I’ve already received my first condescending comments from the dendro world about the mysteries of standardization. Just to pre-empt some further pontification presuming that I know nothing about these mysteries, I’m posting up some notes that I wrote in 2004 on standardization – which was what I would have been working on had people just accepted the defects in the Mannian multiproxy articles at the time. I hadn’t looked at these comments in a couple of years, but they are interesting and well worth publishing as they are quite original.
Many “standardization” operations carried out in dendrochronology can be interpreted using nonlinear mixed effects methods (implemented here in the nlme package of Pinheiro and Bates). RCS standardization can be interpreted using the nls function, while “conservative” standardization (negative exponential “COFECHA option 2) can be interpreted using the nlsList function. Given this equivalency, there are many advantages to interpreting dendrochronological standardization in a mixed effects context as dendrochronological standardization can then be integrated into a broader statistical context, rather than simply being a rather ad hoc collection of techniques, as it is presently. There are many diagnostic tools available in nlme that are unavailable in standard dendrochronology application packages. Interestingly, while dendrochronologists are well aware of both RCS and “conservative’ methods, one sees exactly the same pulls in nonlinear mixed effects modeling, where the nlme function effects a form of compromise between nls and nlsList functions. (For nlme users, this parallels the identical compromise that the lme function achieves between the lm and lmList functions.) I’ve been able to accurately emulate site chronologies using nlme methods. By utilizing the tools within the nlme package, new diagnostics and analyses can be produced, illuminating the results. [I have not yet considered spline modeling from a mixed effects framework, but it should be possible.]
Conversely, dendrochronology brings an extraordinarily rich collection of data, which somehow has eluded the mixed effects statistical community, but which integrates many of the issues that interest mixed effects statisticians. Longitudinal data sets used in mixed effects modeling are often very small and short in comparison with tree ring collections, where one can have data sets for individual sites with over 100,000 measurements.
The application of mixed effects techniques is very natural. Tree ring data is already grouped into cores from individual trees, which have pronounced individual differences between trees that are suited to mixed effects modeling. Growth is affected by aging, usually modeled through a generalized exponential. Individual cores usually have pronounced serial correlation and heteroskedasticity. Growth is also affected by annual climatic factors (and, indeed, the measurement of this effect is the primary goal of dendrochronology).
By applying a more general statistical methodology, there is the prospect that the analysis and allocation of growth among age effects, climatic effects and individual effects under the simple nls and nlsList modeling of dendrochronology can be placed in a broader context and perhaps some new results obtained.
1. ARSTAN settings for “conservative” standardization
As an example, I consider here the cana036 data set from Gaspé, which was of specific interest to McIntyre and McKitrick [2005], as it was one of the two strongest contributors to the AD1400 hockey-stick in Mann et al (1998). The cores were collected in the early 1980s by Edward Cook. The ring width measurements for 29 cores (19 trees) are archived at WDCP as cana036.rwl and the site chronology is archived as cana036.crn. By coincidence, Cook is also the originator of the computer program ARSTAN, which, together with its various offspring, is used to develop most site chronologies.
Archived information at WDCP does not typically specify the exact methods used to make the site chronology. However, in this case, I achieved a good replication of cana036.crn using ARSTAN on cana036.rwl with the following options from the ARSTAN menu: Detrending #2; L=2 (negative exponential, linear regression with negative slope or line through mean); no negative asymptote; no double detrending.
The mean of the ARSTAN chronology was 980 (while the mean of the archived chronology was 1000). Adjusting for the difference in means, the ARSTAN chronology was nearly always within 0.1% of the archived chronology and always within 2%, with the largest differences in the early portion where there are only 1-2 trees (See Figure 1 below). Thus, it can be confidently asserted that cana036.crn was calculated using options extremely close to these ARSTAN options and that this can be used as an example of “conservative” standardization.
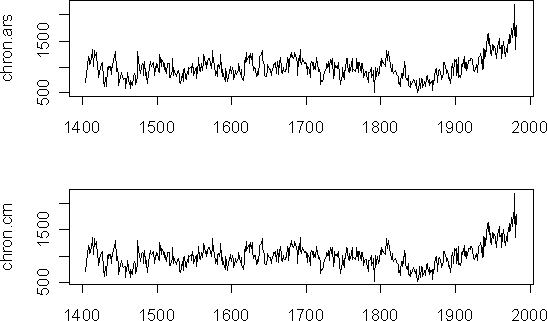
Figure 1. cana036.crn. Top: ARSTAN chronology; bottom: archived chronology at WDCP.
