We’ve had a couple of discussions of dealing with end-points for smoothing. Here’s a little note about smoothing algorithms, which I think is pretty funny. It’s hard to imagine a note about smoothing algorithms being funny, but see what you think.
We talked last summer about the pinned end-points in Emanuel 2005. Landsea 2005 had objected to this and Emanuel accepted the criticism. As it happened, Emanuel had somewhat of an out. He used a very short smooth (1,4,6,41) and the combined 2004-2005 seasons still left the short smoothing at very high levels.
On to 2007. Recently I discussed Mann’s “explanation” of the Divergence Problem, that it was an artifact of IPCC smoothing and, had they applied the “correct” method, set out, by coincidence, in Mann’s own article, the Divergence Problem would not exist. Re-capping, the poster had asked:
What we are interested in in this thread, however, are the error bars on the temperature reconstructions from proxies. What is striking from the IPCC chart is that the “instrumental record” starts diverging seriously upwards from the “proxies” around 1950, and is in the “10%” overlap range by about 1980. The simple read on this, surely, is that the proxies are not reflecting current temperatures (calibration period) and so cannot be relied upon as telling what past temperatures were either?
Here’s Mann’s answer again:
[Response: Actually, you have mis-interpreted the information provided because you have not considered the implications of the smoothing constraints that have been applied at the boundaries of the time series. I believe that the authors of the chapter used a smoothing constraint that forces the curves to approach the boundary with zero slope (the so-called ‘minimum slope’ constraint). At least, this is the what it is explicitly stated was done for the smoothing of all time series in the instrumental observations chapter (chapter 3) of the report. Quoting page 336 therein, This chapter uses the minimum slope’ constraint at the beginning and end of all time series, which effectively reflects the time series about the boundary. If there is a trend, it will be conservative in the sense that this method will underestimate the anomalies at the end. So the problem is that you are comparing two series, one which has an overly conservative boundary constraint applied at 1980 (where the proxy series terminate) tending to suppress the trend as the series approaches 1980, and another which has this same constraint applied far later (at 2005, where the instrumental series terminates). In the latter case, the bounday constraint is applied far enough after 1980 that is does not artificially suppress the trend near 1980. A better approach would have been to impose the constraint which minimizes the misfit of the smooth with respect to the raw series, which most likely would in this case have involved minimizing the 2nd derivative of the smooth as it approaches the terminal boundary, i.e. the so-called ‘minimum roughness’ constraint (see the discussion in this article). However, the IPCC chose to play things conservatively here, with the risk of course that the results would be mis-interpreted by some, as you have above. -mike]
[Response: Well, no, actually the proper read on this is that you should make sure to understand what boundary constraints have been used any time you are comparing two smoothed series near their terminal boundaries, especially when the terminal boundaries are not the same for the two different series being compared. -mike]
[Response: p.s. just a point of clarification: Do the above represent your views, or the views of Shell Oil in Houston Texas (the IP address from which your comment was submitted)? -mike] 😈
As I noted in the earlier post, Mann’s “minimum roughness” constraint, when translated from inflated Mannian language, boils down to a reflection of the series both horizontally and vertically around the final value. Mann:
Finally, to approximate the minimum roughness’ constraint, one pads the series with the values within one filter width of the boundary reflected about the time boundary, and reflected vertically (i.e., about the y’ axis) relative to the final value.
This implementation can be observed in some code here.
When I wrote a little routine to implement Mannomatic smoothing, I noticed something really funny. I know that it seems bizarre that there can be humor in smoothing algorithms, but hey, this is the Team. Think about what happens with the Mannomatic smooth: you reflect the series around the final value both horizontally and vertically. Accordingly with a symmetric filter (as these things tend to be), everything cancels out except the final value. The Mannomatic pins the series on the end-point exactly the same as Emanuel’s “incorrect” smoothing.
Just for fun, I applied the Mannomatic smooth with the short (1,4,6,4,1) filter to a hurricane series – category 3 days and obtained the following result, where I’ve emphasized the closing value to show that the Mannomatic smooth pins at exactly the closing value. It’s crazy, but it’s so. IPCC Chapter 3 Appendix 1 discusses smoothing algorithms drawing on Mann’s analysis, but doesn’t mention this.
