Lucia has written an interesting post – see here, continuing the effort to figure out the Santer brainteaser.
I can shed a little more light (I think) on what Santer’s “S.D” is in operational terms. I was able to replicate Santer’s Table III values using the line item from Table 1 entitled “Inter-model_S.D._T2LT” which is shown in column 1 (“Trend”) as being 0.092. So this number – whatever it is – is the one that is used as the other component of the denominator in his t-test.
Santer did not archive the 49 time series as used and thus far has not responded to my request for this data.
The caption to Santer Table 1 says:
The multimodel mean and inter-model standard deviation were calculated using the ensemble-mean values of the time series statistics for the 19 models [see Equations (7)–(9)].
Now there is a bit of helpful information in Douglass Table 1, which provides ensemble-mean values for 22 models – I haven’t checked to see which models are different. Douglass Table 1 provides model ensemble trends by altitude, but not weighted according to T2LT weights. John Christy sent me weights by email and I calculated T2LT trends according to these weights as follows:
douglass=read.table(“http://data.climateaudit.org/data/models/douglass.dat”,header=TRUE,sep=”\t”)
name1=names(douglass)[4:15]
alt=as.numeric(substr(name1,2,nchar(name1)))
douglass[,3:15]=douglass[,3:15]/1000 #converts to deg C/decadechristy.weights= c(0.1426, 0.0706, 0.1498, 0.1894, 0.1548, 0.1382, 0.1035,
0.0477, 0.0167, 0.0067, -0.0016, -0.0179) ##CHRISTY WEIGHTS email Apr 30 2008
names(christy.weights)=alt
douglass$trend_LT= apply(douglass[,c(3,5:15)],1,function(x) weighted.mean(x,christy.weights) );
douglass$trend_LT
# 1] 0.176 0.131 0.427 0.144 0.268 0.212 0.141 0.093 0.175 0.245 0.337
sd(douglass$trend_LT) #[1] 0.0913
The standard deviation of 0.0913 from this calculation compares nicely with the value of 0.092 in Santer Table 1 for UAH_T2LT, so it looks like this is apples and apples.
In the subsequent t-calculation for Table III, Santer (like Douglass) divides this number by sqrt(M-1), where M is the number of models, yielding a value of 0.02152. So Santer, like Douglass, in effect proceeds on the basis that the 95% CI envelope for the ensemble mean trend is 0.171- 0.257 deg C/decade. The majority of individual models are above 0.171 deg C/decade.
Now here’s a quick simulation that implements what I believe to be a fairly reasonable interpretation of what should be done (considering the sorts of points that beaker and others have made).
First I assumed that the ensemble mean was the true trend; I centered everything at their midpoints and then calculated residuals from the observed values. I then did an arima AR1 fit to the residuals getting an AR1 coefficient of 0.89 – a little higher than with a better fit and a sd of a little over 0.14 (deg C/decade). I then did 1000 simulations in which I generated AR1 “noise” with parameters of AR1= 0.89 and sd=0.141, added the AR1 noise to the ensemble mean trend ( a straight line), calculated the OLS trend for each run and made a histogram as shown below, also showing the observed OLS trend as a red triangle and the 2.5% and 5% percentiles. The observed OLS trend is outside both percentiles.

Histogram of OLS Trends adding AR1 noise (AR1=0.89, sd=0.141) to ensemble mean trend
Next, I did the same thing assuming a trend of 0.17 (the lower limit of CI interval on ensemble means) and a level that picks up a few important individual models. In this case, the observed OLS trend is outside the 5% percentile, but inside the 2.5 % percentile.

Suppose that Santer now says in Mannian tones: you are “wrong”!!!! You haven’t allowed for uncertainty in the observations. Haven’t you read about the uncertainty attached to an OLS trend in the presence of autocorrelation?
But haven’t we already dealt with that by generating this type of “noise” in our simulations. Aside from the big problem between RSS and UAH, we know what the observed OLS trend and the AR1-type uncertainty does not enter into this calculation. We compare one OLS trend to the distribution of OLS trends generated by our simulation.
