A few days ago, I mentioned that I thought that Bürger et al 2006, while recognizing the linear relationship between MBH proxies and their RPCs, had incorrectly formulated the form of the relationship as the form of the linear relationship was inconsistent with my own derivation, which I had cross-checked and verified against source code (not that the methodology is "correct" only that the representation of the methodology is accurate.) This has led to an interesting exchange with Gerd Bürger, which I’m now in a position to summarize.
Gerd initially thought that my derivation must be incorrect. I asked him to show how he got Tellus equation 8. (I thought that the form of Tellus equation 8 was ugly and contained unnecessary complications but that was seemingly a side issue.) Gerd sent in a derivation which looked plausible; when I tried the calculations his way, you could get Tellus equation 8 so I figured that maybe it was OK after all. The calculations still didn’t seem to reconcile, so I figured that I’d gotten lost somewhere in the reconciliation – although I’d spent lots and lots of time on it.
Gerd then wrote in correcting his calculation and stated that Tellus equation 8 did contain an error after all, so that my original conclusion was correct. Gerd says that the error does not affect their simulations and I suspect that this is so. However, it directly affects the argument in Bürger et al 2006 about VZ variance attenuation. I’m not sure that this argument is all that valid anyway, but the argument doesn’t seem to apply with a corrected equaiton 8 or at least it will require a total re-working.
Bürger et al used Moore-Penrose pseudoinverse inverse notation, which I had not used. The Moore-Penrose pseudoinverse is familiar to people who use linear regressions:

For rectangular matrices, you need to be careful as to whether you are taking a left pseudoinverse or a right pseudoinverse as the following is also a (right) pseudoinverse:
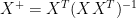
The error in Bürger et al equation 8 appears to be traceable to the following property of Moore-Penrose pseudoinverses. Suppose that R is a rectangular matrix and S is a square matrix, if you do a right Moore-Penrose pseudoinverse,

but the following does NOT hold
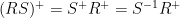
You can esily verify this by expanding the original definition. But notation can deceive and, if the latter is (incorrectly) assumed to be correct, then Tellus equation 8 is obtained as I’ll show here. This or something formally equivalent is almost certainly what happened in Bürger et al 2006.
Let’s review the bidding. Tellus equation (8) states:

where
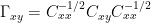
In my notation, I used columns and rows in the transpose arrangement with time series arranged in columns which seems to be a far more common practice. A second difference in notation is that I used a Y matrix for the proxies ( which are X in Gerd’s notation). Given that temperature supposedly causes ring widths rather than ring widths causing temperature, I prefer not to use X for ring widths, to avoid any temptation to reify an inverse relationship. Thirdly, I use U for temperature PCs rather than X, to act as a reminder that we are dealing with temperature PCs in this situation. Now in MBH, the monthly PCs are orthonormal and the U series entering into the calculations are annual averages and are no longer orthonormal. However, they are close to being orthogonal and using the U nomenclature helps remind this. In this case, the PC decomposition of the temperature fields is
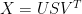
Nothing turns on the notational differences, except that it’s easier for me to keep track of my own notation and then re-substitute at the end. The calibration step in my derivation was:

Using Bürger’s Gamma nomenclature, this is equivalent to:
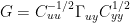
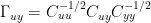
In one of his posts, Gerd wrote that
The estimate for the temperature TPCs
is derived by the least-squares solution of:

In Gerd’s notation, this yields without any trouble (as I had equivalently done in my calculations):
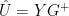
There are available simplifications, which I pointed out in the one-dimensional case. Using Gerd’s Gamma terminology, the same equation would be:
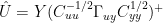
In this case, you can extract the left matrix 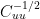
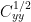

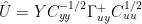
Allowing for rows and columns exchanging u for y and y for x, this converts to the following, which is their Tellus equation 8:
So it’s now pretty easy to see where they probably went wrong. I say this not as a gotcha, but simply because it’s always worth understanding where a calculation went wrong so that the error is not replicated again (a trap that I temporarily fell into when I tried to start from Gerd’s equations rather than my own.)
In passing, I wouldn’t say that I observed the error in Tellus equation 8 from attempting to "audit" Bürger et al 2006, so much as observing an inconsistency between it and my own derivation. However, I did spend a lot of time unsuccessfully trying to reconcile these results before making any comments on the matter online.
A Re-Statement of My Derivation
I thought that it would be useful to present my previous results from the same starting point as Gerd so that the reconciliation can be clearly seen and perhaps persuade Gerd and others as to the correctness of the PLS viewpoint. You will also see the simplifications and cancellations that result from how I did it and why this leads to the PLS derivation that had eluded previous commentatots. First let’s get rid of the 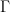
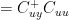



Thus,

This is both simpler than Gerd’s equation; it’s accurate and reveals the structure. At this point, we can expand the Moore-Penrose (right) pseudoinverse:
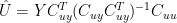
In the one-dimensional case with standardized Y, 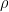
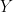

