Here is what Reviewer #3 submitted in his review of the Bürger CPD submission (I’ve taken down the draft review.) He regrets agreeing to do the review (for reasons that will become clear). Even though Reviewer #3 has much goodwill towards Bürger, he is rather a stickler for detail and it seems rather unfair that Bürger should draw Reviewer #3 for this submission and Michael Mann for his last submission, while other authors get cheerleaders. Reviewer #3 hopes that he has managed to separate his comments from his POV, although the separation is not always easy.
He appreciated the thoughtful response from CA readers, especially TCO. The online submission of reviews was turned off when Reviewer #3 sent in his review, so he sent it to the editor by email. We’ll see what happens. Reviewer # 3 writes:
I have benefited from reading the reviews of the two other referees. I have written on these matters and am cited in this article, my comments should be weighed in that context.
I see two fairly distinct objectives within this paper:
– the proposal that multicalibration provides an advance in statistical methodology for evaluating temperature reconstructions;
– the estimation of a “model skill” for MBH98 of around 25%
I think that these two objectives fit together very uncomfortably within one article. If one wants to propose multicalibration of RE and CE calculations as a novel application for testing climate reconstructions, the utility and benefits of this method should be demonstrated on uncontentious pseudoproxy networks where one knows the properties (perhaps the von Storch-Zorita pseudoproxies could be used). Perhaps multicalibration will yield new insights relative to present methodologies; perhaps not. But one should not use the same dataset (in this case MBH98) to develop the method, which is then used to evaluate the dataset. In this case, one could hardly pick a worse data set than MBH98 to benchmark a novel application of a statistical method, since the dataset is controversial.
Bürger correctly observes that very high RE statistics can arise from “nonsense”/”spurious” regressions. In addition to the example provided by Bürger, the stereotypical examples of spurious regression (alcoholism rate versus Church of England marriages [Yule 1926]; cumulative rainfall versus money supply [Hendry 1984]) have high RE statistics. This is a point that makes it imprudent for paleoclimatologists to rely exclusively or over-rely on RE statistics and might well be made more forcefully by the author.
Econometricians have pondered the spurious regression problem for many years, as Eduardo Zorita observed in a CPD review last summer. There has been much searching for a statistic that could serve as a magic bullet for separating spurious relationships from valid relationships, but thus far, there is no such single statistic. Granger and Newbold 1974 observed that spurious correlations arose between random walks; that many such spurious relationships failed Durbin-Watson statistics and urged practitioners to check this statistic before jumping to conclusions from high r2 statistics. The NAS Panel last summer also urged that this statistic be consulted. Most of the well-known millennium reconstructions fail the Durbin-Watson statistic in the calibration period and the verification r2 statistic (Bürrger’s cross-validity) in the verification period. However, the Durbin-Watson statistic primarily watches out for first-order autocorrelation and other sources of spurious relationships, such as uncontrolled or mis-specified variables must be watched out for as well in any attempt to evaluate the validity of a model. At present, in the absence of any universal method of identifying spurious correlations, applied practitioners must look at the data from multiple perspectives – something that is very much in the spirit of the NAS panel recommendations.
While Referee #1 says that multicalibration brings a “rigorous assessment” of the quality of a reconstruction, it is still not the “magic bullet” that economists have sought for. In order to show this, I tested the method of Bürger’s Figure 3 against a classical spurious relationship — Yule’s marriage-alcoholism relationship mentioned above. In this particular case, very high RE statistics are returned for all permutations and combinations. In Bürger’s terms, the “model skill” here is well over 80% and yet one remains unconvinced that there is an underlying relationship. (I will posted a script for this and some related calculations at http://www.climateaudit.org/scripts/proxy/burger.txt)
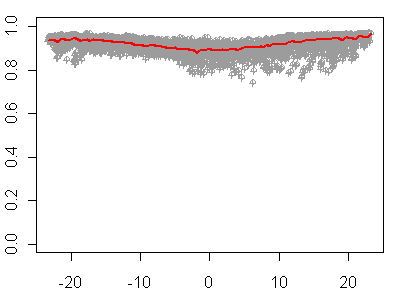
Figure 1. RE statistics from multicalibration of Yule’s relationship between alcoholism and Church of England marriages.
In respect to Bürger’s other enterprise, the estimation of a “model skill” for MBH, while Bürger has presented many interesting graphs, which might well be the topic of a very focused paper, without a full, previous qualification of multicalibration as a statistical method, it is inappropriate to use it here to estimate “model skill” in a contentious situation. While I share Referee #2’s concern that the term “skill” (which is used 50 times in the article) is never defined, I view the more serious problem as being the fluidity in use of the term, which includes, as Bürger said in his reply to Referee #2, a colloquial usage on the one hand and on the other hand a seemingly technical use as a property of models that can be be estimated.
If Bürger proposes to estimate “model skill”, he needs to establish that the model is even valid, which requires a considerable amount of statistical analysis additional to what is provided here.
In view of the criticisms in our articles, endorsed on this point by both the NAS Panel and the Wegman Report, I do not believe that the MBH98 PC1, as calculated, can continue to be used as a proxy even for the exercise undertaken by Bürger. Any skill in a model which includes the use of this particular series will necessarily have a fortuitous element to it. As a result, I’m afraid that there has been a considerable amount of wasted effort in analysing permutations and combinations of reconstructions involving this particular proxy (or red noise models based on this proxy) if the ultimate objective is to estimate “model skill”.
