In his RC post yesterday – also see here – Steig used North et al (1982) as supposed authority for retaining three PCs, a reference unfortunately omitted from the original article. Steig also linked to an earlier RC post on principal components retention, which advocated a completely different “standard approach” to determining which PCs to retain. In yesterday’s post, Steig said:
The standard approach to determining which PCs represent to retain is to use the criterion of North et al. (1982), which provides an estimate of the uncertainty in the eigenvalues of the linear decomposition of the data into its time varying PCs and spatial eigenvectors (or EOFs).
I’ve revised this thread in light of a plausible interpretation of Steig’s methodology provided by a reader below – an interpretation that eluded me in my first go at this topic. Whatever the merits of this supposedly “standard approach”, it is not used in MBH98 nor in Wahl and Ammann.
Steig provided the figure shown below with the following comments:
The figure shows the eigenvalue spectrum — including the uncertainties — for both the satellite data from the main temperature reconstruction and the occupied weather station data used in Steig et al., 2009. It’s apparent that in the satellite data (our predictand data set), there are three eigenvalues that lie well above the rest. One could argue for retaining #4 as well, though it does slightly overlap with #5. Retaining more than 4 requires retaining at least 6, and at most 7, to avoid having to retain all the rest (due to their overlapping error bars). With the weather station data (our predictor data set), one could justify choosing to retain 4 by the same criteria, or at most 7. Together, this suggests that in the combined data sets, a maximum of 7 PCs should be retained, and as few as 3. Retaining just 3 is a very reasonable choice, given the significant drop off in variance explained in the satellite data after this point: remember, we are trying to avoid including PCs that simply represent noise.

Figure 1. Eigenvalues for AVHRR data.
As I observed earlier this year here, if you calculate eigenvalues from spatially autocorrelated random data on a geometric shape, you get eigenvectors occurring in multiplets (corresponding to related Chladni patterns/eigenfunctions). The figure below shows the eigenvalues for spatially autocorrelated data on a circular disk. Notice that, after the PC1, lower eigenvalues occur in pair or multiplets. In particular, notice that the PC2 and PC3 have equal eigenvalues.

North et al 1982 observed that PCs with “close” but not identical eigenvalues could end up being “statistically inseparable”, just as PCs with identical eigenvalues. North:
An obvious difficulty arises in physically interpreting an EOF if it is not even well-defined intrinsically. This can happen for instance if two or more EOFs have the same eigenvalue. It is easily demonstrated that any linear combination of the members of the degenerate multiplet is also an EOF with the same eigenvalue. Hence in the case of a degenerate multiplet one can choose a range of linear combinations which .. are indistinguishable in terms of their contribution to the average variance…Such degeneracies often arise from a symmetry in the problem but they can be present for no apparent reason (accidental degeneracy.)
As the reader observes, if you have to take everything in an overlapping confidence intervals, then there are only a few choices available. You can cut off after 3 PCs or 7 PCs – as Steig observes in his discussion. Not mentioned by Steig are other cut off points within North’s criteria: after 1, 9, 10 and 13 PCs, the latter being, by coincidence, the number in Ryan’s preferred version. North’s criterion gives no guidance as between these 4 situations.
In addition, if you assume that there is negative exponential decorrelation, then the eigenvalues from a Chladni situation on an Antarctic shaped disk area as follows – with the first few eigenvalues separated purely by the Chladni patterns, rather than anything physical – a point made on earlier occasions, where we cited Buell’s cautions in the 1970s against practitioners using poorly understood methodology to build “castles in the clouds” (or perhaps in this case, in the snow).

Eigenvalues from 300 random gridcells.
As an experiment, I plotted the first 200 eigenvalues from the AVHRR anomaly matrix as against the first 200 eigenvalues assuming negative exponential spatial decorrelation from randomly chosen gridcells. (I don’t have a big enough computer to do this for all 5509 gridcells and I’m satisfied that the sampling is a sensible way of doing the comparison). A comparison of observed eigenvalues to those from random matrices is the sort of thing recommended by Preisendorfer.