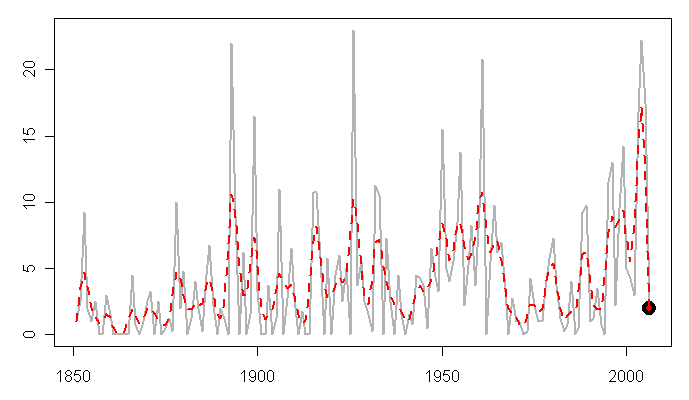





46 Comments
From a mathematical viewpoint, the boundary conditions constraining higher than first derivatives are unnatural because they don’t define a good boundary problem. There are only two boundary problems worth considering, Neumann and Dirichlet (and their linear combinations if you want to be really general).
Mann is inventing a new kind of mathematics that makes no sense. Another way to see that it makes no sense is to decompose the temperature data into Fourier series and ask what kind of components in the Fourier series are allowed. “sin” or “cos” are really the only two well-defined bases of functions on an interval. It’s not surprising that any attempt to define a new method has to lead either to the Neumann or the Dirichlet boundary conditions which indeed happened in this case, too.
It apparently ends up with small tragedies if a person who is really qualified to attack people because of their Texas IP address starts his own “revolutions” not only in statistics but also functional analysis. 😉
You’re right Steve. The humour is fairly obscure.
I wrote a paper on this issue and sent it to GRL a couple of years ago … but they didn’t like it. In it I pointed out that it pins the end points … no joy. I even wrote on this very blog last year that Mann’s method pins the endpoints … but nobody seemed to notice. I re-wrote the article and resubmitted it … GRL rejected it again.
Ah, well … keep up the good fight.
w.
You would get an even clearer illustration if you
a) also showed what happens if you truncate at the second last year
b) applied smoothing over more years
I’m no expert, but this business of setting various derivatives to zero looks to me like more of an aesthetic judgement than a mathematical one. Why would anyone expect any of the derivatives to be zero at the endpoints?
The way I would approach it is by looking at the data in the middle and regressing the smoothed value against the data neighbouring it on the left. That gives you the endpoint weights that best reproduce the symmetric smoothing in the middle.
In general, what you really ought to do is start with a statistical model for the data y(t) as the sum of a smooth trend function m(t) selected from some probability space and zero-mean errors e(t) (which may be autocorrelated) and then work out what weights give you the best estimate of the trend function from the data – linear regression being a good starting point. Estimating m(t0), you would expect only those y values close to t0 have significantly non-zero weights. Regressing m(t0) against y(t0+deltaT) for deltaT over some range around zero, you will get a set of weights which you can apply as a filter to smooth the data. The weights depend on the statistical model, and to come up with a smoothing scheme without discussing the model it fits seems very… informal… to me. (It’s fine for improving the visual appearance of a messy graph, but surely not for extracting trends?)
If you suppose the symmetric smoothing kernel (like the 1-4-6-4-1) you’re using in the middle of the data set is good, you can use this as your estimate of m(t) and regress against the data around it. If you regress against the whole window, you will of course just recover the smoothing kernel you used to generate it, but if you regress against only part of it, you’ll get an estimator that does the best it can to reproduce your smoothing method given the limited data at the endpoints.
Doing it this way might also give you a chance to calculate by how much the error bars increase at the ends. Since you have less data being input, you’re going to be less certain about your estimate. It would be very nice in an ideal world if the plotters of graphs could show that. If your method winds up using only the last point as the estimate of the smoothed value there, the increase in error is surely going to be rather large.
Like I said, I’m no expert, but that’s how I’d do it.
This is all way over my head, but I would like to know something from the data set you have shown; what happens if you pretend that your data set ended in 1980, you then you add “padding”, buth conventionally and via “Manning” and do a smoothed line to 2005? what does the line shape of the “padding” look like, compared to the ‘real’ data?
#3. Willis, sorry about that.
BTW, I don’t think that a whole lot turns on how things are smoothed in these particular networks as I mentioned in connection with Mann’s attempt to say that the Divergence Problem is merely a smoothing problem. In this case, I just thought is was amusing that Emanuel (of Mann and Emanuel 2006) thought that pinned end points were “wrong”, while Mann’s method did exactly that.
I’ve gotten into the habit if using gaussian smooths with mean padding, simply because that’s used so often in this field; but left to my own devices would probably use a function like lowess or less, which yield smoothed values right to the end points, but I haven’t investigated exactly how lowess/loess works. Again, I don’t think that it matters much.
Loess/Lowess are good – better than picking something like 1-4-6-4-1 out of a hat with no justification, anyway. Basically they assume the smooth function m(t) can be taken to be either linear or quadratic in a neighbourhood of given width around the point (which you use as the moving window to regress over), and that the errors in this range follow the usual Gauss-Markov type of assumptions for least-squares regression, (i.e. linear model, zero mean, constant finite variance, independent errors). This also supposes that least squares is a good optimisation to use. Strictly it is only optimal for a Gaussian error distribution.