In addition, if “model skill” is to be estimated, the “robustness” of the model (using “robust” in the sense of say, Frank Hampel) needs to be assessed. This requires the examination of “leverage points”; in many cases, as observed by Hampel, the retention or exclusion of “leverage points” needs to be decided on scientific grounds rather than statistical grounds (a statistic may identify data as a leverage point, but may not be able to say whether the underlying data is usable or not.) In the case of the MBH98 data set, bristlecones have been identified as having great leverage. Any attempt to attribute “model skill” to MBH98 needs to discuss these leverage points, which would also require the author to address the NAS Panel recommendation that these series be “avoided”. Given that there are only 22 series in the MBH98 network, I would urge that any attempt to estimate MBH98 “model skill” include a plot of the 22 series in a concise format, plus a plot and discussion of the residuals from, say, the 222-flavor.
There are any number of details which should be tidied up. The article needs to be spell-checked in English. It should probably be broken into distinct papers. The exposition needs to be improved.
Following are some of the points that I’ve noted, but the list is by no means exhaustive and I’d be happy to provide further comments offline.
251, 9: The NAS Panel Report and the Wegman Report should both be added to this list, as should McIntyre and McKitrick [EE 2005b], which is complementary to McIntyre and McKitrick [GRL 2005] which is cited.
251: 9-11. “the aspect of verification has not found a comparable assessment”. I suggest that this wording be modified as it is inconsistent with the discussion of page 266.
251 29: The term “robust” has a specific meaning in statistics that is inconsistent with the usage here. If the term is to be used, it should be consistent with usage by (say) Hampel.
252 10: Gordon in Hughes et al, eds. Climate from Tree Rings 1981, p 60, discusses the splitting of periods, citing McCarthy 1976 for what seems to be what Bürger calls multi-calibration as follows:
Of course there are a great many different ways that the data may be halved and the selection of a proper subset of these possibilities has been discussed in some detail by McCarthy (1976)
253 17: MBH98 and MM05 do not use the term “level of no skill”.
254 9: Briffa et al 2001 uses a different network that is relatively distinct from the others which do overlap a lot.
254 10: While, some of the cited studies calculated verification statistics, many did not.
Briffa et al 1992 reports all the tests listed in Fritts 1976; Briffa et al 2001 report verification r and RE statistics, but, based on a quick inspection, I don’t think that any verification statistics are reported in Jones et al 1998; Crowley and Lowery 2000; Esper et al 2002.
254 14: In the context of Wilks 1995, it might be noted here (or in the discussion of the relationship between verification statistics) that they show an equation linking RE to verification r2 under the assumption of constant climatology, citing Murphy (1988). Under that equation, the RE is necessarily lower than the verification r2 statistic.
254 15-17: Do Fritts 1976 and Briffa et al 1988 actually say this exactly?
254ff: I don’t get how this discussion is necessary to the development of the conclusions announced in the Abstract. Many readers will find it distracting. I skipped over the section, and even when I came back to it, I had trouble figuring out the point. If the section is retained, shouldn’t the relationships between verification statistics presented in Murphy (1988), cited in Wilks 1995, be mentioned as well?
255 20: Wahl and Ammann 2007 do report MBH98 scores from their emulation, which are virtually identical to scores previously reported in MM05a? Would it be unreasonable to cite the earlier report as well?
256 7: Are you sure that Lorenz 1956 really the “first” article to estimate this dependency? The citation in Raju et al 1997 mentions some articles from the 1930s that seem to be on this topic.
256 15-20: I couldn’t replicate this figure or this calculation. I’ve posted up my script and maybe the author can point out why I’m having trouble.
256 21: It’s certainly possible that equation (4) applies to say Partial Least Squares regression, but shouldn’t a citation be provided for this claim? If no citation can be found, I don’t see that it’s necessary for the development of the article.
257 1: the simple trend is “a” trivial predictor, but I wouldn’t call it “the” trivial predictor which has mathematical connotations not present here.
257 1-16: the existence of spurious RE statistics is important. However I don’t see how the term “calibration mean bias” contributes to the discussion.
257 13 I understand the point here, but why is it a “discrepancy”? And what is the value of saying that there is an “enormous bias in the calibration mean”?
259 13: I’ve presented results from the classic Yule spurious regression, which show a high RE value regardless of the temporal separation of the calibration and verification data sets. So I think that there’s a lot of heavy lifting to be done before one can conclude that a general property has been established.
265 1-10: Bürger misses an important aspect of the concept of “spurious regression” in this discussion. I would urge him to read or re-read Granger and Newbold 1974 and Phillips 1986, before re-writing this section. The problem, as posed in econometrics literature, is how a regression between unrelated series can yield a statistic that indicates “strong significance”. The strategy of Phillips 1986 was to see if the the conventional distributions accurately described the circumstances being tested, looking, in particular, at the random walks of Granger and Newbold 1974. Phillips observed that conventional distributions for t-statistics did not apply for this type of model and, when the distributions were re-calculated, the seemingly significant statistic proved not to be so. This was our strategy in MM05a, where we sought to explain the seeming discrepancy between the failed verification r2 (and CE statistics) of MBH98 and the high RE statistic. While I may disagree with some nuances of the calculation in Bürger’s Figure 6, I endorse the approach of examining actual distributions. My disagreement with the characterization of this paragraph is that, in my opinion, it fails to adequately record the problem thrown up by failure of one important verification statistic. However, the above comments very much reflect a POV; while I would urge the author to consider the POV, it would be inappropriate for me to insist that this POV be adopted.
265 8: The “trivial” model may have a high RE statistic, but,as the author obviously realizes, it is not “significantly skillful” and this wording should be changed.
265 11-18: This paragraph is poorly worded and particularly hard to understand.