Comparison of Eigenvalues for AVHRR and Random data. Proportion of variance of first 200 eigenvalues shown on log scale .
This is actually a rather remarkable pattern. It indicates that the AVHRR data has less loading in the first few PCs than spatially autocorrelated data from an Antarctic-shaped disk and more loading in the lower order PCs.





49 Comments
In North et al., the error bar width is given by Eq. 24. It’s proportional to each particular eigenvalue. If you look closely at Fig. 4 of North, the error bar widths are smaller for smaller magnitude eigenvalues than for larger magnitude eigenvalues. The widths don’t vary much because the largest eigenvalue is only 40% greater than the smallest, but the variation is there.
In Steig’s figure (in his RC “tutorial” post and above), the error bar widths appear equal in spite of the fact that the ratio of the largest to the smallest eigenvalues are about 50 for the satellites and 100 for the weather stations. Whatever is being used to compute the error bar widths, it isn’t Eq. 24 of North. However, Steig’s comments seem to imply that his formula is the one being used to compute how many PCs to use.
Re: Steve J (#1), He’s using a log scale on the graph, which is why they look the same.
Re: Ryan O (#2), You’re right. My mistake.
I’ve edited this slightly, cropping Steig’s diagram, to show the overlap of eigenvalues for the PC2 and PC3 – which are thus not “statistically separable” (regardless of the scale of the graph.)
It seems to me that he’s saying that wherever you draw the line in retaining PC’s, it needs to be between “statistically separable” eigenvalues. So you can’t just take 2 PC’s because 2 and 3 aren’t separable. But you can take just 3, because PC 3 and PC 4 are separable.
Likewise, PC 4, 5, 6 and 7 aren’t separable. But 7 is from 8 and 3 is from 4. So you can choose either 3 PC’s or 7 PC’s.
So in other words, Steig is claiming that PC 2 and 3 are separable from the rest not from each other, which may be an idiosyncratic usage, but I’m not sure he’s confused about North.
Am I missing something?
-rv
Re: richard (#5),
Re-reeading Steig’s excerpt, I think that you’re right about your interpretation of what Steig’s doing. It’s not an approach that is “standard” in principal components literature – Ryan’s listing of PC retention methods does not include it. It’s not an approach that Mann used in MBH, though he also said that he used the standard method.
Your interpretation opens up an interesting point in terms of Ryan’s PC=13 reconstruction. The first 13 PCs are “separable” according to the above diagram.
I’m revising the thread to correct my reading of the article (and will post any deleted material in a comment.)
The whole business about North and ‘standard’ seems far to general for PCA. Certainly there are processes with multiple axes of variance which can violate these criteria. I can’t get my head around any concept of a pre-determined number of PC’s which guarantees a good result. Some methods come close.
Steve’s hypothesis of random distributions on a map of antarctica is an extension of the broken stick method (as far as I understand) with the added complexity that the continental shape and auto-correlation is important in generating random data.
Ryan showed me this link before which describes a number of methods and the limitations. Sorry if everyone has already seen it.
Click to access pca.pdf
Re: Jeff Id (#6),
Jeff, the linked article has a pretty exhaustive survey of stopping rules, but, as far as I can tell, none of them correspond to Stieg’s “standard” approach which is not set out in that form in North et al 1982. Despite all my reading about PCs over the past few years, I’d never seen Steig’s “standard” method before in statistical literature – though perhaps it subsists within the climate subculture.
Without having read North in full, I’m also interested in what it has to say about chained inseparable eigenvalues (to make up a term). In other words, PC 4 is not “statistically separable” from PC 5 and PC 5 is not separable from PC 6, but PC 4 is separable from PC 6.
The key insight of inseparability is the fact that a linear combination of the (1 or more) inseparable eigenvectors is also an eigenvector with the same eigenvalue (within margins of error). But in the case above, will linear combinations of PC 4, 5, and 6 be eigenvectors? And if so, what will their eigenvalues be?
Re: richard (#7),
You are quite correct in the statement that any linear combination of eigenvectors corresponding to the same eigenvalue is also an eigenvector (corresponding to that same eigenvalue).
