 In my most recent post, I discussed yet another incident in the long running dispute about the inconsistency between models and observations in the tropical troposphere – Gavin Schmidt’s twitter mugging of John Christy and Judy Curry. Included in Schmidt’s exchange with Curry was a diagram with a histogram of model runs. In today’s post, I’ll parse the diagram presented to Curry, first discussing the effect of some sleight-of-hand and then showing that Schmidt’s diagram, after removing the sleight-of-hand and when read by someone familiar with statistical distributions, confirms Christy rather than contradicting him.
In my most recent post, I discussed yet another incident in the long running dispute about the inconsistency between models and observations in the tropical troposphere – Gavin Schmidt’s twitter mugging of John Christy and Judy Curry. Included in Schmidt’s exchange with Curry was a diagram with a histogram of model runs. In today’s post, I’ll parse the diagram presented to Curry, first discussing the effect of some sleight-of-hand and then showing that Schmidt’s diagram, after removing the sleight-of-hand and when read by someone familiar with statistical distributions, confirms Christy rather than contradicting him.
Background
The proximate cause of Schmidt’s bilious tweets was Curry’s proposed use of the tropical troposphere spaghetti graph from Christy’s more recent congressional testimony in her planned presentation to NARUC.  In that testimony, Christy had reported that “models over-warm the tropical atmosphere by a factor of approximately 3, (Models +0.265, Satellites +0.095, Balloons +0.073 °C/decade)”
In that testimony, Christy had reported that “models over-warm the tropical atmosphere by a factor of approximately 3, (Models +0.265, Satellites +0.095, Balloons +0.073 °C/decade)”
The Christy diagram has long been criticized by warmist blogs for its baseline – an allegation that I examined in my most recent post, in which I showed that baselining as set out by Schmidt and/or Verheggen was guilty of the very offences of Schmidt’s accusation and that, ironically, Christy’s nemesis, Carl Mears, had used a nearly identical baseline, but had not been excoriated by Schmidt or others.
I had focused first on baselining, because that had been the main issue at warmist blogs relating to the Christy diagram. However, in twitter followup to my post, Schmidt pretended not to recognize the baselining issue, instead saying that the issue was merely “uncertainties”, but did not expand on exactly how “uncertainties” discomfited the Christy graphic. Even though I had shown that Christy’s baselining was equivalent to Carl Mears’, Schmidt refused to disassociate himself from Verheggen’s offensive accusations.
One clue to Schmidt’s invocation of “uncertainties” comes from the histogram diagram which he proposed to Judy Curry, shown below. This diagram was accompanied by a diagram, which represented the spaghetti distribution of model runs as a grey envelope – an iconographical technique that I will discuss on another occasion. The diagram consisted of two main elements: (1) a histogram of the 102 CMIP5 runs (32 models); (2) five line segments, each representing the confidence intervals for five different satellite measurements.

Schmidt did not provide a statistical interpretation or commentary on this graphic, apparently thinking that the diagram somehow refuted Christy on its face. However, it does nothing of the sort. CA reader JamesG characterized it as “the daft argument that because the obs uncertainties clip the model uncertainties then the models ain’t so bad.” In fact, to anyone with a grounded understanding of joint statistical distributions, Schmidt’s diagram actually supports Christy’s claim of inconsistency.
TRP vs GLB Troposphere
Alert readers may have already noticed that whereas the Christy figure in controversy depicted trends in the tropical troposphere – a zone that has long been especially in dispute, Schmidt’s histogram depicts trends in the global troposphere.
In the figure below, I’ve closely emulated Schmidt’s diagram and shown the effect of the difference. In the left panel, I’ve shown the Schmidt histogram (GLB TMT) with horizontal and vertical axes transposed for graphical convenience. The second panel shows my emulation of the Schmidt diagram using GLB TMT (mid-troposphere) from CMIP5. The third and fourth panels show identically constructed diagrams for tropical TMT and tropical TLT (lower troposphere), each derived from the Christy compilation of 102 CMIP5 runs (also, I believe, used by Schmidt.) Discussion below the figure.

Figure 1. Histograms of 1979-2015 trends versus satellite observations. Left – Gavin Schmidt; second panel – GLB TMT; third panel – TRP TMT; fourth panel: TRP TLT. The black triangle shows average of model runs. All calculated from annualized data.
The histograms and observations in panels 2-4 were all calculated from annualizations of monthly data (following indications of Schmidt’s method.) The resulting panel for Global TMT (second panel) corresponds reasonably to the Schmidt diagram, though there are some puzzling differences of detail. The lengths of the line segments for each satellite observation series were calculated as the standard error of the trend coefficient using OLS on annualized data, closely replicating the Schmidt segments (and corresponding to information from a Schmidt tweet.) This yields higher uncertainty than the same calculation on monthly data, but less than assuming AR1 errors with monthly data. The confidence intervals are also somewhat larger than the corresponding confidence intervals in the RSS simulations of structural uncertainty, a detail that I can discuss on another occasion.
In the third panel, I did the same calculation with tropical (TRP) TMT data, thus corresponding to the Christy diagram with which Schmidt had taken offence. The trends in this panel are noticeably higher than for the GLB panel (this is the well known “hot spot” in models of the tropical troposphere). In my own previous discussions of this topic, I’ve considered the lower troposphere (TLT) rather than mid-troposphere and, for consistency, I’ve shown this in the right panel. Tropical TLT in models run slightly warmer than tropical TMT model runs, but only a little. In each case, I’ve extracted available satellite data. Tropical TLT data from RSS 4.0 and NOAA is not yet available (and thus not shown in the fourth panel.)
The average tropical TMT model trend was 0.275 deg C/decade, about 30% higher than the corresponding GLB trend (0.211 deg C/decade), shown in the Schmidt diagram. The difference between the mean of the model runs and observations was about 55% higher in the tropical diagram than in the GLB diagram.
So Schmidt’s use of the global mid-troposphere shown in his initial tweet to Curry had the effect of materially reducing the discrepancy. Update (May 6): In a later tweet, Schmidt additionally showed the corresponding graphic for tropical TMT. I’ll update this post to reflect this.

The Model Mean: Back to Santer et al 2008
In response to my initial post about baselining, Chris Colose purported to defend Schmidt (tweet) stating:
“re-baselining is not the only issues. large obs uncertainty, model mean not appropriate, etc.”
I hadn’t said that “re-baselining” was the “only” issue. I had opened with it as an issue because it had been the most prominent in warmist critiques and had occasioned offensive allegations, originally from Verheggen, but repeated recently by others. So I thought that it was important to take it off the table. I invited Gavin Schmidt to disassociate himself from Verheggen’s unwarranted accusations about re-baselining, but Schmidt refused.
Colose’s assertion that the “model mean [is] not appropriate” ought to raise questions, since differences in means are assessed all the time in all branches of science. Ironically, a comparison of observations to the model mean was one of the key comparisons in Santer et al 2008, of which Schmidt was a co-author. So Santer, Schmidt et al had no issue at the time with the principle of comparing observations to the model mean. Unfortunately (as Ross and I observed in a contemporary submission), Santer et al used obsolete data (ending in 1999) and their results (purporting to show no statistically significant difference) were invalid using then up-to-date data. (The results are even more offside with the addition of data to the present.)
For their comparison of the difference between means, Santer et al used a t-statistic, in which their formula for the standard error of the model mean was the standard deviation of the model trends by the square root of the number of models (highlighted). I show this formula since Schmidt and others had argued vehemently against inclusion of the n_m divisor for number of models.

The above formula for the standard error of the model, as Santer himself realized – mentioning the point in several Climategate emails, was identical to that used in Douglass et al 2008. Their formula differed from Douglass et al in the other term of the denominator – the standard error of observations s{b_o}.
In December 2007, Santer et al 2008 coauthor Schmidt had ridiculed this formula for the standard error of models as an “egregious error”, claiming that division of the standard deviation by the (square root of ) the number of models resulted in the “absurd” situation where some runs contributing to the model mean were outside the confidence interval for the model mean.

Schmidt’s December 2007 post relied on rhetoric rather than statistical references and his argument was not adopted in Santer et al 2008, which divided the standard deviation by the square root of the number of models.
Schmidt’s December 2007 argument caused some confusion in October 2008 when Santer et al 2008 was released, on which thus far undiscussed Climategate emails shed interesting light. Gavin Cawley, commenting at Lucia’s and Climate Audit in October 2008 as “beaker”, was so persuaded by Schmidt’s December 2007 post that he argued that there must have been a misprint in Santer et al 2008. Cawley purported to justify his claimed misprint with a variety of arid arguments that made little sense to either me or Lucia. We lost interest in Cawley’s arguments once we were able to verify from tables in Santer et al 2008 that there was no misprint and were able to establish that Santer et al 2008 had used the same formula for standard error of models as Douglass et al (differing, as noted above, in the term for standard error of observations.)
Cawley pursued the matter in emails to Santer that later became part of the Climategate record. Cawley pointed to Schmidt’s earlier post at Real Climate and asked Santer whether there was a misprint in Santer et al 2008. Santer forwarded Cawley’s inquiry to Tom Wigley, who told Santer that Schmidt’s Real Climate article was “simply wrong” and warned Santer that Schmidt was “not a statistician” – points on which a broad consensus could undoubtedly have been achieved. Unfortunately, Wigley never went public with his rejection of Schmidt’s statistical claims, which remain uncorrected to this day. Santer reverted back to Cawley that the formula in the article was correct and was conventional statistics, citing von Storch and Zwiers as authority. Although Cawley had been very vehement in his challenges to Lucia and myself, he did not close the circle when he heard back from Santer, conceding that Lucia and I had been correct in our interpretation.
Bayesian vs Frequentist
In recent statistical commentary, there has been a very consistent movement to de-emphasize “statistical significance” as a sort of talisman of scientific validity, while increasing emphasis on descriptive statistics and showing distributions – a move that is associated with the increasing prominence of Bayesianism and something that is much easier with modern computers. As someone who treats data very descriptively, I’m comfortable with the movement.
Rather than worry about whether something is “statistically significant”, the more modern approach is to look at its “posterior distribution”. Andrew Gelman’s text (Applied Bayesian Analysis, p 95) specifically recommended this in connection with difference in means:
In problems involving a continuous parameter θ (say the difference between two means), the hypothesis that θ is exactly zero is rarely reasonable, and it is of more interest to estimate a posterior distribution or a corresponding interval estimate of θ. For a continuous parameter θ, the question ‘Does θ equal 0?’ can generally be rephrased more usefully as ‘What is the posterior distribution for θ? (text, p 95)
In the diagram below, I show how the information in a Schmidt-style histogram can be translated into a posterior distribution, and why such a distribution is helpful and relevant to someone trying to understand the data in a practical way. The techniques below do not use full Bayesian apparatus of MCMC simulations (which I have not mastered), but I would be astonished if such technique would result in any material difference. (I’m somewhat reassured that this was my very first instinct when confronted with this issue: see October 2008 CA post here and Postscript below.)
On the left, I’ve shown the Schmidt-style diagram for tropical TMT (third panel above). In the middle, I’ve shown approximate distributions for model runs (pink) and observations (light blue) – explained below, and in the right panel, the distribution of the difference between model mean and observations. From the diagram in the right panel, one can draw conclusions about the t-statistic for the difference in means, but, for me, the picture is more meaningful than a t-statistic.

Figure 2. Tropical TMT trends. Left – As in third panel of Figure 1. Middle. pink: distribution of model trends corresponding to histogram; lightblue: implied distribution of observed trends. Right: distribution of difference of model and observed trends. In the data used in panel three above (TRP TMT), I got indistinguishable results (models +0.272 deg C/decade; satellites +0.095 deg C/decade).
The left panel histogram of trends for tropical TMT is derived from the Christy collation (also used by Schmidt) of the 102 CMIP5 runs (with taz) at KNMI. The line segments represent 95% confidence intervals for five satellite series based on the method used in Schmidt’s diagram (see Figure 1 for color code).
In the middle panel, I’ve used normal distributions for the approximations, since their properties are tractable, but the results of this post would apply for other distributions as well. For models, I’ve used the mean and standard deviation of the 102 CMIP5 runs (0.272 and 0.058 deg C/decade, respectively). For observations, I presumed that each satellite was associated with a normal distribution with the standard deviation being the standard error of the trend coefficient in the regression calculation; for each of the five series, I simulated 1000 realizations. From the composite of 5000 realizations, I calculated the mean and standard deviation (0.095 and 0.049 deg C/decade respectively) and used that for the normal distribution for observations shown in light blue. There are other reasonable ways of doing this, but this seemed to me to be the most consistent with Schmidt’s graphic. Note that this technique yields a somewhat wider envelope than the envelope of realizations representing structural uncertainty in the RSS ensemble.
In the right panel, I’ve shown the distribution of the difference of means, calculated following Jaynes’ formula (discussed at CA previously here). In an analysis following Jaynes’ technique, the issue is not whether the difference in means was “statistically significant”, but assessing the odds/probability that a draw from models would be higher than a draw from observations, fully accounting for uncertainties of both, calculated according to the following formula from Jaynes:

By specifying the two distributions in the middle panel as normal distributions, the distribution of the difference of means is also normal, with its mean being the difference between the two means and the standard deviation being the square root of the sum of squares of the two standard deviations in the middle panel ( mean 0.177 and sd 0.076 deg C/decade respectively). For more complicated distributions, the distribution could be calculated using simulations to effect the integration.
Conclusion
In the present case, from the distribution in the right panel:
- a model run will be warmer than an observed trend more than 99.5% of the time;
- will be warmer than an observed trend by more than 0.1 deg C/decade approximately 88% of the time;
- and will be warmer than an observed trend by more than 0.2 deg C/decade more than 41% of the time.
These values demonstrate a very substantial warm bias in models, as reported by Christy, a bias which cannot be dismissed by mere arm-waving about “uncertainties” in Schmidt style. As an editorial comment about why the “uncertainties” have a relatively negligible impact on “bias”: it is important to recognize that the uncertainties work in both directions, a trivial point seemingly neglected in Schmidt’s “daft argument”. Schmidt’s “argument” relied almost entirely on the rhetorical impact of the upper tail of the observation distributions nicking the lower tail of the model distributions. But the wider upper tail is accompanied by a wider lower tail and, for these measurements, the discrepancy is even larger than the mean discrepancy.
Unsurprisingly, using up-to-date data, the t-test used in Santer et al 2008 is even more offside than it was in early 2009. The t-value under Santer’s equation 12 is 3.835, far outside usual confidence limits. Ironically, it fails even using the incorrect formula for standard error of models, which Schmidt had previously advocated.
The bottom line is that Schmidt’s diagram does not contradict Christy after all, and, totally fails to support Schmidt’s charges that Christy’s diagram was “partisan”.
Postscript
As a small postscript, I am somewhat pleased to observe that my very first instinct, when confronted by the data in dispute in Santer et al 2008, was to calculate a sort of posterior distribution, albeit in a somewhat homemade method – see October 2008 CA post here.
In that post, I calculated a histogram of model trends used in Douglass et al (tropical TLT to end 2004, as I recall – I’ll check what I did). Note that the model mean (and overall distribution) at that time was considerably less than the model mean (and envelope) to the end of 2015. When one squints at the models in detail, they tend to accelerate in the 21st century. I had then calculated the proportion of models with greater trend than observations for values between -0.3 and 0.4 deg C/decade (a different format than the density curve in my diagram above, but one can be calculated from the other).
|
|
|


Figures from CA here. Left – histogram of model runs used in Douglass et al 2008; right





301 Comments
Reblogged this on Climate Collections.
Reblogged this on ClimateTheTruth.com and commented:
Gavin Schmidt, wrong again.
Schmidt did provide an histogram for Tropical TMT.
On Twitter, the same discussion.
Doesn’t look too good for the models. More so since RSS v4 was not born by the time of Christie’s comparison.
Steve: thanks for pointing this out. I’ve updated the post to take note of this.
The chart comparing anomalies doesn’t make sense to me. The models all have a starting temperature (not anomaly) that may differ from both the actual and other models. Physically, this affects how the outputs progress since the computed values depend on the actual temperature (and other parameters) and not the anomalies. Even if the models all start with the same initial conditions, this does not mean that the actual measurements also start there.
Steve,
Everyone wants to know how the models work and now you have the theory (BK2002) and the model output to compare the real dynamics with the numerical trickery going on in the models. I am more than a bit surprised that you have not shown the output because it took me time and effort to obtain the data and learn the NCAR Command Language (NCL)
to get down to the truth. In fact I am willing to provide the NCL script so others can
verify the code.
Jerry
I remain wary of how the uncertainties are handled here. If you include the regression uncertainty in the observations, then why not also include it for the model runs? In fact, the model distribution is, in part, influenced by the regression uncertainty. So, that portion of the uncertainty is being double counted when you compare it to observations with regression uncertainty included.
See more in this previous discussion at Lucia’s (http://rankexploits.com/musings/2013/ar5-trend-comparison/) and in her Twitter reaction to Gavin’s histogram presentation (partly here, https://twitter.com/lucialiljegren/status/717673211366866944).
-Chip
Chip, Have Steve show you the ECMWF model output. No need to argue about model uncertainty. They are not even close to the correct dynamics.
Jerry
Chip says:
In this post, I was trying to show that the implication of Schmidt’s own preferred methodology did not support his invective against Christy. I didn’t endorse it as a methodology. Indeed, I made a point of showing that Schmidt’s past assertions on this topic were inconsistent with Santer et al and rejected by Wigley.
I do not believe that there is anything so special about this problem that it requires people to philosophize more or less from first principles about what is the “right” way to account for uncertainties. My eyes tend to glaze over at such discussions unless there is a reference to a statistical authority or a work-up using known statistical software.
Having said that, it seems to me that the setup can be effectively and trivially modeled with a multilevel model (in which runs are grouped within models) – I’ve written on this technique (as linear mixed effects) on multiple occasions. I have done some experiments using multilevel models on which I have not yet reported. The effect of using a multilevel model was that the within-model variance was reduced. In particular, the trend fit to the outlier Russian INM model was higher – as it appears that some of its outlier-ness was assigned to within-run variance and away from within-model variance.
For the purposes of drawing Jaynes-style conclusions: what proportion of the time does a model run hotter than observations, it is my surmise that the conclusions are rather insensitive to the issues that you raise here, because, as I pointed out in the post, if the uncertainty is larger such that the upper tail of obs nicks the lower tail of models, you also have larger negative uncertainties and the distribution of the difference doesn’t appear to be affected as much as you might think. This is another reason why it seems to be a good idea to focus on the posterior distribution of the differences.
a true tour de force.
excellent graphics representation of data.
Are you talking to Steve or me ? 🙂
Jerry
“”absurd” situation where some runs contributing to the model mean were outside the confidence interval for the model mean.” Schmidt is working with statistics and understands nothing about them! If you have 100 model runs you should have about 5 of them outside a 95% confidence interval. All runs that contribute to a mean are not withing the confidence bounds unless there are very few runs and a very high percentage confidence interval.
Steve: yes, it was a bizarre claim.
Thanks for mentioning that. I was wondering why it had not been pointed out.
Is it only reasonable to have all runs within a 95% confidence interval if you have 20 runs max, with high confidence interval?
Am I wrong to say with 100 runs in this scenario 95% drops to 70% confidence?
Or to make what I mean more clear, only 70-75% of runs are statistically within the claimed 95% range.
So, 95% CI range should be greater as a result, but this would increase uncertainty, a bad thing for the models obviously
I think there is a greater probability I dont know what I’m talking about..
The absurdity lies in the fact that the INM CM4 lies outside the 95% confidence range. This model is the cool outlier on Gavin’s histogram which best conforms to the observations. A fine irony that proper statistical technique should marginalize the model that gives the best results.