265, 17-18. The proposed significance benchmark of RE=54% was relevant to the analysis as carried out in MBH98, which was what was being discussed at the time.
265 20-25: as noted in paragraph 6 of this review, evaluating models requires not only a consideration of autocorrelation properties, but of potential misspecification, which requires a different suite of methods, which are too quickly assumed out of existence here.
266 10. Bürger’s characterization of the methodology of MM05a, MM05c is incorrect. Bürger stated that the red noise predictor was estimated from “one of the 22 proxies”. In fact, the red noise predictor was simulated by doing a principal components analysis under MBH methodology on a network of 70 red noise series (constructed according using the algorithm described by Bürger at 267 5-10.) The properties of these time series differ somewhat from the time series generated by a univariate model of the MBH North American PC1. This difference in procedure probably accounts for some differences in our red noise results and Bürger’s (although both simulations yield many a substantial population of positive RE values from red noise simulations.)
266 13: where does the figure of 36% come from? I read Huybers as arguing for a value of 0.
266 14: the same point applies as 266 10 in respect to the simulated PC1s. I’m uncertain what Bürger’s question is in respect to “uncorrelated?” here. White noise series are by definition uncorrelated. I would be happy to provide clarification for any remaining question.
266 22: In MM05a, we described our simulations as establishing a “lower limit” for a benchmark since our distributions were entirely obtained from operations on noise. I agree with Bürger’s observation about “lower bound” on line 22, but this was also approach, which is not noted here.
266 21. I don’t understand what is meant by “convergence” here or the utility of this concept under these circumstances. My key objection to Bürger’s simulation approach here, insofar as it is an attempt to simulate salient particulars of MBH, is excessive reliance on univariate modeling red noise modeling of the MBH North American PC1 (as opposed to modeling of a PC network),
266 19: To this recital, the viewpoint of Wahl and Ammann 2007 needs to be discussed.
267 8: Our simulations were done using Brandon Whitcher’s algorithm stated to be an implementation of the method of Hosking 1984 (as cited in our text and code). A correspondent has said to me that the Whitcher algorithm has somewhat different properties than Hosking 1984 and accordingly the Whitcher algorithm is the more precise citation here.
267 24: Bürger reports that the MBH-type reconstructions have somewhat higher typical realizations than red noise networks as he modeled them. In order to claim that this difference is “significant”, a significance test should be performed.
269 10-15: Some (no doubt Wahl and Ammann) might argue that the RE and CE statistics with the record split in half in calendar years is to be preferred because it provides information on “low frequency” that is unavailable from multicalibration. Whether one agrees or disagrees with this argument, it should be dealt with.
269 29: this is an interesting argument that appears out of nowhere. In order to be stated as a conclusion, it needs to be proven in the text.





61 Comments
Suggestions to create a more science-useful review:
(I have looked at the paper, but it is still a mess…and I’m not going to fix it line by line)
On the paper:
A. Still suffers from being too many papers at once: unclear if the focus is on MBH or on general reconstructions. Almost seems like it’s really on MBH, but there is an attempt to generalize to make the paper seem more important. Also, unclear to what extent the author’s comments on RE/CE apply only to temp reconstructions or are useful basic stats comments, appliying to econ, etc. The “flavor” stuff seems out of place. It was awesome when we wanted to see how methodology affects recon shape in BC05 and was the main subject. HEre it’s not really right tool.
B. Paper still has poor logic and English. Just write a simple direct high school student paper that says what the problem is that is being examined. That creates a good test. That shows the data. And then that makes conclusions. Huybers comment is a very good model to emulate for revelatory analysis and write-up.
C. The whole RE/CE (or even bootstrapping in general) is questionable for hindcasting. Shouldn’t we use all the data to fit the best curve? And don’t we implicitly do this by rejecting models that don’t pass the 2-step tests? Really, out of sample tests are needed to check posited relationships. And RE/CE division is NOT out of sample.
In addition, it uis probably useful to think about how well a relationship matches data over time. Per EZ’s comment, what we really need to see is “wiggle-matching” of the relationship and the data to get a feel that this is more than just a single (or double with RE/CE) comparsion test of say 100 years temp rise and model showing 100 years rise. I thin “binning”, RE/CE, and aopther metrics (r2?) that compare performance over shorter periods within the historical data are all trying to do the same thing in a way. There is no way to REALLY test W&A’s lonlow frequency hypothesis unless we have more historical temp data or wait 400 years, or invent a chamber that accelerates plant growth. But wiggle matching helps to make the relationshop more likely to be true. THe problem is that tree rings have so many confounding factors. The only answer there is to get lots, lots more data and/or to do experimental studies to determine the exact nature of confounding variables (which vary randomly, which covary, etc.)
For your review:
-there are some good parts where you share general knowledge that is helpful to the author and to science.
-there are some bad parts where you ask for too much citation, or try to have a debate on your paper versus his versus Mann’s.
-in some cases, this is not even germane to Burger’s paper (e.g. “in passing”), but us just general hockey stick war debate.
-A particular example of this is the BCP stuff. OF COURSE, factors that covary can influence the reconstructions and of course, we have an issue with both CO2 and temp going up at the same time. Like DUH. That’s basic six sigma/DOE stuff. BUT THAT’S NOT WHAT BURGER’S ARTICLE IS ABOUT. Let him analyze one issue rather than having to rehash all the various places where MBH might be wrong. (Same deal with the Yule citation, and btw, theis is a place where even r2 has plenty of issues. But, no stat will ward off every evil. There is always the 5% that is the danger with the 95% confidence interval. Always dangers of data of sampling, of uncontrolled variables. But those are well-known issues, which can be addressed on their own. Burger is NOT writing an assessment of MBH. He’s writing about RE/CE.
