Wilson et al 2016, like D’Arrigo et al 2006, includes a ‘Polar Urals’ chronology as one of its components. Tree ring chronologies from Polar Urals and Yamal have long been a contentious issue at Climate Audit, dating back to the earliest days (see tags Yamal, Polar Urals).
Whereas the D’Arrigo et al 2006 version had one of the biggest blades in the entire D’Arrigo et al 2006 portfolio (ending at nearly 4 sigma, with the smooth at 2.5 sigma), the new version, while slightly elevated in the 20th century, remains under 1 sigma.
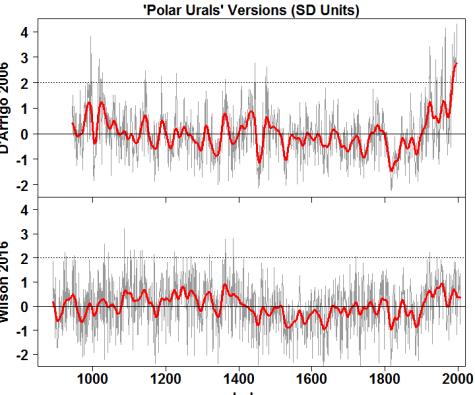
Figure 1. ‘Polar Urals’ chronologies (scaled to SD Units): top- from D’Arrigo et al 2006 (RCS); bottom – Wilson et al 2014. The top series is actually the Yamal chronology (Briffa, 2000), while the bottom series is a Polar Urals MXD version from Briffa et al (2013).
In today’s post, I’ll first discuss the dramatic reduction in the blade of the ‘Polar Urals’ chronology from D’Arrigo et al 2006 to Wilson et al 2016 (which uses a variation of the Polar Urals MXD chronology from Briffa et al 2013). This doesn’t take long to explain.
I’ll then use the rest of the post to discuss the bewildering thicket of adjustments to the Polar Urals MXD chronology in Briffa et al 2013. I would be astonished if any practising paleoclimatologist (including the lead author of Wilson et al 2016) has ever made any attempt to figure out what Briffa (or more likely, Melvin actually did) in Briffa et al 2013. I doubt that the editor and peer reviewers did either.
In this case, it’s not so much that the result is “WRONG!!!”, but that it is unintelligible. In the course of trying to understand what they did, I re-did the MXD chronology using the random effects techniques that I’ve discussed at Climate Audit from time to time. This gives a rational foundation for the “RCS” chronologies with which dendros thrash around so incoherently. It distinguishes the allocation of variance to annual random effects from allocation of variance between sites – an essential topic in any statistical analysis, but one which is not even broached in conventional dendro analyses. This form of analysis is something that I’ve been nibbling on for a long time: the extraordinarily messy and incoherent Briffa 2013 analysis gave a useful opportunity to refresh my thoughts on it
The MXD Data
Briffa 2013 used MXD data from four datasets:
- a Schweingruber dataset (pou_la; russ021x) sampled in 1990. This was the basis of Briffa et al 1995. It is a combination of living and subfossil data. Published information on the location of this sample is imprecise. Thus, while there are detailed site location maps of the area in Shiyatov’s articles, there is insufficient information to locate the sampled area on the location map. My guess is that the sample was taken near the lower Shiyatov transect, but this is only a surmise.
- additional subfossil data was acquired in 1998 (polurula; russ176x). Esper et al 2002 did a RW chronology including this data. (This chronology was not separately published and it took a huge fight with Sciencemag to get the chronology and data.) D’Arrigo et al did analyses with the combined data, but did not use it, instead reporting the Yamal chronology, which was incorrectly attributed to Polar Urals. This additional subfossil data appears to have been from the same location as the earlier sample, but again only a guess.
- A new, fairly small, Russian sample of living trees from 2001 (purlasi, also “148”). Its reported location appears to have been taken fairly close to Shiyatov Transect 1, but, if its location is imprecise, this might be coincidence.
- A second new, even smaller, Russian sample from 2006 (purlasi_sc, also “225”). This appears to have been taken some distance away from the purlasi site, and perhaps at lower elevation.
There are also several Polar Urals RW (only) datasets, including Shiyatov’s enormous dataset that remains inaccessible to western dendros.
Because there is a significant altitudinal gradient and other local effects at the Polar Urals location, inter-site differences can be material. Another potential inhomogeneity raised in Briffa et al 2013 was that a substantial fraction of the subfossil data, based on a re-examination of original correspondence, was reported as coming from roots, rather than stems. Briffa et al argued that this created radial inhomogeneity and required the discarding of root data. As so often, however plausible this reasoning may be, concerns about radial inhomogeneity never seemed to be a problem when it came to strip bark bristlecones, where radial inhomogeneity is a far more severe problem. As I observed at the time, this criterion seemed very plausible to me if it were consistently applied (which dendro specialists did not have the slightest intention of doing), but, when applied ad hoc to Polar Urals, smacked of a Calvinball technique to get rid of the inconvenient MWP in the Polar Urals RW series.
‘Polar Urals’
I placed quotation marks around Polar Urals in the opening graphic, because the “Polar Urals” series of D’Arrigo et al 2006 was actually Briffa’s notorious Yamal series, incorrectly identified. I pointed out the erroneous identification to the D’Arrigo authors long ago, but, for reasons that remain obscure, they refused to issue a correction.
The first Polar Urals variation came from Briffa et al 1995 (top panel below) and was based on the first of the above four datasets: it was a temperature reconstruction based on regression against both MXD and RW chronologies. It is more strongly correlated to MXD data and has a strong visual similarity and high correlation (0.82) to the Briffa et al 2013 MXD version used in Wilson et al 2016.
In 1998, additional subfossil data was collected. When incorporated into a RW chronology, it had a very elevated MWP. As discussed at CA on many occasions, this version was a pariah among multiproxy authors, whe (used only in Esper et al 2002, from which the middle panel), whereas the big-bladed Yamal chronology (top panel of first figure) was extremely popular. In early CA days, I challenged the infatuation of paleoclimatologists with the big-bladed Yamal chronology to little avail. D’Arrigo et al 2006 considered the Polar Urals RW chronology resulting from the combined data: evidenced by their Table 1, but used the Yamal chronology even though Briffa refused to give them the underlying measurement data.
Ironically, the Briffa et al 2013 version (bottom panel) reverts to a variation that is very similar to the original Briffa et al 1995 version (which was popular in early multiproxy reconstructions: Jones et al 1998, Mann et al 1999, etc.)

