I’d like to finish off our discussion of the supposed “strong visible anticorrelation” between the Q5 (Oman) and D1 (Socotra) speleothems (as supposedly evidenced in Figure 9), before discussing millennial issues. Again, I preface these remarks by saying that there is much of interest in speleothems and I’m just discussing one statistical issue here that happened to catch my eye.
As noted before, although I have no wonderful recipes for testing correlation of irregularly sampled series with dating errors, we’ve already seen that, if the Q5 dates were brought about 75 years closer to the present, the sign changed from inverse to positive and the positive correlation was noticeable more “significant” than the weak inverse correlation (correlations being calculated on data interpolated to an annual basis.)
In the 2700-4700BP overlap section under discussion, there were multiple date points for each series. If errors in these date points were independent, then the case for a relatively “stiff” displacement of one series relative to another would be pretty strained; however, it there were something in the method of estimating date that biased one core relative to another, then a relatively “stiff” displacement of Qunf Q5 with respect to Socotra D1 would be a definite possibility.
This led us to examine the dating methods for speleothems – and dating methods are something that interest me. Speleothems are dated using U-Th dating, an interesting technique. Edwards 1987 is a seminal article and I was able to more or less replicate their calculations. U-Th dating calculations work best when there is no native Th in the system – something that is substantially true for the corals that Edwards 1987 was concerned with. As the technique gets extended to other types of data e.g. speleothems, adjustments for Th-230 not arising from the U-238 system needed to be developed.
The Th-232 levels in Q5 are about an order of magnitude higher than in D1. Intuitively, this seems like the sort of place that one would look for potential uncertainties in the calculation that might permit a systemic difference of 75 years. Fleitmann et al 2007 note Th issues and describe their methodology as follows:
In some cases, detritus corrections were needed when 230Th/232Th ratios were high (see Table 1). If necessary, ages were corrected assuming a 232Th/234U ratio of 3.8 (see Frank et al., 2000 for details).
With due respect to Dr Fleitmann, this sort of verbal description occurs all too often in paleoclimate methodology descriptions and shows one more time the benefit of including source code in an SI. What is the benchmark for triggering a “detritus” correction? Why do this for “some” cases and not “all” cases? Issues like this would be instantly clarified by consulting code; in the absence of code, one has to try to guess what the authors did, a pointless and time-consuming exercise, which is one reason why calculations are so seldom verified.
Turning to Frank et al 2000 (online here.) merely compounds the replication problems. Frank et al 2000 nowhere mentions a “232Th/234U ratio of 3.8” so one has to guess.
Frank et al 2000
In addition, Frank et al 2000 is also a practical article on German travertines, where the methodological issue of adjustments is mentioned in passing in an appendix, without providing clear benchmark information to enable one to readily ensure that one is doing the calculations apples-and-apples.
Stepping back for a moment from annoying dating techniques, Frank et al describe interesting geological evidence of the warm period about 110,000 years that was the interglacial prior to the present Holocene. The warmth permitted the growth of travertine around Bad Cannstatt, Germany. Travertine formation ceased during glacial periods and resumed only in the Holocene. U-Th dating is a technique that permits independent dating of the travertine deposits to this period. Frank reported a date of ~105,000 for the laminar Biedermann travertine (which also had leaf imprints of oak, ash, poplar and Mediterranean honeysuckle trees) and several thousand years later (~98-101,000) for the laminar Deckerstrasse travertine.
Frank et al (note to Table 1) report the use of the following equation with Th232-corrected values (and the same decay constants as Edwards 1987):

With a bit of experimenting, this proves to be equivalent to the corresponding equation in Edwards 1987 (multiplied by [U238/U234]_act ).
The Th adjustment deducts an allowance for non-U238-sourced Th-230 using the following equation (Appendix):

This adjustment requires two empirical constants: 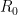

I’ve tried pretty hard to replicate the results in Frank et al 2000 and have got close, but can’t quite replicate them. Without being able to do so, it’s impossible to test the Th-adjustments in Fleitmann et al 2007. For what it’s worth, here is my attempt to replicate the calculations of Frank et al 2000:
First, here are the constants collated from various locations in the paper:
lambda=NULL; lambda[“Th230”]= 9.195E-6#Table 1 Frank
lambda[“U234”]= 2.835E-6 # Table 1
lambda[“U238”]= 1.551E-10 #Table1
R0=1.85;Rd=.526
Next here is the information in Frank Table 1, collated by cut and pasting from the pdf into Notepad and tidying:
A=read.table(“http://data.climateaudit.org/data/speleothem/Frank.2000.edited.dat”,sep=”\t”,header=TRUE)
Next here is an implementation of the function in Frank et al 2000, combining the equation in the note to Table 1 (the one that corresponds to Edwards 1987 Equation 1) and the Th-adjustment equation in the Appendix.