You need to watch it if there are outliers from non-Gaussian heavy-tailed distributions, and (a favourite topic of yours, I believe) heavily autocorrelated errors like stationary ARMA processes. I believe you can correct for these using similar methods as for linear regression, but I don’t know the detailed implications. (Are high-frequency temperature variations uncorrelated and Gaussian?) However, like linear regression generally, you can often ignore some or all of these in exchange for a bit of non-optimality or slightly wider error margins than you expect.
Smoothing is basically a multivariate estimation problem. A lot of the machinery you’ve brought to bear in the past on the Team’s time series error estimations ought to be applicable here too, I’d guess. If all they’re doing is making their curves look nice, then fine, but if people are actually drawing conclusions from the details of these smoothed plots, one might want to check how much of that result comes from unstated assumptions.
There’s a paper by Niglio and Perna on “Kernel smoothing for the analysis of climatic data” you might be interested in too. They say that using one of the usual smoothing methods on autocorrelated data tends to under-smooth, and use climate data as a particular example. You might find their introductory exposition useful. I don’t think all of this is anything very significant either – just a lack of sophistication in some minor graphical output that isn’t that important anyway – but I’ll let you decide that for yourself.
why would one want to smooth this data? I can understand fitting
a MODEL ( with a physical basis ) to the data, but smoothing? To what end? IF you Want to make the data “appear”
more regular? stretch y, apply arbitrary transforms to y, apply arbitrary long window filters, with
arbitrary boundary conditions. ” ah today, we shall pad the series” Wait, “today we shall
truncate the series at the filter’s end” How wide a filter? 5 points, 10, 15?? And your reason for filter width would be….???
Would the time constant of the underlying physical system have anything to do with your selection
of filter width? Dunno. Sharper tools in the box will answer or straighten me out on that.
In real world engineering folks filter all the time. But they are trying to do something. Like control things.
Control a plane, control a car, land on the friggin moon. So,the test of a filter is… Did the plane
crash? did the car skid? did the lunar lander Land or make a divot ? Did the missile hit
the target? Thanks Mr Kalman, we like your filter. It allows us to hit the target. We know. we tested it.
and it has a nice physical basis, too.
Applying filters to reconstructions of climate, seems to me to be a rhetorical excercise.
Since the purpose of the filter is never really tested.
Without any physical basis for selecting the filter one is left with deciding what “looks appealing”
end point pinning has an appeal, a subliminal appeal that the most recent data should be given primacy.
Smoothing is done in order to highlight and quantify long term trends that would be hard to see if you only plotted the raw data out. They are based on the idea that the causal deterministic relationships they are interested in are all present in the low frequencies while the high frequency part is mostly ‘noise’. Therefore getting rid of the high frequencies gets rid of error disproportionately more than signal, and so improves data quality. I don’t know whether that is really true of climate or has been proved and the boundary located, but some people evidently think it is/has, and for their purposes smoothing is therefore a legitimate tool.
But whether the way they’re doing it is justified and correct is another matter. That people write papers about the best way to do it suggests they see it as a matter of some importance.
For those who are interested, here’s the paper about smoothing at the end of time series that GRL didn’t like …
Comments gladly accepted, I’d like to get it published someday.
w.
Just realized that some people may prefer PDF, so here’s the same smoothing document in PDF form.
w.
Just some toughts:
Isn’t it linear regression you want to do if you want to see the trend?
I could see a physical reason for a rectangular filter if “climatic temperature” was defined as the average temperature over a specific period, lets say 30 years. But then, you couldn’t talk about the “climatic temperature” for a specific year, but rather a specific period with some start and end year. And then there would be no end point problems. The climatic temperature for the period 1998-2028 is not yet a physical measureable entity. Of course we can speculate about it, but it is not measurable.
If you really want to reflect the last value in the rightmost point after smoothing, wouldn’t a casual filter like an exponential filter be the only sensible thing?
re 10 and 13.
SteveB. I get the point of filtering noise to see a long term trend. my eyeball does it.
without a calculator. ( see #13 ) We call that kentucky windage or dead reckoning.
One thing to note: we always EXPECT a trend. we expect a trend in every physical process over some period
of observation. The Odd thing would be No trend, no change. So, applying transformations to raw data
to highlight our expectations is just a form of confirmation bias. Without a physical basis,
lets say a theory, one is merely manipulating data. pocket pool for the mathematically reclined.
If I plotted the pimples on my ass versus time, I doubtless would find trends. I could corralate them with sunspots.