Figure 2. Polar Urals versions all converted to SD units. Top – temperature reconstruction from Briffa et al 1995 using a regression on MXD and RW; middle – RCS chronology from Esper et al 2002 based on RW, including additional data from 1998; bottom – Wilson et al 2016 version, from temperature reconstruction based on MXD chronology of Briffa et al 2013.
The Briffa-Melvin Flowchart
While the Briffa 2013 MXD chronology is very similar to the Briffa 1995 temperature reconstruction, the process by which they got to the similar result is astonishingly convoluted, as shown by their flowchart (Supplementary Material 4) for combining data from the four sites (on which I’ve added the red,blue and green bubbles were drawn by me to illustrate the comparisons in the PC figures discussed later in this section.)

Figure 3. Annotated flowsheet from Briffa et al 2013, Supplementary Material 4.
To implement this flowchart, they produced the following datasets:

Briffa and Melvin SM4 contains six figures (PC03, PC05, PC07, PC09, PC11, PC13), all in an identical style (see example below), in which they compare age-MXD curves in order to assess the need for adjustment of one dataset relative to another. The top right red bubble in the above flowchart locates the PC13 adjustment which is described in Figure PC13 as follows:

Figure 4. Briffa et al 2013 Supplementary Material 4 Figure PC13 illustrating relative adjustment between purlasim.mxd and purlasi_scm.mxd.
This sort of comparison is done six times for MXD data in each of PC03, PC05, PC07, PC09, PC11 and PC13 (and six more times for RW data). In some cases (PC05) where the adjustment was “small” (3%), they decided not to use the adjusted data and keep the unadjusted data. In one RW case, they concluded determined that “simple scaling” did not produce “matching” chronologies, by which they meant that there were “still differences in the shape and position of curves from each sub-sample”, and elected to exclude the data. Clearly there are “differences” between the adjusted curves in every case. There are elementary methods to quantify the difference between two such curves, but no reference is made by Briffa and Melvin to such quantification. Readers will be unsurprised to learn that that the data excluded by Briffa and Melvin as a result of this analysis was the RW data that had yielded the high MWP in the “Polar Urals Update”. But because none of these “adjustments” had statistical criteria, let alone ex ante statistical criteria, the single implementation of this policy to remove data that yielded the inconvenient MWP seems very Calvinball-esque. In the present post however, I am limiting myself to the MXD data; I will try to return to the RW data on a future occasion.
Because there are real differences between sites, there are real allowances that have to be made for inter-site variance. Indeed, one of my issues with Briffa’s original Yamal chronology was its failure to consider inter-site random effects, thereby creating a superblade in which inter-site variance was transferred to the chronology. On the other hand, CRU’s method of accounting for inter-site variance is so unintelligible and so ungrounded in known statistical methodology that it is impossible to know what meaning, if any, can be attributed to any result. This very unintelligibility of Briffa et al 2013 adjustments ought to be viewed even by conventional dendros (including the coauthors of Wilson et al 2016) as a sort of reductio ad absurdum of conventional inter-site adjustments and ought to make dendros aware of the need to place their discipline on more rational footings, a topic that I’ll now turn to.