In such a situation, the PCs are calculated to form an orthogonal basis for the vector space spanned by the eigenvectors corresponding to that common eigenvalue. However, the answer is not unique because any rigid rotation (i.e. one which retains the orthogonality) of those basis vector PCs will produce a new set of PCs.
Re: RomanM (#10),
Right, that makes perfect sense to me when there are 3 PCs that share an eigenvalue (within error bars). But I was specifically talking about a situation where the first and second are “the same” (i.e. inseparable) and the second and third are the same, but the first and third are separable.
When you are talking true equality of eigenvalues, this is not a problem, either all three are equal or they aren’t. So you might have three eigenvectors with eigenvalues of 0.5.
But when you extend it as North did to include error bars, you can get the situation I described. To extend my example, you might get eigenvalues of 0.6, 0.5 and 0.4, all plus or minus 0.075. How does this affect the situation given that the first and third are separable?
With more inseperable PCs (as in Steig), the problem gets bigger. If you have 7 PCs, each inseparable from the next, the first might have a very different eigenvalue than the seventh.
Re: richard (#12), The problem with blindly using North is that he does not define how close eigenvalues have to be to be considered “separable”. The closer they are together, the more likely they represent a mixed mode. But this is not necessarily the case, as the loads of small eigenvalues show.
.
In my opinion, an approximate truncation point should be determined based on the purpose of the analysis (i.e., whether you are simply looking to reduce the size of a data set or whether you are looking to extract individual components for analysis), using some of the heuristic selection tools (like in the Jackson article) as a guide, and supplementing with North to minimize the chance of splitting important modes.
Re: richard (#12),
You are confusing the sample PCs with the population PCs.
Statisticians would model a situation with a population from which the multivariate sample of observations was taken. That population would have some sort of correlation structure. In the simplest case, it might be that all of the variables are independent and have equal variability. In that case, all of the population eigenvalues would be exactly equal to one.
However, the sample would display various levels of (spurious) correlation and it would very likely be that the eigenvalues of the sample correlation matrix would all be different (although most of those differences might be small). Various tests have been devised to decide whether the differences in the sample eigenvalues represent real differences in the population. Such tests should be viewed as giving conclusions of either “could be the same (i.e. I can’t tell the two eigenvalues apart)” or “the eigenvalues are different (i.e. in the Steig vocabulary, “separable”)”.
The interpretation in the case you describe, for example, is “I can’t tell that 1 and 2 differ and I can’t tell that 2 and 3 are different, but 1 and 3 are far enough apart to decide that they are not the same”. Even when all of the poulation eigenvalues are all different, it is quite possible that I might not be able to decide this for each comparison because the amount of information in the sample is too small.
This sort of conclusion can also arise quite often when doing multiple comparisons for factors in an analysis of variance as well. It should not be viewed as contradictory.
I’ve edited the above post in light of comments 5 and 7. I substantially reorganized the thread, adding some new material and deleted the following comment:
Steig et al 2009 stated:
I’ve observed elsewhere that there is considerable reason to interpret PC1-PC3 as no more than Chladni patterns. Interpreting North et al 10=982 literally, the PC2 and PC3 are not statistically separable and the statement in Steig et al 2009 is not correct as it stands. However, reader richard has convinced me that Steig had a different point in mind – and, rather than parsing North et al 1982, I’ve followed this interpretation in the restatement above, so that comments are at least apples and apples as much as possible.
I’ve been following the various Steig et al 2009 threads for some time, and one thing really puzzles me. I wish I know a bit more statistics but given that I don’t – how is any use of PCA justified at all?
We have a load of data – it’s a measure of temperature (or something close to it). For simple people (like
myself) there is a simple way forward. Use the temperature data. If you use the temperature data you can then plot the data and perhaps observe a trend (like temperature going up or going down). Sorry this is all a bit basic when compared to the level you statisticians work at.
