and I need to spend a lot of time looking for bugs, and analyzing the code. Trying to better understand the theory and hopefully eventually some Monty Carlo testing. I’ll post the code in a sec. One thing that doesn’t quite look right is I was expecting the error parameters to have a standard deviation of one.
The code can be found here:
http://www.geocities.com/s243a/warm/code/
To get it to work in MATLAB, copy all the files into your working directory, change the .txt extension to a .m extension. Then run script2. In the yes know question it asks, type ‘y’ your first time though. Don’t forget to put in the single quotes. On you’re second time though you can type ‘n’. This user input was added because MATLAB seems to take a while to initialize the memory it needs for arrays. This can really slow a person down if they are working on code.
Bump
John Creighton, if you put a full link in the first few lines of your post, it messes up the front page for Internet Explorer users. If you use the link button, you can put a link text instead of the URL, and the problem does not arise.
And again …
Avast ye, landlubbers …
The devil damn thee black, thou cream faced URL …
where got thou that goose look …
# 124 cont.
How should we interpret these confidence intervals? Here’s my suggestion: It is very unlikely that the NH reconstruction is a realization of AR1 process with p??? In an assignment A(:,matrix) = B, the number of elements in the subscript of A and the number of columns in B must be the same.
Error in ==> Z:\script2.m On line 148 ==> Ry(:,k-1)=Rx3(LE:end);%We keep track of the auto corelation at each itteration
UC, I don’t get that error. To help me find the bug once you get the error message type:
size(Ry),size(Rx3),size(LE)
I suspect that Ry might be initialized to the wrong size.
Here is my suggestion. On line 85 change
RYs=zeros(L,L,N);
To
Ry=zeros(LE,N);
I think that the version of MATLAB I am using (version 7) initializes Ry in the assignment statement where you got the error. I’ll go make this change in my code now.
Thanks, seems to work now. I’m still not quite sure what it does, though 😉 I have a fear of overfitting.
Glad it is working. I’ve been thinking about where to go with it and bothered me that the noise parameters were not white. Well, they looked white except for the standard deviation not being one. I think this is caused by me weighting too much the estimated error in the estimation of the error auto correlation and not weighting enough the residual in the estimate of the error auto correlation.
I am going to add some adaptation into the algorithm as follows. The initial assumption is that the measurement part of the residual is white noise. My first estimate of the error auto correlation will be done by taking the sum of the residual error plus a weight times the estimated error and then auto correlating that weighted sum. I will choose the weight so after I do my frequency domain smoothing the value of the auto correlation at zero is equal to the expected standard deviation of the residual.
This gives me an estimate of the error covariance which I use in the regression and I get a new estimate of the error parameters. To get my new estimate of the measurement residual standard deviation, I will multiply what I previously thought it was by the standard deviation of the error parameters. The idea being to force the standard deviation of the error parameters to one. Then hopefully at convergence all of the residual covariance error can be explained by the mapping of the error parameters onto the measurements via the square root of the covariance matrix. (fingers crossed :))
#136
So your final goal is to explain the NH-temp series using only forcings and linear functions of them, in a way that residual will be std 1 and white? Sorry if Im completely lost here!
Forcing include the error and the known inputs. The estimation of the error should help make up for model uncertainty. The optional solution is a statistical since of the linear equation
Y=AX+e
Is equal to the least squares solution of:
RY=RAX+e
where
R is the choleskey factorization of the covariance of the noise (e=y-AX)
E[e e^T]=P=R’ * R
P is the covariance matrix of the noise (residual)
R is the choleskey factorization of P
So the optimal solution is:
X~=inv(A’ R’ R A’) R A y
The problem is we don’t know the noise so how do we find the most efficient estimator? Consider the equation:
[y]=[A S][X]
[0]=[0 I][e]
Where e is a white noise vector. We want to estimate e and x and we can do this by weighted regression but if we want the most efficient estimate we have to whiten our regression problem as we did above.