Tidying Data
One of the first prerequisites of modern data analysis is making the data “tidy” – housekeeping that is emphasized by many R authors (e.g here):

Being tidy is even more important when one is dealing with multiple sites and when one wants to also assess the effect of modern vs subfossil trees or roots vs stems. The baroque profusion of datasets in the Briffa and Melvin analysis is about as untidy as one can imagine.
I organized all of the MXD data into a “tidy” dataset (http://www.climateaudit.info/data/proxy/tree/briffa/2013/collated_polarurals_mxd.csv) in which there is one row for each MXD measurement, also showing on each row, the tree ID, year, age, dataset, site, modern/subfossil, root/stem. Following Briffa and Melvin, when there are multiple cores for a single tree, they were averaged. (There were some gross errors in the Briffa and Melvin purlasim.mxd average – I noticed these because of implausibly high individual MXD values as high as 461. I re-did the averaging of purlasim.mxd in my collation.) My collated data can be read as follows:
loc="http://www.climateaudit.info/data/proxy/tree/briffa/2013/collated_polarurals_mxd.csv" tree=read.csv(loc) dim(tree) #[1] 23444 8
Briffa and Melvin were interested in the following five classes of data: POL modern stem; POL subfossil stem; POL subfossil root; PURLASI (modern stem) and PURLASI_SC (modern stem). Because I have tagged each tree with its site, modern/subfossil and root/stem, these subsets can be readily tagged simply by combining (pasting) the site, modern/subfossil and root/stem labels and taking the combination as a factor. There were exactly five such combinations, with total number of measurements in each factor ranging from 1982 to 8685. The technique is shown below:
tree$alia= paste(tree$site,tree$mod,tree$root,sep="_") tree$alia=factor(tree$alia) table(tree$alia) #148_mod_stem 225_mod_stem pol_mod_stem pol_sf_root pol_sf_stem # 5261 1982 4151 3365 8685
To this data, I fitted a simple mixed effects model in which I used a fixed effects Hugershoff curve (common in tree ring studies) to model the MXD-age structure with a single random effect for each class, used here in preference to a negative exponential. A “Hugershoff” curve, in dendro jargon, is a linear transformation of a gamma function:
A + B* gamma(x,s,a) = A+B* 1/( s^a *gamma(a))* x^(a-1)* exp(- x/s)
The mixed effects model can be constructed in two lines using the R-package nlme, not only vastly simplifying the bewildering Briffa-Melvin flowchart, but doing the analysis in an organized way using methods with known properties and diagnostics. Here’s the formula (I obtained the starting values from an nls model run first).
require(nlme) Tree=groupedData(x~year|id,tree) fm=nlme( x~ A + B* age^D * exp(-C*age), data=Tree, fixed = A+B+C+D ~ 1, random = A~1|alia, start=c(A=72,B=.116, C=.03,D=1.43))
The next figure shows the average MXD for each tree-ring age for the five subsets identified in Briffa and Melvin, together with the fitted curve from the above random effects model. (The heavy black dashed line is the overall fixed effects curve). This technique gives an impressive match to the data, especially for ages less than 170 years: the number of (old) tree ring samples off to the right is small and they do not affect the fit very much. In my opinion, this is rather an impressive match with relatively few moving parts. This match indicates that it is not necessary to vary the B,C and D Hugershoff parameters for each class; random effects for the A parameter should be sufficient (and also necessary). (This observation can be tested more formally.)