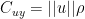
this reduces to:
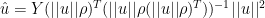

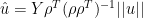
as I had previously derived. I think that this one-dimensional case is much the most important for several reasons: (1) the early portion of MBH is one-dimensional; (2) the NH temperature index is dominated by the PC1 and so the calculation of primary interest can be closely approximated by the one-dimensional case in subsequent periods; (3) arguably the multidimensional case can be either represented or closely approximated as piecewise one-dimensional calculations with some of the multivariate apparatus not actually contributing to the result.
Here’s a way of representing the multidimensional case in a similar format to how I did the one-dimensional case. Because 

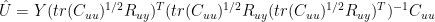

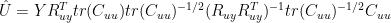
Since 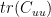
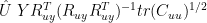
This is just a piecewise version of the one-dimensional calculation. If annual temperature PCs are used, as in Wahl and Ammann re-working of MBH, as opposed to the monthly temperature PCs of MBH, then
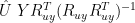
The "standardization" operation for Y assumed here is handled a little differently in Bürger et al 2006 in their discussion of canonical correlations. Using canonical correlations the normalized form of 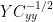


Bürger’s K Equation
In response to my earlier post, Gerd offered the following replacement of Tellus equation (8):
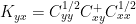
yielding revised equation (8):

In my notation, this converts to:

where:

In the analysis of Bürger et al 2006, properties of the 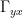
Other Comments
I’m in the process of evaluating the canonical correlation arguments in Bürget et al 2006. While TCO and others have commented that they found Bürger et al easy to understand, I found much of it very difficult to understand (while liking other parts). I found equation 8 very hard to understand and it turned out that there was a reason for this. I find their analysis of canonical correlations and their impact on VZ variance attenuation very difficult to understand as well. I’m struggling to see the point of using canonical correlations and I’m dubious as to whether this analysis will survive the demise of equation 8. Maybe TCO understands some of this better than I do, but I’d be surprised.
Also the analysis in Bürger et al 2006 does not IMHO properly analyze the specific effect of re-scaling the RPCs. Yes, they consider this as a flavor in their simulations, but IMHO the re-scaling operation is intimately related to VZ variance attenuation, which cannot be properly understood without explicitly including the re-scaling operation in the linear algebra. I think that Bürger et al got distracted by the canonical correlation argument which doesn’t survive and missed an easier argument, which actually does the job. Once you do that – using the simple and direct representation of MBH methodology that I’ve presented here, you can show (IMO) that VZ variance attenuation is a simple application of orthogonality and the Pythagorean Theorem. From this vantage point, the huffing and puffing by the Hockey Team goon line against VZ is little more than a pointless diatribe against the Pythagorean Theorem.
I hadn’t previously thought about Tellus as a potential market for an article showing that MBH can be construed as a partial least squares method, but it’s probably logical. If they’ve published an incorrect formula, they can probably be persuaded to publish a correct formula, although you never know. I’ve got other material in hand advancing the attenuation issue, which I’ll write up for publication. (I will invite participation from others.) In order to protect myself against academic fussing about too much internet disclosure, you’ll have to be content for now with these teasers. With academic journal schedules, if I don’t get impatient in the mean time, you should learn about these other results no later than 2008 or 2009.