However, in this paper, apparently, instead of using the temperature we use the first n PCs. How can this ever be an improvement. instead of using the actual data of temperature – which we acgually have, we put in through some statistical mincing machine and use some numbers that come out of the other end.
In a sausage factory, if you want to know the length of a sausage, you put it against a rule and measuer it. You don’t mince it back up and then meause the length of the mince.
In the most famous (or infamous) example of PCA discussed here, MBH98, there was at least some physical argument for using PCA. (I am about to say something positive about MBH98 – here of all places – weird!) It could be argued that tree ring growth isn’t directly a measure of temperature. It’s a measure of how tree friendly conditions were at that time. That includes temperature but may also include other things, nutrients, water table, rainfall, CO2 levels, the absence of deer whatever. In MBH98, tree-ring growth wasn’t used – instead the first PC was used. There is a justification for this – the 1st PC represented the strongest of many signals that the tree was measuring. This was assumed to be temperature.
So my question is this. What physically does the sum of the first 3 PCs represent? It can’t be temperature – to get that you have to add all the PCs back together. And what physically do the remaining PCs represent? And is it OK to throw that information away?
Re: Nick Moon (#14),
I do not see how you can say there was justification for this, if you read all the papers under Hockey Stick Studies on the left in this blog.
Re: Gerald Machnee (#35),
I didn’t mean to suggest that it was a valid justification 🙂 Perhaps I should say, it’s how they justified it to themselves. But I remain confused as to how you can choose to ignore the actual temperature data that you have and instead use something else derived from but clearly different from the temperature.
With MBH98, you could claim (not saying it would be true – but you can make the claim) that PC1 was close to temperature – being the strongest component of tree-ring growth. You could also choose to argue that the remaining PCs represented other factors – not temperature.
I can’t see in this case how you can mkae any such ‘justification’ for using PCs.
Re: Nick Moon (#36),
I will not discuss it as this has been gone over by Steve many times, But the Team used it as a display of temperature and got it into IPCC.
Re: Nick Moon (#14),
Nick, your question is reasonable enough, but, as Gerald says, this isn’t a good thread to interject it. In addition, if you want an explanation of how PCs applied to tree ring networks are supposed to yield something sensible, you really should ask Michael Mann or Caspar Ammann. The methodology more or less arrives from outer space in their articles with the only argument being how many PCs to retain. And the issue is always couched with bristlecones in the background. If you remove Graybill bristlecones, then no one really cares about PCs anyway. The entire debate is about magic thermometers – but this has been discussed in many threads and I don’t want to spend time on it right now.
I’m still stuck on the concept of “overfitting”. I thought I understood PCAs, eigenvalues, eigenvectors and similar mysticisms when I took Numerical Linear Algebra class. It seems I was wrong.
For Steig to try to apply the idea of overfitting the order of a polynomial equation to the number of PCAs just seems like a complete misfit to me(?). As I recall, adding more PCAs always gets you at least a little closer to the matrix that you’re reconstructing. After some number of PCAs, the incremental change from using more might be imperceptible, but adding PCAs is never going to take you further from the goal in the way increasing the order of a polynomial equation does, is it? It seems to me that overfitting isn’t really even a relevant idea in the context of PCA. Am I missing something?
Re: scp (#15),
I started writing a response to your post several hours ago as follows:
…
After a while, I realized that I could NOT frame the regression example in a meaningful fashion in the context of the Steig et al. (2009) paper. It just didn’t fit! Of course, if there was a place in the RegEM procedure where they did PCA regression, i.e. used the PCs (which were limited to 3 by the “standard rule”) as predictors for imputing the missing values, I could have pointed to it and said, “Yes, there is the danger of overfitting because you have too many predictors!”. But that is not the case anywhere in the procedure.
Perhaps Dr. Steig or whoever came up with the example could explain to me how it relates to what was done – I am always open to learning new things . (For quite a while I lurked more than I posted. It was only when I became more comfortable that I actually had learned enough to have a handle on what climate statistics was about that I decided I would add a comment or two.)