To iterate, the “model ensemble mean” concept renders the best performing model as statistically inconsequential. Such clever fellows, those climate scientists.
Jerry, Can you put your results in a comment?
dpy6629,
They have a number of graphical images from the ECMWF output so I don’t think they can be added to a comment unless Steve scans them? I can send the stuff to your email.
I want to add the conversion I made from omega (dp/dt) to w (dzdt) so people can match the plots better to our 2002 manuscript. That way they can see that the unresolved vertical velocities are of mesoscale magnitude, but not smooth, i.e., pure noise caused by the columinar forcing.
I have considered writing a manuscript but probably could never get it thru the met journals as long as they are controlled by modelers. My email is hrhrbb@comcast.net
so if you send me yours I will send you the package.
I can’t figure out why Steve hasn’t sown the package.
Jerry
GB:
This post is a critique of claims by schmidt. Perhaps your multiple demands are out of place in that limited venue.
Dr Browning, you CAN get a photo placed here:
1) Place your graphic ANYwhere online, even in a Google Photo collection
2) Use your mouse to right-click on your photo in your browser, and choose “view image”
3) Copy the URL (address) from your web browser.
4) Now come here and paste the address in HTML form. You’ll write something like the following:
<img href=”http://some.thing.or/other/whatever/is/the/address.jpg”>
And all should be well. Or just email the URL to Steve or anyone involved in this site if you can’t figure it out 🙂
Mr Pete,
Thank you for your suggestion.The file is a mixture of text and graphics. I have a PDF version. Can I post it somehow or must I separate the text from the graphics?
Jerry
Mr Pete,
It appears I can move the PDF file to Google Drive and then you can access it there?
Jerry
Mr. Pete,
Here is the link to the package of text and graphics showing that the ECMWF model dynamics is completely wrong.
Let’s see if it works.
https://drive.google.com/file/d/0B-WyFx7Wk5zLR0RHSG5velgtVkk/view?usp=sharing
Jerry
Mr. Pete,
Thanks to your idea, I was able to find this solution (Google Photo does not take PDF documents). Th link appears to work and now anyone can see why the ECMWF model dynamics (considered the best in the world) is completely wrong. I will answer any questions
about the package, but as far as I am concerned the package completely agrees with the theory mentioned in the Memorial to Professor Kreiss, i.e., the models are using the wrong system of equations.
Jerry
Sorry for the grammatical errors – replace is by are. 🙂
Gerald, weather prediction models need this kind of measures to suppress gravity waves, otherwise the forecast runs out of control in no time. It works (they prove it all the time, and they understand this stuff, believe me). Of course, that does not make the same models suitable for climate prediction; on the contrary. So yes, potentially, much can be wrong with climate models because a lot of the approximations that work for time scales of up to two weeks may not work for long time scales. And we do not know, because we cannot make models run properly without these approximations.
probahblah,
What kind of measures? Large unphysical dissipation that is destroying the numerical accuracy of the spectral method? Browning, Hack, and Swarztrauber showed that the spectral accuracy was decreased by two orders of magnitude when the dissipation used in typical global models is applied. Also the dissipation did not help the accuracy in any of the test cases. The unrealistic dissipation is just used to keep the model from blowing up from the excessive noise from the parameterizations. The gravity waves can be suppressed by proper initialization.
Why do you think Heinz Kreiss and I had to spend much of our careers sorting out the
problems caused by the hydrostatic assumption?
You need to identify yourself if you are going to make statements that are not based on scientiifc facts.
The bar charts present the discrepancy between models and observations even more starkly than the curve charts, visually. Gavin Schmidt has resorted to a mode of presentation that punctures his arguments completely.
mpainter – I agree entirely. I’m not sure why Steve’s elaborate analysis is even necessary. Your eyes tell you the story just as well
The histogram view that Gavin Schmidt provided only showed the mean and standard error spread for satellite observations. The vertical placement of the satellite observations had no relationship to the y axis of the histogram, and was only used to visually separate the satellite results for ease of viewing.
Steve’s analysis above turned the two data sets into comparable distributions. If the two data sets had been from one population, then the difference distribution should show a mean of zero, or be close to zero (eg within one standard deviation). Not only are the two data sets not from one population, but Steve’s analysis above provides values that show the probability of how far apart these two populations are from one another.
Steve,
So post it on a separate thread as I politely requested. You have not responded to any of my emails
and I am beginning to think you are censoring the facts. I have sent the package to David Young and await his comments.
Jerry
Steve: I have other things to do in my life and don’t always have time to do things at someone’s beck and call. If you want to post it somewhere else, so be it.
Steve,
Out of common courtesy You could at least have acknowledged one of my emails.
How long would that have taken?
\
Jerry
Perhaps he gets lots of e-mail and doing so for all of it would take hours a day. Perhaps your mail ended up in a spam box and went unseen.
I’ve sent many e-mail to Steve and heard nothing back. I don’t whine about it. Ironically, the only reply I have received was when he was at his busiest, and I suggested posting a defense of ClimateGate e-mail, volunteering to take the scientist’s side.
Thanks for making that PDF available Dr Browning. Very interesting.
However, until there is general acceptance that the models ARE wrong, there will be little interest in why they are wrong.
At present, most of those involved in modelling seem to be in deep denial that there is a problem with model output. Apparently it is the observational DATA which is wrong !
Mr Pete,
Thank you for your suggestion.The file is a mixture of text and graphics. I have a PDF version. Can I post it somehow or must I separate the text from the graphics?
Jerry
Gavin’s use of the histogram is clearly a useful tool for analyzing model performance. It shows quite clearly the one model whose products conform to observations. Thus Gavin Schmidt makes a contribution toward our understanding, if only inadvertently.
Nesting fouled, thanks WP
another assessment of climate models: “lack of global-mean lower stratospheric T trends since 1995”
http://onlinelibrary.wiley.com/doi/10.1002/2015JD024039/full
stratospheric temperature changes during the satellite era
You wrote: “As an editorial comment about why the “uncertainties” have a relatively negligible impact on “bias”: it is important to recognize that the uncertainties work in both directions, a trivial point seemingly neglected in Schmidt’s “daft argument”.”
Yes, trivial – but also crucial! (I’ve just bumped across the use of asymmetry in funnel plots as a measure of bias and am very taken with it.)
Unlike your usual thoroughness, I don’t see links to the mentioned Climategate emails. Could they be included?
Steve: Without fully understanding what I was doing statistically, I tried a similar approach to answering the question: “What is the probability that the difference between models and observations is zero or less? Lacking the real data, I took the midpoint from each bar in Gavin’s histogram to get 102 trends, which I copied 99 times to get 10200 trends. Then I used a random number generator to simulate 10200 trends for each of the six observational data sets. Subtracting the model values from the observed values (produced by chance pairing on my spreadsheet) gave 10200 differences. For UAH, less than 1% were less than zero. For two other data sets, closer to 10% were less than zero. Using IPCC-speak, this could be converted into a conclusion that it is “very likely” to “virtually certain” the models are running hot. (I wasn’t cleaver enough to determine the probability that the trend difference was at least 0.1 deg/decade.) Was this a valid (“Monte Carlo”) approach to the problem?
Based on your Figure 2, you have fit the model trends with a normal distribution, rather than working with the actual distribution of trends shown in the histogram. And you have one normal distribution for observations, instead of the sum of six separate pdfs. (I could add the number of times models minus observations came out less than zero for all of the data sets.)
Working with the real data would have made more sense. Is it easily available somewhere?
Steve: I’ll post up the underlying data.
After finishing the above exercise, I wondered if there were a better way to represent the model data than copying the same trend 102 times. If occurred to me that each of those 102 trends came from a regressions that also produced a confidence interval (corrected for autocorrelation). The model data would then be represented by the sum of 102 pdfs (or perhaps compressed into one pdf for each model). That might require a lot of work. Any thoughts?
As an outsider looking in, these debates are beyond bizarre. Anyone can tell that the models aren’t working just looking at the outputs raw — well anyone who works with data anyway. All the other exercises are just rejigging the presentation of the data. Pulling up a histogram instead of a spaghetti chart to deny an accusation is the equivalent to changing the colours of the plotted lines and claiming that this changes the facts on the ground. Okay, that’s maybe a teeny exaggeration. But not much of one.
That’s not to detract from the work you do here, McIntyre. For me it’s fascinating to see what sorts of debates take place in this space. But really, when a discipline becomes completely focused on statistical method rather than on statistical fact you know that discipline has passed its sell-by date. The phrase “I’m pointing at the moon, you’re looking at my finger” comes to mind.
You’d think so, but Santer and Schmidt have kept the obfuscation in play for years. When Ross and I submitted a comment on Santer et al 2008 showing that their results did not hold up with up-to-date data, our comment was rejected. Concurrently, Santer et al was cited in the US CCSP and Endangerment Finding as showing that there was no statistically significant discrepancy.
IPCC AR5 contemptibly perpetuated the obfuscation, even editorializing against McKitrick et al 2010’s demonstration of the discrepancy.
“well anyone who works with data anyway”
People who work with data are not Schmidt’s intended audience.
It’s a pity for the literature and science that Steve and Ross’ clear commentary on Santer 2008 was not published. The submitted paper can be found at http://arxiv.org/abs/0905.0445
Keep up the good work. In economics we have it bad. Complex system, likely chaotic dynamics, total lack of real knowledge etc. But not this bad.
The failure of the clitamaterati to acknowledge the fundamental work done by econometricians regarding the issues endemic with climate data (noise time lags and autocorrelation as examples) is astounding.
Their reluctance to call in professional statisticians is telling.
David, why would the climaterati want to call in statisticians? The American Statistical Association passed resolutions that approve of the statistical modeling that they did on their own without the help of statisticians, and that includes by direct implication approving their inventing new statistical methods without having them vetted or published in relevant professional literature. So the message from ASA is “hey, you don’t need us; anybody can do what we do as long as they say the things we like to hear”.
How well does the endangerment finding hold up with up to date data over the last 6 years?
PilkingtonPhil,
Outsiders have little idea of what is taking place in the shadowy world of climate science. There are scores of instances that would drop the jaw of any “outsider” who has a general appreciation of science and scientific methodology. The annals of Climate Audit are full of meticulously detailed dissections and accounts, similar to this post in the level of astonishment that they provoke.
And if you remove the Russian INM-CM4 outlier do we reach 100%?
And I forgot to mention, it’s a shame that this number wasn’t 97% for obvious reasons.
How does the Russian INM-CM4 model handle CO2 forcing and feedback, and why is it so different?
Excellent in several ways, thanks again.
One minor point not mentioned is the virtue of turning Mann’s graphs sideways. It’s not only convenient, it brings out the point much more clearly.
In fact, when I first saw Mann’s version I could not work out what was going on. You naturally compare the height of the models with the height of the observations, and looked at that way, his graph doesn’t look so bad. It took me a minute or so to realise that the height of his observations lines is completely arbitrary and irrelevant – it’s only their distance from the models on the x-axis that is of interest, since the way Mann has done it, the y-axis (density) does not apply to them at all.
Once you turn the graphs 90 degrees the valid comparison does become height and the eye makes that comparison immediately. Result – you can clearly see that model performance is dismal.
BTW when on earth are climate scientists going to stop claiming models should be relied on as long as there is still a 5% or even 1% chance that they might be right?
Mann, Schmidt, what’s the difference.:-)
Thanks, sorry about that, having a bit of seniors moment.
The RSS website shows a best linear fit, from 1979 to last month, of 0.151 deg K/decade in the tropics. I don’t think a linear fit is a good representation of the warming over this period, but let’s ignore that. The model predictions are centered around 0.272 deg K/decade. One could, justifiably, simply reject the computer model predictions as fundamentally wrong and worthless. But alternatively, one could assume that the actual heating for the rest of the century will remain about 56% of the computer predicted value. In that case, the Earth would still have a level of heating that would be unacceptaly large. Which choice is better? To toss out the predictions as worthless, or to take action on the grounds that the Earth’s heating might still be too large?
Steven says: “The RSS website shows a best linear fit, from 1979 to last month, of 0.151 deg K/decade in the tropics”
##
There is no basis for relying on the RSS product in preference to the UAH product, which shows about half the rate of warming in the same 37 year interval.
Steven says: “one could assume that the actual heating for the rest of the century will remain about 56% of the computer predicted value”
###
But in fact, neither satellite dataset shows a warming trend for the last eighteen years. The impending La Nina will extend that hiatus to over twenty years. Compare the model projections over the same interval. There is no basis for assuming a resumption of warming, except as a conjectural basis for alarmism.
Steven says: “Which choice is better? To toss out the predictions as worthless, or to take action on the grounds that the Earth’s heating might still be too large?”
###
The models can be ignored, as these are falsified by observations.
Actually, the plethora of models and their wide range of products are an invitation to pick and choose, and there seems to be one model that gives results consistent with observations (as seen in the chart graphics). So I choose that one. Let’s get Gavin to signify which one he prefers.:-)
m painter seduction:
“But in fact, neither satellite dataset shows a warming trend for the last eighteen years. The impending La Nina will extend that hiatus to over twenty years.”
Do you realize that this falls under the category of making things up. What you say may actually transpire but to assert it as fact seems silly.
F’ing auto correct “mpainter sed”, though it might be seductive to some POVs.
Jeff, I view it as dead certain that La Nina will appear. There is a solid basis for my confidence: in the critical ENSO region 1-2, SST is already cooler than the La Nina threshold, ENSO region 3 will shortly reach that threshold, if it has not already. Already a tongue of cool upwelling extends westward from Peru for over 1500 kilometers. This is incipient La Nina, though some may not understand this.
Also, there’s little chance that a step-up will occur, such as the one that followed the 1999 La Nina. I regard it as virtually certain that the hiatus will lengthen to over twenty years.
Seductive? Ha, many would say “repellent”.
Having faith that something will happen in the future and expressing it as a fact remains silly, regardless.
Come, Norman, where is your remit to call others silly. I expressed future certainty (will), and you resort to semantic spin (facts) for the sake of calling me a name. Enough of that, please.
How can I remain skeptical of the way climate models are used to justify policy decisions and give assertions of contrary futures a pass? It is silly that you are making up your own stuff about how the hiatus will extend into the future while criticising the GCMs. How can you not see the hypocrisy?
Norman, aren’t you smarter than a climate model?
So am I.
I, for one, have never been sold on the idea that inconsistency between models and observations on one issue makes them “worthless” or renders concern moot. Over the years, I’ve discouraged this interpretation of Popperianism, if indeed it is a valid interpretation of Popperianism.
If this was something uncontroversial like modeling smelter or refinery throughput, a similar degree of inconsistency would prompt re-tuning of the models, not throwing them out. However, academic climate modelers have stubbornly refused to do so. Since they have refused to do so, it is entirely reasonable for me to comment on the inconsistencies. I have a particular annoyance on this topic as McKitrick et al 2010 was misrepresented in AR5 and an earlier submission pointing out false results in Santer et al 2008 was rejected, thereby permitting Santer et al 2008 to be used in policy relevant documents by US CCSP and EPA.
If change over the next 50 years is more likely to be of the same order as change over the past 50 years, as opposed to the accelerated changes contemplated in the climate models, that is surely relevant to the development of policies that are commensurate with and appropriate to the actual problem. Unfortunately, it also seems to me that much of the climate science community has, in the name of doing “something”, promoted feel-good but pointless or resource-dissipating self-indulgences such as windmills. In Ontario, unwise subsidization of wind resulted for example in purchase of 3 TWH of power from wind crony at a cost of $450 million in 2015-4Q alone, which was sold to neighboring jurisdictions for $5 million. We not only lost $400 million in one quarter, but over charged hard pressed industry in Ontario while subsidizing competing industry in Michigan, New York and Ohio. A more toxic policy is hard for me to contemplate. And yet our politicians want to expand this program.
Division of labor: scientists say Do Something –> politicians use as an excuse to Do Anything.
When pressed on the fact that their advocacy is used for destructive policies, scientists ludicrously mumble something like ‘I’m not into policy’. When asked why the 2ºC target is given so much importance, they simply say it’s the ‘internationally-agreed’ target as if that had any relevance. It’s an endless pass the buck.
And then they always have the excuse that whatever waste of money has been concocted by the climate bureaucrats is ‘better than nothing’. Well, no; some things are in fact worse than doing nothing. E.g., the EU is spending over €100bn a year on climate policies and the effect is indiscernible.
My concern with mitigation is that money will be spent (wasted) on schemes with little likelihood of benefit -shooting in the dark, so to speak – and thus diminish the wealth available when the problems associated with warming do show up, when we can clearly identify what needs to be done, and will then find ourselves hard pressed to pay for it.
Great point @AZ But
..”EU is spending over €100bn a year on climate policies and the effect is INDISCERNABLE.”
That is clearly not correct
…They are in fact managing to nicely INCREASE CO2 emmission rate ..that’s what they want isn’t it ?
“Eurostat estimates that in 2015 carbon dioxide (CO2) emissions from fossil fuel combustion increased by 0.7% in the European Union (EU), compared with the previous year. ”
Paul Homewood reports on the May 3rd Eurostats release
It all seems rather Biblical…
15 Beware of false modellers, which come to you in science’s journals, but inwardly they are ravening activists.
16 Ye shall know them by their trends. Do people gather hope of peril, or faith in danger?
17 Even so every good model bringeth forth objective data; but a corrupt model bringeth forth subjective
19 Every model that bringeth not forth good data is hewn down, and cast into the fire or not.
20 Wherefore by their output ye shall know them.
Steve,
Have you ever looked at the models that are used to determine the global surface temperatures for the period when there was not enough coverage from surface stations?
More toxic: do what Steve described at a loss of $400M… and actively prohibit those in developing nations from using available energy sources to provide live-giving heat, food-cooking and other essentials… thus resulting in further poverty, sickness and death.
Even more invest in these ineffective policies, while failing to invest in other serious issues that do need a response.
Very real people are harmed by our bad decisions and unintended consequences.
And all of this is completely independent of the banned p* topic 🙂
Yes Steve, I agree with your point. Given the poor performance of GCM’s one would expect the modeling groups to be desperately trying to find out why and improve the models. The question is why this hasn’t happened.
There are some hints. There was an effort to build a “new” GCM by DOE in the US that started a couple of years ago. It is called ACME and is ongoing.
http://climatemodeling.science.energy.gov/publications/accelerated-climate-modeling-energy-acme-project-strategy-and-initial-implementation
There is also an interesting article in science magazine discussing the reactions of pre-existing modeling groups to this proposal.
http://www.sciencemag.org/news/2014/12/new-us-climate-model-project-getting-cautious-praise
Sounds like pretty much what I would have expected. Building a GCM is a big task and requires a lot of resources.
I get a 404 on your last link.
A new climate model, will get a very frosty reception, if it shows any degree of accuracy over & above what’s already on offer.
Questions along the lines of “Why are we spending $$$$$/£££££ on your model & team, when it isn’t as accurate as this one” will be asked by funders!
Adam Gallon,
Try this URL instead: http://www.sciencemag.org/news/2014/12/new-us-climate-model-project-getting-cautious-praise
Any climate model that, when initiated at the beginning of the satellite era, reflects the temperature record with fidelity will show two flat trends connected by a step-up of about 0.25-0.3° C at approximately year 2000. This should be easy to achieve.
Karl Popper got his falsification idea from Einstein, who observed that if no stellar redshift was found, then relativistic mechanics would be proven wrong. This was and remains the standard of science, namely that theory is contingent on fact.
So it’s not “Popperianism,” but rather Popper’s formalization of how science works. A seriously contravening experiment or observation does falsify a physical theory.
Apart from that, modeling smelter or refinery throughput describes an engineering model; one that is parameterized to reproduce in-bounds behavior. Such models can be validated and proven to be reliable within their boundary conditions.