This can be done by multipolying the top part of the matrix equation by R
To get:
[Ry]=[RA I][X]
[0] = [0 I][e]
And the residual error is:
[e]=[Ry]-[RA I][X]
[e]=[0 ]- [0 I][e]
Which is white noise:
Thus although we don’t know R or S we know what the residual should look like if we choose S correctly. One of my conjectures is that is if we choose an S that gives a residual error that looks white then we have a good estimate. My second conjecture is that if we pick a well conditioned S and estimate the residual based on that, we can get successively better estimates of S until we are close enough to S to get a good estimate. I conjecture we will know we have a good estimate when the error looks like white noise (flat spectrum standard deviation of one)
Let’s see if I got it now. So, you assume y=Ax+S*e, where A is the [co2 solar volc] data, and e is white noise. Due to matrix S, we have correlated noise process (S should be lower diagonal to keep the system causal, I think). If we know S, we can use weighted least squares to solve x. But you are trying to solve x and S? If this is the case, it would be good see how the algorithm works with simulated measurements, i.e. choose x and S, generate e using Matlab randn-command, and use y_s=A*x+S*e as an input to your program.
#139 (UC) you got it exactly :). Thanx for that lower diagonal idea. I am not sure if it is necessary in the algorithm for S to be lower diagonal but for simulation purposes I think it is a good idea. You can have non causal filters (smoothing) so I am not sure if non-causalisty is that bad. For simulation purpose I am not sure what S you should choose as I think some choices may be difficult to solve for. Those choices that I think that would be difficult are where S results in non station error statistics.
On another note, I was thinking about the co linearity of proxies and how to best handle this in a regression problem. It occurred to me that we can add extra error terms to introduce error in the cost function if the regression proxies are not collinear. We do this by introducing an error (residual) measurement that is the difference between two proxies.
Physical model should be causal, present is independent of future (just my opinion..). And actually, in this case, weighted least squares does the smoothing anyway, it uses all the data at once. S for AR1 is easy, that’s a good way to start.
It’s been a while since I posted in this thread. I had some thinking to do about my results and as a result I made some code changes. The ideas are the same but I thought of a much better way numerically to converge on the results I had in mind. Is the algorithm an efficient and accurate way to get the fit? I am not sure but:
1.The fit looks really good,
2.The noise parameters looks like white noise with standard deviation one as I expected.
3.The estimate of the error attributes more error to low frequency noise.
4.All the parameters appear to converge and all the measures of the error appear to converge.
6.The predicted DC gain is not that far off from a basic regression fit with simple linear model (no auto regressive or moving average legs)
The figures in my post 125
http://www.climateaudit.org/?p=692#comment-39708
Are replaced by my new figures and all the code in the link given in that post is replaced. Unfortunately at this time I have no expression for the uncertainty. On the plus side the algorithm estimates the noise model as well as the system model so several simulations can be done with different noise to see the effect the noise has on the estimation procedure and on the temperature trends. The algothithum is interesting because unlike most fits that use a large number of parameters only a few of the parameters are attributed to the system and the majority of the parameters are attributed to the error.
Thus although I do not have a measure of uncertainty my procedure tells me that 60% of the variance in the signal is attributed to the noise model. Well this does not give us the error bars it tells us that from the perspective of an arma model with 3 zeros and 4 poles and a noise model of similar order that the majority of the signal is due to noise and not the external drivers CO2, solar and volcanism.
#89 I think a good part of temperature variation cannot be explained with simple linear models as a result of the combined forcing agents, solar, volcanic and CO2. I believe the dynamics of the earth induce randomness in the earth climate system. I’ve tried doing regression with a simultaneous identification of the noise here:
http://www.climateaudit.org/?p=692#comment-39708
I don’t think the results are that different from stand multiple regression for the estimates of the deterministic coefficients but it does show that the system can be fit very well, to an ARMA model plus a colored noise input. Regardless of what regression technique you use a large part of the temperature variance is not explained by the standard three forcing agents alone. Possible other forcing agents (sources of noise) could be convection, evaporation, clouds, jet streams and ocean currents.
opps, did my html wrong:
Please ignore the above two posts, I meant to post here:
http://www.climateaudit.org/?p=796#comment-43600
That is true, but I would put it like this: ‘large part of MBH98-reconstructed-NH temperature variance is not explained by the given three forcing agents alone’. I don’t think that MBH98 NH-recon is exact.