2. Replicating ARSTAN Option 2 with nlsList
ARSTAN produces file of coefficients (*.coe) for the individual fits of generalized exponentials or defaults to each of the 29 cores. In the benchmark run, ARSTAN modeling fitted 19 generalized exponentials and defaulted to 9 lines through mean and 1 negatively-sloped linear regression. These coefficients are shown in Appendix 1 columns 1- x (Word document).
I emulated the ARSTAN calculations under the R package nlme as follows (see script mixed.effects/mixed.effects.1.txt.) I first converted the dataset cana036 into an R data frame tree with columns id, year, age and rw (ring width). The id here is a composite of codes for site, tree and core: typically the site id is 3 characters, tree id is 2 characters and core id is one character. The core and tree id were unpacked as follows:
tree$core< -substr(as.character(tree$id),5,5)
tree$tree<-substr(as.character(tree$id),3,4)
Ring widths of 0 were changed to ring widths of 1 for use of logarithms. A factor for years was calculated for use in later calculations.
The data frame tree was in turn converted to a groupedData object Gasp” with a nested structure.
Gasp'< -groupedData(rw~age|id/core,data=tree)
Mean values for each core were associated with each data point (for use in later calculations) as follows. The tapply function takes a mean over a ragged array, while the next step reverts a factor back to numerical values.
Gasp’$mean< -Gasp'$id
levels(Gasp'$mean)<-tapply(Gasp'$rw,Gasp'$id,mean)
Gasp'$mean<-as.numeric(levels(Gasp'$mean))[Gasp'$mean]
A negative exponential aging model was fit to the entire dataset using the nls function. Then a “chronology” was calculated by dividing each ring width by the value of the fitted nls function and converting the ratio to a time series, as shown below. This procedure emulates certain RCS methods.
fm1.Gaspe.nls< – nls(rw~A+B*exp(-C*age),start=list(A=mean(Gasp'$rw),B=25,C=.01),data=Gaspe,trace=TRUE)
E<-coef(fm1.Gaspe.nls)
In this case, the coefficients E were A= 26.55, B=19.96 and C= 0.01555, representing an asymptotic ring width of 26.5 mm/10 and a juvenile growth effect of 19.96 mm/10 with a decay scale of 1/.01555 = 64 years. The correlation of the resulting chronology to the archived chronology was 0.965.
A site chronology from the nls model was calculated by first treating each year as a factor (as understood in R and S) and then taking the mean of the ring width to the fitted values as in dendrochronological standardization as a time series. These operations are shown below:
yearf< -factor(Gaspe$year)
chron.nls<-ts( tapply(Gaspe$rw/fitted(fm1.Gaspe.nls),Gaspe$yearf,mean), start=min (Gaspe$year), end=max(Gaspe$year))
Secondly, a “conservative” standardization procedure was emulated using the nlsList function with default iteration settings, using the nls coefficients determined above as starting values, as follows:
fm1.Gaspe.lis< -nlsList(rw~A+B*exp(-C*age),start=list(A=E[1],B=E[2],C=E[3]),data=Gaspe)
Table 1 below compares the values from this replication procedures to the ARSTAN results. In 21 of 27 cases, both methods achieve similar results, with exact replication of coefficients in 16 of 27 cases (indicating that the method is being modeled accurately.) In 7 cases, one or the other method converged (but not both), indicating the sensitivity of the method to convergence parameters. Finally, there appears to be a numerical error in ARSTAN in the calculation of the coefficients for the first series. The reason is very unclear, but the anomaly is consistent.
| Both have convergent neg exponential with exact replication | 16 |
| Both have convergent neg exponential, but ARSTAN coefficients are inaccurate | 1 |
| Neither converge (ARSTAN line through mean) | 5 |
| nlsList convergence (but not in ARSTAN) | 5 |
| ARSTAN convergence (but not nlsList) | 2 |
| TOTAL |
By changing the convergence parameters, increasing the maximum number of iterations to 500 (default-50) and increasing the tolerance at 1e-03 (default 1e-05), the number of non-convergent series was reduced from 7 to 1, as below. It seems that ARSTAN gives up too early, even though there is a possible convergence.
fm2.Gaspe.lis< -nlsList( rw~A+B*exp(-C*age) , start=list(A=E[1],B=E[2],C=E[3]),data=Gaspe, nls.control(maxiter=1000,tol=1e-03,minFactor=1e-8))
The ring width series for the nonconvergent series is shown below.
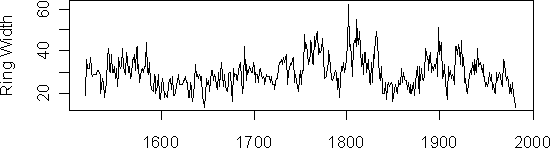
Figure 2. Nonconvergent series 93151.