Climate models are supposedly scientific models. They are used to predict out-of-bounds behavior. They are not represented as engineering models. They are purported to give reliable predictions of future climate states. The fact that their predictions are wrong is very significant within a scientific context, and should falsify the models.
In that context, the inconsistency between models and observations on one issue does makes them predictively worthless and does render concern moot. And it’s not just one issue, but virtually every issue of climate they get wrong.
Finally, climate models are rife with so many internal uncertainties that they cannot produce falsifiable predictions at all. That means they fail at the first of the scientific dyad — making a prediction. As they cannot make a prediction precise enough to be falsified, one cannot even say they’re wrong when their specific output does not match the evolution of the climate.
Steve: we’ll have to agree to disagree. I do not agree with your points, but I profoundly dislike philosophical discussions and am unwilling to engage in them. I prefer to stick to practical issues.
Pat, I don’t think anyone pretends that GCM’s are anything other than engineering models. They are very complex and at least in principle get some of the large scale dynamics right. They have many other serious defects of course. But despite their shortcomings, there is reason to expect them to be improvable with better methods and data. That’s something I and people like Jerry Browning are at least trying to develop, even though I make no pretensions that our contributions are that significant.
Pat, see new link I posted above. I think you will be amused (if not outraged 🙂
Jerr
Wong position.
Pat,
Pat, see new link I posted above. I think you will be amused (if not outraged:-)
Jerry
Just to say, Steve, that discussing how science works is not philosophy.
Thanks, Jerry. I’ve downloaded the file. It’ll take some digesting. 🙂
“Climate models are supposedly scientific models. They are used to predict out-of-bounds behavior.”
Darn it, I should not have tried to envision a model that predicts out-of-bounds behavior. My head exploded.
Is there any evidence or study that shows how much wind power “saves” in mass electricity production? That is, how much consumption of other energy resources are offset by the production of electricity by wind generators?
I suspect it is near nothing.
Steve: it depends on the jurisdiction and season. In Ontario 2015-4Q, it was zero. A precise accounting throughout the world is a large undertaking, well outside my time and energy,
Having faith that something will happen in the future and expressing it as a fact remains silly, regardless.
In theory the wind generation was installed to replace the coal generation that was prematurely shut down (about a decade) by the government to satisfy various environmental beliefs.
Wind is a variable energy resources so numerous CCGTS were installed as backup for the wind.
Backup generation was required to provide Operating Reserve which is scheduled for the largest contingency (loss of a nuclear station or rather its transmission circuit). Wind cannot provide Operating Reserve. The CCGTs can provide Operating Reserve but have high idling loads, 300 MW for 200 MW of O.R. A coal unit could provide 200 MW of O.R. while idling at 50 MW.
When there is excess baseboard generation, water is spilled at hydroelectric stations and nuclear units are maneuvered down.
A large nuclear station is scheduled for retirement in 2020. The environmentalists are lobbying the government to shut it down earlier than that.
Further to Steve’s point about Ontario’s insane energy policies:
Ontario’s government high fives the fact that it has just about saved the world by closing a coal fired plant while over one hundred continue to operate in adjoining US states and 1200 new ones are planned globally.
By telegraphing the intention to continue raising rates, it has encouraged manufacturers who used to make goods with relatively clean Ontario nuclear and hydro sourced electricity to source from coal supplied Chinese plants – and then ship the goods back to us half-way around the world.
Global emissions have risen due to Ontario’s policies, but our government feels so gosh darned righteous! The sad thing is, they probably believe it.
Further to the comments on Ontario’s green energy policies, the neighboring province of Quebec has sufficient green hydroelectric capacity to supply Ontario’s needs. Quebec offered this to Ontario. The Ontario government declined the offer in favour of its Green Energy Act plan to create a green energy industry in Ontario with subsidies to wind and solar generation. The industrial policy failed. As described previously, Ontario rate payers are still paying the subsidies but there has been no significant amount of industry created.
By my count that is 15c per kilowatt hour. Is that in Canadian or US? That is cheaper than what I have seen in New England.
Selling this at 5 million would mean 1/6 of a cent per kilowatt hour. Gray Davis should have solved his energy crisis by taking a really long extension cord and plugging into a socket in Ontario.
The cost of electricity and the contributions of the various sources may be seen at http://www.ieso.ca (Independent System Operator). The price paid by the consumer at various hours may be seen at http://www.ontarioenergyboard.ca/oeb/Consumers/Electricity/Electricity%20Prices. These are just the prices for the electricity they do not reflect other charges for the grid
To toss out the predictions as worthless, or to take action on the grounds that the Earth’s heating might still be too large?
Your posturing of choices are a false dilemma and a failure to consider that the failure of the models, which you concede for argument’s sake are false, falsify the fears of AGW altogether. You state that “56% of the computer predicted value” is real-world correct, and thereby infer the models are 56% correct. No, the models are 100% incorrect and that there is warming does not mean that warming is unnatural or due to human actions in whole or in part because the models are “56% correct.”
Anyway, since the earthly powers that be have decided to “take action” by taking actions which actually do not decrease the human production of CO2 but sound like they might, like cap and trade, and mass solar and wind elec. production, these powers can’t too afraid for the future..
I don’t get it. So we’re doomed if the world heats up by 0.56 * 2.72 = 1.52 K over the next century? Color me comprehensively unworried about this possibility.
Yup, anything over 1.49 is unmitigated catastrophe
Steve, Excellent post. I am very glad that for have made these important points and, in particular, that you have highlighted Gavin Schmidt’s completely wrong ideas on the standard errors of model means.
Schmidt has not corrected his December 2007 view that division of the standard deviation by the square root of the number of models was not appropriate when calculating the standard error of the multimodel mean, contrary to standard statistical understanding. Appallingly, he has had his absurd views applied in the peer reviewed literature. The confidence intervals for efficacies in the recent Marvel et al paper, of which he is second-named author (and Kate Marvel’s boss) appear to be calculated by dividing the square root of the sum of the squared differences in the five (six in one case) individual run values, by the square root of the number of runs of the (single) model involved, supposedly giving the standard error for each individual run. The correct divisor for this calculation is smaller by one, as estimating the mean uses one degree of freedom. The thus (mis)calculated standard error for each model run is then used as the standard error for the ensemble mean, instead of dividing it by the square root of the number of runs.
That results in the confidence intervals being too high by a factor of two (more in one case), as pointed out here: https://climateaudit.org/2016/02/11/marvel-et-al-gavin-schmidt-admits-key-error-but-disputes-everything-else/ . A commentator at RealClimate also questioned the size of the confidence intervals. Although Gavin Schmidt had the paper corrected to deal with two of the other errors in it that I pointed out, he has declined to correct the calculation of the confidence intervals; he seems unable to see that it is incorrect.
It does seem to me that this is a problem with climate science generally. It is a field that is very multi-disciplinary and it is impossible for scientists in such a field to know the best practices from more than a few of the disciplines involved. Yet climate scientists tend to not seek out input from specialists in fields like statistics and numerical methods but to insist on doing their own versions, often flawed versions, of the science. Statistics seems to be a weak point for most climate scientists.
Dpy6629, agreed.
But, curiously Gavin Schmidt is a mathematician, having a PhD in math from University College London.
I wonder if his co-authors were deficient in math to the extent that he put one over on them, or whether they went along with his mathematical inventions from their own considerations. For example, as Nic Lewis points out, Kate Marvel et al, as employees of GISS, are subordinates of Gavin Schmidt, who heads that organization.
This is most curious. Another curiosity is the acronym GISS.This stands for Goddard Institute of Space Studies. Yet it’s research is devoted to the planet earth, mostly climate related work.
A most curious outfit, GISS.
Steve: applied math and statistics are different disciplines. Applied mathematicians often have preconceptions that serve them poorly. Mann’s background was also in applied math. See his methodology description in MBH98 for an absurdly overblown characterization of ordinary regression techniques in applied math terms.
Remember applied Math is a huge field with scores of sub specialties. It took me 20 years to become possibly competent in aeronautical CFD. To expect Schmidt to be an expert in any real detailed technical subfield of climate science is unrealistic given his leadership responsibilities. I would then expect someone like Schmidt to be honest enough with himself to realize his predicament and seek out expert advice especially on statistics. This illustrates the peculiar nature that the “communication” of climate science has imposed on the field. It leads to all kinds of obvious errors and dishonesties.
My assumption was that any mathematician could sufficiently grasp the principles of statistics to acquire some basic skills in that field. Not necessarily so, it seems. Climate Science is rife with those types of assumptions.:-)
What I do not understand is that Gavin Schmidt, Director of NASA GISS and Chief of Lab (he apparently holds two titles there), responsible to the public for his performance and the performance of his subordinates, manages to use in his work egregious statistical techniques for years after being called out on these. This is the sort of stuff that makes rockets explode on the launch pad. But NASA GISS seems to be incorrigible in this regard. Maybe someday some statistician of US citizenship will engage him on the issue.
Perhaps someone has. Perhaps there are emails.
Bear in mind that applied mathematics is a large field with many very technical sub-fields. Numerical solutions of PDE’s is itself a full time occupation. Schmidt is reasonably competent in this sub-field. As director of GISS, he probably no longer has time to maintain even that expertise and relies on others. What is puzzling is that he doesn’t hire a statistician and some other non-climate science specialists. That would be a smart move and would prevent future embarrassing elementary mistakes.
Dpy6629, no doubt.
Except, that NASA GISS has over 150 on its personnel roster, presumably scientists/mathematicians, about half of whom list affiliation with COL (presumably Columbia university, with which NASA GISS is married to, sort of). So Schmidt has the expertise at his disposal that he could refer any problem to, and I assume there are statisticians somewhere in Columbia university, or at any of the other institutions in the area that GISS works with, such as CUNY, Lamont-Dauherty, etc. Expertise is a phone call away, or he could detail the problem to a subordinate. This he does not do. Yet it is his obligation and he should be censured for not doing so.
You cite Gavin Schmidt’s time constraints. No doubt he has these, so what is he doing at RealClimate?
No excuses. It should be his priority to hire the best from OUTSIDE climate scoence
Could it be that Gavin does not want any experts, e.g. mathematicians or numerical analysts, looking too closely at what his institute is doing? The institute would probably lose its funding.
Jerry
Jerry, That is a possibility. I see this all the time. Most fields have a top tier of less rigorous practitioners who don’t want to hear any persistent questions. My brother says its true of whole classes of MD’s who of course make a lot of money off interventions that may or may not have rigorous support. He has been trying to wean his docs off some of the expensive and worthless interventions. In aeronautics, I often hear the “engineering judgment” excuse when people want to believe some computed result that has a lot of holes in it.
Perhaps they didn’t like the results that Columbia stats people were telling them.
Isn’t this the same place that had their deflategate analysis rejected?
thanks, Nic.
BTW Schmidt’s erroneous December 2007 perspective appears to underpin IPCC AR5’s assessment, where they blamed inconsistency on use of inappropriate formulas in articles such as McKitrick et al 2010, conspicuously not criticizing Santer et al 2008 for their use of a correct formula.
Nic:
I always write that ignoring the basic assumption that form the foundation of statistical analysis inevitably leads to no good
This is a perfect example..A lack of understanding of just what a degree of freedom is….
A principal author not understanding the concept of linearly independent observations, and a failure of any support staff to point this out?
This isnt an example of failing to use “best practice”, its an example of malpractice.
Simply inexcusable.
Schmidt’s blog post gives lower real-world forcings (relative to RCP8.5, presumably) as a possible reason for part of the discrepancy. Perhaps I’m missing something but I don’t see how this can be.
Christy used RCP4.5, not 8.5 which seems to be what Schmidt’s paper discussed. In any case a more detailed analysis later found the actual forcings were almost the same as in RCP8.5 – the difference was only 0.03w/m2. So if anything using real-world forcings would have made the discrepancy between models and observations bigger.
http://onlinelibrary.wiley.com/doi/10.1002/2015JD023859/full
“All climate models are wrong, but some of them are useful, and by working more closely to answer the questions that are actually being posed by policymakers, we can make them more useful still.” -Gavin Schmidt
More from Gavin https://wattsupwiththat.com/2013/06/01/a-frank-admission-about-the-state-of-climate-modeling-by-dr-gavin-schmidt/
Gavin proudly admitted regional models lacked skill in the past decade. Now he wants them to appear skillful when they still don’t.
I would love to see a list of the questions “actually being posed by the policy makers”. Do you suppose that these could be in emails?
Michael,
If you want to see just how careful one must be to obtain the correct solution in a limited area model, peruse the Browning and Kreiss 2002 manuscript. The recreation in a limited area was accomplished with no observational errors, no forcing errors, and very careful well posed boundary conditions and BDT initialization. If anyone claims to have computed a limited area solution correctly, I would be highly dubious.
Jerry
” a bias which cannot be dismissed by mere arm-waving about “uncertainties” in Schmidt style”
I’m not sure that Gavin gets credit for the style. We all know this has been standard meme in the climate industry for some time.
A more ridiculous position is hard to imagine except when you consider that the industry has lost its argument and has nowhere else to hide. Considered that way, their current stance and their future positions are predictable for the next few years. Expect even more adjustments to forcing and observations as well as statistical nonsense to make the CI’s closer. It seems pretty likely that these methods will also fail as it is pretty clear now that climate model sensitivity is too high in general, but the industry can always continue tweaking observations while praying for a gaian warmup type miracle until then.
Steve —
I’m afraid that I agree with Gavin here with regard to the sqrt(n) issue.
If I understand these model runs correctly, they are essentially supposed to be Monte Carlo draws from the distribution of climate outcomes that are possible according to the models. They differ because they are based on different draws from the distributions of uncertain parameters, as well as from the distribution of unknowables like future cloud cover on any given day.
The comparison to the instrumental outcome then asks whether the actual outcome could have been another draw from this same distribution, not whether the actual outcome equals the mean of the distribution. For the former question, we just see where it lies in the simulated distribution, while for the latter question, we average the simulations and then compute a standard error, dividing the standard deviation of the simulations by the square root of the number of simulations.
The fact that the observed satellite trend is way out in the lower tail of the distribution of model outcomes indicates either that the models are wrong, or that the satellites are wrong, or that the earth is wrong. I’m guessing that the problem is with the models in that they have all used an artificially inflated climate sensitivity, as discussed here by Ken Lewis, though I haven’t been following that discussion very closely.
When the outcomes are reduced to a single trend slope, the uncertainty of the slope coefficient becomes a factor, and that is very sensitive to the amount of serial correlation in errors, which is still acute even for annual data. However, I am not sure how to incorporate that into the comparison of the actual outcome to the distribution of simulated outcomes, since if the simulations come up with the correct amount of serially correlation, the additional uncertainty it causes is already incorporated in the distribution of simulated trend slopes. In this case, it would seem that the realized trend slope can just be compared to this distribution directly, without having to compute or use its AR(1)-adjusted standard error.
To be sure, calling an inappropriate method “egregious” or “absurd,” to use Gavin’s terms, doesn’t advance communications between opposing viewpoints. And although Twitter may be the ideal medium for politicians to hurl drive-by juvenile invectives at their opponents, it is hard to see how it can have any usefulness for serious scientific discussions.
Hu McCulloch writes
Isn’t the spaghetti diagram showing the results of runs for multiple distinct models? If this is so, is there any sense to asserting that this is a distribution resulting for uncertain parameters since the parameters would be different from model to model?
I believe there are 102 runs of 32 different models, so that there are on average 3 runs of each model, presumably with different random shocks. Admittedly that’s not enough runs to allow uncertain parameters to be drawn with different values, so perhaps my interpretation is not correct.
Hu,
I would say that different runs by the same model can reasonably be taken to be random draws from a distribution, since they sample the internal variability of the model. Thye all use the same parameter values, but with slightly differing initial model states.
I’m not convinced that different models can reasonably be taken to be random draws from a distribution of possible models with differing parameter values and/or structures. However, since the model mean values of various variables are used for many purposes it is relevant to ask whether the mean in question appears to be biased with respect to observations. If one is interested in how realistic the model mean is, then surely it is the uncertainty in that mean that is relevant?
Of course, when estimating how significant any bias is one must allow for uncertainty in the observations, including that from internal varaibility as well as from measurement uncertainty. There is no reason to expect the standard deviation of such internal variability to be as high as the inter-model standard deviation – it should be more like that for multiple runs of a single model.
In a true monte carlo simulation we would have done 20-40 runs for each case, using like numbers of initial random number seeds, and explicitly drawing a value for each random variable based on it mean value and variance. Due to the lengthy run times of the climate models, my guess is that they don’t have the time or space to do that. They
appear to be running a long, deterministic run, or a few runs, possibly slightly changing initial conditions. I don’t know how they would do a sensitivity analysis, for
instance to look at the long-term (60 yr) sensitivity to say, change in Calif Central Valley albedo between the seasons. I think they type in the data to the best of their
ability and let it fly. This makes the output extraordinarily sensitive to bad or missing data.
Hu,
Some would argue with the characterization that they are “monte-carlo” draws and the basis of “they use physics” . But with respect to post-hoc analysis, the share every characterisitc of a “monte-carlo” draw. (And besides that, ‘monte-carlo’ diffusion and dispersion models can use physics. They are often simpler than climate models, but that’s not fundmental to comparing model output to observations they output is intended to simulate or predict.
Hu, Nic, Steve, and Lucia, I am very interested in this issue as we use a similar statistical procedure in our paper on uncertainty in CFD. We assume that our CFD model result are randomly distributed about their mean value. This is not strictly valid of course. The models are NOT random methods, but perhaps there is some justification in saying their results on problems other than the ones used to tune the models are random to some extent. I am not a statistician, but my two collaborators are.
I do however think it is justified to assert that the distribution of the model results is a lower bound on the uncertainty in all such models. Our model is a mixed effects model so in principle one could define fixed effects between models based on expert judgment and mostly eliminate the random component of the model.
I can send you the paper and am deeply interested in your thoughts as this is an issue we in industry need to understand as a matter of public safety. If any of you have an interest in this, please send me an email.
dpy6629 : ” we use a similar statistical procedure in our paper on uncertainty in CFD”
I, we, our paper ? You seem to be a publishing author, it would be more helpful if you linked “our paper” and used a handle which indicated who you are. That way we can credit your comments with the seriousness they probably merit.
If you wish to remain totally anonymous, that’s fine, but there’s not much point to referring to “our paper” etc. like you are a practising scientist. There are plenty such claims where the “paper” in question turns out to be an article on someone’s wordpress account, which has had independent scrutiny.
Your comments seem informed, I’m sure the paper would be interesting.
“I can send you the paper and am deeply interested in your thoughts as this is an issue we in industry need to understand as a matter of public safety. If any of you have an interest in this, please send me an email.”
“If you wish to remain totally anonymous, that’s fine, but there’s not much point to referring to “our paper” etc. like you are a practising scientist. There are plenty such claims where the “paper” in question turns out to be an article on someone’s wordpress account, which has had independent scrutiny.
Your comments seem informed, I’m sure the paper would be interesting.”
Greg, Since I signed up for WordPress it seems to post all my comments under my account login there. I’m David Young. My request for responses is genuine and yes we do have a real paper we are about to submit to a journal.
Hu –
“The comparison to the instrumental outcome then asks whether the actual outcome could have been another draw from this same distribution.”
To my mind, the problem with this formulation is that the very wide range of model outcomes makes it a weak test. For example, suppose we have a model with 3 runs, the outputs of which can be characterized as respectively equal to 0, 2, or 4 K/doubling times the forcing (plus a small amount of white noise). The mean response is 2 K/doubling, and the se is also 2 K/doubling. If the actual climate response is 1 K/doubling (plus noise), then the model mean is 100% too sensitive. Yet even a long period of data collection will not result in the rejection of the model (at the p<0.05 level, anyway). A sufficiently broad distribution can't be falsified, but then it also doesn't make any risky predictions.