I made some changes to the file script2.txt
http://www.geocities.com/s243a/warm/code/script2.txt
The algorithm wasn’t stable for a 20 parameter fit, now I know it is stable for at least up to a 20 parameter fit. I enhanced figure 2 so you could compare it to a standard regression fit of the same order. I will do the same for the plot of the DC gains and the bode plot.
Oh yeah, I added a bode plot for the parameters identified by my algorithm. Not to interesting. The biggest observation is that the earth seems to have a cutoff frequency of about 0.2 radians per year or equavalanetly 0.06 cycles per yer. Or another words inputs with a period less then 16 years are attenuated by about 2DB (50%)
http://www.phys.unsw.edu.au/~jw/dB.html
Re #143, you say:
Let me suggest that you might be looking at the wrong forcing agents. You might therefore be interested in LONG TERM VARIATIONS IN SOLAR MAGNETIC FIELD, GEOMAGNETIC FIELD AND CLIMATE, Silvia Duhau, Physics Department, Buenos Aires University.
In it, she (he?) shows that the temperature can be explained quite well using the geomagnetic index (SSC), total solar irradiation (TSI) and excess of length of day (LOD). Look at the October 29, 2005, entry at http://www.nuclear.com/environment/climate_policy/default.html for more info.
w.
Whillis, that are some very interesting articles at the site you gave. The mechanisms sound very plausible and it is disappointing the figures don’t seem to contain much high frequency information. Of course perhaps a lot of the high frequency components of global average temperatures are due to the limited number of weather stations over the globe.
Here is an interesting section from the link Willis gave:
http://www.nuclear.com/environment/climate_policy/default.html
I’ll see if I can find some data.
hmmm more driver data sets (ACI)
http://www.fao.org/docrep/005/Y2787E/y2787e03.htm
Another interesting climite factor:
http://www.nasa.gov/centers/goddard/news/topstory/2003/0210rotation.html
I found some data on the earths rotation:
http://www.zetatalk.com/theword/tworx385.htm
It seems to have a hockey stick shape from 1700 to year 2000. From the link I posted earlier the slowing of the earths rotation would have a cooling effect so this produces and anti hockey stick effect. This makes senesce because it would increase the standard deviation of the temperature on earth thereby increasing the cooling since heat flux is proportional to the forth power of the temperature.
This attribution stuff is quite interesting. I used to think that the methods ‘they’ use are fairly simple, but maybe they aren’t.
I’ve been following the topical RC discussion, where ‘mike’ refers to Waple et al Appendix A, which is a bit confusing. Specially Eq. 9 is tricky. I would put it this way:
i.e. the last term is the error in the sensitivity estimate. This shows right away that high noise level (other forcings, reconstruction error, ‘internal climate noise’) makes the sensitivity estimate noisy as well. Same applies if the amplitude of the forcing is low during the chosen time-window. That is one explanation for #113 (CO2 does not vary much during 1610-1760).
But maybe I’m simplifying too much.. See these:
(Waple et al) I thought first order approx. is the linear model..
(RC)
I see, eq. should be ‘estimate of s equals s + E(FN)/E(FN*FN) ‘. Hope you’ll get the idea.
US, is my Latex edit in 154 OK?
Yes, thanks. The original paper uses prime, and that didn’t get through. I think they mean ‘estimate of s’. But on the other hand, they say s (without prime) is ‘true estimate of sensitivity’. This is amazing, it takes only 4 simple looking equations and I’m confused. These issues just aren’t as simple as non-experts like me like to think.
Obviously you don’t have a proper training in Mann School of Higher Undertanding 😉
# 158
I see 😉 Robustly estimated medians, true estimates etc. I need some practice.. Seriously, I think MBH98 fig 7 and MBH99 fig 2 are the ones people should really look into.