Figure 5. Average MXD measurement for each tree ring age for five subsets, together with fit from nlme model. Also shown is fixed effects curve (heavy dashed black).
In my opinion, this diagram is far more informative than the forest of messy Briffa and Melvin diagrams. One can immediately see observable differences between the three modern sites, with the two new Russian sites, especially purlasi-sc (148), running higher than the earlier Schweingruber samples. An important moral: if no allowance is made for the random effect between sites (as is done in the frequently-used one-size-fits-all RCS technique, the inter-site variance between the Schweingruber and 148/225 sites will get incorrectly allocated to the chronology, making it artificially high at the end, a phenomenon that very much appears to have taken place in Briffa’s earlier Yamal chronologies, each of which used one-size-fits-all RCS despite inhomogeneous sites.
Conversely, because average measurement time of these datasets is not identical, variance properly attributable to the chronology can be allocated to inter-site effects. Such transfers are what cause the “segment length curse” in “standard” dendro chronologies. STD chronologies, in effect, allocate a random effect to each core (through the process of separate standardization of each core); this transfers variance from the chronology to inter-tree variance. While the loss of low frequency variability in STD chronologies is well known to dendros, I think that the phenomenon is more rationally explained in random effects terminology. In the next section, I’ll discuss a technique for handling “crossed” random factors to mitigate this.
Tree ring “chronologies” are conventionally calculated by dividing the observed values by the fitted values and then taking an average (or biweight mean) for each year. Conventional statistics are built around residuals (subtraction). While the dendro division convention can be forced to a residual framework by taking logarithms, the chronologies resulting from use of residuals turn out to be very similar to those resulting from division, but have the benefit of an interpretation within known statistics. A residual “chronology” (crn_nlme below) can be calculated in a couple of lines as the average residual for each year:
tree$resid=resid(fm) crn_nlme=crn.nlme=ts( as.numeric( tapply(tree$resid,tree$year,mean)),start=min(tree$year))
The resulting time series of average residuals yields a chronology (bottom panel below) that is almost exactly linear to the Briffa et al MXD chronology (top panel below – from here). Unsurprisingly, given the visual similarity, the correlation of the two versions is very high: 0.982. One large advantage of the approach set out in this post is that the units are residuals in the original MXD scale; they are not “dimensionless” units as in standard chronologies.