.
But you make an excellent point. It seems to be difficult to translate the important question of "how useful is the multi-model mean?" into a precise statistical query.
HaroldW, you say
“It seems to be difficult to translate the important question of “how useful is the multi-model mean?” into a precise statistical query.”
###
First one must put “useful” into context. What other context gives meaning than its “usefulness” as a predictive tool? Then Gavin et al, will declare again that the models project, not predict. This is none other than a semantic dodge. Thus “climate ball”. It bears repeating that the present generation of “climate scientists” have set the field back by decades.
There is nothing Monte-Carlo-based about it. The procedure is to find parameters for aerosols, natural variation, land-use and CO2 forcing that manage to obtain a not-unreasonable hindcast, leaving other parameters constant. Inherent is an unrealistically high aerosol parameter to allow the high CO2 sensitivity that is believed a-priori to be true. These parameters are then set for a variety of forward projections with different fossil fuel and aerosol scenarios and a declining natural variation. There is no possible way to justify frequentist statistics for such a biased and inadequate method. Even calling it pseudo-Bayesian is flattering. A true Monte-Carlo-based selection of inputs withing their known uncertainty bounds produces enormous scatter so it is not ‘useful’ for policy. However all that is required to achieve reasonable hindcasts as well as pause prediction is to tone down the aerosol parameter and the water vapour feedback and increase natural variation, which is partly what the Russian model does. Alas that approach would not CO2 reduction drive policy at all.
JamesG, a worthwhile comment. Editing,
I infer:
“Alas, that approach would not [allow] CO2 reduction [to] drive policy at all”
I am glad for comments like yours that highlight the structural deficiencies of the GCMs.
Hu, Interesting comment. The first question you pose, whether the actual data could be another random draw from the set of all possible model results is in my view not a very enlightening question. Consider the case of a model with high variability. The set of all model simulations then will include a wide range of outcomes. The actual data is likely to lie within this range of outcomes. However, this result merely tells me that the model is not a useful model for making predictions.
The other issue here is what one allows to constitute the set of all model results. If you can change things such as model grid spacing, parameters, sub grid processes etc., the set of all model outcomes becomes very large and once again we conclude that the model is not useful for predictions.
“Santer forwarded Cawley’s inquiry to Tom Wigley, who told Santer that Schmidt’s Real Climate article was “simply wrong” and warned Santer that Schmidt was “not a statistician” – points on which a broad consensus could undoubtedly have been achieved.”
Thank you, Steve, for that superb example of ‘la politesse canadienne.’ A lesser man would have given in to the temptation of inserting ‘97%’ between ‘broad’ and ‘consensus!’
If the models are nowhere near reality and using the wrong dynamics, why argue about their output?
Jerry
I am very sad to see our wonderful neighbors to the North are starting to suffer from the same political malfeasance and misdirection afflicting the American political machine(s. I was hoping that I could move to Canada should Hillary be elected here, when she undoubtedly would continue or even increase the blatant attempt to silence skeptical scientists (on AGW) using legal measures. Seems Canada may be traveling down the same road soon if the Ontario regulations are an indication of the misinformed politicians in that country as well
So we know who ‘beaker’ is now!
Hu,
I agree with you that the correct statistic to use is dependent on the question posed, and the assumptions which underpin the analysis. If however an analyst wishes to argue that the ensemble mean outcome from a collection of models has some value in prognosis, or indeed that it is acceptable to average key abstracted parameter values from the models, then it is perfectly proper to test the statistical likelihood of that ensemble mean outcome (or average parameter) occurring against the observation space. The correct variance to use is then the variance associated with the mean. If an analyst, on the other hand, forcefully argues that you should never use the ensemble mean for prognosis, nor for the averaging of key abstracted parameters, then he does have the intellectual freedom to argue without any short-circuit in logic that the observational reality is not analogous to a fixed parameter to be matched; it is (instead) just one randomly-drawn realization from a large space of possible outcomes, and there then continues to exist the possibility that the model runs represent a series of equi-probable draws from a hopefully similar sample suite. This latter stance of course raises three substantial questions; the untested assumption of equal validity of the GCMs, the utility of the models in any predictive capacity, and whether they can be falsified in the Popperian sense.
To my mind, a key problem is that most climate scientists (97% approximately) want their penny and their bun in this regard; they want the ability to modify their assumptive stance depending on the question being posed. On the one hand, climate scientists make the argument that the ensemble mean of the models provides a useful and usable characterization of the system, but, on the other hand, without pause for breath, they will pull out the argument that if you want to test the models against observational data, you should use the full spread from the models as a proxy for the uncertainty associated with the single realworld observational dataset, rather than the lower uncertainty that we would associate with the ensemble model mean.
Let me however draw a clear distinction between the issue that Nic Lewis raised and the more general question here of comparing observations with results from multi-model studies. The issue raised by Lewis is a lot more clear-cut than the latter.
In the issue raised by Nic Lewis,the aim of the process was to produce a best estimate of forcing efficacy displayed by a specific GCM for each of a number of single forcing species, together with a best estimate of the uncertainty associated with each of those estimates.
The authors of Marvel et al (which included Schmidt as co-author) for each of the single forcing species made use of a number of repeat runs of the same model. All inputs were identical for each single forcing species; the only difference between the repeat runs for each forcing species arose from varying the initial conditions – which then gave rise to different “natural variation” in each model run; the final reported (temperature) results for each run then took differences between the final state and initial state of the run. The clear intention in this was to sample the effect of “natural variation” in the model for each of the single forcing cases. The authors then compared the result from each run with the expected response for CO2 forcing to obtain an efficacy estimate of the specific forcing species and averaged the results to obtain a mean estimate for that forcing species. The expected CO2 response came from the same GCM and represented a mean outcome from multiple realizations; once again, the between-run variance for the CO2 response was determined/caused by design only by natural variation within the model. In order to estimate the uncertainty around the mean estimate of the efficacy calculation for each forcing species, the authors then seem to have tried to use the variance of the (full) distribution of outcomes for each forcing species – I say “tried” because it fits with a response made by Gavin on RC, but there remains some unexplained calculation error if this was indeed their intention – instead of using the variance of the mean of the distribution. In effect then, instead of using the variance of the mean to define confidence in their mean estimate of efficacy, the ultimate parameter of interest, the authors have attached (or tried to attach) to the mean estimate of efficacy the uncertainty arising from the model-specific “natural variation”.
What should perhaps have given them pause for thought was the fact that, had they increased the number of runs to 10000, say, they would have seen negligible improvement in the confidence of their mean estimate of the efficacy of the forcing. They would only have improved slightly the characterisation of the model variance attributable to natural variation.
The Marvel et al issue is a problem where you should definitely not be agreeing with Gavin on the sqrt(n) issue, irrespective of your stance on the comparison of model ensembles to observational data. I have to agree with other commenters who surmise that Gavin is lacking some basic understanding of theoretical stats. Just consider again his telling statement:- “…that division of the standard deviation by the (square root of ) the number of models resulted in the “absurd” situation where some runs contributing to the model mean were outside the confidence interval for the model mean.” Mmmm. That will come as a big shock to some high school stats students, I am sure. Way to go, Gavin.
the expected response for CO2 forcing
This is the not-very-variable, untouchable expectation, right? I expected as much.
In context, forcing efficacy is a relative measure. The expected response to CO2 forcing is therefore unambiguously defined as the response to CO2 forcing exhibited by the specific model being tested. It does not have to be the true realworld response, just the true model response.
Thanks for this Kribaez. It is a very painstaking write-up, and I needed every word of it to understand the debate.
I’ll concede with Nic, Lucia, and all, that the model runs are not a proper Monte Carlo sample as I had conceived. However, it’s not clear to me exactly what they’re supposed to demonstrate, if not that there’s probably going to be a lot of warming under various CO2 scenarios, which has not, as John Christy’s graphic shows, materialized. Gavin’s histogram does seem to suggest that at lest in his mind the runs are something like a Monte Carlo sample.
It seems that up to 2005, the AR5 CMIP5 runs are based on actual CO2, volcanism, etc, but that after 2006 they are based one of 4 RCP CO2 scenarios. This makes the portion of trends due to the 2006-2015 behavior entirely irrelevant for comparison to actual temperatures (except insofar as they are interpolated to actual CO2 behavior), so I’m not sure why the comparison is being made by either Christy or Gavin.
RGB@duke has commented extensively on the practice of even considering the ensemble mean, and IIRC he is quite critical of the concept, primarily because the ensemble mean is not comprised of independent, random samples from a population that has a normal distribution…
IIRC, he favors throwing out the models whose runs indicate that they dont accurately model climatic behavior, among other things.
Perhaps you might contact him?
David,
Here’s the link for those that are interested.
TY Ian.
Whenever I read the term “Model ensemble mean” I see red, as it were.
err because people will listen to james annan, not RGB.
Steve:
With all due respect to you, given your BA in ENGLISH, as well as your extensive body of peer reviewed published research, Dr Brown is a tenured member of the physics department at Duke. Now, that may not demonstrate to you sufficient field specific knowledge to opine on issues related to applied statistical analysis, but one wonders just what right an association with an entity that gloms off of UC Berkley’s good name and reputation confers on one of its employees
Just because you dont happen to like his perspective is no justification for your snark and condescension..
Perhaps if you attempted to present a reasoned critique of his views on ensemble means your points would at least least exist in writing.
Steven,
err but you listen to him though, don’t you (?), which must count for something, surely.
Steven,
It is worth considering where the two of them agree as well as where they decide to diverge.
Both James Annan and Robert Brown agree on one very important point, which is that what Annan calls the “truth-centred paradigm” – that each ensemble member is sampled from a distribution centred around the truth – is utterly bogus. This puts both of them at odds with the 97% of climate scientists (as well as the specific IPCC Expert Guidance on the subject) who thoughtlessly pull out the ensemble mean and use it as though it represents the most accurate prediction available.
It irritates me that JA spends more time excoriating people who make model-observation comparisons based on ensemble mean outcome than he does excoriating the climate science world which has pushed – implicitly or explicitly – this truth-centred paradigm. It will be interesting to see whether he reacts to this article by SM.
Where JA and RB seem to differ is that JA seems comfortable accepting a between-model consistency check (rank-histograms of key output variables) as sufficient support for using range estimates from the models. In this, I disagree with him quite fundamentally. RGB would, I think, argue that at best between-model consistency represents a necessary condition, but still offers no protection against the incorporation of models in the ensemble which are hopelessly wrong because of incomplete physics or poor formulation. In fact, because of their strong interdependence it remains entirely likely that all of the models are flawed in a similar way. In this latter regard, Jerry Browning’s examination of the result of assuming hydrostatic equilibrium is highly relevant. Equally relevant is the fact that none of the GCMs can explain the quasi-60 year oscillation in terms of temperature and net flux. The presently incorporated physics puts the net flux behaviour out of phase with observations. We know something is missing but we don’t know what.
RGB has argued that the first step should be V&V of each model with the elimination or mothballing of all models which do not pass pre-established criteria. Focus should then be on improving the high-graded models. This seems very sensible to me, but I am fairly sure that it won’t happen for a very long time.
Its simple david
Even an English major knows that RGB has no real standing.
Now if he were to publish something i might consider weighing his position.
WRT to V&V he is repeating what I wrote long ago.. so again,, why listen to him?
It’s simple Mosher, your ego is too big for this room. It’s so big that there’s no place for the truth.
So steve:
An english major, one who has basically no publications, record of peer review research, one who makes such insightful statements as:
“scientists dont deal in probabilities” is qualified to form an informed opinion regarding RGB?
He has no “standing”?
So that excuses your repeated unwillingness to engage the points he makes about the foolishness of “ensemble means”?
Now, if you were to publish something, i might consider weighing your position.
The models do not produce observations. They produce hypothetical derivatives (the models are elaborate hypothetical constructs). But is it of great advantage to the advocacy scientists to treat model output as observations, hence model means. This deception is effective because of its subtlety. One should never forget the hypothetical nature of the models: if x (the model), then y (the product).
Hu,
In answer to your last question re post-2006 relevance, see the comment of Alberto Zaragosa May 7th.
Paul
Reblogged this on I Didn't Ask To Be a Blog.
Why doesn’t Christy’s graph show the 1998 spike due to El Nino?
Five-year smoothing on the data mutes the spikes. This was probably for display effect, to compare to the models mean.
No he is not “smoothing” [ aka low-pass filtering ] he is using a running mean. Running means often invert peaks , not mute them.
Why the hell we can’t get beyond defective ‘running averages’ and use proper filters is beyond me.
If you get a slight trough in place of the largest spike in the record, you know something is screwed and should do something about it.
Yeah, running means tend to distort the data. They alias their main frequency into the final product, a fact which is well known to mathematicians. Not only that, but using a moving average cuts off data points in the final product and Christy’s graph has been padded to fill in the missing points. Since Christy provides no details about his method, we can’t know whether he used a training average or a centered one. Worse yet, his balloon data has been adjusted to simulate the TMT satellite measurements which exhibit peak weighting near 500 hPa, roughly half way thru the atmosphere but also include weighting from higher levels into the stratosphere. There’s no indication regarding a similar adjustment of the various model runs and he may be plotting surface temperatures, not simulated TMT results.
Christy’s PR campaign has worked wonderfully well. I’m sure his favorite Congressmen and fossil fuel buddies are quite happy with it…
E. Swanson,
Do you not agree that Gavin Schmidt’s histograms show the discrepancy between model output and observations more starkly than John Christie’s chart?
Also, strange that Gavin would intervene with a diagram that re-enforces what you call “Christy’s PR campaign”.
At least, I think it strange. Don’t you think it’s strange?
Correction, Christy, not Christie.
I don’t know if Gavin Schmidt used surface data from the models in a direct comparison with the TMT series, but, if he did, I think that’s the wrong way to go, which is the same objection I have regarding Christy’s graphs…
E. Swanson,
You seem to be confused. Christy did not compare surface with mid troposphere.
mpainter,
I don’t deny being confused regarding what Christy did with the KNMI data. In his 2 February 2016 testimony, Christy wrote:
I was able to access 102 CMIP-5 rcp4.5 (representative concentration pathways) climate model simulations of the atmospheric temperatures for the tropospheric layer and generate bulk temperatures from the models for an apples-to-apples comparison with the observations from satellites and balloons.
In my reading of the KNMI data set, it appears to offer only monthly data at 3 pressure levels. Christy has not offered any details about the method used to convert these monthly data into simulated TMT time series. For example, how does Christy treat the surface influence on the TMT, such as the impact of declining sea-ice or the influence of high altitude land forms, such as Antarctica? As far as Gavin’s work, did he just obtain the processed model data from Christy, or did he start from scratch and produce his own simulated TMT from the models? Of course, none of these questions have been answered in published peer reviewed papers…
Apparently none others share your confusion. Christy clearly did not compare surface data with mid troposphere data, as you claimed. As for the methodologies of UAH, these have been published or are in publication (V6). For the methodology of Gavin Schmidt, perhaps you should consult him at RealClimate.
E. Swanson,
John Christy provide this information in the previous Climate Audit post:
-Chip
Chip Knappenberger,
Thanks for the link. The listing of the pressure levels used would appear appropriate, were it not for the other claim that the KNMI Climate Explorer is the source of the CMIP-5 rcp4.5 model results. These data are monthly averages, which Christy claimed on his graphs to be his source. So, where can one find the temperature vs pressure level data at his source?
Besides, his implication that monthly data can be used to simulate daily and seasonal variables, such as snow/sea-ice/ocean emissions and storms with rain and hydrometeors, both of which influence the TMT, continues to give me considerable distress. And, one must understand that his TMT weighting function is an idealized model based on the US Standard Atmosphere, not real world weather, with seasonal changes, such as the change in the pressure level of the tropopause between summer and winter at high latitudes. One size does not fit all measurement conditions…
“…continues to give me considerable distress. ”
###
E Swanson, perhaps your distress is due to your false claim that Christy compared surface data with mid-troposphere data, which false claim you have yet to correct or withdraw. Perhaps you are distressed because your honesty is seen to be questionable.
mpainter,
Perhaps you question about honesty should be addressed to Chip Knappenberger. As Gavin Schmidt noted, his graphs use the model data as provided by Knappenberger. My comments regarding whether Christy used surface temperatures was a question, that is, I don’t know the source of the data which Christy plotted in his graphs, thus I suggested that he used the surface data from the KNMI Climate Explorer as noted on those figures. Now, if Kappenberger were interested, he could provide us with the chain of processing for these data leading back to the claimed source of the CMIP-5 model results. Since Kappenberger has not replied to my previous query, I assume that he has no answer to my question regarding the source of these data…
E Swanson, you avoid the pertinent issue: Gavin Schmidt’s histogram is the clincher.
It shows even more starkly the discrepancy between model products and observations. Thus the models are condemned by their own results.
Schmidt, scientist-aspirant, intended to refute but instead supplemented and re-enforced the point of John Christy. Were Gavin possessed of any critical faculty, he could have avoided this ironic result.
Surface datasets show the same discrepancy between model products and observations, as Roy Spencer has shown in his own comparison of these. Hence your attempt to discredit the observations is unavailing of the Cause.
I note that you have refused to correct yourself in your false attribution of a surface to troposphere comparison by John Christy.
mpainter,
Are you Chip Knappenberger? Or, do you have absolute knowledge of the source of his data, (which is likely Christy’s work)? Are you aware (and do you care) that Christy’s graphs include fabricated data, i.e., the padded endpoint(s) on his 5 year averaged satellite results? Almost 13 years ago, I presented evidence which showed that S & C’s data over the Antarctic was suspect. They have never acknowledged this problem in the years since. Christy’s presentation of the unpeer reviewed, unpublished version 6 is little more than a political stunt, IMHO. Why should I (or anyone else) trust Christy now, especially as he has so forcefully allied himself with the denialist camp in his Congressional testimony?
“denialist camp”. Is this a scientific term?
And what “camp” do you consider yourself to be in, E. Swanson?
E. Swanson, presumably Richard E. Swanson of of Ashe Co., North Carolina, responding to your fusilade of questions:
1.”mpainter,
Are you Chip Knappenberger?”
..no, I am mpainter.
2. “Or, do you have absolute knowledge of the source of his data, (which is likely Christy’s work)?”
..yes, it is the link provided by John Christy in his comment on the previous post.
3. “Are you aware (and do you care) that Christy’s graphs include fabricated data, i.e., the padded endpoint(s) on his 5 year averaged satellite results?”
..i am aware that you have made other bald assertions about John Christy’s work, one of which is patently false, which falsehood you refuse to correct.
4. “Why should I (or anyone else) trust Christy now, especially as he has so forcefully allied himself with the denialist camp in his Congressional testimony?”
..Christy’s work is confirmed (and re-enforced) by the histograms for Gavin Schmidt, who has not “.. so forcefully allied himself with the denialist camp..” That’s why you (or anyone else) should trust Christy.
Probably Gavin did not realize that his histograms re-enforced and confirmed Christy. Doubtless he imagined it would support his own position. He in fact torpedoed his own arguments. IMO, this sort of self-destructiveness is typical of the AGW crowd. Their position is bereft of science and so they resort to all manner of contortions of logic and fact. Gavin has inadvertently torpedoed the whole of the warmmunist effort to uphold the models through discrediting observations. Roy Spencer has called their efforts as “silly”. I would add “and amusing”.