-Burger’s red noise levels may be too low. But your levels may be too high or too “modeled” to mimic an actual data set (I think you had 70 different sets of 5 parameters…that’s lilke 350 parameters. I could fit an elephant with that. Maybe I have it wrong here–You were unwilling to answer questions here–referring to the code and saying figure out the subrotuines on yourself–and one time misdirecting towards “fractional differencing” w)
Sorry about typos. This comment box is not working correctly and on a laptop the preview does not help. Will try to compose off line and cut and paste.
The unintelligable paragraph cited above reads:
I could translate this as:
“This whole approach begs the question of whether any of these approaches can be said to be significant when compared to a table of random numbers. We could be being fooled by random walks, autoregression and persistent noise. Our simple metrics don’t help”
Specific edits:
I have benefited from reading the reviews of the two other referees. I have written on these
matters and am cited in this article, my comments should be weighed in that context.
I see two fairly distinct objectives within this paper:
– the proposal that multicalibration be used as a statistical test for reconstructions;
– the estimation of a “model skill” for MBH98 of around 25%
I think that these two objectives fit together very uncomfortably within one article. If one
wants to propose multicalibration of RE and CE calculations as a novel application for testing
climate reconstructions, the utility and benefits of this method should be demonstrated on
uncontentious pseudoproxy networks where one knows the properties (perhaps the von Storch-Zorita
pseudoproxies could be used). Perhaps multicalibration will yield new insights relative to
present methodologies; perhaps not. But one should use datasets that themselves are under
examination (e.g. MBH) to develop a method, which is than used to evaluate the same dataset.
In addition to the example provided by Bürger, the stereotypical examples of spurious high r2q
(citations) have high RE as well.
Bürger correctly observes that very high RE statistics can arise from “nonsense”/”spurious”
regressions. This is a point that makes it imprudent for paleoclimatologists to rely exclusively
on RE statistics. Econometricians have pondered the spurious regression problem for many years,
as Eduardo Zorita observed in a CPD review last summer. There has been much searching for a
statistic that could serve as magic bullet for separating spurious relationships from valid
relationships, but thus far, there is no such single statistic. Granger and Newbold 1974 observed
that spurious correlations arose between random walks; that many such spurious relationships had
failed Durbin-Watson statistics and urged practitioners to check this statistic before jumping to
conclusions from high r2 statistics. The NAS Panel last summer also urged that this statistic be
consulted. Most of the canonical millennium reconstructions fail the Durbin-Watson statistic in
the calibration period and the verification r2 statistic (Bürger’s cross-validity) in the
verification period. However, this statistic primarily watches out for autocorrelation-enhanced
matches. Other sources of spurious relationships, such as uncontrolled variables or even chance
exist as well. At present, in the absence of any universal method of identifying spurious
correlations, applied practitioners must look at the data from multiple perspectives ‘€” something
that is very much in the spirit of the NAS panel recommendations.
While Referee #1 states that multicalibration brings a “rigorous assessment” of the quality of a
reconstruction, it is still not the “magic bullet” that economists have sought for. In order to
show this, I tested the method of Bürger’s Figure 3 against a classical spurious relationship ‘€”
Yule’s marriage-alcoholism relationship mentioned above. In this particular case, very high RE
statistics are returned for all permutations and combinations. In Bürger’s terms, the “model
skill” here is well over 80% and yet one remains unconvinced that there is an underlying
relationship. (I have posted a script for this and related calculations at
http://www.climateaudit.org/scripts/proxy/burger.txt)
Figure 1. RE statistics from multicalibration of Yule’s relationship between alcoholism and
Church of England marriages.
(YOU MAY WANT TO WRITE A FORMAL COMMENT IF THIS IS AN IMPORTANT CALCULATION–I DON’T. ALSO, NOT
SURE THAT THIS IS REALLY RELEVANT TO BURGER’S PAPER, IF BURGER NEVER MAKES tHE “RIGOROUS” CLAIM.)
In respect to Bürger’s other enterprise, the estimation of a “model skill” for MBH, Bürger has
presented many interesting graphs, which might well be the topic of a focused paper. However,
without a full, previous qualification of multicalibration as a statistical method, it is
inappropriate to use it at present to estimate “model skill” in an uncertain situation.
While I share Referee #2’s concern that the term “skill” (which is used 50 times in the article)
is never defined, I view the more serious problem as being the fluidity in use of the term, which
includes, as Bürger said in his reply to Referee #2, a colloquial usage on the one hand and on
the other hand a seemingly technical use as a property of models that can be be estimated.
There are any number of details which should be tidied up:
-The article needs to be spell-checked in English.
-It needs to be broken into appropriate papers (for full explication) or a considerably longer
paper needs to be written (preferably the former).
-The writing is unclear in overall story and in specific sections. I recommend that Professor
Burger consult with a technical writer to help with getting a clear story and clear prose–this
is the second submission of this paper and the problem remains.
Following are some of the points that I’ve noted, but the list is by no means exhaustive and I’d
be happy to provide further comments offline.
251, 9: Recommend to add McIntyre and McKitrick [EE 2005b] as it is complementary to McIntyre
and McKitrick [GRL 2005] which is cited. (STEVE, I AGREE WITH LEAVING THE PUBLIC COMMISIONS OUT.
THERE’S NO ORIGINAL WORK IN THEM. BURGER’S PAPER IS ON RE/CE SCIENCE, NOT ON PUBLIC COMMISIONS
OR CONTROVERSY OR WHAT PANEL OF EXPERTS ENDORSES WHO.)