Figure 6. Polar Urals MXD chronologies. Top – from Briffa et al 2013 here ; bottom – average residual by year.
The extreme similarity of the two different chronologies (up to an irrelevant for present purposes linear transformation) shows to me that, at the end of the day, the forest of Briffa and Melvin adjustments are more or less equivalent to the calculation of inter-site random effects. The adjustments in this case are not “WRONG!!!”; but, as presented by Briffa and Melvin, they are unintelligible.
One other observation: the calculation of chronologies by averaging of residuals (whether it be through an nlme fit or an RCS fit) allocates too much variance to the annual effect. Some of the residuals result from unfitted variability. I’ll now consider how this issue can be addressed through crossed random effects.
LMER
One way of estimating annual contribution is to treat each year as a factor and then estimate a model with crossed random factors – one of which is the annual effect and one of which could be the five classes identified above. (Or multiple factors.) Or if one wanted to develop STD chronology methods in which each tree was a factor, the crossed factors would be the annual effect and the tree effect. In each case, the fixed effect is a non-linear (Hugershoff) fixed effect plus random effects. Or there cold be multiple random effects.
The R-package lme4 (by the same authors as nlme) is designed to handle crossed random effects. It has a function for non-linear fixed effects combined with crossed random effects, but I haven’t been able to get it to work/converge for this dataset. However, based on considerable experimenting, it appears to me that the nonlinear model can be closely approximated by a linear model in which the Hugershoff parameters C and D are fixed at the values of the nlme model. This simplification fixes the shape of the gamma function, but leaves the linear transformation parameters A, B to be fit in the model. (I’ve done some experiments in which I examined separate optimizations on C and D within a nearby box, but the logLikelihoods of nearby changes are rather slight and there is little impact on the resulting chronology from slight perturbations of C and D.) So for the purposes of this post – which is to focus on crossed random effects – I’ll limit myself to the following linearization of the problem:
require(lme4) tree$yearf=ordered(tree$year) hug= function(x) x^1.12187057*exp(-0.02390783*x)#values from nlme nm= lmer(x~ hug(age)+(1|alia)+(1|yearf),data=tree)
The random effects for the five subsets are similar to the values from the nlme model. The average measurement time of the 225 dataset is in the 20th century (1941), as compared to 1858 for the 148 dataset. Inclusion of a factor for annual effect ends up somewhat increasing the difference between the random effects for these two datasets:

In the next figure below, I’ve plotted the chronology of annual effect (bottom panel – lmer) versus the chronology of average residuals from the nlme model previously calculated. Other than the earliest values, the two series are practically indistinguishable. However, there’s an interesting benefit to the lmer method in the early period where data is sparse. Residual chronology techniques (both conventional and nlme) yield elevated chronology values in the opening period. Dampening variability of sparse periods is a longstanding problem for dendros (who have various ad hoc methods of dealing with it). In the lmer method, much of this early variance is treated as random variance and left with the residuals, thereby damping the variability of the early portion of the chronology.

Figure 7. Comparison of nlme (top) and lmer (bottom) chronologies.
The five classes distinguished by Briffa and Melvin are pasted together from three different factors: site, modern/subfossil and root/stem. The separate contribution of each factor can be estimated as follows:
nm1= lmer(x~ hug(age)+(1|site)+(1|root)+(1|mod)+(1|yearf),data=tree)
The resulting chronology for annual effect is indistinguishable from the previous chronology, with a maximum difference of only 0.0125 – imperceptible on a graph. The resulting random effects for each factor are shown below.

Conclusion
RCS chronologies lack any form of statistical theory for their decisions to adjust or not adjust for varying sites. This results in ad hoc decision making by practising dendros that all too frequently is indistinguishable from Calvinball – a form of Calvinball in which the objective is to get a HS. The Briffa 2013 MXD chronology, though lacking a distinctive HS shape, is nonetheless the produce of an unintelligible and bizarrely complicated series of adjustments. Ironically, these adjustments produce a chronology that is functionally indistinguishable from a chronology of annual effects produced from a random effects model – further supporting the longstanding Climate Audit thesis that analysis of tree ring data ought to be done within the framework of random effects statistics.
The Polar Urals MXD chronology itself – in any of its guises – obviously lacks the distinctive HS shape of the ultimate Wilson et al 2016 composite. While specialists increasingly suggest that MXD chronologies are a better guide to temperature variation than RW chronologies, the Polar Urals MXD chronology doesn’t have as much low-frequency variance as one would expect from such an extreme location. Shiyatov and associates (e.g. CA here) have reported dramatic changes in Polar Urals treeline over the past millennium. In an earlier discussion of Briffa et al 2013, I criticized them for their abject failure to consider the effect of changing altitudes, which they cursorily dismissed as follows:
We have not investigated the influence of sample elevation on the absolute magnitude of tree growth or made any allowance for such differences in our analysis, but this may not be a very significant factor (Briffa et al., 1996).
Mazepa et al 2011 reported a lowering of treeline of ~150 m from the MWP to the late 19th century. To the extent that the trees followed the treeline, MXD values would be damped relative to temperature changes.