( ok sorry about that, sunspot fans)
And I get the point of the assumption that there may be low frequency signals that are swamped by
high freq noise. But that’s not a theory. That’s a data mining expidition. Without an underlying
physical model ( which could have low freq signals) this stuff looks like Bible code analysis to me.
So, Why filter the high freq? Because one assumes there is a low frequency signal? Why does one assume
there is a low frequency signal? does one report every FAILURE to find a low freq signal? or does one just
hunt around until you find one?
Now, to be clear, these questions don’t refute anything. The low freq signals may be there. When
someone explains the physical system that generates those signals, we will have understanding.
We will also be able to predict future tree rings and late wood density.
If I’m being too snotty, forgive me. Long day here.
Until then we have pretty graphs.
Here’s a stupid question. Why not smooth the thermometer data using the same smoothing algorithm used to smooth the proxy data and then compare the two smoothed series? Then it would be apples to apples.
That would be case were not so much emphasis being placed on the tail-end of these graphs.
Steve,
It is even worse than you say. As you say, the last point does not get smoothed at all. But also the last point exerts undue influence on the previous ones. For example with the (1,4,6,4,1) averaging, the averaging at the first inside point amounts to (1,4,5,6) – the 5 corresponds to the first inside point and the 6 to the last point. It gets even more ridiculous if you use a flatter filter. Consider for example (1,1,1,1,1,1,1) ie just averaging over 7 points. Then the filter at the first inside point is (1,1,1,1,0,3) and at the second point it is (1,1,0,0,5) – in this case the point we are averaging around gets no weight at all and the last point gets a huge weight! [To work these out, if the points leading up to the boundary are x2 x1 x0 then the Mannic padded points after the boundary are 2×0-x1, 2×0-x2,…]
The more I learn about this the more astonishing it gets. The guy who is supposedly one of the top experts in the field, widely quoted by the IPCC, is confused over how the graphs are produced and proposes a completely ridiculous smoothing method, showing himself to be more or less innumerate.
MannGRL04:
Probably Gelb’s figure
is based on unobjective statistical smoothing approach, see how uncertainties grow near the endpoints. Unlike in MannJones03, which is mentioned in MannGRL04:
Source: Gelb (1974), Applied Optimal Estimation
RE: #5 – Indeed, what they are doing is creating a very high d(dx/dt)/dt value in most cases, the only exception being where the actual derivative was close to zero at the data point nearest the end point. Possible but not common. Whereas, the right thing to do would be to examine some set of n data points near the end point. look at the d(dx/dt)/dt of the intervals between the points, and assign say a mean of them to the interval between the nearest point and the end point. In the grand scheme of things, you’d have a lower error.
From a mathematical viewpoint, what you say is only strictly true for second order systems and the climate system is not a second order system. Higher order systems naturally require constraints on higher than first derivatives for existence and uniqueness. For an example in Benard convection see:
E.H. Twizell and A. Boutayeb, Numerical methods for the solution of special and general sixth-order boundary-value problems, with application to Benard Layer eigenvalue problems, Proc. R. Soc. Lond. A 431 (1990), pp. 433-450.
Since the title of the thread ostensible involves smoothing, a few words about spline smoothing are in order. B-splines are a local basis functions which implies that their values on the interior of the fit are relatively robust to the data and boundary conditions at the end-points. They are solutions to a minimization problem and this minimization problem may be justified by Bayesian arguments when the data are associated with certain priors. The climate data may not be consistent with these priors, and autocorrelated errors complicates analysis, but these issues are generally not insurmountable.
In application to empirical data fitting, natural B-spline fits impose constraints on higher order derivatives at the boundaries. Cubic B-spline smoothing with natural boundary conditions imposes $latex $f”(0)=0$ $ and $latex $f”(1)=0$ $ on the interval [0,1]. Higher order splines force conditions on higher order derivatives. Usually the smoothing parameter (and perhaps the spline order) is/are chosen to minimize the Kullback-Leibler information loss between the data and the fit.
Here might agree.
Again, I respectfully disagree.
Looks like my attempt at tex failed
f8821;(0)=0 should be f”(0)=0
f8821;(1)=0 should be f”(1)=0
cheers,
— Pete
Steve M., loess and lowess both treat end conditions the same way. The total weighting and the width of the filter remain the same, but the peak in the filter gradually shifts toward the end of the data as the end approaches. In other words, the peak remains under the point being averaged, but it shifts from the middle to the end as the end of the data approaches.
The method I use (a standard Gaussian filter, with the resulting average value increased in size by the amount of missing data) is better at estimating the final position of the average, as I showed in my paper cited above.
w.
Dear Pete #20,
the temperature curve are much more chaotic and in the very short-term they resemble Brownian motion, with a possibly different exponent. That implies that the derivative doesn’t really exist. The more derivatives you take, the sicker result you get.