f=function(t) {
X=act.Th230_U234-act.Th232*(R0-Rd)*exp(-lambda[“Th230”]*t)-act.Th232*Rd #equation A1
B=act.U238_U234* (1-exp(-lambda[“Th230”]*t) )
C= (1- act.U238_U234)* lambda[“Th230”]/(lambda[“Th230”]-lambda[“U234”])
D= (1- exp( -(lambda[“Th230”]-lambda[“U234”])*t) )
f= (X- (B+ C*D) )^2
f}
Now I solved the non-linear equation for each set of measurements, setting non-converging to NA:
K=nrow(A); age=rep(NA,K)
for(i in 1:K) {
act.Th230_U234=A$act.Th230_U234[i]
act.U238_U234=1/A$act.U234_U238[i];
act.Th232=A$act.Th230[i]/A$act.Th230_Th232[i]
age[i]= optimize(f,interval=c(0,200000),tol=1E-6)$minimum
}
names(age)=A$sample
age[(abs(age-200000)<1)]=NA
Next I collected the results and reported the comparison to the corresponding results in Frank Table 1:
test=data.frame(names(age),A$height_m,round(age,0),A$age*1000,round(age- A$age*1000,0) )
dimnames(test)[[2]]=c(“Sample”,”Height_m”,”Repl(corr)”,”Frank”,”Diff”)
test
This yielded the following results, with the results being sort of close, but nothing quite matched. The differences were all within the “error” shown in the Table, but that seems to me to be a different sort of issue – the numerical results should match exactly.
|
Sample |
Height(m) |
Replication |
Frank |
Difference |
|
BN6 |
7.5 |
100139 |
96700 |
3439 |
|
BN4 |
6.7 |
NA |
NA |
NA |
|
Bi7! |
6.5 |
105098 |
105600 |
-502 |
|
Bi1 |
5.9 |
107348 |
107500 |
-152 |
|
BN5 |
5 |
105526 |
105500 |
26 |
|
Bi2 |
4.75 |
101775 |
102200 |
-425 |
|
Bi3 |
4.2 |
104922 |
105400 |
-478 |
|
Bi4 |
2.95 |
106076 |
105600 |
476 |
|
Bi5% |
2.85 |
108505 |
104600 |
3905 |
|
Bi8 |
2.15 |
108307 |
106800 |
1507 |
|
BN3 |
0.6 |
103024 |
93600 |
9424 |
|
Bi9 |
0.35 |
119712 |
118300 |
1412 |
|
BN1 |
0.3 |
111148 |
111200 |
-52 |
|
De1/1! |
2.6 |
99045 |
98600 |
445 |
|
De2% |
1.3 |
116641 |
114500 |
2141 |
|
De2/4 |
1.22 |
97282 |
97700 |
-418 |
|
De2/3 |
1.21 |
104979 |
105300 |
-321 |
|
De2/2 |
1.2 |
101566 |
101900 |
-334 |
|
De2/1 |
1.19 |
101659 |
101900 |
-241 |
|
De7 |
0.7 |
109464 |
108400 |
1064 |
|
De3/1 |
0.2 |
115415 |
116400 |
-985 |
|
De5/1 |
0 |
113393 |
114300 |
-907 |
Right now, I don’t have any idea why my results don’t quite match. So it becomes hard to proceed to analyze Fleitmann et al 2007 without being able to benchmark the dating procedures. Perhaps I’ve misplaced a sign somewhere or made some other slip. The replication is pretty good, which makes it that much harder to sort out what, if anything, I’ve done wrong. As I’ve shown here, the age calculations take only a few lines – if you don’t believe me, run the scripts. Frank et al 2000 documented their lab procedures very carefully; wouldn’t it be nice if they did the same for their statistical procedures.