E. Swanson,
Please quote a numerical analysis theorem that states that one can run any numerical model forever without the error between the continuous partial differential equations (pde’s) and the numerical model of that system growing with time. And what if the numerical model is not even correctly approximating the continuous pde’s,.i.e., using the wrong dynamics? Lax’s equivalence theorem states that the pde’s that the numerical method is approximating are well posed (the primitive equations are not), and that the mesh size is sufficiently small to be close to the continuous
solution. The latter is not true for either global weather or climate models. Why do you think that the weather models are continually inserting new obs into the models – could it be that the error
between the models and reality is growing?
Jerry
mpainter, So, since you have outed me as a real person, taking what little privacy I might still enjoy, what’s your name and location? Put up of shut up, as they say.
I see you took no notice if the evidence I presented in my paper or the implications regarding S&C’s products. It appears that Christy may have applied his theoretical weighting functions to the model results. Did he use monthly data? If so, did he adjust for the surface effects, such as snow/sea-ice and the impacts of storms, particularly precipitable ice, and high elevation land on the result? Is applying a single weighting function appropriate for monthly averaged data which includes both land and ocean temperatures? The MSU/AMSU data from which the TMT is produced does include these effects, which tend to cool the resulting measurement relative to the surface. If Christy made no effort to adjust the model results, the simulated TMT would of necessity be too warm! Besides, where does Christy provide proof that using monthly averaged data, such as radiosonde data, adequately represent the MSU/AMSU hourly measured time frame on a global basis? Not to mention that the new V6 processing, which, unlike that of the earlier v5.6, may not include an effort to remove the effects of large storms on the data, but we must wait for the peer reviewed paper to learn what they did. Meanwhile, the US is in an election cycle, with one side refusing to consider any impact of AGW and climate change.
As for Gavin’s histogram, it appears that all he did is re-plot Christy’s model results, which does nothing to prove/disprove Christy’s simulated model results. Or, can’t you understand that simple fact?
Eric Swanson (RealClimate bloggonym) aka Richard E Swanson (per linked publication) aka E. Swanson (Climate Audit bloggonym) says
“As for Gavin’s histogram, it appears that all he did is re-plot Christy’s model results,..”
###
Quite the contrary, he did not re-plot Christy. Gavin’s first histogram showed a comparison of global TMT for which comparison he undoubtedly derived his figures independent of Christy, since Christy compared tropical TMT only.
Somehow you missed this global vs tropical.
Later, Gavin provided his tropical TMT histogram for which he must have used figures from his first (global) histogram.
Once again you fire a fusilade of baseless/false assertions. Seems to be habitual with you.
You still have not corrected or withdrawn your first falsehood.
Were you/are you associated with the NCDC national hq in Asheville, North Carolina (now the NCEI)?
“mpainter” descends into ad hominem attack with a baseless “guilt by association”, while ignoring the scientific facts at issue. Disclaimer: I have no association with the NCEI, not that it would matter if I had.
Gavin Schmidt’s RC post claims to have used Chip Knappenberger’s sourced data to create the histograms in his plots. He compares these to 4 graphs from Christy’s testimony, 3 of which are labeled “global” and the last is labeled “tropical”. Schmidt also separates the three different sets of TMT data, instead of using Christy’s average.
“mpainter” is just playing “climate ball”, trolling along, compounding it’s errors in the process.
Gerald Browning
“If the models are nowhere near reality and using the wrong dynamics, why argue about their output?”
Because arguing about whether their dynamics is correct or not is highly technical and in the face of bad faith on the part of modellers will be futile. Showing the output is wrong is accessible to all.
What you have shown about the structure of models being wrong will be very useful the day someone decides that they want to make a model which works better.
Greg,
The argument about the model dynamics being wrong is no more technical than all of the statistical arguments about the output. In the latter case, there is a lack of understanding of the underlying cause of the model errors. I have used actual ECMWF model graphical output (not statistical arguments of output) for a more direct indication of the problems with all global models. FYI I have now also checked the output of the U.S.A. NCEP global model with the anticipated similar results. The models are using the semi-implicit numerical method to enforce geostrophy (the linear balance equation) inappropriately on all scales of motion [need only see similarity between the global model output of geopotential (pressure) compared to global solution of the linear balance equation to see this – it can’t be any clearer than that]. This uncouples the large scale geopotential from the small scale noise (obvious in global model plots of vertical velocity) caused by the columnar forcing from Richardson’s equation (a result of the inappropriate hydrostatic assumption). The graphics and text (and associated manuscripts mentioned in the
Memorial to Professor Kreiss) are very clear as to the exact nature of the problem.
I have made the mathematical theoretical arguments in the manuscripts easy to understand
using simple textual explanations illustrated with actual global model output.
No need for obfuscation with statistical arguments. Read the info in the link below before saying that this is too complicated to understand.
https://drive.google.com/file/d/0B-WyFx7Wk5zLR0RHSG5velgtVkk/view?usp=sharing
Jerry
Greg,
If the readers have learned anything from this blog, it should be that minor tweaks (e.g. cherry picking) in the way that statistics formulas are applied can lead to quite different conclusions.
That is not the case with the theory of mathematical partial differential equations and is why Heinz and I used it to get to the bottom of the problems with the hydrostatic assumption.
Anyone reading this blog should have a basic understanding of calculus if they understand statistical mathematics (e.g. matrix theory and least squares analysis) and that suffices to understand the info in the link.
Jerry
Gerald Browning,
I say, with no disrespect, that it would benefit you to consider revising your view on this point. I think it would make you more effective in your communication of the problem. All technical folk are capable of understanding a comparison of key model outputs to observations – whether or not they have any training in theoretical stats. Very few people in my experience have any depth of understanding of numerical modeling. And, of those few, they are less interested in being told that there is an unwarranted error-prone approximation in a model than being told that the consequences of the approximation are X and Y on prediction of some specified key output variables.
All models carry error-prone approximations, so a hand-waving defence is readily available unless you can exemplify the consequences of such approximations on key variables of interest. I can cite many non-climate science examples where formulation errors are bounded by explicit (heat or mass balance, say) conservation in the numerical formulation, including instances where numerical dispersion of a physical front is varied as a poor man’s method for assessing the effects of physical dispersion. So the existence of such approximations does not per se make a model useless.
In this instance, you assert that the hydrostatic assumption leads to error in the vertical velocity field, at least at high wavenumber. To avoid uncontrolled error propagation, nonphysical suppression is then needed. OK, you have convinced me, but so what? So far, this just suggests that there may be a better way of formulating the governing equations. Until and unless you can translate your findings into some easily-grasped estimate of prediction error in atmospheric mass and heat transport, with consequent error X in this specified key variable, it will remain of interest only to the select few numerical analysts who understand what you are talking about.
kribaez,
So read Sylvie Gravel’s article on this site if you want to see errors between an actual hydrostatic global forecast model and observations grow to unacceptable size in a day. I can do the same thing with the ECMWF and NCEP models, but Sylvie’s manuscript has already done that. Try reading – it is amazing what one can learn.
Steve has used many very technical arguments using matrix theory. The actual numerical errors between analytic solutions and numerical approximations are shown in our BK2002 manuscript and in Browning, Hack and Swarztrauber. This type of comparison method is the standard way to demonstrate the accuracy of a given numerical method. The BHS paper is very illuminating at showing the impact of the large unphysical dissipation on the accuracy of the spectral numerical method used in the ECMWF, NCEP and Australian global models and the domination of the time truncation error over the spatial error. It was only known when these types of tests showed that time truncation error was dominating the error in the test cases and that the dissipation was destroying the spectral
accuracy. The Australians (Bourke) did not believe the test results or theoretical truncation analysis so I wrote a paper with them and with careful testing of their model, guess what.
The BK2002 manusript mathematically proves what the correct initialization constraints are (and they are not Richardson’s equation) and then demonstrates that is the case showing a realistic storm evolving in a limited area. The latter demonstration was so that a reader could see that the mathematical thoery is correct through visual demonstrations. If the math is so complicated, look at the plots. Note that the manuscript was accepted in the most prestigious atmospheric science journal
because the Editor was not a modeler.
Jerry
Jerry, I agree with kribaez. Your and my argument is strengthened by accurate statistical analysis of model output.
It is very important i think to engage the statistical argument because of the strong bias in the community to try to devise justifications of the models. For example the arguments of those like G. Cawley, who is not a PDE expert or a modeler, but whose test for model falsification is practically impossible to employ for GCM’s and thus can never result in falsification. Steve M and Lucia have done a good job here.
I am convinced there is a lot of bias in the reporting of GCM results, just as there is in CFD. Only the “best” results are reported and I have not seen any sensitivity studies with respect to either numerical parameters or “model” parameters. This situation is made worse by the large computer requirements to run the models. No one wants to “waste” computer time doing these studies.
kribaez, the inconsistencies you describe in model formulation are not best practices however. There are simple tests to do to expose the problems. Use grid refinement studies for example. Does the output converge as the grid is refined? This becomes particularly important when you are trying to improve a model. You must first distinguish error from numerical issues from error in the sub grid models. It’s a hard job, but its the only way to actually make significant progress.
krabaez,
Interesting login name. Exactly what do you mean by “technical folk” ? Please elaborate. Are you a modeler? Why use a fake name?
Jerry
David,
The standard errors used in all of mathematics are relative L_p (continuum) or l_p (discrete) norms
(in Banach spaces). The latter is what I had Sylvie use when she compared point wise obs over the U.S. with point wise model predictions at the same points. If you look at the norms the modelers use, they are not these standard relative norms, but e.g., a rmse that is difficult to interpret if one does not know the magnitude of the field with the mean removed (especially crucial with the geopotential that has a large mean) or a comparison to their own model analysis that is less than amusing. Basically they try to make things better than they really are by using nonstandard mathematics. Thus Sylvie used the correct mathematical error estimates and it showed that the models come unglued in a day.
kribaez stated that what was needed was a comparison between key met variables and obs and that is exactly what Sylvie did. This is old news. The new news is that the cause of that fast growing error is the use of the wrong dynamics, i.e. the use of the hydrostatic approximation and Richardson’s equation. And note this was not in one of the high resolution models as he stated, but the lower resolution Canadian model. The problem has been there for a long time.
Jerry
David,
The BHS manuscript was showing convergence for three different numerical methods on a sphere.
However, the large unphysical dissipation used in the global models destroyed that convergence.
This was showing that the basic numerical method was working fine, but the incorrect dynamics necessitated the large dissipation. This was separating out the numerical errors from the parameterization errors (in this case wrong dynamics) just as you recommended.
And the link shows how Richardson’s columnar equation has always led to large amplitudes in the highest wave numbers in the models because it results in discontinuous forcing, thus violating
the Bounded Derivative Theory. Only when Heinz and I restored the hyperbolic nature of the original system and mathematically proved that the multiscale hyperbolic system accurately describes the large scale motions in the atmosphere did the correct initialization constraints (and thus the reduced system that correctly describes the slowly evolving solution to first order) become clear.
And as I have continued to say, Richardson’s equation is not one of the correct constraints.
Here is a message I sent to Steve:
Steve,
Heinz and I both knew that the global climate and weather models were using the wrong dynamical equations over a decade ago (Browning and Kreiss 2002). I bided my time since then allowing the predicted divergence between the climate models and observations to become evident. Thanks to your diligence and fortitude, the evidence of that divergence has become overwhelming. Now that the two pieces of the puzzle are joined, i.e. the mathematical theory and divergence of climate models from reality, I decided to obtain the output from the acknowledged best weather model to demonstrate the mathematical theory and support the divergence data by again raising the reason
for the divergence of the climate models. I also have the output and NCL code for the USA NCEP global model to show that the ECMWF results are not unique (available on request).
Heinz had two wonderful traits: scientific curiosity and intellectual
honesty. I would not have been able to work with someone that did not have those traits. I have followed your blog for many years and can confidentially say that you have those same traits. I want to thank you for allowing me to post on your blog in order to bring to light facts that I knew would probably never make their way through the meteorological gate keepers.
There is obviously one question remaining. Can a PC model based on the correct dynamics produce a daily large scale forecast as good as or better than the global weather models running the wrong dynamics on super computers.
This may or may not be possible because of the poor observational data, but out of respect foe Heinz I will give it a try.
If that can be shown, then it would put the last nail in the coffin of nonsense.
Jerry
David,
I agree with your comments. You have probably noted the quite remarkable absence of publications on L2 convergence tests of GCM solution routines under grid-refinement of well-defined systems. I am fairly sure that this must reflect suppression of adverse results rather than the absence of such tests. In the very few publications I have found, the solutions do not converge under refinement, but the authors offer as a sort of defense the observation that the physics parameterisations are resolution-dependent. It is not clear to me why this should offer any comfort.
More recently, there are a number of publications suggesting a substantial new wave of GCM investment into adaptive gridding and nested LGR. Presumably this means that in the future the GCMs will still be wrongly formulated, but they can be wrong on a finer grid. Meh.
Isn’t it interesting that when the cold war was winding down, all of the DOD labs (Lawrence Livermore, Oak Ridge, etc.) got into the climate modeling game? Were they looking for the latest boondoggle to fund themselves? And this is not to mention atmospheric “scientists”.
Jerry
They need to know were an atomic cloud is going so global circulation models were created.
A lot of atmospheric scientists were employed in atomic labs before the AGW controversies.
I would rather like to know why Oak Ridge Labs gave a grant for the Hockey Stick.
All,
I have offered to answer any questions or clarify any points in the presentation given at the link above. I challenge any modeler or warmer to disprove any of my presentation with mathematical and/or numerical theory. If not, the Bounded Derivative Theory stands as correct and my arguments
demonstrate the correctness of the manuscripts in the Memorial to Professor Kreiss.
Jerry
Jerry, I do have a question about the hyper viscosity method. There is a recent paper by Jameson and Lopez-Morales on this type of method (by which I mean high order spatial discretization coupled with stabilizing filtering) for aeronautical CFD. Their paper made no pretense that the method was better than standard unwinding or artificial viscosity methods, but did say these methods might be good preconditioners for more standard methods.
“Stabilization of High-Order Methods for Unstructured Grids with Local Fourier Sectral Filtering: high-Re Simulations in Course Meshes,” Manuel Lopez-Morales and Antony Jameson, AIAA Paper 2015-2447.
1. Might this explicit filtering be superior to hyper viscosity?
2. There is obviously a lot of work to do to extend this to 3D and its clearly outside the “consensus” in CFD, but it looks interesting.
3. The main advantage seems to be ability to capture qualitatively reasonable solutions on grids that are too coarse for standard methods.
4. This paper does a reasonable job I think of putting things in proper perspective.
David,
Heinz and I wrote a manuscript on the use of different dissipation techniques that are typically
used when there is insufficient resolution to accurately compute the solution with the real value of viscosity. Heinz had derived an estimate for the number of wave numbers (resolution) one would need for the nonlinear incompressible Navier Stokes equations (unbelievably complex) in 2D and 3D. As you know this is the standard system used in turbulence studies. His estimates were bang on, i.e.,
when one used less than the required resolution the models blew up and when using the correct amount the solution converged to the continuum solution. Hyperviscosity produced a solution that either had a similar magnitude or phase, but not both. Note that similar tests can be run on any suggested
dissipation. Heinz’s manuscript was very controversial because it shed new light on the use of
variously claimed ad hoc methods. But no one could disprove his theorems and the manuscript was finally published. There was supporting numerical evidence in Math Comp by Heinz and me and else where by Bill Henshaw and me. I cna look up the references if you want.
Note that higher order dissipation methods eventually approaches the chopping method of removing all waves above a certain number and that method is very sensitive to the number of waves removed and the number of times it is applied.
Jerry
Yes, Jerry, I would appreciate getting the references
David,
Comparison of Numerical Methods for the Calculation of Two Dimensional Turbulence
G.L. Browning and H.-O. Kreiss
Math. Comp.
volume 52 number 186
April 1989
Pages 369-388
see reference 6 for the original estimates
I will have to find the Henshaw article if you want it also
Jerry
I tried to post the link on Real Climate. Not surprising that is went into a black hole.
The modelers do not have a leg to stand on. Only lots of hand waving.
Jerry
What link went to the black hole on Realclimate? Your link is there. Visible and working. Or is there an other one that you are missing?
It was comment 3 and last I looked it was not there. And what is their response to the mathematical facts. They now show the results of a simulation of a coupled atmosphere ocean model I know the ocean equations are not correct. I will get the correct ones from a previous student at Stanford (now a publishing Ph.D. who has developed the correct ones based on the BDT.
Jerry
Is it the link in comment No. 93 over here that you are talking about?
http://www.realclimate.org/index.php/archives/2016/05/comparing-models-to-the-satellite-datasets/
I found the link and corresponding denigrating comments on Real Climate. As usual not a scientific fact in any one to refute the presentation. When they can’t respond scientifically, that is their normal response. I do not normally post there for exactly that reason.
Jerry
And another intellectual one from Real Climate in response to my link
Barton Paul Levenson says:
19 May 2016 at 6:29 AM
GB, I’ll bet YOU disappear because you’re using the wrong dynamics.
Any mathematics here? The site is full of morons. 🙂 I await their scientific response to my challenge.
Jerry
They deleted the last two.
One where I asked Hank Roberts to state the Lax equivalence theorem – or was Peter also banned from the site.
Disgusting.
Jerry
Jerry,
1. I did read your pdf file and it looks correct to me even though even I as a specialist would need a week of full time to carefully read the theory paper and code up some simple stuff to “replicate” it. Based on your and Kreiss’ track record, my expert opinion is that your work is correct. And of course, no one in the climate world has shown the slightest indication that they have understood, much less read your paper.
2. It’s interesting that just now with finer resolution is the issue starting to show up in GCM output. In any case, the logical question to ask is why not address an obvious source of error?
3. As to dissipation, I’ve seen some evidence in some of Isaac Held’s posts of smearing of sharp features. So, yes any model will benefit by reducing numerical dissipation to a minimum. That’s perhaps one of the most fundamental truisms of numerical PDE’s.
4. Real Climate is from my point of view a waste of time. Their moderation policy allows free reign to trolls so long as they toe the party line. Further, the in line responses are annoying. Just respond at the end of the comment for crying out loud. Steve McIntyre does a far better job of moderation and keeping things readable.
5. The problem here goes very deep into the nature of modern CFD modeling groups. Having oversold the results of the models, any challenge must be met with disinterest (the first line of defense because its so easy) or a counterattack. An interesting example is the recent rehash of the Santer/Douglas train wreck about model statistical validation, with a silly defense from Gavin Cawley (and our friendly Ken Rice, the public relations flak for an astronomy department) that if accepted basically makes it practically impossible to falsify a model if its “weather noise” level is high. This is just stupid and political.
6. The result of this state of affairs is that the very best numerical PDE people are unwilling to wade into the fray and try to build improved models. I won’t name names. The end result is that the political strategy has worked to retard scientific progress. It’s sad but I think a lot of people bear a measure of shame for their denial that there is a problem especially those who are just really very ignorant of the technical details.
dpy6629,
Our earlier manuscripts use the Bounded Derivative Theory on simpler systems, e.g., the shallow water equations. Note that this theory is now well known in the applied mathematical and numerical analysis areas and has been applied to many other systems including oceanography and plasma physics.
Based on your and Kreiss’ track record, my expert opinion is that your work is correct. And of course, no one in the climate world has shown the slightest indication that they have understood, much less read your paper.
Not any real surprise. It revealed a number of serious errors that we corrected. You know how that goes – keep things in the community and keep others out.
They might have to do admit they made an error and do some work instead of just more model runs. 🙂
As you read in the link, the dissipation used in the models reduced the spectral accuracy by two orders of magnitude. So the spectral method is not anywhere near as accurate as shown in play tests.
Boy you are right on here.
I was told a story by a Navy person that the first attempts at submarine ballistic missile
launches failed because the numerical models miscalculated. Oops.
Well Heinz and I did and you see how the results have been buried. The horror stories I could tell about the reviews by modelers we received.