20 Comments
On the content:
A. Could not follow the lin alg. Glad you are doing it though.
B. I’m interested what the implications of the difference are.
C. Not sure what you meant about the rescaling not being considered well enough. Is there an error in the flavor runs? Or is it that they should spend more time writing about the nuances and implications of the issue?
4. I hope as you pursue this, that you do so a bit fairly and agnostically. My reading on the Huybers kerfuffle (corelation matrix) was that there are well known issues with either not dividing or dividing. I think it much more useful to understand the plusses and minuses of either option in a choice then to jump up and down about the minuses of one option. It doesn’t really drive real science understanding, is defensive and tendentious.
Editorial crap:
1. No need for snark. You know my level of math ability (I know no LA). My comment about BC being easy to understand is especially related to their full factorial “flavor” frame-work, where they disaggregate methodology issues rather then conflating them. (And note that interactions are actually maintained, since they did a full factorial, not 6 OFATs). I would also put a little bit of a difference between something being easy to understand and well communicated versus it being RIGHT. Remember, Strunk’s mantra, “if you’re going to guess on a word pronunciation, say it LOUD”. Actually, I thought that the full factorial part of Burger and the later part (about training periods and the like) were enough different that it maybe justified two separate publications. Rereading it, he does connect them, but still. There is enough to do two papers. But I stand firm in my liking of that paper’s well-writtenness as well as the elegance of the problem-solving insight involved in the flavor framework.
2. That’s great that you are going to publish. I think you will get some personal rewards from it. I think it is best to have things in abstracted, archived literature that is peer-reviewed. I think that it will spur others to take your work into consideration and will better push them to improve their work. I also think it will raise your own game.
3. If you DON’T think of Tellus as an appropriate journal for the type of publication that you have, then I caution you against submitting because of the BC equation 8 correction. Especially if that is not the main point of your proposed paper. To do so, would indicate the same type of kitchen sink conflation that bothers me in other places.
4. Caution you to be clear, to publish (many) LPUs* rather then kitchen sink compendiums, to thoughtfully consider what message is appropriate in what journal, and to be clear in writing. No snark intended, but I say this having seen that you are lacking in some of these things in the past (e.g. Powerpoint for the meeting that was a mess). I am not a naturally organized thinker or tactical publisher either. But I can see the quality of being so, and with much effort drive myself to be so. I think you can as well.
5. I think almost all the major analyses here could still be published if properly rewritten despite the publication on this site. I doubt that you have tried hard enough to do so or are just anticipating rejections rather then reacting to them.
*Note that this does not stop you from publishing overarching “review” articles that draw on all of them in the future. If anything it better justifies doing so.
C. No I’m not saying that there’s an error in the flavor runs. If you re-read B-C, you’ll see that section 3 is about VZ variance attenuation and section 4 changes gears completely and discusses non-robustness of MBH-type methods.
I don’t think that section 3 is either correct or very clear. I have no reason to doubt the results in section 4 and this section and their approach is very good. As with these things, I don’t think that it’s the end of the story. The “flavors” are an interesting rhetorical device, but they are not tied back to known multivariate methods very well. This is not a criticism of B-C for not doing this because the act of presenting things changes how you see things.
For example, I would submit that we showed in an empirical sense that MBH results were non-robust, focussing on issues of PC methodology and proxy selection. B-C substantially generalized these empirical results (and despite my discontent with their handling of the VZ issues), I think that this other portion dealing with non-robustness is terrific. They did so in two ways: first by showing other forms of non-robustness in the MBH proxy network (Burger and Cubasch, GRL 2005) and then in regression methods themselves even with the very tame VZ pseudoproxy network (Burger et al 2006) – rather than the “wild” MBH proxy network, using “tame” and “wild” as mathematicians do.
This latter portion is stimulating for me. However, the arrangement of “flavors” do not link back in a tidy way to usual arrangements of multivariate methods. In multivariate statistical literature, there is a small industry making diagrams associating different techniques: Stone and Brooks 1990 link OLS, PLS through a continuum of ridge regression. Borga has some pretty arrangements. Burger et al did not achieve any sort of pattern in their flavors and I think that the “flavors” can themselves be arranged in a more elegant pattern tying back to multivariate statistics. This is an ambitious project for an aging businessman but the 19-year old math major still tries to break out now and then. I’ve been thinking and researching this for quite a while. It interferes with finishing other projects, but it’s got a chance of achieving finality to this particular project, which I’m anxious to do. I’m not good at compartmentalizing and I’m envious of people, like Clinton, who can seemingly without effort move from file to file and give attention to each.
Good on you.
I guess I need to re-read BC. I sort of automatically divide that paper into the MECE flavor part and the “extension of uncertainty” part. I will take a look again to see what you are calling the VZ variance part.
Steve, can’t you go further with your equation by showing that you get exact reconstruction during the calibration period i.e.
by showing that you get exact reconstruction during the calibration period i.e. 
#5. You don’t quite get to such a complete overfitting. But one of the big consequences of deriving this result is that it forces (or should force) people to squarely face what’s going on in the calibration period, the hopeless overfitting and the mendacity of using calibration period residuals for confidence intervals.