Frankly, by limiting the number of PCs a priori to three, the only thing that seems sure is that they would pretty much no longer have enough information to possibly describe the complexities of a large area with a multitude of topographies and diverse climate influences – the “smearing” referred to by Jeff and Ryan. Overfitting indeed!
Re: RomanM (#23), I almost responded to the overfitting part at RC, but the only thing I could come up with was, “That doesn’t really apply.” 🙂 It does apply quite nicely to the RegEM portion, but Steig didn’t seem to take issue with our RegEM. This is odd, since the results are more sensitive to RegEM settings than retained AVHRR PCs. In the end, I decided it wasn’t that important, since our verification stats indicate that overfitting is not a major problem.
.
Also – I’m not sure if anyone else realizes this – but Steig automatically assumed you need to set regpar equal to the number of retained AVHRR PCs. I don’t think it ever occurred to them to look at the ground station imputation as a separate animal from the AVHRR data – and they are quite different. That could be why they disregarded using the higher-order PCs. Keeping regpar the same as the AVHRR PCs leads to massive overfitting during RegEM. I compared his graphs of trends by PCs to my table I generated for the “Antarctic Tiles” post and they match rather well to the regpar = # PCs entries.
.
Re: Steve McIntyre (#25), I note the implication in Smith: As long as your EOFs are based on densely populated data (like the AVHRR data), you almost can’t retain too many. I’ve done reconstructions using up to 25 PCs. The answers don’t change. I should try more, just to see what happens.
.
If, however, you form the EOFs out of sparsely populated data, then I imagine the fit between the sample EOFs and population EOFs is subject to increased sampling error, leading to less faithful representations in the higher-order modes.
Re: Ryan O (#26),
I think this is an important point, it’s almost like overfitting is a misnomer. It’s more of a convergence to one of many local minima in my mind. Overfitting implies a more exact solution with too many dof, however when the data is this sparse it has a different connotation to me. Regularization is designed to help EM converge to a reasonable solution with more extensive missing data. In this case half is missing and the premise is that there are going to be cases when the solution is unreasonable.
Since we have a situation where we know reasonable spatial covariance/distance doesn’t occur until at least 7 pc’s and we also know RegEM ttls really distorts the signal at that point (extreme fluctuations resembling overfitting), other regularization is required. That’s one of the thing’s Ryan has solved through his piecemeal optimization is the stabilization of the result at higher PC’s (I’m sure Dr. Steig has missed this). I’ve been working on a post about that but we are currently in intermission in the Stanley cup finals so it will have to wait. Go wings.
North et al:
For fellow statistics dummies, EOF = Empirical Orthogonal Functions, http://en.wikipedia.org/wiki/Empirical_orthogonal_functions
–from our own handy http://climateaudit101.wikispot.org/Glossary_of_Acronyms
Cheers — Pete Tillman
We should not forget that statistical procedures are merely a tool for scientific understanding; not an end in and of themselves.
Do PCs 4 through 13 contain important information about the geographic distribution of Antarctic temperature trends? Or are they just noisy residue?
Its not clear to me that Steig et al have ever argued that PCs 4 through 13 are noise. Their own comments seem to suggest otherwise.
If so, it hardly seems relevant which authority is cited for excluding the extra PCs. Their exclusion only serves to obscure the underlying physical reality by attributing much of the very rapid peninsular warming to regions that have actually gotten colder or displayed very modest warming trends.
It seems to me irrelevant what a “standard” method says about retaining PCs when RyanO shows that the results change completely with different numbers of retained. In this case they are clearly not “noise” and have not been shown to be “noise” by Steig et al. That is, the result (the temperature map) is NOT converging with addition of more PCs but is unstable with this addition.
It is finally beginning to penetrate this non-mathematical, non-statistican’s brain that, strangely enough in this day and age, although we, or someone, may have observed that parts of West Antartica have trended warmer in recent years, and that thermometers in Central and Eastern Antartica have shown cooling during the same period, no one “knows,” and, given the limits of our technical resources, together with the remoteness, the size, and apparent persistency of the place, may never “know” whether these basically unobserved and non-verifiable Antartic conditions, and therefore trends, are any sort of valid evidence for or against the theory of man-made climate change. Or any other kind of climate change. Statements to the contrary, be they in “peer” reviewed journals or on blogs,and no matter how calculated, are nothing more than guesses; and we have no way of knowing whether they are “educated” guesses or not. Antartica is the head of the pin.