I agree that my conclusion about the boundary conditions applies to second order systems but the climate makes the higher derivatives even worse, not better. Do you disagree? Of course, smoothed versions of graphs may have all kinds of derivatives, but then the constraints on the derivatives don’t mean natural manipulation with data but rather a universal prescription of the whole curve at the endpoint which is clearly unphysical.
Best wishes
Lubos
But Lobos this wasn’t your original argument in #1. I objected to your two claims that (1) Neumann and Dirichlet are ‘the only two boundary problems worth considering.’ (2) ‘”sin” or “cos” are really the only two well-defined bases of functions on an interval.’ Neither claim is correct and the second isn’t correct for second order systems.
Now you’ve changed the argument and raise the spectre of a fractional ARIMA(p,d,q) process? You say “the temperature curve are much more chaotic.” More chaotic than what?
The temperature data is non-stationary so this raises the question of how you established this “more chaotic.”
Did you differentiate the time series (perhaps several times) to obtain a stationary one?
Did you subtract a smooth (differentiable) background?
These are two reasonable approaches for removing long term trends and seasonal variations so that you can study the stochastic behavior of residuals and perhaps fit a fractional ARIMA model to the residuals.
Did you do something else? Can you describe your methodology?
What is the continuity of the underlying physical process? C^0? C^1? C^2? How did you establish this?
Certainly we can differentiate up to the continuity of the underlying process and beyond that derivatives are undefined not “worse.” B-splines of degree p have continuity C^(2*p-1) which means linear B-splines are C^0 and only piecewise continuous.
The DFT of the data (descomposing the data into sines and cosines), as you suggested above will be differentiable, as by application of this method you have assumed that the data is band limited (sampling theorem). Nor are Neumann boundary conditions appropriate if the derivative “doesn’t exist.” So by now claiming “derivatives” don’t exist you have further undermined your original post in #1.
However, this whole argument is a bit of a red herring, you can separate the data into a smooth “background” and the residuals. The smooth background is differentiable but the total temperature isn’t. This is done all the time in theoretical physics. Plasma dispersion relations are based on this methodology, i.e., neglecting the discreteness of charge in favor of a smooth charge density.
Nope. As I pointed out in #20 B-splines aren’t global basis functions like polynomials so what you say doesn’t really apply and they won’t have “all kinds of derivatives” but rather differentiability consistent with minimizing the information loss between the B-spline fit and the data.
Have a look at this nice demo of B-spline interpolation. (i.e., not smoothing).
Keep in mind, I’m in no way defending what Mann has done. Indeed I would suggest that any inference based on empirical analysis that is sensitive to how the end-points are treated cannot be robust (Feynman would agree). So the whole nuanced approach to how to treat the end points is unnecessary…. use robust methods, rely on the conclusions that may be drawn from the interior data points, and wait for more data.
Regards,
— Pete
In this context, there are at least two meanings for ‘smoothing’, something related to making first derivative continuous or filtering-theory smoothing (non-causal filtering). In the former case you are correct, no other options to obtain apples-to-apples comparison for different decades. In the latter case, there will be no arguments about end-points, as they are handled well by the theory. Gelb’s figure in #18 refers to latter case. Not sure what Mann means, but he includes uncertainties to smoothed data, makes this interesting.
In this context, there are at least two meanings for ‘smoothing’, something related to making first derivative continuous or statistical-filtering-theory smoothing (non-causal filtering). In the former case you are absolutely correct, no other options to obtain apples-to-apples comparison for different decades. In the latter case, there will be no arguments about end-points, as they are handled well by the theory. Gelb’s figure in #18 refers to latter case. In MannJones03 and many other publications, smoothed data and original CIs are combined, which is very interesting from the theoretical point of view. Specially, along with statements like
Due to significant academic interest, I did some Monte Carlo simulations with MBH98 reconstruction + Mannian smoothing:
( Matlab Code )
Too bad that AR4 Uncertainty Guidance does not address this kind of issues. Seems that Fig 6.10.b reconstructions are in disagreement if one assumes uncorrelated noise.
#27. A Divergence Problem?
RE: #27 – based on that, there is a significant probability that it peaked during sometime around 1970. Is it a proxy for air pollution in North America, which also peaked around that time?
28,29
No answers, just some notes:
1) Mann’s minimum roughness constraint causes that divergence at the end-points. With minimum slope constraint, they’d agree more with each other near the end-points.
2) Spaghetti graph in AR4 Fig 6.10.b uses minimum slope, have you seen a spaghetti graph that uses minimum roughness?
3) In 6.10.b reconstructions agree in the calibration period, but diverge elsewhere. In the case of uncorrelated errors this wouldn’t happen.
