Carl Wunsch has an interesting new preprint entitled: Abrupt climate change. An alternate view at his website. Continue reading →
On Tim Lambert’s weblog, our regular correspondent per was making interesting points on the R2 statistic in the thread called "McIntyre’s Irrational Demands" when suddenly // all// some [updated – SM ] of per’s comments vanished.
Was it Spam Karma or just per’s karma?
To be fair, Spam Karma has reacted strangely to some people’s posts on this weblog and both Steve and I have had to retrieve posts that got sent to hell erroneously. I assume that as time goes on, Spam Karma will learn not to mark down posts just because they’re complimentary.
There’s obviously an innocent explanation for these things.
Update(Steve ): I’ve asked people to shut this topic down and flame elsewhere. Continue reading →
I’ve been knuckling down to finishing off an article on the multiproxy study, Jones et al [1998], used in all the spaghetti diagrams. This is not robust to the Polar Urals reconstruction and a discussion of the Polar Urals site has taken on a life of its own. Many of the topics are familiar from posts earlier this year. As a spot-check of the 2005 HadCRU2 edition and the 2005 CRUTEM2 edition, I compared the gridcell series from these editions at the Polar Urals location (lat 66N, long 66E). I also compared results from the older dataset ndp020, which was either used in the Polar Urals study (or a variant edition from the same vintage) and the dataset supposedly used in MBH98 (archived in July 2004 at the Corrigendum SI at Nature). Most of the values were identical between the 2005 HadCRU and 2005 CRUTEM series, but there were 60 values which differed. The 2005 HadCRU and 2003 HadCRU series were identical where they overlapped. I’ve collated the set of differing values here. It’s a tab-separated text file and will open in Excel or R (among others). A script for doing the collation is here, but it requires prior collation of all 5 temperature datasets into R tables – which is worth doing for anyone researching specific gridcells. The time taken to set up the data in an organized way gets paid back quickly.
I’ve just updated my HADCRU2 dataset and, for good measure, also the current edition of CRUTEM2. I’ve updated my scripts and, for those brave souls that want their very own copy of HADCRU2 or CRUTEM2 in R format, I’ve posted up scripts to make R tables organized like time series usually are, with each column being a gridcell time series. I’ll post up some utilities as well for locating a gridcell-column from lat-long coordinates and the inverse and some plotting layouts that I’ve been using recently. Continue reading →
The reason for looking at the form of stochastic process that bests suits the gridcell (and hemispheric) temperatures is that the statistical behavior of a random walk (one type of stochastic process) is very different than independent draw from a normal process. Continue reading →
Here are plots of the autocorrelation functions and time series for the 17 gridcells with the highest AR1 coefficients in an ARMA (1,1) model. The locations and patterns are a little curious. Continue reading →
Here is a plot of ARMA (1,1) coefficients for the CRU data set plotted up against a world map. I ‘ve not seen anything like this plotted up before. I think that the patterns are really quite pretty.
Continue reading →
I tested some cells which were outliers under the ARMA(1,1) model. Here’s the result of the first cell that I looked at: the top panel shows the ACF – which has an unusual structure to say the least. The temperature anomaly plot is shown in the second panel and is also unusual to say the least.
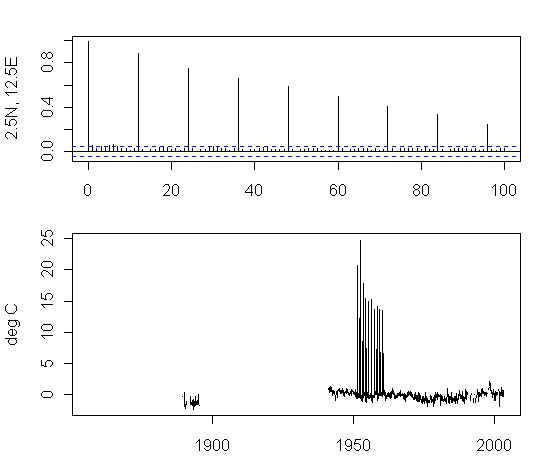 Continue reading →
Continue reading →
We’ll reach 500,000 hits tomorrow (Aug. 14, 2005) since start of this blog on February 8, 2005. Traffic in July was nearly 130,000 hits. There are obviously a lot more visitors than people who post comments. If you’re someone that does visit the site, but who doesn’t feel comfortable posting comments on technical topics, I’d welcome you using this post as a type of guest book, if you’re comfortable doing so.
Here are the top ten most read posts:
1. Some Thoughts on Disclosure and Due Diligence in Climate Science
2. Other Multiproxy Studies
3. Wahl and Amman #2
4. "We cannot make claims as to the 1990s being the warmest decade."
5. Bring the Proxies Up to Date!!
6. Blogs on Barton Letters
7. Sci-Am: Mann and the Hockey Stick
8. Climate: Geological Views #1
9. Lost Cedars #2
10. McKitrick: What the Hockey Stick Debate is About?
I did an ARMA (1,1) on the CRU monthly (as opposed to the usual annual) global data set to see what it looked like. The ARMA (1,1) coefficients for the GL data for the second half of the data set were similar to those observed in the satellite data (AR1 +0.93; MA1 -0.46), but were different in the first half (AR1 +0.71; MA1 -0.27). The "look" of the persistence in the 19th century was quite a bit different than in the 20th century. I don’t see why the ARMA(1,1) structure should change with increased temperatures or increased CO2 and I wonder how much of this is due to measurement issues. It may be an interesting quality control cross-classification.
Here’s another interesting calculation – the AR1 and MA1 coefficients for all CRU gridcells by gridcell (this is from the July 2003 CRU dataset). There seems to be a strong ARMA (1,1) structure to the underlying temperature data(whatever the basis) – it seems plausible that ARMA (1,1) outliers would be an interesting form of quality control on the CRU data set: I wonder what causes the outliers, which are obviously more prevalent in higher latitudes. I can see weakening of the AMRA(1,1) structure away from the tropics, but negative AR1 coefficients are surprising.

Figure 1. ARMA (1,1) Model for CRU Gridcell Temperature Data By Latitude. Top: AR1 Coefficient; Bottom – MA1 Coefficient.