21 Comments
I think you might be interested to know that the U/Th dates from Stuttgart-Untertürkheim (Biedermannsche steinbruch) are rather shaky. The stratigraphy consists of two travertines (Untere and Obere) depoosited in a warm climate separated by the so called Steppe Rodent Layer, which was deposited in a cold “mammoth steppe” climate. The lower travertine is dated to Eem sensu stricto (MIS 5e c. 117,000-127,000 years BP) on biostratigraphic grounds (fully interglacial fauna and flora indicating conditions if anything warmer than today). However most of the U/Th-dates cluster around 105,000 years, which would suggest that the lower travertine should be assigned to the MIS 5c (Brörup) Interstadial (a mild interval, of less than interglacial rank, though in that case the dates are instead a bit to early). However if this is true, then the Upper Travertine must belong to MIS 5a (Odderade), the last relatively warm period before the fully glacial MIS 4. However in that case the Upper Travertine must be something like 80,000 years old, but the U/Th dates are about 105,000 years for the Upper Travertine as well. So whatever way you interpret them some of those dates must be either considerably too old or too young.
I can’t remember where I heard it, but there is a quote that runs roughly: “There are no known statistical techniques to distill knowledge out of ignorance”.
” the numerical results should match exactly. ”
Why? You are solving a nonlinear equation numerically, so your solutions and theirs are only approximate, and you should not expect exact agreement. They solve ‘iteratively’.
I tried to check it but I cannot figure out which of the several U234/U238 ratio they use in their formula.
Your link to Frank 2000 is not quite right.
Steve: Link fixed. The nonlinear equation is pretty simple and monotonic. It can be solved instantaneously to close tolerance. OK, it would be better to say that that the agreement should be within negligible difference than “exact”, but the issue is that the differences are not negligible.
Could an issue be that the original ages were calculated from measured data at full double precision but your replication is based on truncated data? If, for example, the data are given to 4 figures, does perturbing the input data one in the 4th figure yield differences comparable to the inconsistencies you see? This is the sort of issue I see frequently in trying to replicate other people’s results.
I haven’t tried to check it myself, but the paper gives Rd and the U/Th ratios as mean values with uncertainties. Is it possible that the tabulated values (also mean and uncertainties) differ because, when propagated through the non-linear function, the mean of the outputs when the inputs are varied is not the output when only the means are used.
I think that it’s most likely that my Th adjustment implementation has done something inconsistent with the procedure used by the authors, as opposed to things like rounding, but it’s hard to tell. Until I have more data and/or a copy of an algorithm as used, I think that I’ll leave this along for a while.
I reimplemented your function in Matlab and got the same answer for sample 1.
Looking at Appendix 1 of Frank, the equation is
Th230a = Th230 – Th232*etc
Your line is X=act.Th230_U234-act.Th232*(R0-Rd)*exp(-lambda[“Th230”]*t)-act.Th232*Rd
I think the first term should be act.Th230_Th232*act_Th232 and then X should be divided by act_U234 to get the ratio, however when I do that I get 92,928 years not the 96,700 in the table.
In any case the value for X in your f function should match the Th232/U230 column of the table which gives a value of 0.654. Matching your original equation I get a value of 0.6394 and with my suggested change I get 0.608.
I also tried replacing the U234/U238 ratio values with the estimates from next column without getting a match.
Jud Partin’s Ph.D. thesis submission dated mid-2008 also has an emphasis on possible sources of error, reinforcing my subjectivity that at least some problems are physical/chemical before mathematical. In particular, the method to establish the base level of Th232 in solid speleothem, so that a later correction can be derived for detritus, is on unsteady ground, so to speak.
The half life of U238, 4.5*10^9 years, means that it makes itself available to produce U234 only rarely. In the time span of speleothems, U238 can be held almost constant, so that any measured variation in its ratio to U-234 has to reflect either (a) a normal event that is used for dating, based on the half lives or (b) a system from which either U238 or U234, or both, have been added to or taken from a system thought to have been closed. This system in (b)can located far from the sampling site, near it or at it. Because of the closeness of their atomic weights, U234 and U234 are usually considered to vary little in specimens of similar age because they behave similarly in geochemistry, ie disequilibrium is seldom assumed to be a factor of any magnitude.
Jud is saying that earlier papers that show variation in U238 to U234 are showing evidence of contamination by an exogenous source of uranium. The authors try to correct for this contamination by assuming that uranium, but insignificant thorium, has entered the liquid system that preceded the carbonate deposition that makes the speleothem. However the large variation measured in U238/U234 makes it unlikely that this is the sole explanation.