4) With N year smoother, the end-point constraint selection affects N-1 most recent years. If 37 professors don’t like the 1940-65 decline, it is easy to smooth out. On the other hand, MBH99 smooth exaggerates that decline.
The reason Mann uses minimum roughness is that it pins the end of the spag graph to the highest point of a rising trend. Looks like another way to enhance the hockey stick.
Correction in 24:
“B-splines of degree p have continuity C^(2*p-1)” should be “B-splines of degree d=2*p-1 have continuity C^(2*p-2)” (p is the “half order” with p=1, d=1, C^0, corresponding to linear B-splines)
Hi UC,
I’m a bit confused here by terminology. Anyhow, B-splines are non-causal (the latter case) since data at past and future times are used to estimate local values, but they penalize the pth derivative corresponding to something like what you describe as the former case. For natural B-splines, the pth derivative f^(p)(t)=0 at the end-points. One could choose something different I guess if one had a good reason. The only real argument is over which order (2*p) to use and the roughness parameter. Both arguments are resolvable with information theoretic measures.
So I agree. No arguments in the “latter” case and one can resolve approximate ties with model averaging. I’m not sure what the “former” case is so I can’t comment. As a general principle, I think that if one perturbs the boundary values a little and gets dramatically different results, the results aren’t robust.
I think Gelb’s figure makes good sense. The confidence intervals should grow as the smoothing approaches the endpoints; these smoothed values near the ends cannot be as reliable as the interior values.
I don’t know what an “unobjective statistical smoothing approach” is (Mann’s comment in #18). If I were a reviewer I would ask for clarification and require that established terminology (which this might be) be used. I had a look at the Mann 2004 GRL and that provides no extra information in regards to this comment. This paper ignores perhaps 40 years of progress on this problem.
#27 I’m not a Matlab guy, but I’ll ask a few naive questions to make sure I understand the main issues:
The uncertainty, i.e., the divergence between trajectories is larger near the endpoints? (in agreement with Gelb).
Why does Mann claim the residuals are white? This is an odd noise model for experimental data. There must be an obvious reason for this claim.
The Mann reconstruction is a (weighted) aggregate of several independent temperature series?
Pete, thanks for the interesting post
What I’m thinking here is that if boundary constraint is extremely sensitive to noise (as with Mann’s minimum roughness, #27), can it be robust ?
Remember, this is climate science. No interaction with mainstream statisticians (or signal processing guys, mathematicians.. ) is needed. If I were reviewer, MannLees96, MBH9x, MannJones03, would not have been published. Robustness of proxy-based climate field reconstruction methods has not been published, maybe science starts working..
And it is not the only one in this field that does that.
I don’t know what Mann reconstruction actually is. Steve, Jean S et al know more. I took MBH98 data for this example because it is well known here, main point was to show the effect of uncorrelated noise to Mann smoother. Secondary point was to show how well smoothed reconstructions would agree in the middle-points, if uncorrelated noise assumption holds for all those reconstructions of AR4 fig 6.10.b
Net of moving the pea under the thimble, the “Active ingredient” in the Mann reconstruction i.e. the data which gives it a hockey stick shape are the bristlecone pine ring width series, which have a growth pulse in the 20th century. Read our articles for a discussion of bristlecone pines, which no one believes to be a “temperature” series and even the NAS panel agreed should be “avoided” in temperature reconstructions.
Since the problems with Mann’s PC1 and bristlecones have been widely publicized, climate scientists, in a perverse show of solidarity with Mann, have actually increased their use of his PC1 and bristlecones, with his PC1 being used in Rutherford et al 2005, Osborn and Briffa 2006, Hegerl et al 2006, Juckes et al ??
Pete,
If you really want to get puzzled (or remove my confusion), consider this: In the calibration period, MBH98 reconstruction has smaller sample variance than reference temperature. Note that global temperature is clearly non-white sequence. Combined with white residuals, we have
where reconstruction is separated to true temperature T and uncorrelated (wrt time) noise sequence n. How can you add white sequence to a red sequence so that variance is reduced?
Easy. Do a multiple linear regression of a trend against one red noise series and 21 white noise series. See
http://www.climateaudit.org/?p=370 – go down to the bottom where I’ve excerpted a figure from Phillips 1998 showing the regression of a sine curve against white noise (Wiener processes). This post is worth reading as I thought then that it was one of my best.
Thks Steve, I’ll read it. Hmmm, someone told you to apply Variance Adjustment.. I’d take that as an personal insult.
#33.
We first encountered mention of this last summer in the review of Burger and Cubasch discussed at CA here. In July 2006, it was described as “accepted”.
In Mann’s EPSL article on line here
published online in December 2006, it is cited as Mann ME, Rutherford S, Wahl E, Ammann C. 2006a. Robustness of proxy-based climate field reconstruction methods. J. Geophys. Res. In press. HEre JGR is identified.