And BTW, I sure don’t get why this has to get to a 5% or even 2.5% level of significance before practitioners concede that something needs to be re-tuned. This isn’t really a Popperian falsification problem and that way of thinking probably makes this over-dramatic. This is more like an engineering problem. Ask yourself – would a reasonable engineer in a chemical factory wait until his model got into this sort of red zone or would he take steps when signs of bias started showing up.
Which takes us back to UAH vs RSS. That’s the $64 question. If RSS is right, the modelers don;t have a problem; if UAH are right, they do. The UAH-RSS differences still need to be resolved and the failure of the climate science community to resolve this leaves the modelers in an unreasonable situation. If I were running the show, I’d say that the parties had had long enough to resolve the situation by lobbing grenades at one another in the academic literature, where nothing is really getting resolved. (They might as well be writing blog articles.) I would hire third party engineers, give them a proper budget and ask them to resolve the matter.
Not a pro bono winging effort, but a proper engineering study so that modelers would have a benchmark. I agree that Santer had cause to criticize the statistics in Douglass, but that doesn’t mean that Santer’s own analysis was necessarily right. It’s possible for both sides to have done things wrong. In terms of conclusions, I think that both Santer et al and the predecessor CCSP report, in effect, distract people from the need to finally resolve UAH v RSS by purporting to paper over real differences with what turns out to be less than adequate statistical analysis.





22 Comments
Something seems to be missing in the following sentence:
I’ve put [?] where I think something is missing.
My undestanding RSS uses GCMs to calculate the adjustments required to correct for satellite drift. This would imply that the RSS data is not truely independent of the assumptions built into the models and cannot be reasonably used to demonstrate that the models are correct.
Steve,
How about something pretty simple (radical?) like a well instrumented G5 flying around at set altitudes/pressures in sync with TOB from the Sats and the calibrating to a good set of observations? New and improved balloon radiosondes might be cheaper, but they don’t serve Starbucks in the balloon. Can Laurie David donate the use of her jet?
Re: hswiseman (#3), A novel application of the starbucks principle, for sure.
Does this RSS vs UAH problem apply if the data is updated to 2008? The difference between average 2008 figures for RSS and UAH is only 0.06 degrees C. I get a 29.8-year trend of 0.17 degrees perdecade for RSS and 0.13 degrees per decade for UAH. Does this really make or break the analysis?
(The 1979-1999 trends were 0.17 for RSS and 0.10 for UAH, so the difference is declining.)
I can’t see why RSS vs UAH is a live issue. It seems crystal clear that the RSS data has a step function in its sequence about 1993 that doesn’t match any other data series and this generated the trend difference which is gradually getting washed out as the sequence becomes longer.
Can’t we apply common sense and stop worrying about nothing? When someone gives a convincing explanation for the RSS step we can reconsider. Till then forget it.
This is an extremely interesting development

Look closely. Has this ever happened? Hint:Iceland
Steve: c’mon. there are sea ice threads. How hard is it to find ont?
Tammy has a thread of sorts started on UAh and RSS. no code or anything that allows you to check his excel spreadsheets. He’s made a couple claims in favor of RSS, but appears to be back pedaling a bit, no harm in that. Might be worth a look
Re: steven mosher (#8),
FWIW Christy and Douglass have this paper (http://arxiv.org/pdf/0809.0581v1 ) where appendix A, which is almost half the paper, discusses RSS vs UAH. I should note that I came across this via the Tamino post you refer to – http://tamino.wordpress.com/2008/10/21/rss-and-uah/ – where in the update he very clearly states that RSS cocked up in the 1992/3 era:
re 9. yes, that “withdrawl” is what I refer to as backpeddling.
I have a question which I hope you can answer: All these atmospheric temperature data reported to 0.001 centigrade degree–are they really that accurate? That’s hard for me to swallow–in fact, even to 0.01 degree. If–and it is an “if”–the data are not accurate to that amount of significance, then it is meaningless to report statistical analyses to that significance. Can anyone recommend a paper dealing with this issue?
Bill, I presume the answer is that these are not measurements, they are “averages” of measurements. An average can be more precise than any individual observation.
Ok, Beaker, how does Steve’s analysis in this thread look to you?
Re: craig loehle (#13),
I think beaker was sucked through a wormhole into a parallel universe around the time he posited that Santer et. al. contained a typo. He might be having some trouble posting from there.