Experimenting with different starting points resulted in different convergence failures, although no inconsistent convergences were observed. In a run with a different starting point, convergence for the above series was obtained with coefficients of A=29.6; B=0.76 and C=0.0443, resulting in a fit only slightly different than setting the mean to A=29.63. Combining results from different starting points yielded convergences for all series, although there were two cores with negative juvenile growth coefficients and one with negative asymptotic growth.
This numerical quirkiness clearly affects convergence in ARSTAN, where the slightly different convergence from the first nlsList fit undoubtedly a different starting value. The nls control parameters (number of iterations, minimum step, tolerance) in ARSTAN are probably close to the nlsList default settings. There is little practical effect for site chronology as the juvenile effect modeled through the generalized exponential is minimal in each of the cases in which convergence is slow.
An emulation of the construction of a site chronology is readily accomplished by substituting mean values (previously calculated) for missing values in the fitted model and then repeating the method used in the nls example, as follows:
fit.fm1.Gaspe.lis< -fitted(fm1.Gaspe.lis)
temp<-is.na(fit.fm1.Gaspe.lis); sum(temp) #2584
fit.fm1.Gaspe.lis[temp]<-Gaspe$mean[temp]
chron.fm1.lis<-ts( tapply(Gaspe$rw/fit.fm1.Gaspe.lis,Gaspe$yearf,mean), start=min (Gaspe$year), end=max(Gaspe$year))
The correlation to the archived version was very high (0.987). The resulting series is shown in Figure 3 below and closely replicates the ARSTAN chronology.
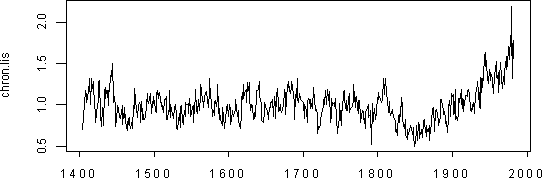
Figure 3. Site chronology from nlsList model.
An alternative method of implementing the same approach without keeping the mean calculations in the dataset is as follows:
fit.fm1.Gaspe.lmlis< -lmList(rw~1,data=Gaspe)
temp<-is.na(fit.fm1.Gaspe.lis); sum(temp) #2584
fit.fm1.Gaspe.lis[temp]<- fit.fm1.Gaspe.lmlis[temp]
This is an extremely simple example of lmList, where the fixed effect is the grand mean, while the random effect for each core is the difference between the grand mean and the mean for each core. This model is itself one of the ARSTAN options.
The convergence issues in “conservative” standardization seem to differ significantly from site to site. In the Polar Urals site ring width data set, 51 of 93 cores did not converge. In this case, ARSTAN conservative standardization reverts to modeling with a mean. These non-convergence issues are circumvented in the Briffa chronology by using the equivalent of a very coarse nls model (RCS), but perhaps point to statistical issues that need consideration.
More on this tomorrow, where I’ll discuss RCS.
Update: Sept 28, 2009. While I promised in 2007 to discuss RCS “tomorrow”, I didn;t return to the topic. The following notes were in draft. I’m posting them up today, but haven’t checked them – there might be some reason why I didn’t finish the draft.
Having replicated “conservative” methods in a more general statistical framework, I’ll now turn to replicating RCS methods in a more general framework. Although RCS methods have become popular in recent years and their conclusions are widely applied in multiproxy studies (see use of Briffa’s Tornetrask and Polar Urals RCS reconstructions), relatively little information is available to verify the conclusions. To my knowledge, there are no archived data sets in which both the RCS chronology and the measurement data are available: it’s one or the other. [Note – Sept 2009: we know have benchmarks for Briffa et al 2008!]
In the estimation of starting values for the nlsList function used for the “conventional” chronology, an RCS calculation was done to obtain starting values as shown previously as follows:
fm1.Gaspe.nls< – nls(rw~A+B*exp(-C*age),start=list(A=mean(Gaspe$rw),B=25,C=.01),data=Gaspe,trace=TRUE)
coef(fm1.Gaspe.nls)
In this case, the nls coefficients were A= 26.55, B=19.96 and C= 0.01555, representing an asymptotic ring width of 26.5 mm/10 and a juvenile growth effect of 19.96 mm/10 with a decay scale of 1/.01555 = 64 years, as noted previously. An RCS chronology can be simply obtained from the residuals of the above calculation as follows:
chron.nls< -ts (tapply(Gaspe$rw/fitted(fm1.Gaspe.nls),yearf,mean), start=min(tree$year))
The plot of the RCS emulation is shown in Figure 4 below, which, in this case, does not differ much from the individually fitted chronology.