I won’t name names. The end result is that the political strategy has worked to retard scientific progress. It’s sad but I think a lot of people bear a measure of shame for their denial that there is a problem especially those who are just really very ignorant of the technical details.
Everyone is after grant money – damn the science.
Jerry
dpy6629,
If you have questions, want clarification, or simpler examples please ask.
The shallow water system is the simplest pde with multiple time scales. It has a slowly evolving component and two fast ones (3 equations – 3 components). The two fast ones satisfy a wave type equation and if the initial data is smooth in space and satisfies the two BDT constraints that the divergence (time derivative of pressure) and time derivative of the divergence are sufficiently small (the latter constraint leads to an elliptic equation for the pressure much as in incompressible flow)
then the solution can be guaranteed to evolve on the slow (advective/convective) time scale for a period of time. The term Bounded Derivative Theory comes from the process of generating constraints by ensuring higher and higher time derivatives are of the order of the advective component. In scaled equation terms that means that higher time derivative must be of order unity. The constraints are always elliptic and best solved by fast elliptic solvers. The theory also shows how to ensure a solution with inflow and outflow open boundaries will evolve slowly. The BK2002 manuscript shows that the theory is correct for a limited area containing an evolving mesoscale storm. But one must be very careful with the open boundaries, not just add dissipation 🙂 Hope this helps, but feel free to ask for further clarification.
Jerry
dpy6629,
Dave,
The shallow water equations essentially are
du/dt + g h_x – fv = 0
dv/dt + g h_y + fu = 0
dh/dt + h (u_x + v_y) = 0
where u and v are velocity components in the x and y directions, g is gravity, h is height, and f is the Coriolis parameter. Note that in mathematical terms this is a hyperbolic system
so is automatically well posed for the initial value problem and with appropriate boundary conditions also well posed for the initial-boundary value problem. Scaled versions appear in our earlier work,
but hopefully the above text will help you to understand the BDT without the scaling?
Jerry
Thank God for Doppler radar. 🙂
Jerry
Here is a fine quality scientific response to my link on Real Climate:
Ray Ladbury says:
19 May 2016 at 4:48 AM
Gerald Browning@94
Wrong. It will merely lie there undisturbed because, like all dog turds, no one wants to pick it up.
99
Do you see any mathematics here?
Jerry
E. Swanson:
This just gets better and better.
You are right and I stand corrected.
From Gavin Schmidt at RealClimate:
“To avoid discussions of the details involved in the vertical weighting for TMT for the CMIP5 models, in the following, I will just use the collation of this metric directly from John Christy (by way of Chip Knappenburger). This is derived from public domain data (historical experiments to 2005 and RCP45 thereafter) and anyone interested can download it here.Comparisons of specific simulations for other estimates of these anomalies show no substantive differences and so I’m happy to accept Christy’s calculations on this. Secondly, I am not going to bother with the balloon data to save clutter and effort; None of the points I want to make depend on this.”
###
Note the sentence that determines the issue; it bears repeating:
“Comparisons of specific simulations for other estimates of these anomalies show no substantive differences and so I’m happy to accept Christy’s calculations on this.”
Gavin indicates here that he has looked into the matter thoroughly. Your dispute is with Gavin Schmidt, E. Swanson. Have at.
Note also Gavin’s dodge on the balloon (radiosonde) data. This data best supports UAH data, compared to the other satellite datasets. So Gavin blithely dismisses the radiosondes.
Incidentally, John Christy in his Congressional testimony provides a chart that shows a .98 correlation between radiosonde and UAH data.
In fact, the whole of Christy’s testimony (linked above through Chip Knappenberger) is a very interesting read which serves as a guide on the AGW issues, thoughtfully and well written.
For example:
“It is a bold strategy in my view to actively promote the output of the theoretical climate models while attacking the multiple lines of evidence from observations.”
Well I see no mathematical partial differential equation or numerical analytic theory responses to my challenge to the modelers or warmers. Exactly as I surmised. As you have seen above they are good at name calling and character assassination, but not any theory.
Jerry
It bears pointing out that the problem of the GCM’s is more fundamental than mathematics. Note the cool outlier of Gavin Schmidt’s histogram which best approximates the observations. This is no accident.
This particular model comes from the Institute of Numerical Mathematics of the Russian Academy of Science. The model is known as INM CM4, (climate model 4).
These modelers have apparently devised a model intended to yield a product that is consistent with observations. According to R C Lutz, they achieved this by 1. Reducing the forcing of CO2; 2. Reducing the climate sensitivity by increasing the thermal inertia of oceans and reducing water vapor to levels observed rather than postulated.
Thus it appears that they have constrained positive feedback with observations, all in accordance with the approved principles of modeling as practiced everywhere but in climate science.
mpainter,
Please cite where any numerical model can be run for long periods of time and remain an accurate
approximation of the partial differential equations. The Russian model is not immune from this.
As I have pointed out earlier, the tuning can produce any answer you desire. I will look at their dynamics or model output if they documented it. I would be very surprised if they didn’t use
the hydrostatic approximation as that is the standard in the rest of the world. Do they have an interest in showing that fossil fuels don’t cause any problems?
Jerry
mpainter,
As I thought the Russian model approximates the hydrostatic system, not with the spectral numerical method (considered to be the best by meteorologists), but by finite differences. These results just confirm how even an inferior model can be tuned to provide any answer desired. And it also uses
the wrong dynamics.
Jerry
Has anyone heard from Steve? Is he OK or just extremely busy?
Jerry
hes readin all ur posts 🙂
Jerry, my understanding is that all of the models are “tuned”. The distinction of INM C4 is that its product is consistent with observations.
Please note I make no statement concerning mathematical deficiencies, only that the fundamental assumptions behind the GCM’s are flawed. The INM C4 shows that these could be adjusted to achieve a product consistent with observations. I’ll leave it to you to argue that the right result was achieved in the wrong way.
Yes, mpainter, all models of complex turbulent high Reynolds’ number flows must be tuned to have any chance given that computers are about 10 orders of magnitude too slow to do an eddy resolving calculation even for a wind tunnel model. And even such an eddy resolving calculation would not be the panacea often claimed.
One of the problems here as kribaez points out is that many of the sub grid models used are not grid independent. That’s a real problem even in CFD for large eddy simulations for example. At least RANS methods are grid size independent and it makes sense to speak of a grid converged result.
An excellent example of how models are developed and tuned is Mark Drela’s thesis at MIT. It’s dated 1985 and he goes through all the details for his 2D aeronautical method and code. He is fully honest about how many of these things, like most useful statements about turbulent flows, are as much leaps of faith as real science. But that’s the nature of this problem.
For those who read the link and might not understand what happened when the linear balance equation was solved.
The term e^(ikx) = cos(kx) + i sin (kx) can be used to indicate one term of an infinite Fourier series in 1D.
The magical thing about Fourier series (or Fourier integral transforms) is that they convert
derivatives to multiplications, i.e d/dx e^(ikx) = ik e^(ikx)
In the case of the balance equation, the Fourier series representation of an individual Fourier term on each side becomes
[(ik)^2 + (il)^2] phi_kl = rhs_kl
where the subscript kl indicates the coefficient of the term with x wave number k and y wave number l. Dividing through one obtains the solution
phi_kl = rhs_kl / [-(k^2+l^2)]
Here is the main point. The Fourier coefficients of the rhs are reduced by more and more as k and l become larger. Thus although the Fourier coefficients of the rhs had large amplitudes in the high wave numbers, in the solution they were reduced to the point of extinction. That is why the geopotential is smooth in spite of the roughness of the rhs.
Now the linear balance holds for the large scale (L ~1000 km), but not for smaller scales (L < 100km).
Thus the geopotential is wrong for the smaller scales and the models have uncoupled the large scale geopotential from the smaller scales (noise).
Please reread the link with this in mind and we can proceed to lesson 2 🙂
Jerry
I will answer any questions or clarify anything above. Just need to ask. 🙂
Jerry
Any questions or comments? I can go into more detail about Fourier series to show how the complex notation for infinite series can be reduced to the normal infinite real sine and cosine series.
The complex notation is used more often, but might be more confusing. Just let me know.
I can also go into more detail as to why the linear balance equation holds for the large scale, but not the smaller scales of motion. Your choice. 🙂
Jerry
Or did everybody fall asleep? 🙂
Jerry
In Gavin’s 5/7 RC post at http://www.realclimate.org/index.php/archives/2016/05/comparing-models-to-the-satellite-datasets/#more-18943 , he fortunately explains his objections to Christy’s plots in more than just a 140 character tweet.
Although his point that Christy’s 5-year smoothing with data padding is an unnecessary distraction is well-taken, I completely disagree with him that Christy’s baseline (passing the trendline through 1979) is “weird.” In fact, it directly allows one to visually compare the trends while still seeing the texture of the actual data. Since the trendline is computed using all the data, it does not single out any observation or subset of observations as Gavin claims. I would call Christy’s baselining “novel” or even “ingenious”, perhaps, but not “weird.”
However, an even more direct way to compare the trends is with Gavin’s histograms, and they clearly do show a big divergence between the models and the satellite data, especially for Tropical TMT.
What does bother me about the trend comparisons, both by Christy and Gavin, is that the models only use actual forcings up until 2005, and then the “RCP4.5” hypothetical forcing scenario after 2006. The comparison of trends should therefore either be only up until 2005, or else the models should be updated using actual forcings to 2015. If the models are horrendously expensive to run (either terms of $ or CO2 emissions), a valid shortcut for CO2 at least would be just to interpret the model outputs for RCP 2.6, 4.5, 6.0 and/or 8.5 to the actual CO2 experience.
Another thing that bothers me about the RCP scenarios is that they are based on hypothetical CO2 concentration paths, rather than hypothetical CO2 emission paths. All humans can hope to control is emissions, and there is already a substantial modeling problem to predict concentrations and therefore GHG warming from emissions. As I recall, only about half of all emissions since 1900 are still in the atmosphere, so it’s important to explain what happens to the other half. Do they disappear immediately, while the rest stays in the atmosphere forever? Or do emissions gradually get absorbed into the kudzosphere, oceans, etc over the decades? If the latter, will they eventually (with a half time of several decades) all be absorbed, or are the sinks meaningfully exhaustible? AR5 Figure SPM4.b shows an increase of ocean surface CO2 partial pressure comparable to atmospheric concentrations, but some of this is being gobbled by algae, plankton etc. and perhaps taken out as sediments, and the deep ocean is vast. A further complication is that if the globe is warming due to solar or other non GHG factors, the oceans will hold less CO2, driving up atmospheric levels.
Gavin admits that a CMIP5 ensemble “should not be seen as a probability density function for ‘all plausible model results’.” However, he admits that “it is often used as such implicitly” and then he himself constructs 95% envelopes abut the mean, so it’s still not clear how the ensemble spread should actually be interpreted.
I wrote, “a valid shortcut for CO2 at least would be just to interpret the model outputs for RCP 2.6, 4.5, 6.0 and/or 8.5 to the actual CO2 experience.”
Make that “a valid shortcut for CO2 at least would be just to interpolate the model outputs for RCP 2.6, 4.5, 6.0 and/or 8.5 to the actual CO2 experience.”
Hu,
Once again, can I draw your attention to the comment by Alberto Zaragoza Comendador on May 7th and the reference he included
http://onlinelibrary.wiley.com/doi/10.1002/2015JD023859/full
A forecast made with updated forcings (and taking into account the most recent heat uptake data) should yield results identical to RCP 8.5 according to the referenced authors. Christy’s comparison was based on RCP 4.5. If he had used 8.5, the discrepancy would have been even greater.
Hu,
You seem to continue to believe that the climate models accurately describe the real world.
If the weather models go awry in one day and need to daily insert obs in order to get back to reality, clearly the climate models are nonsense. Plus they are not even describing the correct set of dynamical equations.
Jerry
I’m not trying to make a case for the climate models, just trying to understand how they might meaningfully be compared to reality, given that some of their parameters are only known imprecisely, and that it must be impossible to model the turbulent troposphere without a lot of monte carlo error.
BTW, the only allusion that Gavin on 5/7 makes to this 5/5 post by Steve is his PS that “some people seem to think that [tweeting] is equivalent to ‘mugging’ someone. Might as well be hung for a blog post than a tweet though…”
Hu,
The dynamics of the atmosphere near the equator is totally dependent on the local heating
because the vertical velocity there is directly proportional to that heating. Thus there the dynamics becomes two dimensional, i.e., the shallow water equations driven by the heating forcing.
Because that heating is poorly understood, it is only logical that there would be larger differences
between the climate models and reality in that area. The theory continues to be correct.
Jerry
Hu, you say “Although his point that Christy’s 5-year smoothing with data padding is an unnecessary distraction is well-taken…”
###
Gavin’s post conspicuously ignores radiosonde datasets which confirm the satellite data. His entire post is based on strawmen which he sets up and demolishes all the while pretending that there is no issue with model reliability. His four points:
1. Baseline issue, which is no issue. The trend comparison is what counts.
2. Satellite structural uncertainty, and this issue is demolished by corroborating radiosonde data
3. Model structural uncertainty, which has no bearing but allows Gavin to indulge an effusion of confusion
4. Inconsistent smoothing, which issue Gavin himself confesses is “no big issue”.
Gavin’s last sentence:
“The bottom line is clear though – if you are interested in furthering understanding about what is happening in the climate system, you have to compare models and observations appropriately. However, if you are only interested in scoring points or political grandstanding then, of course, you can do what you like.”
We have it from Gavin: a histogram is the appropriate method of comparison of models and observations. Christy’s methods are “political grandstanding”. Never mind that the two methods show the same discrepancy between observations and models.
Except for the radiosondes, which Gavin ignores.
For those not at ease with complex numbers:
Assume the boundary conditions for the Laplacian are 0 on all boundaries. Then the solution can be expanded in the infinite sine series
phi = sum from 0 to infinity sin (pi k x/X) sin (pi l y/Y)
where X and Y are the sizes of the box.
Then the Laplacian of phi (partial^2/partial x^2 + partial^2/partial y^2) phi is
Laplacian phi = sum from 0 to infinity – (k^2 + l^2) sin (pi k x/X) sin (pi l y/Y)
Notice the factor – (k^2 + l^2) just as in the complex notation.
The right hand side can be expanded as
rhs = sum from 0 to infinity rhs_kl sin (pi k x/X) sin (pi l y/Y)
Then the solution is
phi_kl =- [rhs_kl/(k^2+l^2)]
because each term in the series on the left and right hand sides must be the same
Now one can see that the real amplitude of each wave number of the right hand side is reduced by the factor (k^2+l^2) that becomes larger for higher wave numbers, i.e., the amplitude is reduced more for higher wave numbers than for the lower ones. This means that the solution will be smoother than the right hand side because it will have less large amplitudes in the high wave numbers.
Jerry
There is one error in the discussion. Did you see it?
Jerry
For simplicity let X=Y (square box) and replace replace k^2 + l^2 by (pi/X)^2 (k^2 + l^2)
Jerry
Has someone on this site had calculus? If so please comment on the above so we can move on.
Jerry
Gerry..I had the old school three semester sequence, and two semesters of dif eq, a semester of numerical analysis, more statistics than I probably should have been exposed to in one life, and I simply cant stand the way mathematical expressions are conveyed here.
I also taught statistics, and worked developing macro models back in the day when we used key punch cards.
The real crux of the problem is, as you stated, the fact that we need something like 7 to 10 orders of magnitude greater computing power to model climatic behavior.
That, and the current models dont even attempt to emulate actual climatic behavior.
If the modelers were trying to emulate observations, theyre doing a really poor job. Since its possible to do so, and they dont, I assume this is because they dont wish to do so.
Of course, when we deal with individuals who dont grasp what a degree of freedom is, what independent observations are, who attempt to pawn off on us all a bizarre chimera like an “ensemble model mean”, I think solving PDEs is really the least of their problems.
BTW, your point regarding models’ tendency to drift:
“If the weather models go awry in one day and need to daily insert obs in order to get back to reality, clearly the climate models are nonsense. Plus they are not even describing the correct set of dynamical equations.”
is spot on.
David,
If possible I will write the equations in LATEX?
Jerry
you are very kind.
Was this helpful Steve?
Jerry
How does one get in LATEX mode?
Jerry
Test
davideisenstat,
Not sure this was worth it (debugged offline), but here it is. The main point is do you understand it.
For those not at ease with complex numbers:
Assume the boundary conditions for the Laplacian are 0 on all boundaries. Then the solution can be expanded in the infinite sine series
where L is the size of the box. Then the Laplacian of
of 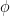 is
is
Notice the factor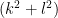 just as in the complex notation.
just as in the complex notation.
The right hand side can be expanded as
Then the solution is
because each term in the series on the left and right hand sides must be the same
Now one can see that the real amplitude of each wave number of the right hand side is reduced by the factor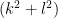 that becomes larger for higher wave numbers, i.e., the amplitude is reduced more for higher wave numbers than for the lower ones. This means that the solution will be smoother than the right hand side because it will have less large amplitudes in the high wave numbers.
that becomes larger for higher wave numbers, i.e., the amplitude is reduced more for higher wave numbers than for the lower ones. This means that the solution will be smoother than the right hand side because it will have less large amplitudes in the high wave numbers.
Jerry
davideisenstadt,
WordPress seems to have problems with debugged latex. 😦
jerry
davideisenstadt,
I simplified the Laplacian. Let’s try this
I’ve fixed up most of the LaTex. For Dr Browning, and others attempting to use LaTex here:
– Surround the LaTex with
$latex(your stuff)$– Be careful with auto-converted characters. One of Dr Browning’s final issues was of N-dash for the minus sign, instead of a plain dash character. Unfortunately, many word processors will make that substitution automagically. Aren’t they so nice 😦
– Spelling of LaTex “commands” matters. It’s \frac not \fract for example.
MrPete,
Thanks for finding the source of the problem.
I now feel that it is best to debug the LaTEX stuff off line and then store it on Google drive so that I am not debugging it on multiple messages. Did you understand the smoothing impact of inverting the Laplacian on the noise in the right hand side (large amplitudes in the high wave numbers of the right hand side)? That explains how the geopotential (essentially pressure) is so smooth in the ECMWF plots even though the vorticity is extremely noisey. And the vorticity is noisy because of the inappropriate use of Richardson’s equation for the vertical velocity (instead of the correct 3 dimensional elliptic equation) and rough forcing.
Jerry
I’m sorry, my math runs out before Laplace. 40 years ago I had enough to work through undergrad semiconductor electronics and related physics, but it never got used. 😦
I do understand enough to recognize the symbols etc… and I studied under Dr Knuth who invented TeX. But sadly this math is beyond me. (My dad would have much enjoyed all this: his PhD involved working out the mathematics of dendritic growth.)
MrPete,
LaTex is used by most scientists to write their manuscripts so you studied under a very famous Professor.
I used LINUX nroff for many years and the similarity between the two text processors allows for a fairly easy transition. Just need to swap
things like sub and sup for _ and ^. 🙂
Jerry
All,
Let’s go thru the Bounded Derivative Theory initialization for the shallow water equations.
The first thing one does is to determine the size of each of the terms in the equations for characteristic values of the independent and dependent variables for the flows of interest.
This can be accomplished by a change of variables but we will do it in a different way.