But when I really think about it, this is my favourite
(-gavin)
I know people here don’t like RC, but I think this topic is a good introduction to MBH98 fig 7 (and even more general) problems.
Some highlights:
gavin started to read CA? If there is no scheme to detect difference between ‘internal variability’ and forcings, then we don’t know how large is the last term in #154 eq, right?
Hey, how about MBH99 then? Or is this different issue?
experiments, synthetic, simulation, mike hasn’t started to read CA.
The discussion between Rasmus and Scarfetta is a hoot over at RC. Rasmus persists in complaining about methods to get a linear relationship based on delta(y)/delta(x). He has the bizarre stance of saying that because the method is in danger with low differentials (which only Rasmus tries, not Scarfetta), that the method is inherently wrong. I guess Rasmus thinks Ohm’s Law is impossible to prove as well! Poor Scarfetta, he just doesn’t know what a moron he is dealing with.
Gavin on the other hand is more artful in his obfuscation. But doesn’t bother putting Rasmus out of his misery (nor does he support his silly failure to understand). All that said, I think Moberg is a very suspect recon, so that examinations based on it, are less interesting. Scarfetta does make the cogent point that D&A studies and modeling studies vary widely based on what they mimic (Moberg or Mann) so that given the uncertainty in recon, there is uncertainty in the models.
I think Gavin has good points, but they are in conflict with MBH9x. Dialogue between Scafetta and Gavin might lead to interesting conclusions.
The distribution of the last term in #154 eq is very important. And not so hard to estimate, it is just a simple linear regression. Thus, if terms in N are mutually uncorrelated (does not hold, but let’s make the assumption here), then the variance of that error term is
and X is simply a vector that contains CO2 (or any other forcing in question) values, and is the variance of N. So, the variance of N is important, but so is the variance (and amplitude) of the forcing! I think we should think about MBH98 figure 7 from this point of view, and forget those significance levels they use..
is the variance of N. So, the variance of N is important, but so is the variance (and amplitude) of the forcing! I think we should think about MBH98 figure 7 from this point of view, and forget those significance levels they use..
I think that the error variance, as shown in # 163 explains a lot. Shorter window, more error. More noise (N), more error. Variability of the forcings within the window does matter. And finally, if (for example) solar and CO2 are positively correlated within the window, the errors will be negatively correlated. I tried this with MBH98 fig 7 supplementary material, makes sense to me.
And I think these are the issues Ferdinand Engelbeen points out in that RC topic (# 71). And Mike says that it is nonsense.
Here’s the Matlab script, if someone wants try/correct/simulate/etc
UC, could you make the script turn-key so that the figures load correctly from the ftp site?
bender, don’t know how to force Matlab to load directly from ftp (or was that the question?)
http://ftp.ncdc.noaa.gov is down, but http://www.nature.com/nature/journal/v430/n6995/extref/nature02478-s1.htm seems to work. ‘Save as’ to working direcory and then it should work (my 5-version Matlab changes fig7-co2.txt to fig7_co2 when loaded, not sure what the new verions do)
re #167: worked fine on my ver 6.5. 🙂 The command to use is mget, but I think it was introduced in ver 7 😦
Re #167
That was precisely the question. Thx.
Re #168
But you have the files already in a local directory, correct? I want it to run without having to download anything.
re #170: Yes, and the only solution I know for Matlab to do that is with the wget-command, which, I think, was introduced in ver 7…
But, hey, check the Hegerl et al paper I linked… it has an attribution section … 😉
Yicks! I’m looking back at what I did and I’m scratching my head. I think I need to document it a little better. No wonder their wasn’t more discussion.
Looking back I see what I’ve done and I am wondering why I didn’t use a state space model. The temperature, carbon dioxide and volcanic dust should all be states. Perhaps to see the contribution each drive has on temperature you don’t need a state space model but a state space model will help to identify the relationship between CO2 and temperature. It will also allow predictions and perhaps even the identification of a continuous model.
John, you may find this page useful.
#174 that could be of interest. I have though been developing my own Kalamn filter softare. I lost interest in it for a while but this could reinvigorate my interest. The software I developed before can deal with discontinuous nonlinearties. What was causing me trouble was trying to simplify it.