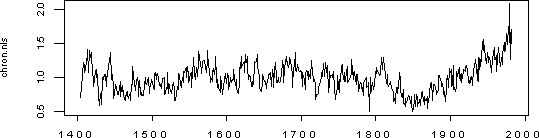
Figure 4. Chronology resulting from RCS emulation using nls function on cana036.
A simple lme example
If one inspects the coefficients in Appendix 2, listing the fitted coefficients from the negative exponential model, one is struck by the wide spread in coefficients, even between cores in different trees.
One of the underlying themes in lme and nlme modeling is the tension between over-fitting single series (nlsList, lmList) and not allowing for individual differences (nls, lm). The theory of lme and nlme models is to apply the information about all the individuals in modeling of each individual by regarding the coefficients of the model as being drawn from a regular distribution (usually normal).
I will illustrate this first using the simple model of means used to supplement the negative exponential fits.
This can be called from the previously calculated lmList model:
fit.fm1.Gaspe.lmlis< -lmList(rw~1,data=Gaspe)
plot(fit.fm1.Gaspe.lmlis)
fm1.Gaspe.lme<-lme(fm1.Gaspe.lmlis)
Update: May 2012: Here are some notes from a couple of years ago, using a style unavailable when I first looked at this. The approach set out here gives somewhat different looking chronologies but seems like a better statistical approach. It’s interesting that chronologies can be generated in a couple of lines from totally unrelated methodology. I have quite a few experiments on this.
##############################
# GET RWL AND CRN DATA
###########################
#chronology
download.file("http://www.climateaudit.info/data/tree/cana036.crn.tab","temp.dat",mode="wb");load("temp.dat");
gaspe.crn=chron.crn;tsp(chron.crn) #1404 1982
#measurement data
download.file("http://www.climateaudit.info/data/tree/cana036.rwl.tab","temp.dat",mode="wb");
load("temp.dat");
dim(tree) #40892 4
tree$tree=factor( substr(as.character(tree$id),1,4) )
tree$TC=with(tree,tree:id)[drop=TRUE] #nest core within tree
#this isn't used today but for reference
tree$yearf<-factor(tree$year) # set up for lmer by making year a factor
info=info.gaspe=make.info(tree)
order1=order(info$end)
############################
# do lmer chronology without nesting
############################################
fm=fm.lmer= lmer(rw~ exp(-age)+(1|id)+(1|yearf),data=tree)#works
chron.lmer= ts(ranef(fm.lmer)$yearf,start=min(tree$year) );tsp(chron.lmer)
plot.ts(chron.lmer)
################
#pseudo-RCS
##################
fm=fm.lmer.rcs= update(fm.lmer, rw~exp(-age)+(1|yearf) )
anova(fm.lmer.rcs,fm.lmer0)
#fm.lmer.rcs 4 93466 93495 -46729
#fm.lmer0 5 91065 91102 -45528 2402.3 1 < 2.2e-16 ***
chron.lmer.rcs= ts(ranef(fm.lmer.rcs)$yearf,start=min(tree$year) )
plot.ts(chron.lmer.rcs)
rcs.gaspe=RCS.chronology(tree,method="nls") #"standard"
#png("d:/climate/images/2012/proxy/gaspe_chronologies.png",w=720,h=720)
nf=layout(array(1:2,dim=c(2,1)),heights=c(1.1,1.3) )
par(mar=c(0,4,2,1))
year=c(time(gaspe.crn))
plot(year,scale(gaspe.crn),type="l",xlab="",ylab="",axes=FALSE,col="green4")
axis(side=1,labels=FALSE);axis(side=2,las=1);box();abline(h=0,lty=3)
title("1. Gaspe Chronology")
lines( year,scale(rcs.gaspe$series),col=1,lty=1)
legend("topleft",fill=c("green4","black"),legend=c("ITRDB","RCS"),cex=.8)
par(mar=c(3,4,0,1))
plot(year,scale(chron.lmer),type="l",xlab="",ylab="",axes=FALSE,col=2) #,ylim=c(-.8,.8))
axis(side=1);axis(side=2,las=1);box();abline(h=0,lty=3)
lines( year,scale(rcs.gaspe$series),col=1,lty=1)
legend("topleft",fill=c("red","black"),legend=c("LMER","RCS"),cex=.8)
#dev.off()
Here’s a plot comparing versions.






One Trackback
[…] described in the past as artisan statistics) into a statistical framework: tree ring chronologies here and Hansen’s “reference” method here. Let me start with a very standard boxplot […]