In Mann’s current online CV , it is also said to be “in press” at JGR: Mann, M.E., Rutherford, S., Wahl, E., Ammann, C., Robustness of Proxy-Based Climate Field. Reconstruction Methods, J. Geophys. Res. (in press). Also at Ammann’s webpage here
At Wahl’s current online CV, it is said to be “in revision” at JGR: Mann, Michael.E., Rutherford, Scott., Wahl, Eugene, and Ammann, Caspar, in revision, “Robustness of Proxy-Based Climate Field Reconstruction Methods”, Journal of Geophysical Research.
I looked at the acceptance dates for current JGR published articles: they are all Feb-Mar 2007; I didn’t notice any aticles coming out of inventory that were accepted in July 2006 (or even December 2006). Odd. But then Mann said that he didn’t calculate the verification r2 statistic.
It’s now out, enjoy 😉
Mann, M. E., S. Rutherford, E. Wahl, and C. Ammann (2007), Robustness of proxy-based climate field reconstruction methods, J. Geophys. Res., 112, D12109, doi:10.1029/2006JD008272. (Free copy from Mann’s web page)
If I may raise a non-statistical (ethical) issue on this old thread: Mann has claimed that the Wahl/Ammann (“Jesus Paper”) was some kind of “independent” vindication of his work, yet it is clear that in 2006-07 Mann was including Wahl and Ammann in co-authorship on this work which Jean S links above.
So not only are Wahl & Ammann not “independent” of Mann in any plausible sense but they are getting the professional credit from Mann including them on another paper’s co-authorship in the same time period.
Talk about ethically conflicted! In light of Mann’s upcoming talk for a Stephen Schneider memorial lecture at Stanford, it might be an ideal time for someone able to write up a critical review of the Mann-Wahl-Ammann and Schneider saga. Not trying to add to Steve’s load, really, maybe someone at WUWT or BH could take this on….. it might get attention at Stanford in time for Mann’s talk in a few weeks.
sorry, it’s Gore not Mann who is soon to give the Schneider memorial lecture at Stanford…. I was mixing up the climate clowns for a moment.
Like Mann, I’m not a statistician, but I have done some spline curve smoothing and more recently some Kalman filtering/smoothing. When I first read Mann (2004), his double flipping of the series to pick up the terminal trend seemed ad hoc but reasonable. I was, however, puzzled by why the method goes nuts on the Cold Season mean NAO series (his Figure 2), even though it looks good in his Figure 1 (CRU annual mean NH temps).
However, Steve and Willis are of course right that the method simply picks up the last observation, wherever it may be. In Mann’s Figure 1, the last point is kind of on trend, so the “minimum roughness smoother” looks reasonable. In his Figure 2, it’s an isolated positive uptick, forcing the “trend” up as well. Note, however, that Mann’s blue and red lines do not quite coincide for some reason at the ends. This makes the mathematical equivalence less noticeable.
There’s nothing intrinsically wrong with extrapolating a terminal trend. In fact, I now do this in my interest rate term structure estimations, by imposing a “natural” (ie 0 second derivative) restriction on the long end of my cubic spline log discount functions. (See my Real Term Structure” webpage .) However, it should be recognized that this adds an extra element of uncertainty to the fit, especially at the end(s).
Mann’s method is all wrong. A far better, yet simple, method of fitting a terminal trend would be the following: Take a say 21 year centered moving average, up until time t = n-10. For t > n-10, use data points t-10 through n to fit a straight line, and then evaluate the line at t. The standard errors of these fits, properly computed, will of course fan out as t = n is approached, but given the serial correlation it’s complicated to do this correctly. An easier and less technical way to show that there is more uncertainty would simply be to plot the last 10 (or whatever the half band width is) points that depend on the padding or extrapolation in the same color, but with a dotted line. (Larry Huldf, #45 on the earlier thread, wanted to use a different color, but there are plenty of colors on these spaghetti graphs already!).
Of course, any statistical analysis should go back to the raw data rather than using these “non-causal” smoother estimates.
BTW, can anyone tell me what IPCC would mean by a “Gaussian-weighted filter to remove fluctuations on time scale less than 30 years”? (Caption to Figure 6.10 of AR4 WGI) A Gaussian filter (as defined on Wikipedia) has infinite support, and so would have to be truncated somewhere. At 3 sd? Why not 2 or 4? Also, where does the 30 come in? Is this the sd? Or is it two sds? Or maybe the interquartile range? I notice Steve occasionally does “41 point” Gaussian filters. What does this mean?
Thanks!
— Hu McCulloch
Econ Dept.