251: 9-11. “the aspect of verification has not found a comparable assessment”. I suggest you
modify this wording. This is inconsistent with the discussion of page 266.
251 29: The term “robust” has a specific meaning in statistics that is inconsistent with the
usage here. Per reference, BLUE BOOK TUKEY, it means BLABLABLA. A better way to discuss the
colloquial issue of robustness is BLEHBLEH.
252 10: Gordon in Hughes et al, eds. Climate form Tree Rings 1981, discusses the splitting of
periods, citing McCarthy 1976 for what seems to be what Bürger calls multi-calibration.
(GOOD!!!)
253 17: MBH98 and MM05 do not use the term “level of no skill”.
254 9: Briffa et al 2001 uses a different network that is relatively distinct from the others
which do overlap a lot.
254 10: While, some of the cited studies calculated verification statistics, many did not.
Briffa et al 1992 is the most comprehensive, reporting all the tests listed in Fritts 1976;
Briffa et al 2001 report verification r and RE statistics, but, based on a quick inspection, I
don’t think that any verification statistics are reported in Jones et al 1998; Crowley and Lowery
2000; Esper et al 2002.
254 14: In the context of Wilks 1995, it might be noted here (or in the discussion of the
relationship between verification statistics) that they show an equation linking RE to
verification r2 under the assumption of constant climatology. Under that equation, the RE is
necessarily lower than the verification r2 statistic.
254 15-17: Do Fritts 1976 and Briffa et al 1988 actually say this exactly?
.
254ff: I don’t get how this discussion is necessary to the development of the conclusions
announced in the Abstract. Many readers will find it distracting. I skipped over the section, and
even when I came back to it, I had trouble figuring out the point. If the section is retained,
shouldn’t the relationships between verification statistics presented in Murphy (1988), cited in
Wilks 1995, be mentioned as well?
255 20: Wahl and Ammann 2007 do report MBH98 scores from their emulation, which are virtually
identical to scores previously reported in MM05a. Would it be unreasonable to cite the earlier
report as well?
256 7: Are you sure that Lorenz 1956 really the “first” article to estimate this dependency? The
citation Raju et al mentions some articles from the 1930s that seem to be on this topic.
256 15-20: I couldn’t replicate this figure or this calculation. I’ve posted up my script and
maybe the author can point out why I’m having trouble.
256 21: It’s certainly possible that equation (4) applies to say Partial Least Squares
regression, but shouldn’t a citation be provided for this claim? I don’t see that it’s necessary
for the development of the article if no citation can be found.
257 1: the simple trend is “a” trivial predictor, but I wouldn’t call it “the” trivial predictor
which has mathematical connotations not present here.
257 1-16: the existence of spurious RE statistics is important. However I don’t see how the term
“calibration mean bias” contributes to the discussion.
257 13 ‘€” I understand the point here, but why is it a “discrepancy”? And what is the value of
saying that there is an “enormous bias in the calibration mean”?
259 13: I’ve presented results from the classic Yule spurious regression, which show a high RE
value regardless of the temporal separation of the calibration and verification data sets. So I
think that there’s a lot of heavy lifting to be done before one can conclude that a general
property has been established.
265 11-18: This paragraph is poorly worded and hard to understand. Is the point is that
different settings for significance (e.g. the Huybers, MM discrepancy) depend on the level of
challenge of the pseudoproxy test set?
265, 17-18. The proposed significance level of RE=54% is relevant to the analysis as carried out
by MBH, which is what was originally being discussed.
265 27: “red” is meant, “white” is written.
266 10. Bürger’s characterization of the methodology of MM05a, MM05c is incorrect. Bürger stated
that the red noise predictor was estimated from “one of the 22 proxies”. Details of the exact MM
methodology are best understood by looking at the code (archived HERE) and at the subroutine,
(available HERE). Actually, those experiments used a network of 70 series which had the red
noise properties of the MBH North American network, from a 5-parameter (ARMA) model (OR WHATEVER
IT WAS THAT YOU DID).
266 13: where does the figure of 36% come from? I read Huybers as arguing for a value of 0.
266 14: “White” is said, “red” is meant. I’m uncertain what Burger’s question is with the
“uncorrelated?”, but this should be figured out looking at the method details (which are public).
266 16-19: Given the lack of understanding of the actual MM method, Burger needs to clarify what
his desired (level 5) method really is.
266 21. I don’t understand what is meant by “convergence”.
267 8: MM05 did not use “the method of Hosking84”, it used a public subroutine titled “Hosking”
Which does different things.
267 24: Bürger reports that the MBH-type reconstructions have higher typical realizations than
red noise networks as he modeled them. This should be framed in terms of a significance test.
269 10-15: Some might argue that the RE and CE statistics with the record split in half in
calendar years is to be preferred because it provides information on “low frequency” that is
unavailable from multicalibration. Whether one agrees or disagrees with this argument, it should
be dealt with.
269 29: This inference should be omitted or the paper should be rescoped. (It comes in out of
nowhere.)
Since you need this in a hurry, just the typos, etc.
1. Paragraph beginning “I think that these two objectives” in next to last line R3 has “nay” instead of “may.”
2. In the paragraph following the graph, beginning “In respect to Bürger’s other enterprise” this first sentence is actually a sentence fragment. Get rid of the “while”.
3. 254 9: R3 has “OF” instead of “Of”
4. 256 21: need commas around “say”
5. 266 16-9 “which fails to account of the issues…” sb “which fails to account for the issues…” or “which fails to take account of….”