Michael Man tried to fit the northern hemisphere mean temperature to a number of drivers using linear regression in mbh98. To the untrained eye the northern hemisphere temperatures looked quite random. As a consequence it was hard to tell how good the fit was. One can apply various statistical tests to determine the goodness of fit. However many statistical tests rely on some knowledge of the actual noise in the process.
I had become frustrated that I could not determine what a good fit was for the given data. I decided to try to break the signal into a bunch of frequency bands because I was curious how the regression coefficients of the drivers was dependent upon the frequency band. I decided to graph each band first before trying any fitting technique.
The three bands were a low frequency band which results from about a 20 year smoothing. A mid frequency band that results from a frequencies in the period of 5 years and 20 years and a high frequency band where the frequency is less then a 5 years period.
Each filter is almost linear phase. The filter produces signals that are quite orthogonal and extremely linearly independent. In figure 1-A the solid line is the original northern hemisphere temperature signal and the dotted line is the sum of the three temperature signals produced by the filters. As you can see the sum of the three bands nearly perfectly adds up to the original signal.
What is clear from the graphs is the low frequency signal looks much more like the graph of the length of day then the carbon dioxide signal. If carbon dioxide was the principle driver then the drip in temperature between 1750 and 1920 would be very difficult to explain. Conversely the length of day fell between 1750 and 1820 and then started to rise again after 1900. One wonders why the length of day would impact the earth much more then carbon dioxide but the evidence is hard to ignore.
The mid frequency band looks like it has frequency components similar to the sunspots cycle but the relationship does not appear to be linear. The high frequency band looks difficult to explain. My best bet is cloud cover.
my web page
The code to make the above graphs can be found here:
http://www.geocities.com/s243a/warm-band/mbh98_bands_files/code/
My new suspension is volcanoes are the cause of global warming. In Man’s graph if you look at the rise in temperature from 1920 to 1950 and then look down bellow at his measure of volcanic activity you will notice that before 1920 volcanoes were quite frequent but afterwards they almost stopped in terms of intensity and frequency. Additionally if CO2 was the cause you would expect the temperatures to continue to rise but the rise in temperature between 1920 and 1940 far surprises any temperature rise after that. Man’s data for the northern temperature mean looks like a first order response to a step change. It does not look like a response to an exponentially increasing input driver.
Re #176 John it’s intriguing that the low-frequency variation in NH temperature seems to match better (visually at least) with length of day variation than with CO2.
Length of day on a decadal scale, per this article , seems to be related to activity in Earth’s core, which in turn could be forced by internal dynamics and/or solar system activity and/or surface events. How that ties to surface temperature, though, is unclear.
Perhaps an alternate factor affecting length of day is that warming oceans expand, which would move them farther from Earth’s center, which would slow the planet’s rotation.
Something to ponder.
I don’t know if this article is mainstream or not, but it may be of interest to those with a solar / climate interest.
If Earth’s rotation (length of day) is affected by solar factors, and if John’s work above shows a correlation between length of day and NH temperature reconstructions for recent centuries, then maybe there’s a clue somewhere in this about a solar / climate relationship.
With window length of 201 I got bit-true emulation of Fig 7 correlations. Code in here. Seems to be OLS with everything standardized (is there a name for this?), not partial correlations. These can quite easily be larger than one.
The code includes non-Monte Carlo way to compute the ‘90%, 95%, 99%
significance levels’. The scaling part still needs help from CA statisticians, but I
suspect that the MBH98 statement ‘The associated confidence limits are approximately constant between sliding 200-year windows’ is there to add some HS-ness to the CO2 in the bottom panel:
(larger image )
This might be outdated topic (nostalgia isn’t what it used to be!). But in this kind of statistical attribution exercises I see a large gap between the attributions (natural factors cannot explain the recent warming!) and the ability to predict the future:
One Trackback
[…] week, through Chefen, Jean S and myself, here here here and here , we showed that MBH98 contained questionable statistical methodology for assessing the relative […]