The atmospheric characteristic values for large scale features are L= 10 ^6 m for the x and y length scales of the flow, T=1 day (10^5 s) for the time evolution of the flow,U=10 m/s for u and v,
a mean value of height H_0=10^4 m, a perturbation from the mean height of H_1=10^2 m, and a value of g of G= 10 and the Coriolis term f of size F=10^-4
Now I will write the each term of the equations with its size beside it in parameters
u_t (U/T=10^-4) uu_x (UU/L= 10^-4) +vu_x (10^-4) + g h_x (G H_1/L=10^-3 – fv FU=10-3) = 0
dv/dt + g h_y + fu = 0
same scaling as for u equation
h_t (H_1/T=10^-3) + uhx (UH_1/L=10^-3) +vh_y (10^-3)+ h u_x (H_0 U/L= 10-^-1 + h v_y (10^-1) = 0
Now divide thru each equation by the magnitude of the first term to obtain
u_t + uu_x+ vv_y +10^1 (gh_x – fv ) = 0
v_t + uv_x + vv_y +10^1 (gh_y + fu) = 0
h_t + uh_x + vh_y +10^2 h (u_x+v_y) = 0
We have now scaled the equations for the slow time and space scales (advective) evolution of large scale atmospheric
flows. (Note that there are two components that evolve on a fast time scale of sqrt(10^3). We want to choose the initial data so that the solution evolves on the slow time scale. If we want the first order time derivatives to
be on the slow time scale O(1) then
gh_x – fv must be O(1/10)
gh_y + fu must be O(1/10)
u_x+v_y must be of O1/100)
Cross differentiating the first two we obtain the linear balance equation just as in the link
g (h_xx + h_yy) = 0 to first approximation
Also the horizontal divergence must be 0 to first approximation.
By requiring higher order time derivatives we obtain ever finer constraints on the initial data
to ensure a solution that will evolve on the advective time scale for a longer period of time.
Note that using this technique we can obtain a simpler system that accurately describes the slowly evolving component to first order approximation.
That system consists of the vorticity equation (-u_y + V_x)_t, the balance equation, and the divergence u_x_+v_y=0
Jerry
The mathematical estimates that are used to show that if the initial data are chosen appropriately, then the solution will evolve slowly in time reveal that the time and space derivatives are coupled together. Thus the solution cannot contain large amplitudes in the high wave numbers as from Richardson’s equation in the link.
Jerry
I’ll be gone until June 1.
Be happy to answer any questions when I get back.
Jerry
If you can understand the scaling of the shallow water equations and the concept of choosing initial data appropriately to not excite the fast wave components, then I can explain the rest of global dynamical meteorology using variations on that system.
Jerry
Jerry:
thanks for trying to get your work into latex for me.
im digesting it.
davideisenstadt,
Sorry that the one equation didn’t take. But hopefully you can determine what it was from the remainder of the text where the result of the Laplacian on phi is shown in the divisor of the rhs. Please ask any questions. The only dumb ones are the ones not asked. 🙂 The more people that understand what is going on the better.
Jerry
david eisenstadt,
Well iy doesn’t help you when I was missing a term. 😦
Try this link.
https://drive.google.com/file/d/0B-WyFx7Wk5zLWm8wU2tDRlpNMWs/view?usp=sharing
davideisenstadt,
sin (pi k x/L) sin (pi l y/L)
The second derivative of this term w.r.t. x is -(pi/L)^2 k^2 sin (pi k x/L) sin (pi l y/L)
and the second derivative of this term w.r.t. y is -(pi/L)^2 l^2 sin (pi k x/L) sin (pi l y/L)
Then the Laplacian is the sum of these two terms and results in the smoothing factor (k^2 + l^2)
in the denominator of the solution.
Jerry
thanks jerry.
its been decades (literally) since I played around with laplace transforms.
I did not know, or understand, just how the amplitudes of higher wave numbers were affected.
If you didn’t pop the hood up and let us look at the engine, I would still have no idea.
davideisenstadt,
Thank you for taking the time to understand the math. Hopefully it will help others too.
Once you understand the smoothing, you can see how the linear balance equation (enforced by the semi-implicit
numerical method) has been used to hide all the noise in the high wave numbers. Amusing that what they show on TV are the high and low pressure centers, i.e., essentially the geopotential after this smoothing.
The next step is to understand why the linear balance equation is not correct for the high wave numbers so they have hidden this dynamical error thru the smoothing. We can work on this thru the shallow water system.
Venus does not like my pseudo equation method, so when I get back I will make a link to its tex output.
The final step is to see that Richardson’s equation (result of the hydrostatic approximation) is the wrong equation
for the vertical velocity and causes extreme noise in the high wave numbers. This has also been hidden by the linear balance equation and unphysically large numerical dissipation.
Hopefully then the BK2002 paper will make sense.
Jerry
send an email to wordpress w ur latex grievances and
make us a nice recap after ur hols..
im not going to read any of what you wrote so far..is a mess innit
ta
The shallow water equations essentially are written in LATEX standard form. Subscripts and superscripts are easy to understand. I don’t want to go thru word press with the LATEX version and not have it work. If you want the LATEX output you can access our first manuscript with Akira Kasahara and Heinz. It has the same scaling parameters
and a more formal mathematical scaling treatment, i.e., a change of independent and dependent variables.
Jerry
Venus,
I will generate the tex output from the shallow water discussion when I come back. This is a critical piece of the pie
so I want it to be clear to everyone. Do you now understand the impact of the smoothing when inverting the Laplacian?
Jerry
One last try. If this doesn’t work I will post a link to the LATEX output.
Jerry
Word press definitely has a bug.
Jerry
It’s the minus sign. Something converted it from a plain dash (-) to an n-dash typesetting character (–). Very hard to see!
davideisenstadt,
Here is a link to the Laplacian smoothing
https://drive.google.com/file/d/0B-WyFx7Wk5zLOUxYM3EwN19MUFU/view?usp=sharing
davideisenstadt,
Looks like the link is working. Ignore the word latex at the beginning of each equation because that was for the dumb word press latex. 🙂 If you want you can remove that word and run the text thru latex for a clean version.
Jerry
davideisenstadt,
Just a piece of additional math. The reason that each term on the left must match each term on the right is because the basis functions are linearly independent (in fact even orthogonal). 🙂
Thus it suffices from the beginning to look at a single term, but I wanted to be precise so that everyone could see the entire series method before taking the shortcut.
Jerry
related:
http://www.climate-lab-book.ac.uk/2016/slowdown-discussion/
I
I once attended a lecture by Gerald Meehl and asked him some technical questions about the climate model he was using at NCAR. he had no clue about the internal workings of the model, I.e. It was a black box to him. Doesn’t,t say much about The quality of climate modelers.
Jerry
Dr Browning:
My own experience with Macroeconomic models led me to suspect multidimensional models whose performance didn’t exceed those of simpler models.
Steve in earlier pieces, has demonstrated that calendar’s one dimensional model (co2 only as an independent variable) delivered better results than current GCMs..
To me this indicates that the unexplained variance that other independent variable bring to the mix outweighs their p[redictive utility.
Given that we are about 7 to 10 orders of magnitude away from being able to attempt to model climate, I and unable to understand just what utility GCMs actually have.
perhaps you could enlighten me?
Hi davideisenstat, I am not Jerry, but I can tell you what the defenders of GCM’s say. It is basically that while there is little quantitative skill, they are tools for “generating understanding.” I suppose this means perhaps finding mechanisms that might explain broad trends.
I myself don’t find the above justification very persuasive. The problem I think is that such a high percentage of research spending is used to build, maintain, and run GCM’s that we are crowding more fundamental research such as Jerry’s work. It’s far easier to just “run the code” and analyze he results. There is more career risk in attempting to really advance theoretical understanding or do rigorous theory.
Yes, the fact that observation based estimated for ECS and TCR haven’t changed all that much in the past few decades (Nic Lewis’ work aside) says much.
30 years billions of dollars and little progress on the most fundamental aspect of climatic behavior seems a bit…mediocre.
davideisenstadt,
Have you perused the link on the shallow water equations? If you have, let me know where I need to clarify anything.
I can use slight variations on the shallow water equations to explain much of atmospheric dynamics without going into detail about the physics.
Jerry
Has anyone heard from Gerald Browning recently?
I am in CA. Be back Tues
Thanks, kribaez, for reminding me above of the link by Alberto to the article by Outten, Thorne, et al. at onlinelibrary.wiley.com/doi/10.1002/2015JD023859/full . The sequel by Thorne, Outten, et al. at onlinelibrary.wiley.com/doi/10.1002/2014JD022805/full is also very relevant.
These authors investigate the effect of using actual forcings post 2006 to replace RCP 8.5 projected forcings in the NorESM CMIP5 model. They find that it doesn’t make much difference. As it happens, the adjustment to volcanic, solar, and aerosol forcings is an order of magnitude larger in effect than for GHGs. In fact, (per Wikipedia on RCPs), the 4 RCP scenarios don’t differ much at all in 2010 or even 2020. So although Christy’s comparison of actual satellite data to RCP projections is wrong in principle, in practice it wouldn’t make much difference to use actual forcings.
In the second article, they do a quasi-Monte Carlo simulation of the NorESM model for both the “Reference” RCP forcings and the actual “Sensitivity” forcings, by constructing 30 simulations of each. For each, they start in 1/1/80 with 3 standard CMIP5 initializations, and then perturb each 10 times with “microscopic” random noise in the ocean temperatures. Evidently this is enough to make the simulations diverge and then stabilize into a common distribution after a decade or so.
Figure 6 in the second article shows whisker plots for the 1998-2012 global trends in each 30-member simulation, compared with four instrumental surface temperature indices, for annual and 2 seasons. With 30 simulations, the whisker plots, including any outliers, represent non-parametric 93.5% CI’s. In all cases, the instrumental values lie just below or near the bottom of the whisker plots, so that in IPCC jargon the NorESM is “very likely” (prob. > 90%) invalid. (Including parameter and forcing uncertainty would reduce the rejections, but on the other hand would make the forecasts less precise.)
The CMIP5 ensemble is very different, since it is not a Monte Carlo simulation. However, it seems to me now that its members could still be tested one at a time relative to surface instrumental or satellite data, by testing for differences in trends. Since the difference in trends is just the trend in the difference, the easiest way to do this is to take differences first and then test the trend for zero slope using standard errors like Gavin computes for the satellite trends. I’m not sure if he corrected for serial correlation, but the simple Quenouille-Santer adjustment should be adequate if the correlation is less than .3 or so.
The result would not be a blanket statement that all models are rejectable or non-rejectable, but rather a list of which ones are rejectable and which not. I’m guessing that most would be IPCC “likely” to “very likely” invalid (prob. > 66% or 90%), with a few “extremely likely” or even “virtually certain” to be invalid (prob. > 95% or 99%). I’ll leave it to someone else to run these, however.
Thanks for the histograms, Gavin!
“The CMIP5 ensemble is very different, since it is not a Monte Carlo simulation. However, it seems to me now that its members could still be tested one at a time relative to surface instrumental or satellite data, by testing for differences in trends. Since the difference in trends is just the trend in the difference, the easiest way to do this is to take differences first and then test the trend for zero slope using standard errors like Gavin computes for the satellite trends. I’m not sure if he corrected for serial correlation, but the simple Quenouille-Santer adjustment should be adequate if the correlation is less than .3 or so.”8
Ken —
You seem to have prematurely hit “send”.
My tablet failed me in the above post.
“The CMIP5 ensemble is very different, since it is not a Monte Carlo simulation. However, it seems to me now that its members could still be tested one at a time relative to surface instrumental or satellite data, by testing for differences in trends. Since the difference in trends is just the trend in the difference, the easiest way to do this is to take differences first and then test the trend for zero slope using standard errors like Gavin computes for the satellite trends. I’m not sure if he corrected for serial correlation, but the simple Quenouille-Santer adjustment should be adequate if the correlation is less than .3 or so.”
I have been doing analysis of the individual CMIP5 models and comparing the results to the observed values for not just temperature trends but for variation in temperature series, ARMA model to fit the red/white noise, N versus S hemisphere warming and more recently contrasting warming rates of land versus ocean. Additionally there are intra model comparisons that can be made such as the linearity of the regression of TOA net downward radiation versus global surface temperatures and ECS and TCR. Some of these comparison can have variables that have dependency on one another but I think to obtain a complete comparison the more comparisons the better. Doing many comparisons can test for getting a “correct” answer for the wrong reasons.
One at a time testing of models versus observed temperature trends runs up against the problem of the observed being from a single realization of a chaotic climate. That requires either determining where that single realization fits within the distribution of multiple individual model runs, or alternatively, without sufficient individual model runs, modeling the noise of the model and/or observed and doing Monte Carlo simulations to estimate trend distributions.
I think correcting for serial correlation is best done by Monte Carlo simulation and with the computing power of desktop computer done quickly. It allows for better adjustment for serial correlation were the model is not simply ar1 and can even take into account the uncertainty of the of the ARMA coefficients where it is large.
By the way none of the models passes all the statistical significance tests for all these variables and in fact most fail a goodly portion of these tests.
There is something bugging me about all of this. I am saying to myself, “What if I/we are asking the wrong question? That’s followed by, “If so how and what is(are) the source(s) of my error(s)?”. Do these groups ask these questions? Are these questions getting into publication? If yew, then please point me to them. If not, why not? The last one is rhetorical.
Ken —
Thanks! Which models failed at what significance level? Which passed?
I agree that just comparing single model runs against instrumental temperatures doesn’t take into account the model uncertainty. However, if you’re willing to assume that the models are sufficiently alike that they all have about the same uncertainty, you could use the 30 perturbations of the Norwegian NorESM model described by Outten and Thorne above as representing the uncertainty of the other models. For any summary statistic like Tropical TMT trend, 1998-2012, you could generate an artificial ensemble from model X by comparing its point estimate to the median of the NorESM runs, and then construct 30 pseudo-monte carlo runs by adding on the differences of NorESM from its median. Then find the average type-I error across the 30 “samples”.
This still wouldn’t take into account parameter uncertainty. Parameters like the emissivity of CO2 are known to very high precision, but I’d guess that many of the others aren’t so well known. Another day…
Taking model uncertainty into account would allow a lot more of them pass, but at the cost that their forecasts would be much less precise!
It happens that the spread across models that Gavin finds for eg Global TMT, 1979-88 (about 0.5dC for Gavin’s 95% envelope) isn’t much difference than the spread across simulations in the NorESM model (about 0.4dC for Global annual mean anomaly, 1981-2010 in Thorne and Outten Figure 3 top). The total range with 30 observations is a 1-2/31 = 0.935 nonparameteric CI, so this corresponds roughly to Gavin’s 95% envelope.
This suggests that perhaps most of the CMIP5 models are basically just perturbations of virtually the same model. This would make sense if they are all based on very similar assumptions about climate, with just minor variations in implementation. However, a few of them stray from the pack and therefore may actually be different, so that it is not fair or legitimate to pass or fail all of them as a group.
Or, rather than using the NorESM simulations to project what similar simulations of the other models would look like, you can just, as an illustration, run the test on NorESM using its actual simulations, if they are archived. I.e., for each of the 30 NorESM simulations, compute the trend of the desired difference, and compute the p-value for the null that the trend of the difference has zero slope, appropriately correcting for serial correlation. Then average these p-values over the 30 simulations to get the final figure.
This can only be done with NorESM for 1998-2012, since they started with tiny perturbations in 1980 in order to allow 18 years for the chaotic climate system to effectively randomize before the 1998 beginning of the “hiatus” that was their primary concern. Also, they didn’t have all the data after 2012. This is shorter than Christy’s period, but it’s enough to illustrate the test. It should also be recognized that a 1998 start year will make the models look especially bad, since they don’t forecast the extremity of the El Nino of that year.
Hu, I need to post my current model to observed comparisons here in the next day or two.
I agree with your comment about model spread that allows it to encompass the observed can in turn be too large to be meaningful. This point is made too infrequently on both sides of the AGW debate.
Without sufficient individual model runs to compare to the single observed realization, I have found that using Singlular Spectrum Analysis allows for non linear trends and decomposition of the temperature series into trend, quasi periodical/cyclical and red/white noise. In these analyses I find no evidence for significant periodic components in either the modeled or observed series and thus I can model the residual noise with ARMA. I have found that confidence intervals determined from those models having multiple runs agrees well with those determined from Monte Carlo simulations using ARMA models.
If an ar1 model is assumed a number of the models have ar1 coefficients that are significantly different than that of the observed and of other models.
Here is the link to the LATEX version of the Bounded Derivative Theory (BDT) introduction using the shallow water equations.
I have tried to explain the BDT using this simpler (?) system, but I am sure there will be questions. Feel free to ask. 🙂
https://drive.google.com/file/d/0B-WyFx7Wk5zLWE5sanJZLTZsSVE/view?usp=sharing
Jerry
i found two errors in above link. Here is the new one.
https://drive.google.com/file/d/0B-WyFx7Wk5zLaVIzR3QtelZzb1E/view?usp=sharing
Jerry
What went wrong – why are the global climate and weather models using the wrong dynamics?
The hydrostatic equations that are used in all current global climate and weather models is not a hyperbolic system, although the system that was modified by the hydrostatic assumption to obtain the hydrostatic system is a hyperbolic system. Time dependent hyperbolic systems are mathematically well understood and have many good mathematical properties, including well posedness of the initial value problem and well posedness of the initial boundary value
problem. These properties are a necessary requirement for a numerical method to be able to converge to the continuous
solution of the partial differential equation system (Lax equivalence theorem). The hydrostatic system has neither of these properties. The multiscale system introduced by Browning and Kreiss retains the hyperbolicity of the original
system and has been proven mathematically to accurately describe not only the large scale motions of the atmosphere, but also the smaller scales of atmospheric motion. Being a hyperbolic system, the Bounded Derivative Theory (BDT) can be applied to the multiscale system to obtain initialization constraints to ensure the evolution of the slowly evolving in time (advective) solution of main interest to meteorologists. These constraints consist of a pair of elliptic equations: a two dimensional one for the pressure (or geopoential) and a three dimensional one for the vertical velocity. That these equations produce the correct slowly evolving solution has been demonstrated in Browning and Kreiss 2002 for both large scale and mesoscale atmospheric motions. We note that the use of these constraints with the time dependent vertical component of vorticity constitute the correct reduced system (accurate to first approximation) of the original system, i.e., not the hydrostatic approximation that results in Richardson.s columunar equation for the vertical velocity. The difference in smoothness of the vertical velocity required to ensure a slowly evolving solutioncan be seen by comparing numerical results from the two systems in the following link:
https://drive.google.com/file/d/0B-WyFx7Wk5zLR0RHSG5velgtVkk/view?usp=sharing
Jerry
Getting all the comparisons of CMIP5 models and observed temperature series results together in one table is going to take a little longer than I anticipated. I need to consider all of the uncertainties in the observed series in making the trend comparisons. The following paragraphs explain what needs to be taken into account. While the effects noted below are relatively small, consideration of these effects might change some of the significance testing at the margins and since I want to be as comprehensive as I can in these comparisons I need to update my analysis. The comparisons between models and observed of temperature series variance, serial correlation, ratio of warming for Northern and Southern hemispheres and warming slow down from 15 year periods to previous 25 years will not be effected by these considerations and in fact are the largest sources of model and observed differences.
In comparing climate model and observed trends where the models have sufficient multiple runs for obtaining a reasonable estimate of the variation, accounting for the noise in the observed series is not necessary and only the variation due to measurement and sampling error (MS) in the observed series is required. (The model series, of course, have no measuring and sampling errors). Using the observed variation other than MS would be double counting in this instance of comparison.
Another aspect of comparing global climate model and observed surface temperature series trends is that the comparison is often made between the air temperatures for land and ocean for the models and air temperatures for land and SST temperatures for the oceans. It can be readily shown using all the CMIP5 RCP scenarios that where the Land temperature is trending that there is a significant divergence between the Land, Ocean SAT and Ocean SST series, with the Land trending at a considerably faster rate than either Ocean SAT or SST and Ocean SAT series trend at a somewhat faster rate than Ocean SST series. It can also be shown that these rates of divergence are proportional to the land trend. In the observed series the Land and Ocean series show this same trending relationship. The divergence in the observed Ocean SAT and SST is less certain and depends on the particular observed series compared.