TCO, welcome back. It was a pleasure working through your edits. In nearly all cases, I’ve adopted your suggestions. In the few cases that I haven’t, I’ve seen why you objected to the point and re-stated it because I could see why you didn’t like it. It’s hard to avoid hobbyhorses and I appreciate your attention to detail here.
So Steve, why don’t you just come out and say that you are “Reviewer #3”? It seem mighty disingenuous of you to try and hide your identity when it is clear from the review that you are that person. Of course much of the other stuff that you write strikes me as disingenous, so why should I be surprised in this case.
#7. C’mon. I’m not trying to hide my identity. Get real.
JMS, you say:
This kind of innuendo has no place on a scientific blog. Either provide specific, detailed examples, or take it elsewhere …
w.
Steve, Willis,
JMS is a troll, or at least that’s all I remember him doing here. But it may be he doesn’t recognize the Reviewer 2 (I think it was Reviewer 2) thing from a while back and the question of whether it was Dr. Mann or just someone who resembled him. My assumption was that Steve was having a little fun playing off that.
Re: #10
These posters are not so much trolls as there are participants who let their POVs get in the way of their senses of humor, but so obvious is the reaction that I would think it barely deserves a reply.
LOL, I think JMS just didn’t get the humor.
Jae:
I think self-deprecating humor is beyond the ken of true believers!!
Gerd Bürger has replied to my review here http://www.cosis.net/copernicus/EGU/cpd/3/S151/cpd-3-S151.pdf ; I’m not convinced that he responded to the criticisms, but the tone was constructive. Gerd cited this thread as a place to discuss things, regretting that my comment at CPD was so late. I’m really sorry that it was so late as well. I probably won’t have time to reconcile the specific points for a month or so, but I’d be interested in any comments.
The final version is now published. Haven’t read it in detail to see what was cchanged, but it seems to hang together a little more logically, to be a little more tractable to tell what tha hell is at hand (or maybe I’ve just seen it so much).
On your April point, Burger is not clear on what the nature of the white noise is thatis being averaged in for your tests.
Link or Reference?
http://www.clim-past.net/3/397/2007/cp-3-397-2007.html
The gone final version of the Burger paper still has an open issue that was raised in the review process with Steve (that Burger does not understand the structure of the whiee noise used. Is it correlated, etc.) Please supply explanation of these noise series (preferred ) or the code for how they were gnerated (sufficient).
And stop deleting this post and I will stop reposting it. It’s on topic.
#18. I have no idea what point you are referring to. I generate white noise in R with the function rnorm for example x=rnorm(1000)
See page 405, first para (starts with numeral 4) in the Burger final paper.
Note that this question was also raised in Burger’s response (dated 7 APR, posted on the COSS site and evidently read by you, since you refer to it) to your review, S157 266 14
Steve: Please address the white noise nature question. Or if you refuse, say you refuse. Or if you are rpaidly doing some TNR re-reporting, than let us know that you will eventually respond.
P.s. If there is any confusion, I have already posted a direct question on this issue. It was deleted. Not sure if that was deliberate or accidental (caused by retro-spanking). I will not repeat it, so as not to enrage you by hectoring. Please let me know if it is helpful to have me repeat a direct inquiry.
The term “white noise” implies uncorrelated and, if Gaussian, independent. I’m not sure what the problem is. Perhaps Burger was curious if the 21 series were _mutually_ white? Using a noise generator as Steve did (noted above) would produce uncorrelated series.
Mark
Let’s get a definitive answer on that question.
Also, would like to hear Steve’s take on the final paper itself.
The only way they could be correlated would be if Steve intentionally did it when generating the noise series. Most modern random number generators have extremely low autocorrelations, with a repetition rate measured in years, sometimes centuries or more.
Mark
I dont understand why Burger would put a question mark there. White noise is “uncorrelated”. As I said before, the white noise pseudoproxies were generated by the rnorm function in R. Where I disagree with Burger’s calculations in this step is his failure to include the PC calculations in his RE simulations, when PC calculations are an integral part of the Mannian method. He says that the red noise properties of the PC series as it enters the regression should be modeled; this isn’t correct. The red noise properties of the series entering the PC calculation should be modeled and the PC calculation included as part of the simulation.
But Burger has also missed an extremely important aspect of the significance testing (which has also generally eluded climate people.) If the model fails a verification r2 test as badly as Mann’s does, it is not a valid model. Then the question is why was the RE statistic so high. Our explanation was that the RE statistic is not a “rigorous” test as climate scientists huff, but a statistic that has negligible power against spurious correlations. I gave a good illustration of this in my earlier review.
I really don’t have time right now to look at Burger’s final paper closely but will get to it sometime this summer.
“If the model fails a verification r2 test as badly as Mann’s does, it is not a valid model.”
-Is this really such a truism? Wegman commented before Congress that R2 was not really the right metric to look at. Is it not possible that in at least some situations that R2 (or “failure of R2 verification”) is not relevant.? (note that I’m not asking merely about the MBH case, but if it is EVER the case that R2 verification is irrelevant. (because you make the comment as a generalization and because if SOMETIMES R2 verification is not relevant, then we need tpo look at specifics of the MBH case, not just go off of your statement.
Why do you have time for solar and Anthony’s work and such and not have time for this? This seems much clsoser to your original work. You’ve declaimed the rejection of this paper (its progenitor). You have made a review of it, etc. Heck, I’m even interested if you think Burger’s points are more easy to read now (better explication).
A. Was the deletion of my direct request for the R code on purpose?
B. I would like the overall code for how you generate the 20 white noise proxies and combine them with the red noise. (Sorry, if this is imprecise, but I want the entire procedure that was elaboarted in your Huyber’s reply where you give a different method of benchmarking RE.