Ohio State U.
mcculloch.2@osu.edu
#40. This is a smoothing technique used in tree ring studies that has been carried over into proxy studies. Here are my implementations (I use them for consistency with practice). For end points, I usually pad with the mean value, one of several practices. For the things that I’m doing, nothing much usually turns on the precise form of smoothing.
##gaussian.filter.weights
gaussian.filter.weights< -function(N,year) {
#N number of points; year – is number of years
sigma<-year/6
i<-( (-(N-1)/2):((N-1)/2) ) /sigma
w<- ((2*pi)^-0.5) * exp(-0.5* i^2)
gaussian.filter.weights<-w/sum(w)
gaussian.filter.weights
}
##truncated.gauss.weights
truncated.gauss.weights<-function(year) {
a<-gaussian.filter.weights(2*year+1,year)
temp0.05*max(a))
a<-a[temp]
a<-a/sum(a)
truncated.gauss.weights<-a
truncated.gauss.weights
}
#GAUSSIAN FILTER
#The appropriate Gaussian distribution therefore has standard deviation
# s = ? / 6,
# where ? is the desired wavelength at which the amplitude of frequency response is 0.5. The
# filter weights are obtained by sampling the pdf of the standard normal distribution at
# values i/s where i={-(N-1)/s, …, 0, .. (N-1)/s }
# MEKo has values to verify for case of N=21, year=10 #this is verified
#see http://www.ltrr.arizona.edu/~dmeko/notes_8.pdf
Steve —
Thanks for the clarification on the Gaussian filter!
Although IPCC AR4 WGI Chapter 6 generally uses a Gaussian filter, it’s curious that Mann (2004) instead uses the relatively arcane Butterworth filter. This is an electronic filter that has a very flat passband and a monotonic (albeit slow) stopband rolloff. With infinite order, it becomes an ideal “brickwall” lowpass filter, but since all realizeable circuits have some resistances that makes them non-ideal, electrial engineers have to settle for imperfect filters like the Butterworth. The likewise imperfect Chebyschev filter is generally preferred, since it has faster rolloff at the expense of some passband ripple. (See Wikipedia)
However, computer filtering of data is not subject to the same contraints as electrical engineering, and so one could just as well use the ideal filter, which in continuous time is the cardinal sine function sinc(x) = sin(x)/x, appropriately scaled and normalized. In unbounded discrete time there is presumably a discrete version of this. In bounded discrete time, one could simply truncate the weights at the boundaries and renormalize, reflect the data at the boundaries until the weights are imperceptible, or (more ambitiously) recompute optimal weights that kill, in expectation, an equally spaced set of frequencies out to the Nyquist frequency, taking the expectation over the random initial phase of the signal.
But if a precise bandwidth isn’t crucial, one could just use Gaussian, binomial, Kalman, or even plain old equal weights. Mann’s Butterworth filter serves no apparent purpose in this context whatsoever, other than to dazzle the rubes with some high-tech but inappropriate apparatus.
IPCC’s Chapter 3 Apprendix 3.A states that Chapter 3, if not Chapter 6, uses either the 5-weight filter (1/12)[1,3,4,3,1], or a likewise integer-based 13 weight filter. It’s not clear where these come from, since they are not quite binomial, but at least the short one does have the attenuations it claims, making it a clever way to achieve an almost 10-year half power bandwidth with only 5 points! They say the long one has a response function similar to the 21-term binomial filter used in TAR, despite using only 13 points.
— Hu McCulloch
Econ Dept.
Ohio State U.
mcculloch.2@osu.edu
Steve: Once more, congratulations and thank you. I expect both sides will agree that the increased openness facilitates science.
Hansens statement
allows for cherry picking as well as for defect rejection. It will be interesting to see what the impact was.
I dug this old mannimatic thread up today after seeing the call in the climate audit utilities filter. I happened to be using data for a convolution filter test and found that the mannimatic gave my data an enzyte smile. It was pretty lucky as the fake data could have gone either way.
So there I am, years after this post laughing at a computer screen. My wife thinks I’m nuts. 20 hours later, I find this post.
haha.
5 Trackbacks
[…] the trend line to the final end point of the series has been noted in a post “Mannomatic Smoothing and Pinned End-points” at ClimateAudit. The comparison of MRC and non-MRC padded series is shown in figures […]
[…] series is to ensure a smooth trend line until the end of the series. But, as was noted in “Mannomatic Smoothing and Pinned End-points” MRC causes the trend line to pass through the value of the final point of the series (the […]
[…] S writes: #99: It’s been already a while Supplementary info is available […]
[…] a year later, in 2007 Steve McIntyre posted a piece called “Mannomatic Smoothing and Pinned End-points“. In that post, he also discussed the end point […]
[…] “Mannomatic Smoothing and Pinned End-points“ or how to fiddle your data scroll down to Dr Michael Mann – Smooth Operator. […]