Anyway it is important to consider these phenomenon when comparing model and observed global temperature series. In the trend comparison that I made using 1976-1999 and 1976-1997 to 2000-2014 and 1998-2014 time periods the divergence effect had very little to no affect. As Cowtan et al. (2015) shows this effect can make a small difference when comparing longer term GMST trends (1975-2014) between climate models and observed series.
Ken
Did you read the comment from mpainter about the Russian model:
Posted May 22, 2016 at 1:33 PM | Permalink | Reply
It bears pointing out that the problem of the GCM’s is more fundamental than mathematics. Note the cool outlier of Gavin Schmidt’s histogram which best approximates the observations. This is no accident.
This particular model comes from the Institute of Numerical Mathematics of the Russian Academy of Science. The model is known as INM CM4, (climate model 4).
These modelers have apparently devised a model intended to yield a product that is consistent with observations. According to R C Lutz, they achieved this by 1. Reducing the forcing of CO2; 2. Reducing the climate sensitivity by increasing the thermal inertia of oceans and reducing water vapor to levels observed rather than postulated.
Thus it appears that they have constrained positive feedback with observations, all in accordance with the approved principles of modeling as practiced everywhere but in climate science.
Here is a model that uses inferior numerics compared to other global hydrostatic models and obtains a completely different result. This shows that any model can obtain any result that one desires by messing around with tuning the parameterizations even if the dynamics and physics are not accurate. Not a pretty picture and should give pause to anyone that believes that the climate models are anywhere near reality.
Jerry
I’ve often heard the models are ‘tuned’ (some would say fudged) until they more or less fit the historical trend. Since there is uncertainty about ocean heat uptake and a lot of forcings a model can use different numbers that are ‘consistent with’ some specific point in a very wide error bar. The most well-known case is aerosols but it also happens with land use, black carbon on snow, ozone and perhaps more. In the Marvel discussion it was shown that even non-CO2 GHG forcing (methane, N2O and F gases) is uncertain – according to GISS it was double the IPCC figure.
(GISS later disclosed ERF for 2xCO2 is 4.35w/m2, not 4.1. That would drive non-CO2 GHG ERF down from the 1.86 Nic calculates in that comment to 1.77 – still nearly double the IPCC value).
This is BEFORE computing the forcing ‘efficacy’, which adds another fudge layer. For example, most analyses of Pinatubo cooling find a sensitivity of 1 to 2C – but supposedly this is explained by low efficacy of volcanic forcing.
While one could use the GIGO argument to dismiss the models, and many have, the problem is that it smacks of handwaving. A modeler could respond that you have to prove him wrong on more specific grounds, or that he chose specific forcings for this or that reason. AFAIK the forcings used for every CMIP5 model aren’t published anywhere – you have to track them down individually.
The point of my comment is there is a paper making such a comparison, though strangely I haven’t seen it discussed anywhere.
http://onlinelibrary.wiley.com/doi/10.1002/2014EF000273/full
The key is figure 1.
http://onlinelibrary.wiley.com/enhanced/figures/doi/10.1002/2014EF000273#figure-viewer-eft253-fig-0001
It’s simply forcing minus heat uptake rate, which can be considered the ‘effective’ forcing realized so far (i.e. the heat that has not been spent warming water, warming the land or melting ice – and that therefore has been warming the atmosphere instead). The first thing to notice is the massive divergence among models – they’re all over the place, from 0.2w/m2 to 1.7. Unsettling.
The second thing to notice is virtually all models have lower values than AR5. In fact for the most part they’re also lower than AR4. In other words, in a model the realized warming is less than it would be if they were using IPCC values. That’s why they can match the historical temperature record while having a higher sensitivity than energy budget papers.
Whether this is specifically due to aerosols, or land use or some other forcing is unknown. Perhaps it’s because they overstate ocean heat uptake. Then again it’s not up to amateurs to guess what exactly they’re doing wrong.
There seems to be a double standard in that papers published on sensitivity are scrutinized heavily – as they should. If they used this ocean heat dataset the result would be 1% higher, if they started in 1900 rather than 1860 TCR would be unaffected but ECS would change significantly, etc etc. But the models can plug in implausible numbers and apparently it’s not a problem.
Another fudge layer appears to be non-ocean heat uptake. In GISS it makes 13% of radiative imbalance, as opposed to 6% per the IPCC (ocean uptake is 86% rather than 93%). In practice this can mean GISS can keep the same OHU as ‘reality’ while having an 8% larger radiative imbalance. Put other way, non-ocean uptake could be a way to help reconcile model and reality without admitting sensitivity is too high.
Has anyone seen any attempt by the modelers to refute the Bounded Derivative Theory or my discussion
of the problems with the ECMW and NCEP global models? Hard mathematics cannot be refuted.
Jerry
Hi Jerry, I don’t have any indication that GCMers have come to grips with the BDT. I did at one point spend a little time trying to interest some top notch mathematical engineering types in trying to build a new GCM using modern numerical methods. The reaction was thoughtful and recognized the need but pointed out the giant political headache such an effort would be for its leaders. There are plenty of wines to drink that offer a more rewarding experience for famous scientists.
However, I did find out about a DOE project called ACME which is a clean sheet effort that is underway now. If you google “ACME climate” you will find it. There is also an interesting news report about this effort and the modeling community’s reaction to it. You could contact them directly. I know the DOE labs have a lot of mathematically oriented numerical types on their staffs.
Any competent numerical analyst or applied mathematician wouldn’t touch climate modeling with a 10 foot pole.
This is just another boondoggle by DOE labs to find another sourced of funding.
Jerry
Our BK2002 manuscript appeared in the atmospheric science journal JAS and was reviewed by one of the most famous atmospheric scientists (Bennert Machenhauer). The modelers either do not read their own journals or just ignore the manuscripts they do not want to acknowledge. This is no surprise and speaks to the quality of their models and science.
Jerry
In his well known book, Roger Daley acknowledged the Bounded Derivative Theory and even used some of its scaling concepts to derive initialization constraints. The BDT is not unknown to meteorologists, just ignored
because of its serious implications for their models.
Have you looked at the link on the shallow water equations?
Jerry
Jerry, I read your document concerning the BDT applied to the shallow water equations. I had a couple of questions:
1. Your conditions are applied to the initial conditions. If you apply them at every time step, does that result in the simplified system you mention at the end? Seems to me that you might need to do that to keep the fast time scale noise from creeping into the solution.
2. The simple system is interesting as it is incompressible for the horizontal velocities (divergence of horizontal velocity is zero) and an elliptic equation for h. This system looks a lot like incompressible NS and the same methods might apply.
Dave
Dave,
1. Your conditions are applied to the initial conditions. If you apply them at every time step, does that result in the simplified system you mention at the end? Seems to me that you might need to do that to keep the fast time scale noise from creeping into the solution.
Yes, applying the elliptic constraints at every time step (using the time dependent equation for the vertical component of vorticity to advance the vorticity in time) is called the reduced system. Applying the elliptic constraints to the vertical component of vorticity only at the initial time is called initialization.
Note that Charney’s original scaling was only for large scale atmospheric motions in the mid-latitudes
and said nothing about the time evolution of the motion or motions near the equator. Yet it has been used incorrectly
for mid-latitude mesoscale motions and equatorial motions in all global models. The weather models update the vorticity every 12 hours in order to keep the wrong dynamics and inaccurate physics from going off track.
The BDT guarantees that the initialization process results in a smoothly evolving solution for both large scale and
mesoscale features globally for a period of time chosen in the scaling. Finer constraints can ensure that the motions will last longer, but eventually the finer scales will enter, especialy if the forcing (physics) is rough (small scale) as in Richardson’s equation. It is also possible to update the vorticity with the reduced system
and I would expect better forecastsof the large scale with less updating.
2. The simple system is interesting as it is incompressible for the horizontal velocities (divergence of horizontal velocity is zero) and an elliptic equation for h. This system looks a lot like incompressible NS and the same methods might apply.
Exactly. The original theory applies to any hyperbolic system with two fast waves. Kreiss showed that such a system can have only one of two forms. Amazing mathematics. One of the forms is essentially the NS equations
(entrophy, velocity, and pressure). When the pressure has a large mean (as in the atmosphere), the reduced system is incompressible and used in 2d and 3d turbulence studies.
Kreiss (and students Reyna and Henshaw) has derived mathematical estimates for the incompressible nonlinear NS equations with dissipation showing that all derivatives exist and are bounded in 2d. In 3d an additional assumption is necessary.
The estimates determine exactly what resolution is needed to resolve the continuum solution and the estimates are bang
on. (Browing and Kreiss Math Comp v52 n186 pp.369-388)
Jerry
Dave,
Some extra information you might find helpful. The meteorologists linearized the inviscid, unforced (no physics) hydrostatic equations about a state of rest (not realistic) and then were able to use the separation of variables
approach. The horizontal equations are the shallow water equations and the vertical separation values are called equivalent depths. The largest depth (external depth) is the one I used in the shallow water equation scaling (H_0). The smaller equivalent depths lead to smaller values of H_0 and are called internal depths. As H_0 becomes smaller, multiple time scales disappear and so the meteorologists think that initialization of smaller scale vertical features is not possible. The error here (in addition to the hydrostatic assumption) was not to include forcing.
Using the BDT theory we have now shown that for smaller scales (mesoscale and smaller) and for all equatorial scales,
the vertical velocity is directly proportional to the total heating with latent heating/cooling being the main component. Thus the correct reduced system is not the unforced shallow water equations, but the forced shallow water system with the horizontal divergence a function of the total heating. That this is correct is shown in BK2002.
I actually was responsible for coding the linear normal modes for Dave Williamson. When Bob Dickinson and Dave asked me to include vertical shearing (atmosphere not at rest), there were complex frequencies. They blamed it on my coding, but that was not the case. Complex frequencies indicted ill posedness (unbounded growth) of the system.
Heinz and I have a manuscript that shows that the initial value problem for the hydrostatic system is ill posed
because of vertical shearing.
Jerry
Steve,
Have some of these discussions helped your understanding of the problems with climate and weather models?
The mathematics has illuminated all of the problems with these models. Hopefully you can now begin to see the point of my link discussing the ECMWF model. Much has been hidden by the modelers and there have been many false claims.
Jerry
davideisenstadt,
Where are we with the shallow water equations? Do you have any questions? The more people that understand the BDT, the less likely the modelers can pull the wool over their eyes. 🙂
Jerry
Got through the shallow water, but Im curious about the interrelatedness of the models themselves…
How much code do they share?
are some of the models “offspring” of others?
Are they really all independent of each other?
If one can parametrize any of the models to perform adequately, why dont they?
davideisenstadt.
The ECMWF, NCEP, NCAR. and Australian models all are using similar code for the hydrostatic dynamical equations, namely the pseudo spectral method (Fourier transforms in longitude and Gaussian quadrature in latitude).
A global grid in lat/lon with a finite difference method has problems at the poles because of the singularity of the
Jacobian at the poles (horizontal velocities are multiple valued at poles). The spectral method the models use is suppose to solve that problem (although that is not quite the case – see Browning, Hack, Swarztrauber reference mentioned earlier). As I have shown the ECMWF and NCEP global models both use a semi-implicit method that
incorrectly forces geostrophic balance on the solution. Thus the dynamics of the models are almost identical.
The original NCAR atmospheric model dynamics was obtained from ECMWF.
The difference comes in through the physics (parameterizations). WHen ECMWF gave NCAR the dynamical part of their model, they withheld the physics (big secret). The obvious question is that if the parameterizations are accurately
describing the physics, why are there so many different versions. Does arbitrary tuning come to mind? 🙂
It should become clear that parameterizations are not perfect and the inaccuracy leads to large errors very quickly
(see Sylvie Gravel’s manuscript). To over come these problems in longer runs, the models are tuned to produce an energy spectrum that looks somewhat realistic, but is physically nonsense.
Jerry
If you want to see how much weather forecasters trust mesoscale model forecasts see the following link:
http://radar.weather.gov/
The entire U.S. is covered by doppler radar sites that can see severe storms approaching and show hook echoes that indicate possible tornadoes.
The time scale for mesoscale storms is only a few hours and there is very little mesoscale data for any mesoscale model on that time scale. To accurately describe a mesoscale storm in progress, a mesoscale model has to have the latent heating/cooling and vorticity accurate at the initial time. Good luck with that.
Jerry
I have compiled a rather extensive comparison of 4 variables of global temperature series using the 5 observed series of (1) Cowtan-Way’s version of HadCRUT4 (CWHadCRUT), (2) HadCRUT4 (HadCRUT), (3) NASA GISS with 1200 km extrapolations (GISS1200), (4) NOAA NCDC (GHCN) and (5) ERSSTv4 ocean and adjusted ISTIv1.0.0 land (NewKarl) and the CMIP5 models from the RCP 4.5 runs. The variables compared were temperature trends (1880-2005 and 1970-2005), AR1 coefficient from an ARMA(2,0,0) model of the detrended series 1880-2014 for the observed series and 1861-2100 for the modeled series, the warming ratio of the northern to southern hemispheres for the 1880-2005 and the variances of the residuals from the ARMA model (essentially white noise) of the detrended series using 1880-2014 for the observed series and 1861-2100 for the modeled series.
The trends were determined using Singular Spectrum Analysis (SSA) with L=15 years and groups 1 and 2 to reconstruct the trend. The heuristics for SSA of all the observed and modeled series showed no significant periodic/cyclical components. Using SSA allows for and handles conveniently non linear trends.
I was striving to estimate statistical significance between the modeled and observed series and modeled versus modeled series. It became apparent that comparing the single measured realization of earth’s temperatures with a modeled result even where the model has multiple runs will not yield to standard frequentist null hypothesis. A model with multiple runs will provide an estimated probability distribution that one can determine where the observed single realization might fit. That is clearly not the same method whereby the mean of the model is compared to an observed mean – since the observed has no mean and further the observed result cannot be located on a probability distribution, i.e. we do not know how close or far the result is from a mean that could only be determined if we had several realizations of the observed as would be analogous to making multiple model runs. An attempt can be made to estimate the distribution of the observed series by finding a decent fit, for example, to an ARMA model. A similar approach can be applied to a model with a single run. Unfortunately that exercise does not allow determining where on that distribution the single realization/run fits or in other words knowing the mean. Using simulations will not produce the necessary information to do standard hypothesis testing.
The best that can be done for the observed to model comparison where the model has multiple runs is to determine where on the probability curve of the model the observed result falls. For the analysis reported here this was accomplished using a t distribution. The standard deviation is used here in determining the distribution and not the standard error of the mean as would be the case in comparing means. Obviously, as the observed result falls to low probability values, the less likely that the observed result is part of the modeled distribution.
A standard null hypothesis test can be applied when comparing two models where both have multiple runs and that is what I did in these analyses.
Comparing the single realized observed result to a model without multiple runs is not amenable to any standard frequentist comparisons other than showing the results in a histogram in order to view what might be deemed extreme values or indicating that the single model runs cannot be used as part of the same distribution. That is the approach I used for the comparison of the observed and model without multiple run series.
The results of these analyses are linked with Dropbox to an Excel file.
The left-most part of the Excel worksheet shows arrays for the temperature series variables with all paired combinations of models with multiple runs. The probabilities listed in the arrays are probabilities of the model means or ratios (in the case of the variances) being zero for the means or 1 for the ratios by chance and thus can be used for rejection of the null hypothesis that the differences are zero or the ratio is 1. The yellow shaded results in the arrays are for rejection at the 5% level and the red text for rejection at the 1% level.
Moving from left to right in the worksheet shows next the arrays of all paired combinations of the 5 observed series variables with those of the models with multiple runs. Here the probabilities are for where on the probability distribution the observed results will fall with less than 5% probability shaded in yellow and less than 1% probability shaded in red.
Moving further to the right one can observe the histograms of the 5 variable results for the models with single runs with the corresponding observed variables shown with identifying colored Xs.
Comparing variable means of models with multiple runs provides the narrowest distributions and a more sensitive method of determining statistically significant differences. Acknowledging those significant differences amongst the models is important in avoiding the practice of using these model results as part of the same distribution in comparisons with observed series variables. Acknowledging these differences on a more objective basis might well also overcome the collegiality attitude that apparently is at work in avoiding judgments on the validity of the individual models or at least which come closest to representing the observed series variables. The most paired model differences are seen in the variance comparisons and then the trend for 1880-2005, followed by the trend for 1970-2005 and then the AR1 coefficient and finally the NH/SH warming ratio.
The comparison of the paired variables for the observed and multiple run model series shows that the most differences are for the 1880-2005 trend and least with 1970-2005 trend with the variables AR1, variance and NH/SH warming bunched together in the middle.
Models with single runs in my estimation are of little value in comparing those results with observed series and with other models. I also judge that there is sufficient evidence that would lead to not using the distribution of single runs for comparisons. I would consider models with only single runs as not serious efforts at being validated in any form or manner and should probably be better ignored or greatly downplayed. The great advantage of modeling over dealing with the earth’s single realization (and the only one we will ever have) is the ability to look at multiple realizations and thus a single run model is a wasted opportunity.
I suppose the results for the paired comparisons of the 5 variables for the models with multiple runs to the observed series could be used in grading the models capability to at least empirically approximate the single global realization, but it would have to be with the understanding that a frequentist approach to rejecting a null hypothesis is not possible. I think that a Bayesian approach that uses some theoretical considerations for constructing a prior probability might serve better in these evaluations and grading.
* The model temperature series is from the air immediately above the ocean surfaces (tas) while the observed series use SST (tos). There is a difference in the modeled temperatures trends from these two sources of temperature with tas being higher than tos and as a result the temperature trends for the models where adjusted downward by 6% for the above analyses and the warming ratios of NH/SH for the models was increased by the factor of 1.023.
Link to Excel file:
https://www.dropbox.com/s/zl71yyojsl5b5ns/RCP45_Observed_Compare.xlsx?dl=0
Steve,
Would a very simple refresher course in calculus be helpful, e.g., the definition of a derivative and examples of the application of that definition to sines and cosines in order to see how the formulas in the link were derived?
One only needs a trig formulas to do that, namely the sine of the sum of two angles.
Jerry
10 Trackbacks
[…] Schmidt’s Histogram Diagram Doesn’t Refute Christy […]
[…] Steve McIntyre: Gavin Schmidt’s histogram diagram doesn’t refute Christy [link] […]
[…] Steve McIntyre: Gavin Schmidt’s histogram diagram doesn’t refute Christy [link] […]
[…] 2015 data and referencing Christy’s Feb 16 testimony. I made some of these points on twitter, but some people seem to think that is equivalent to “mugging” someone. Might as well be hung for a blog post […]
[…] https://climateaudit.org/2016/05/05/schmidts-histogram-diagram-doesnt-refute-christy/ […]
[…] very good, and explained the various issues really well. Steve McIntyre, however, is claiming that Schmidt’s histogram doesn’t refute Christy. This isn’t a surprise and isn’t what I was planning on […]
[…] Merece la pena leer la entrada completa, para los de aficiones técnicas: Schmidt’s Histogram Diagram Doesn’t Refute Christy […]
[…] McIntyre conducted a review of Dr. Schmidt’s claims (https://climateaudit.org/2016/05/05/schmidts-histogram-diagram-doesnt-refute-christy/) noting that his analysis evaluates the diagram used by Schmidt allegedly supporting his claims […]
[…] data and referencing Christy’s Feb 16 testimony. I made some of these points on twitter, but some people seem to think that is equivalent to “mugging” someone. Might as well be hung for a blog […]
[…] and measured global temperatures and are not afraid of the deep weeds of mathematics and statistics this post by Steve McIntyre is well worth reading. Ever since John Christy presented graphs like the one below his analyses […]