Re: PhilH (#20),
what he said.
Stats or no stats — there isn’t enough information about vast areas of the continent to make any kind of intelligent claim about trends. This study is a farce, not because of what was or wasn’t done with however many PCs, but because the study purported to make a conclusory statement when there isn’t enough information to do so.
Steig says that “One could argue for retaining #4 as well, though it does slightly overlap with #5.” However, in his Figure 1 “eigenvalue spectrum – including error bars,” #4 does NOT overlap with #5.
I mentioned Smith et al 1996 recently in connection with SST. This is an extremely important article regarding the use of PCs for interpolating climate fields and I urge readers to consult it. I should have mentioned it in my post.
The problem in Smith et al – reconstructing SST in periods with sparse data – is really rather similar to Steig and it’s surprising that it wasn’t kept more firmly in view. In Steig’s recent post at RC, instead of reviewing SMith et al 1996, he merely provides an armwaving argument using an example from regression that is at best an analogy.
Smith et al refer to North et al 1982 and the problem of separability. Their eigenvalue plots look a lot like the Antarctic AVHRR plots. Nonetheless, they consider very large number of modes(PCs) as shown in the following table:
As noted previously, they mention that failure to include sufficient modes can cause problems.
Re: Steve McIntyre (#22),
So by claiming that North promotes a few-PC statistical cutoff point, Steig is ignoring deeper analysis? Smith went to the trouble of comparing various PCA against observations, in Smith’s case many regional comparisons in order to find which PCs in each region contain the regional signals. It’s possible that by treating the continent as a single region, Steig’s first 3 PCs are driven by something less relevant to temperatures than is relevant. If Steig had applied Smith’s regional analysis, he might have been able to create better regional approximations. So he might be using something affected by barometric pressure at the higher continental altitudes, and smearing peninsula temperatures across the entire continent instead of limiting the proper peninsula patterns to the peninsula.
Admittedly, Steig has to deal with having much less data and many fewer locations than Smith et al did. For a back-of-the-envelope estimate, what Steig did is reasonable. But because the rough estimate doesn’t show dramatically different results, it shouldn’t have been published and something more detailed should have been done.
Re: AnonyMoose (#41),
I’m not so sure that Smith’s SST data for the 19th century is any better than Antarctic station data in the 1960s. I’d be surprised if it was. The enterprises are similar.
Steig promoted his calculation as follows:
And you say that his calculation is OK for the “back of the envelope”. 🙂
Two more quotes from Smith et al 1996 – I’ve mentioned the 2nd one before. I don’t see how Steig’s 3 PCs can be construed as being “standard” under SMith et al 1996.
Ryan O (#26),
Hmmm. Very interesting.
There seem to be good reasons to carry more PCs from the AVHRR and no valid reason to stop at PC=3. I agree that there are reasons not to increase regpar. Actually, I can think of an argument for regpar stopping at 1.
As he doesn’t seem to understand the ingredients, I guess he didn’t realize that the mixture might not work very well.
Re: Steve McIntyre (#27), so what is the rationale behind selecting a value for regpar?
And going back to my comment in #21, why does Steig claim that #4 and #5 overlap when the uncertainty bars in the exhibit clearly do not? 4 PCs seems to make more sense from “Figure 1” than 3. And now that I look closer, 6 PCS seems to make even more sense, and possibly 7. Or even 10, where the weather station eigenvalue has a pretty big drop-off between #10 and #11, and the eigenvalue change between #10 and #11 for the satellite data looks like it may be “statistically separable.”
You don’t get “statistically separability” in the weather station eigenvalues until you get to the difference between #7 and #8 – where there is also a “statistically separability” in the satellite eigenvalues, too. So even if stopping at 3 PC is somehow justified based on the satellites alone, does it not matter that the weather stations aren’t hitting “noise” yet and should have more PCs?