I’m having difficulty understanding why so much emphasis is being placed on the satellite data (RSS and UAH) when the radiosonde data:
(a) is less prone to the inhomogenization problem,
(b) gives better altitude resolution and clarity
(c) is available from a larger number of independent mesurements.
What am I missing?
Hmmm, this problem should be translated to a test about prediction interval for a single future observation. Or tolerance interval, for Bayesians it doesn’t make a difference 😉
The interesting point is that AR(1) with p of about 0.9 is suddenly accepted for ‘climate noise’. Mann & Lees 96 paper told us that such value would be unphysical. The problem is, you need high p to keep AGW running even if the temperatures go down. On the other hand, you need low p to be able to say ‘one cannot simulate the evolution of the climate over last 30 years without including in the simulations mankind’s influence on sulfate aerosols and greenhouse gases.’
Re: UC (#15),
Did someone actually say that weather with AR(1) and lag 1 autocorrelation of 0.9 is reasonable?
If you were to run AR(1) simulations with this lag 1 autocorrelation, the autocorrelation for observataions of GMST since GMST would be highly unlikely. Highly.. Heck, if “weahter noise” is AR(1) with autocorrelation of 0.728, there’s only a 1.7% chance of getting lag 1 autocorrelations as low as we’ve gotten since 2001.
You can read a bit about the analysis here.
The autocorrealtions are higher during periods when volcanos like Pinatubo and El Chicon are going off. Otherwise… well… The observational evidence suggests it’s lower.
Re: lucia (#18),
I get that impression from Santer17. Confusing stuff, just some time ago someone told us that The conclusion is inescapable, that global temperature cannot be adequately modeled as a linear trend plus AR(1) process.
Steve RE:Sea ice posting above not correct thread here etc… tried your sea ice stretch # 3 to put comment there are 1034 comments ice version #3 and it ends… so not possible unless sea ice stretch version 4? thanks for advice
I have to back to basics to get an idea what is going on in Santer17, and SD vs. SE debate.
Let’s take two samples of size and
and  , compute sample means and variances,
, compute sample means and variances,  ,
,  and
and  ,
, 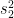 . If these are from same distribution, the statistic
. If these are from same distribution, the statistic
(where ), follows a Student’s t with
), follows a Student’s t with  dof. If
dof. If 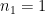 , this simplifies to
, this simplifies to
This test is more SE like than SD. But when you turn this to as prediction interval for one future sample ( ), you’ll get
), you’ll get
and I think test based on this or y in the above is more or less the same thing. Proof is left to the reader, though 😉 This is more SD-like test, specially if is large.
is large.
In Santer17, the variances seem to be different for those two samples, so the situation gets more complicated. And it is a bit unclear to me how sample deviations are obtained in H2 case.
No one objected, so we can conclude that this two sample t-test with SEs turns to prediction interval SD test in the case of equal variances (one future observation ). Douglass and Santer are testing trends instead of means, so degrees of freedom need to be corrected accordingly. In addition, variances are not assumed equal, so dof question gets even more complicated (see for example http://www.itl.nist.gov/div898/handbook/eda/section3/eda353.htm )
Douglass et al assume that observed b_o is the true trend, and in this case one-sample t-test can be performed. With large n_2, t-distribution approaches rapidly normal d., and the 95 % confidence interval for the trend would be
Length of this interval approaches zero as n_2 gets larger, but there is nothing special about that. That’s what should happen under this assumption.
Something that I don’t understand at all is why models that clearly do not reproduce the temperature profile in the troposphere/stratosphere are included in long-term forecasts? Even if you use RSS data instead of UAH, many individual model runs fall well outside the RSS data. Shouldn’t the observational data provide a constraint on which model runs can be included in the ensemble for forecasting? And if those model runs that fall outside the RSS data are excluded, what does that do to the 100-yr forecast and uncertainty? How can you justify including model runs that produce unphysical results simply because the resulting ensemble mean uncertainty happens to lie within the observational uncertainty?
2 Trackbacks
[…] into Matlab and computed area-weighted averages for the first 12 pressure levels. Steve M. reports here the T2LT weights by altitude via Christy. I multiplied the 12 time series by their respective […]
[…] M reported T2LT weights from John Christy that are entirely pressure level specific. The weights however correspond only […]