C. Burger wrote about this earlier in his reply to your review. In April. Did you see his concern thenn? (just curouis).
#25
Had to check, doc rand
You should probably check on randn, since rand is the uniform distribution. I’d do it myself but I just kicked off a 60 hour processing routine (many data sets) so Matlab is somewhat down at the moment. 🙂
Either way, of course, for any finite length time series there will necessarily be _some_ correlation, though it will be very small.
Mark
Oh, I should have said “finite length random series.”
Mark
If I was worrying about career advancement, I would stick to things like this. But I’m interested ultimately in understanding for myself whether increased CO2 is a big or little problem. One of the larger topics is the argument that solar could have caused temperature increases in the first part of the century but couldn’t have caused the increases in the latter part of the century.
This was discussed here a while ago in MBH98 Figure 7 (together with Chefen and Jean S) where Mann misrepresented certain aspects of the statistical relationship.
I’m trying to understand for myself exactly how much weight can be placed on any of the components in the relationship between solar and temperature, and exactly how much uncertainty if any, there is in any of the ocmponents.
I realize that there is some unfinished business on the Mann front, but Ammann and Wahl (which is what I have to deal with and which remains unpublished) is really turgid and mendacious.
But you’re right that I should comment on the final Burger paper sooner than the end of the summer. Burger is smart and interested in the topics that we’ve discussed so I owe him a serious review. I was asked to be a reviewer for the final paper but elected not to do so, as I figured that he was a decent guy and that he’d had enough aggravation with Mann as a reviewer for his first round and me as a reviewer for his 2nd round.
Yes yes, just wanted to show a larger number 🙂
Great Steve, I’m interested in your insights.
BTW, I don’t see finishing off the Mann issue analysis in the sense of career advance,eent. to me what is interesting is really figuring things out.
LOL!
At 100 M random numbers per second, ~31 M seconds per year, that would take 4×10^431 years to complete a single cycle! Yay! 🙂
Mark
Uh, wouldn’t that be x=rnorm(1000), but for 21 different x’s? I.e., in Matlab that would be
x = zeros(21,1000);
for i = 1:21
x(i,:) = randn(1,1000);
end
Mark
Steve (John, Anthony): If you are going to erase my response to Mark 37, then erase Mark 37. My response to him is that we need more than speculation on how one could to someting in matlab. My whole question is to understand EXACTLY what Steve did as there is a question about THAT. About if the different white noise series were correlated. Showing a matlab that doesn’t correlate series does not answer the question. Neither does Steve’s comment citing a single function in R. Burger first raised this issue in APRIL, folks. Why can’t Steve answer it. Would take 5 minutes!
You lot only seem to want honesty in one direction.
Don’t frigging delete this Steve. I’m allowed to make comments. Both on the sciene and on openness/honesty. And it DOESN’T MATTER if you don’t have time to address my snakr. You siuued plenty of your own and this is supposed to be a fair forum. Not some place where only “arguments that you have time to rebut” are allowed.
Steve, please provide the code used for this part of your published work (Huybers comment reply):
“We did new simulations in which we took 1000 simulated PC1s saved from the simulations
described in MM05; for each PC1 in turn, we made a “proxy network” of 22 series with the other 21
being white noise (replicating the 22 series of the MBH98 AD1400 network). We then used MBH98
methodology on the proxy network, including inverse regression of the proxies. After calculating the
reconstructed temperature principal component (RPC), we scaled the variance of the RPC to the
“observed” variance of the temperature principal component prior to calculating a NH average, from
which we calculated an RE statistic. The 99% quantile was 0.54, down slightly from 0.59 as found in
MM05a.”
Actually, Steve told you how he generated the data in R, x=rnorm(1000), which is what the comment by Burger (uh, Huybers?) was referring to. I merely posted what the loop would look like in Matlab because I don’t know how to do loops in R.
Mark
I want the complete procedure/code. This is the same attitude that Steve has towards others. I don’t know whether Steve is just being mulish for the hell of it. Or if he is actually covering something up. It could be either. But in either case, the behavior is reminscent of the unethical dealings of Jacoby, Esper, etc. Clearly, Steve seems to care more about eithics when it is in his service than in principles themselves.
And don’t erase this.
I have the right to make the point if free discussion is allowed. I’m not cursing and it;s on topic. If Steve is tired, or doesn’t like it, or whatever, tough. That’s free commentary.
Steve, my next step is a letter to GRL. Please supply the request.
#41. I’ve been distracted with other things.
Unfortunately journals do not require you to archive code at the time of publication and, in this case, to my regret, I didn’t archive a code SI at GRL at the time of publication, which would have been trivial to do. I wish that I’d done so, as I am committed to this practice although there’s no obligation to do so. Now I have to spend time ensuring that I locate the exact version that I used back then. Also at the time, my intent was to show working scripts as a guide to calculation and people have criticized such scripts for not being turnkey. It’s not that hard to make the codes turnkey i.e. eliminating internal references to directories on my computer and ensuring that all relevant materials are online somewhere. So it’s something that I need to do, should have done at the time and will do some time soon.
All of which proves why it’s a good policy for journals to require this stuff at the time of publication and for authors to do so.
TCO,
Your indignation would be more understandable if you had asked the warming alarmists for the same info.
It seems to me that you are simply hoping to hoist McIntyre by his how petard.
21 white noise series, generated with rnorm, say, have a diagonal covariance matrix. The AD1400 proxies, however, are by no means uncorrelated (e.g., the fran009 and fran010 series are almost identical), so that the true covariance matrix is far from being diagonal. This should be taken into account for a really thorough RE benchmarking.