I think that Dr. Steig has it somewhat backwards. One has to remember that it is the values of the satellite PCs that are BEING predicted in the pre-satellite era and not the other way around. If anything can cause overfitting, it is having too many stations doing the predicting and (unless I am missing a step where different weights are used for each of the stations and PCs – I don’t recall seeing any weights specified), each of the stations and each of the PCs has an equal say so the stations tend to predominate. For that and reasons of blackbox non-linearity, I doubt TTLS can be trusted anyway.
I can’t see any theoretical problem with increasing the number of PCs calculated from the original data to input into RegEM. Put in more satellite information and let the procedure sort it out. Jeff’s observation about local minima with higher values of regpar is likely correct (and exacerbated further through the enormous number of imputed values in the process).
In retrospect, although the personal attacks by his henchmen were pretty animated, I thought his entire defence of the analysis was shaky.
Re: RomanM (#30),
.
Dammit! I was hoping to bust that one out myself and impress people. Hahaha.
.
Seriously, though, I am presently completing my description of Steig’s method (yes – actually drafting notes for a manuscript) where I describe his method as extrapolation. Has important consequences when interpreting the data. 😉
Re: Ryan O (#31), Err, that should be “interpreting the results”.
Re: RomanM (#30),
I don’t know that anyone has looked at Ridge regression yet as an alternative. If high order RegEM ttls overweights low influence PC’s in this case, do you have any thoughts on ridge regularization for minimizing the low influence PC’s? As I understand it, the pc’s are forced to follow a exponentially decreasing order of importance, but I’ve only done a bit of reading on it. I don’t want to waste too much time without good reason but it might be a more appropriate regularization.
SteveM
I also have been looking at R Kriging functions. I’m not sure they will provide a better baseline than area weighting but Kriging is well known and IMO a lot better than all this EM fanciness. If you had any advice, it would be helpful.
Re: Jeff Id (#33),
Jeff, I wouldn’t bother wasting any time with RegEM – ridge. There’s something a bit wrongheaded in their enterprise that this sort of thing won’t patch – I’ve got a post in the works which may elucidate things a bit.
Re: Jeff Id (#33),
Although I don’t have much experience with ridge regression, it is apparent that there are difficulties with bias in the results and with the ability to calculate confidence bounds and do testing. Some of this inherent difficulty seems to stem from the fact that one is simply trying to squeeze too many estimates from limited data. As in PTTLS, there is also the fact that the method leaves itself open to “manipulation” through the choice of parameters by the analyst.
JEff, in a regression setting, ridge regression is “blend” of the partial least squares coefficients (i.e. correlation-wieghted) and OLS coefficients:
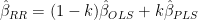
They can be viewed as be a path in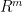 where you have m coefficients from
where you have m coefficients from  to tex]\hat{\beta}_{OLS} $, a perspective that is consistent with Stone and Brooks 1990, about which I’ve written before.
to tex]\hat{\beta}_{OLS} $, a perspective that is consistent with Stone and Brooks 1990, about which I’ve written before.
The truncated SVD coefficients also make a path from from to
to  . In truncated SVD, the matrix
. In truncated SVD, the matrix  is used in the form
is used in the form  latex V_k $ is the k-truncated eigenvector matrix from the SVD of X=USV^T.
latex V_k $ is the k-truncated eigenvector matrix from the SVD of X=USV^T.
When k=n, you have latex
latex
You can construe k=0 as yielding:
 latex
latex
The intermediate values yield line segments that will follow a path in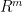 that is a little different than the Ridge Regression, but they will be “close” to one another in the sense that the coefficients become increasingly “overfitted”. The term “overfitted” is not as operational a term as one would like as it seems like a value judgment. In practical terms, the behavior of the inverse borehole coefficients were a good illustration as they become increasingly unstable with as k increases. Operationally, this means that
that is a little different than the Ridge Regression, but they will be “close” to one another in the sense that the coefficients become increasingly “overfitted”. The term “overfitted” is not as operational a term as one would like as it seems like a value judgment. In practical terms, the behavior of the inverse borehole coefficients were a good illustration as they become increasingly unstable with as k increases. Operationally, this means that 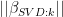 increases as k increases, a point made in Fierro as well.
increases as k increases, a point made in Fierro as well.