However, from occasional observation by a non-expert on caves, the liquid drops that precede carbonate deposition are large compared to the annual layer addition thickness, so each annual layer stands a chance of being a mixture derived from several years of mixed liquid. There can thus be radial and axial and non-regular distortions of the speleothem that make it quite difficult to relate a solid lab specimen to its geochemical history, as Jud notes.
The method of Y-axis intercept used to estimate some thorium isotopes for correction is affected by these factors and is a potential source of large error in the interpretation, even assuming that the lab analysis is error free. The analogy that comes to mind is finding a couple of specified isotope needles in a poorly mixed haystack of miscellaneous isotopes.
#7. I think that I agree with your reading of Appendix 1 and I’ve edited my function accordingly as shown below – not that this improves the replication though. I replaced A$act.Th232 with A$act.Th232_U234
This yielded the following results for me when applied to the Frank data(typically a bit younder):
Sample Height_m Repl(corr) Frank Diff Error
BN6 BN6 7.50 90305 96700 -6395 9600
BN4 BN4 6.70 NA NA NA NA
Bi7! Bi7! 6.50 104695 105600 -905 2400
Bi1 Bi1 5.90 105544 107500 -1956 4800
BN5 BN5 5.00 103695 105500 -1805 3500
Bi2 Bi2 4.75 101050 102200 -1150 5700
Bi3 Bi3 4.20 104291 105400 -1109 4000
Bi4 Bi4 2.95 102618 105600 -2982 9000
Bi5% Bi5% 2.85 96457 104600 -8143 8800
Bi8 Bi8 2.15 102921 106800 -3879 6000
BN3 BN3 0.60 72955 93600 -20645 18200
Bi9 Bi9 0.35 113991 118300 -4309 7700
BN1 BN1 0.30 108796 111200 -2404 9200
De1/1! De1/1! 2.60 96790 98600 -1810 4100
De2% De2% 1.30 110489 114500 -4011 6700
De2/4 De2/4 1.22 96640 97700 -1060 5900
De2/3 De2/3 1.21 104177 105300 -1123 4200
De2/2 De2/2 1.20 100869 101900 -1031 4700
De2/1 De2/1 1.19 100661 101900 -1239 4700
De7 De7 0.70 105549 108400 -2851 5500
De3/1 De3/1 0.20 115029 116400 -1371 11400
De5/1 De5/1 0.00 113147 114300 -1153 9300
I haven’t started learning R yet (I’m an old Pascal fan) but I don’t see where the measurement errors are being handled. Normally in geochronology (my field), you do an error weighted regression, so the optimized parameters minimize the measurement error weighted misfit between model and measured values. It looks like the input data are the ratios, which themselves may or may not have correlations built into their errors (a big issue with the late great Derek York), but sometimes you can justifiably treat them as independent, as when your mass spectrometer is generating ratios and you don’t know any better (ha ha). Anyway, if this is an error weighted fit, then ignore this posting.
#!0. I have no idea how their errors are calculated and did not even begin to try to replicate this part of the calculation. The calculation of confidence intervals in climate is a longstanding conundrum and answers are usually hard to come by. To this day, we have been unable to figure out how MBH99 confidence intervals were calculated and every attempt to obtain clarification has been stonewalled. I wasn’t able to replicate any of the Mann 2008 confidence intervals either. Given this history, I wasn’t going to spend a lot of time on speleothem dating CIs without even being able to replicate the calculation. However, I welcome any suggestions or contributions on the topic.
Re: Steve McIntyre (#11),
Chris H is talking data point weighting, not errors or confidence levels of the derived parameter estimates?
He is right that these must be applied if significantly unequal.
Re: Alan Wilkinson (#15), Yes, that’s what I’m talking about. The top equation above is a bit like a highly constrained line fit to a single point. Because of the constraints, you can’t just put any line through the single data point. Now let x=238U/234U and y=230Th/234U. Both the slope and intercept depend on the age t. The way I would approach this (I’m not a U-series person but an Ar-Ar dater), I would set up a minimization where we have to find not only t but also x(true) and y(true). x(true) and y(true) are exactly constrained to fit the top equation. Now, assuming that sigma(x) and sigma(y) are uncorrelated (we don’t have correlation info, and if they are correlated, it gets more complicated – like fitting a straight line through points with x and y errors and the errors are correlated), then you want to find x(true), y(true) and t such that ((x(meas)-x(true))/sigma(x))^2+((y(meas)-y(true))/sigma(y))^2 is minimized. The assumption of independence is equivalent to assuming that the error ellipse is aligned with the axes. Correlation tilts the error ellipse. This is graphically like finding t such that the error ellipse around the measured x and y isotope ratios is as small as possible when expanded to just touch the line. Now, one can probably do this in R, but most people in the biz would likely just get Ken Ludwig’s Isoplot public domain software (see http://www.bgc.org/isoplot_etc/software.html) over at the Berkeley Geochronology Center (BGC). I don’t use it myself as I tend to write my own software, but I’m pretty sure he has the whole thing worked out.