But the proxies are not white. The problem is now – and that’s a real puzzle – how to obtain a multivariate (fractionally integrated) noise series with prescribed memory and mutual correlations at the same time. I am not aware of any algorithm that could do this.
In Bürger 2007 only the memory was prescribed. Therefore, the benchmarking was done with a few additional dof’s, leading to a slight overestimation of RE significance levels.
Hmmm, generally there will be too many elements to estimate. Some kind of stationary model is needed. Vector autoregressive process?
Gerd, this might be helpful:
Vance L. Martin and Nigel P. Wilkins: Indirect estimation of ARFIMA and VARFIMA models. Journal of Econometrics, Volume 93, Issue 1, November 1999, Pages 149-175.
Is geographic clustering considered at all? Spatial distribution is far from random.
Gerd (#45):
So long as the correlation matrix is positive (semi-) definite, this poses no theoretical problem. One can generate an approximate realization by taking a very long series of iid normals and pre-multiplying them by the inverse of the correlation matrix. However, there are much faster and easier ways to do this, in particular the FARIMA approach of Hosking [1981 Biometrika; I don’t have the reference in front of me].
The requirement that the correlation matrix be positive semi-definite does constrain things a bit, of course.
BTW, did I understand it correctly, MBH98 claims that RE greater than 0 is significant ? After data has gone through MBH algorithm ? Is it even possible to obtain negative RE after such regressions and variance mathings?
ftp://eclogite.geo.umass.edu/pub/mann/ONLINE-PREPRINTS/MultiProxy/stats-supp.html
Any positive value of beta is statistically significant at greater than 99% confidence as established from Monte Carlo simulations.
Sure, they are able to do it by detrending the series, see the third column in “calibration” for steps 1400-1500.
Jean
But I assume that MBH98 Fig 3 top is obtained by using all 112 proxy series and 11 TPCs (INVR+variance match). And it is claimed that even in that case positive beta is significant. I find it very hard to obtain negative beta with white noise, and I don’t think that redness in any direction will change this.
Gerd, from CiteSeer I found this
Modeling and Generating Multivariate Time Series with Arbitrary Marginals Using a Vector Autoregressive Technique by Deler and Nelson
wherein is an equation for covariance of VAR(1) process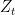 , for zero-lag
, for zero-lag
where is autoregressive coefficient matrix and and
is autoregressive coefficient matrix and and  is covariance matrix of driving noise (white in time). Using this I found one solution for your problem:
is covariance matrix of driving noise (white in time). Using this I found one solution for your problem:
You have N proxy series, each of length n.
1. Assume that all N proxy series are AR(1) processes with one-lag correlation p. Estimate p from the proxy data.
2. Draw samples (N vectors) from multivariate normal distribution, with specified NXN correlation matrix (use mvrnorm, for example). Correlation matrix is estimated from the proxy data (between series correlation).
3. Use these samples as driving noise for N separate AR(1) processes. As per the equation above, the correlation matrix will remain the same.
#47: Thanks, very good. VARFIMA somehow slipped through, although you might think that the sequence AR, ARMA, … is essentially infinite. 😉
I’m not sure though whether covariance is preserved by VARFIMA only after the whitening, that is, in the VARMA step. And I don’t think that is generally covariance or correlation preserving. On the other hand, maybe that’s what it needs for RE significance: reproduce the covariance after the whitening, that is, use VARFIMA. Unfortunately I’m not too familiar with that stuff.
is generally covariance or correlation preserving. On the other hand, maybe that’s what it needs for RE significance: reproduce the covariance after the whitening, that is, use VARFIMA. Unfortunately I’m not too familiar with that stuff.
They say it’s algorithmically complex, but if there is a program floating around then why not use it? However, given the shortness of the series I wouldn’t go much further than VARFIMA(1,d,1). And given the low verification RE levels the effort might not be worth it from the start: Low RE is bad, be it significant or not.
sorry, should be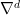 .
.
#53: UC, but proxies show long memory, so how do you deal with that?
If you can generate that process (long memory component + white noise etc) using i.i.d series as driving noise, you can apply the above method. But then the theoretical inter-series correlation might be more difficult to compute. Interesting problem, yet Im quite sure there exists a Department of Economics where it has been solved.
But white noise or not, I find it very difficult to obtain RE less than zero for NH AD1820 step. Which makes me wonder, what does Mann mean by
What numbers are you crunching? No-one is looking at the actually effect any of the issues really have. Where are the controls? You can ideally speculate all you want about how dramatic it will all be in the end, but absent someone demonstrating that it makes a real difference, there is nothing going on. Plus there are dozens of real reasons to expect TMIN to go up faster than TMAX – it does not imply UHI. Same with your other pop fingerprints
#45
There is a geospatial procedure called Gaussian unconditional Gaussian simulation (Wackernagel, 2003) which ought to be possible to extend to address the problem you describe.
I made this scripts operable with external references (as it had refs to files on my computer) and it’s been online at http://data.climateaudit.org/scripts/huybers for a couple of weeks now. I added some other calcs as well into the script. This is a cross-reference.
#60
Here’s a quick question. I’ve seen references to a repository for IMTRB (something like that) for the dendro crowd. But, does there exist, or is there even any push for, a centralized repository for scripts, data files, etc, for all climate scientists to use? It’s great that you make things available, but computers crash, go down, etc. It would be nice if the NSF or some other entity provided funding for a central repository, where one could search for articles, and download all relevant scripts, data, etc. At paper published with NSF funds would be required to provide all said data/scripts, etc., to such a repository. People make it out to sound so difficult, but it’s a simple task, storage is cheap, and it ought to be done.