In the AD1820 period, this boils down to regressing temperature in a period of length 79 years against 112 proxies (and against 22 proxies in the AD1400 step). In OLS, you would rotate the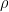 of correlation coefficients by
of correlation coefficients by 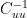 but not in PLS. In theory, PLS is applied in situations of multicollinearity, but the MBH network has many series that are essentially white noise and thus the proxies are surprisingly close to being orthogonal in the early networks and there are blocks of orthogonal series in the later network. Because of the orthogonality, the PLS coefficients are surprisingly close to the OLS coefficients.
but not in PLS. In theory, PLS is applied in situations of multicollinearity, but the MBH network has many series that are essentially white noise and thus the proxies are surprisingly close to being orthogonal in the early networks and there are blocks of orthogonal series in the later network. Because of the orthogonality, the PLS coefficients are surprisingly close to the OLS coefficients.
Imagine regressing temperature against a whole swarm of near-orthogonal proxies in an OLS regression and then using these residuals for confidence interval estimation. It’s one of the big scandals in the whole sordid affair. We raised this with the NAS panel, but I don’t think that any of them got the point. The two statisticians were frequency-domain guys and didn’t seem attuned to this, but I could be wrong.
Steve, we used the “awkward”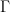 yx simply because with it you can actually prove variance attenuation for “direct” regression – via canonical correlations. Do you know a reference where this has been shown before?
yx simply because with it you can actually prove variance attenuation for “direct” regression – via canonical correlations. Do you know a reference where this has been shown before?
We then thought – erroneously – that this could be turned into an easy proof for variance amplification for inverse regression (the MBH way). You now seem to doubt that there actually is amplification here. I wonder whether you checked this numerically. In all of my cases there was amplification, and all corresponding matrices, such as Kyx, did have eigenvalues >1 (see my earlier post).
I would love to see a counterexample.
There is no counterexample. The corrected proof is here. If you find an error please don’t tell me. 😉
Herrdoktorprofessor: Koenten Sie bitte erkaleren fuer uns dumbkopfen wie das geht ohne so strenge vectors und solche sachen?
Just take the 1-dimensional case. You regress a noisy x on a noisy y, finding a rather flat slope (= attenuation). Then you invert that, and the slope becomes quite steep (= amplification). That’s all.
re #8: Thanks, Gerd. I’ll check it today, but if I find a mistake I do not promise not to report it 😉
Gerd (if this is too tedious, don’t bother…I’m not matastute in this field):
1. How are both the x and y noisy? If x is years and y is ring width, I would think that y would be noisy, but x not noisy.
2. If both are equally noisy, I would not expect any particular tendancy for flat or steep best fit lines.
3. If there is a given slope (y=kx), then adding y axis noise in general (imagine doing it multiple times), will have an overall effect of what? A tendancy to make the k value vary? Effect of (on average) of driving k down (like averaging a line with zero slope)? Is the noise, noise from the trend line or noise from “zero”? In other words, what is the average slope of the noise? Are you just averaging in stuff that has a slope of zero on average? And how are the mean of the noise and the mean of the trend line related?
4. I’m not clear what “inverting” means. If we have y=kx, does inverting mean y=(1/k)x? Or y= 1/(kx)? or just somehow “plotting” x=(1/k)y?
re #12: TCO, x is not “years”, it’s “proxies”. Both “proxies” and “temperature PCs” are noisy. Read carefully this post, which IMHO is still the most readable account of MBH98 Calibration-Estimation procedure.
JeanS:
A. Are you still in the one dimensional land where Gerd was speaking to me?
B. If you say that x is “proxies”, what does that mean? Number of them in the reconstruction?
C. I can’t follow that post, Jean.
t is time, x(t) is a proxy, y(t) is the NHT PC1. Then x is regressed on y,
x(t) = G*y(t) with G 1.
Interestingly, the “smaller than” and the second equation didn’t go through – although my preview showed them (maybe conflicting with the tag-syntax). So let me try again: The above equation gives
y(t) = 1/G x(t) with 1/G larger than 1.
I would recommend that people use the [ tex][ /tex] tags, so that Gerd’s last comment should read:
SG H-D Prof:
RE 15: Ok, I think I get it. Thanks
a. Why the PC1 of the instrumental temps? Why not, the value itself?
b. Why looking for a correlation with global vice local temperature? Seems non-physical to me and likely to lead to data mining/overmodeling. If there is a plausible teleconnection, then we should model to the teleconnected variable, no? But just fishing for local measures of a global trend? Seems fishy. Like throwing 20 stats into a bag and picking the one that comes up at 95% confidence level for significance! And at a minimum, hurts the claim that we have built up a global picture from multiple local sources (since they’re not really local if they are globally trained/selected/weighted).
c. What are the units for temp and proxy? Standardized and if so, how? This will influence the slope, no?
d. Question 12-2 remains. Can you explain?
e. I agree that a flat sloped line when replotted as x-y versus y-x is now steep. Why is that interesting? We all know that, no? Is there some further thing with variance or mean or something?
Please excuse my humble questions. I have no mathematical training in stats or linear algebra.
Gerd, I don’t mean to be ignoring this, but you will understand that I’ve been otherwise preoccupied with the NAS report. I appreciate the comments here and will take a look some time next week.
Gerd,
re 8 that’s interesting result. So, before Mann rescales RPCs they all have larger variance than the target PCs (calibration period). Variance matching makes the variances equal. And as Mann does not reconstruct all PCs, and RPCs are variance-matched to the target PCs, effectively the variance of reconstruction is always less than variance of target temperature. That’s why vS04 thought it is direct regression. And that’s why Mann claims that
even though INVR itself actually amplifies.
One Trackback
[…] with CCE. In the absence of noise, ICE and CCE yield (naturally) the same result. Update: see Gerd’s link and, and also note that ICE is a matrix weighted average between CCE and zero-matrix (Brown82, Eq […]