15 Comments
Nice analysis. It’s surprising that you’ve had no offers to co-author a paper.
Edit needed:
“whe (used only in Esper et al 2002, from which the middle panel), whereas”
I think, SteveM is pointing to other ex post facto decisions for exclusions of proxy series from temperature reconstructions based on finding a reason to exclude that is not based on any standards and as such appear arbitrary and not consistently used. This practice should not be unexpected. Think for a moment if the criteria for selection were made a prior and all proxy data selected were used. None of these apparent arbitrary decisions would be allowed or used. I think this in the vain that SteveM is calling for some discipline in the dendro field.
It must pretty quite in the forests where dendro work is done so I am perplexed why there would be so many deaf ears in that field.
“When the green dark forest was too silent to be real…”
“…I placed quotation marks around Polar Urals in the opening graphic, because the ‘Polar Urals’ series of D’Arrigo et al 2006 was actually Briffa’s notorious Yamal series, incorrectly identified. I pointed out the erroneous identification to the D’Arrigo authors long ago, but, for reasons that remain obscure, they refused to issue a correction…”
Well at least they didn’t call your demonstrable claim of error to be “bizarre” in Mannian fashion.
With these sorts of ingredients, I am concerned that D’Arrigo’s cherry pie might be peach pie instead.
For the 2016 article there are some cherry-juicy data sets among the few that go up to 2010 and 2011. Q, Y, and AG show a remarkable surge of growth from about 2005 onward, like tree-ring ringers.
The article itself has an implicit bragging element by which it compares itself to the 20th c. results of the Mann08 EIV, and how much better it does so than other competitors. Indeed, Wilson et al. 2016 remarkably emulates the mid-20th c. temp drop that arose in the 2000’s versions of Mannian hockey stick blades. Well Done!!
With these sorts of ingredients, I am concerned that D’Arrigo’s cherry pie might be peach pie instead.
IMHO – Cherry pie needs a lot of sugar to overtake the sour cherry taste, peach pie is naturally sweet.
Steve,
Are you leading to a suggestion that a more comprehensive analysis available to dendro researchers could come from adding to this type of random effects model, going to a mixed effects model with parameters such as altitude, rainfall, season, etc? Or is that a bridge too far?
Geoff
Steve: different animal. I’m not saying that the chronology of annual random effects necessarily means anything. Only a “chronology” in fact is the random effect associated with each year. This becomes more of an issue when one looks at various RCS methods where odd decisions are about about one-size-fits-all or the opposite.
Apologies. Shot from the hip again. There is a lot to understand in your essay. Geoff.
It’s not science but trees are not involved.

How did Wilson get such divergence in their latest production, given his stated desire to screen based on correlation to temperatures?
Steve:
a stupid question:
I count 183 individuals tree cores…
The sum of the invivdual sample sizes of four time series at the top of the flow chart you so kindly reproduced…
The total number of samples in the data( polar, and polarxs) used is 264 trees.
Any idea of which trees were more popular than others?
For example it appears that Pou_la_stem contributes to both polar and polarxs….
geez….
I may have missed it, but is there a link or a complete reference to “Wilson et al 2016” to enable the paper itself to be read?
Martin: https://ntrenddendro.wordpress.com/tr-data/
However, I do not think the gravamen of M’s piece here is the 2016 article, but rather flows from earlier Briffa and D’arrigo products. Wilson et al 2016 sets forth “Yamal” data from Briffa 2013, and separate “Polar Urals” from Schneider et al. 2015. Different geographic coordinates are stated for the trees in Briffa and Schneider.
FtM – thank you.
One Trackback
[…] Return to Polar Urals: Wilson et al 2016 By Steve McIntyre, Climate Audit, Feb 8, 2016 https://climateaudit.org/2016/02/08/… “The Briffa 2013 MXD chronology, though lacking a distinctive HS [Hockey-Stick] shape, is […]