Replicating methods: using a hat put 20 of each number from 0 thru 9 in hat. Then begin pulling numbers out one by one. What can I say? It has worked for me in the past.
#9. I think you now have the adjustment equation correct. I changed mine to match but I haven’t had any luck replicating the BN6 values. I fell back to a simple check of the measured and corrected 234U to 238U ratio columns. These are related by equation (2). If you solve (2) for lambda_234 and plug in those values and the corresponding ages you get implied lambda_234 values ranging from 2.8274e-6 to 2.8423e-6. The mean of these implied lambda values is 2.8353e-6. I think that one problem in replicating Table 1 comes from the limited precision of the values given. If you use the given value for lambda_234 and compute the implied ages, you get, for lines 3 to the end:
Frank Age Computed Age Difference
105600 105871 -271
107500 107517 -17
105500 105444 56
102200 102249 -49
105400 105118 282
105600 105591 9
104600 104590 10
106800 106776 24
93600 93569 31
118300 118153 147
111200 111109 91
98600 98842 -242
114500 114402 98
97700 97620 80
105300 105354 -54
101900 101973 -73
101900 102005 -105
108400 108574 -174
116400 116302 98
114300 114380 -80
Given the exponentials, t might be quite sensitive to precision uncertainties.
#11: In the words of the the Mythbusters when looking at a blown up car “well there’s your problem” (possibly). When you use the nonlinear optimization routine, it should be a weighted optimization where you minimize the chi-squared value. That will be calculated as ((the model isotope ratio minus the measured ratio)/(1 sigma measurement error))^2. Sum over all fitted isotope ratios. Please excuse the meta formula, but I think you’ll get the drift.
I see it all the time in industrial engineering.
1) Results don’t correlate, send your test setup.
2) I can do that here. Send me your program.
3) Something funny seems to be happening, send your code.
4) I can’t see the function I want to look at, send me uncompiled code.
5) Please send me uncompiled code soon.
I don’t attribute it to deceit. Instead: hiding untidy code, or hiding issues unrelated to the point of contention, or the “author” never studied the code either but inherited or harvested it.
Even happens between people working for the same company at the same location. Sharing software can be a sensetive subject.
RE 16. Sharing source is like showering with other men. Some of us have no problem whatsoever, other’s are rightly ashamed.
Quick question. If one uses an isotopic ratio (like from a mass spectrometer, measured at the same instant) of say U234 to U238, there will be instrumental errors with each isotope and so errors with the ratios. Is it permitted maths to treat the ratio as a single figure and to do customary statistics on a set of ratios, or does the error of each isotope have to be carried through separately to arrive at total error?
Re: Geoff Sherrington (#19), Both approaches are used. In the multiple-collector world, the canned control software tends to calculate ratios. These ratios are averaged over time and they are invariably treated as independent. However, strictly speaking they aren’t as usually there is a shared peak measurement. One should attempt to estimate the covariance of the ratios, but I doubt if this is normally done. From the mass spec software I’ve seen, any covariance is assumed to be zero. Of course, one can get around this by putting the best determined isotope in the denominator, which will minimize the correlation. In contrast, with noble gas machines (e.g. argon dating), which usually peak hop, one has to extrapolate peaks to gas inlet time (the isotopes get pumped by the machine itself during measurement). So each isotope tends to be treated as a separate measurement and they are essentially independent. However, one can then calculate the covariance expected in the ratio error estimates and this is normally done. At least I do it. 😉
Re: Chris H (#20),
Thank you Chris H. Both approaches are possible. My inquiry was to catch up with modern approaches. There is a particular case, seen for example with the several peaks commonly arising from isotope dilution in U work where one of the abundances is much, much less than others and so sets the error, as you noted in another way.