In the barplot terms shown in the post, my guess is that “overfitted” coefficients will have increasingly wild mixtures of positive and negative weights.
I’m still trying to picture the path of TTLS coefficients in these terms. I think that they are going from the PC1 coefficients (k=1) to the TLS coefficients (k=n+1). I think that the TLS coefficients are going to be “close” to the OLS coefficients in most cases that we’re going to encounter and that the introduction of TLS is the introduction of a more elaborate and murkier technique by people that don’t really understand what they’re doing.
If you went to regpar=1, I think that you’d end up (in a backdoor route) to coefficients that are the same as the GLS coefficients – which I’m pretty sure could be shown to be closer to the maximum likelihood estimate than regpar=3 under most circumstances.
It’s also not the case that more PCs is necessarily “deeper”. I’m not absolutely sold on the idea that going past 1 PC is a good idea. If our ultimate interest is an Antarctic trend, then the statistical model is more less T+noise – and for that sort of model, something that’s more like an average or a PC1 might well be better than starting down the lower PCs.
But if you use lower order PCs, then surely Steig should have considered relevant literature like Smith et al 1996, which warns against the precise situation that occurs. Smith et al 1996 is even cited by coauthor Mann in MBH98 and Smith’s methods are discussed at length in Schneider 2001. This is not an esoteric reference. It’s the sort of thing that maybe he should discuss in his classes on PCS.
Re: Steve McIntyre (#43), In the case of satellite data, it sure looks like a case could be made that PC1 is where the analysis should stop. Whether that means to truly just use PC1 or if PCA should just be avoided for this type of instance altogether, I don’t know.
Re: Michael Jankowski (#44) and Re: Steve McIntyre (#43),
.
The answer to that depends on what you are trying to do. If you are attempting to obtain an overall trend for the continent, 1 PC may work quite well. If you are attempting to obtain geographic information about temperature, 1 PC does not provide the needed resolution.
Re: Ryan O (#45), Yep, we obviously dont disagree on this.
Re: Ryan O (#45),
Given the fact Antarctica has significantly different climate zones with divergent climate trends, doesn’t Steig’s methods and/or PCA of any number give inherently incorrect results? Don’t the climate zones need to be classed with a k-PCA at a minimum, with special handling to prevent the low variability and the small number of interior Antarctic sites being disregarded in the transformations?
Re: D. Patterson (#47), Actually, #48 pretty much answered that question. I believe Steve M has several good expositions on this relative to both his MBH work and what he’s done with Steig. The simple answer is that the extracted modes are unlikely to be interpretable as physical processes. The modes simply explain, in order of most to least, the amount of variation in the original data set. The more you extract, the greater geographic resolution you have (and, also, the more noise you include). There’s always a tradeoff, but in this case – where the idea is to simply reduce the AVHRR set to a reasonable size for computation – the only penalty for extracting too many is that your computer runs longer before returning an answer.
Re: Steve McIntyre (#43),
If that was truly your interest principle components would not be my first thought; it would be frequency domain analysis where you chop off the higher frequency components. There at least what you pull out has a meaningful interpretation that is robust (although only with infinite data if you want to be techincal!). The first principle component is just an orthogonal component that has the greatest weight. It is not fixed a priori and you can choose multiple rotations of your basis that affects the results. PCs have no inherent meaning and arguments about what they actually are never seem to rise above hand-waving in these contexts. (In engineering and experimental sciences you have a chance of attaching robust meaning to a PC, but in others the chance seems vanishingly small.)
One Trackback
[…] A Challenge to Tamino: MBH PC Retention Rules (Mar 14, 2008) Gavin and the PC Stories (Mar 3, 2009) Steig’s “Tutorial” (Jun 2, 2009 ) Possibly related posts: (automatically generated)Tamino v. Montford – A […]