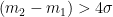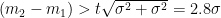Has anyone tried to replicate Santer’s Table 1 and 3 results? It’s not as easy as it looks. What’s tricky is that the table looks pretty easy (and most of it is), but, if you assume that it’s done in a conventional way, you’ll get wrongfooted. In fairness, Santer provided an equation for the unconventional calculation, but it’s easy to miss what he did and I was unable to verify one of the legs for the unconventional method using profile likelihood methods on the UAH data. The difference is non-negligible (about 0.05 deg C/decade in the upper CI trend).
We’ve also had some debate between beaker and Lucia over whether there was a typo in Santer’s equation – Lucia saying no, beaker yes. Lucia said that she emailed Gavin seeking clarification, but she hasn’t reported back to my recollection. Anyway, I can now see what Santer is doing in Table III and can objectively confirm Lucia’s interpretation over beaker’s.
First, here’s Santer Table 1:

Now here it is in a digital format (collated from the pdf to make comparisons handy)
loc=”http://data.climateaudit.org/data/models/santer_2008_table1.dat”
santer=read.table(loc,skip=1)
names(santer)=c(“item”,”layer”,”trend”,”se”,”sd”,”r1″,”neff”)
row.names(santer)=paste(santer[,1],santer[,2],sep=”_”)
santer=santer[,3:ncol(santer)]
Next let’s collect the UAH series for 1979-99 on (using a script on file at CA), dividing the year scale by 10 (because Table 1 is in deg C/decade):
source(“http://data.climateaudit.org/scripts/spaghetti/msu.glb.txt”)
x=msu[,”Trpcs”];id=”UAH_T2LT”
temp=(time(x)>=1979)&(time(x)<2000)
x=ts(x[temp],start=c(1979,1),freq=12)
year=c(time(x))/10;N=length(x);N #252
Column 3 (“S.D.”) matches the obvious calculation almost exactly:
options(digits=3)
c(sd(x),santer[id,”sd”]) # 0.300 0.299
The OLS trend calculations are pretty close, but suggest that the UAH version used in Santer et al 2008 may not be a 2008 version.
fm= lm (x~year)
c(fm$coef[2],santer[id,”trend”]) # 0.0591 0.0600
The AR1 coefficients from the OLS residuals are a bit further apart than one would like – it may be due to a different version of the UAH data or to some difference between Santer’s arima algorithm and the R version. (This is the step where Gavin got wrongfooted over at Lucia’s, as he did arima calculations for Lucia on the original series x rather than the residuals, as he acknowledged when I pointed it out to him.)
r= arima (fm$residuals,order=c(1,0,0))$coef[1]; #
c(r,santer[id,”r1″]) # 0.888 0.891
This difference leads to a 3% difference in the N_eff:
neff= N * (1-r)/(1+r) ;
r1= santer[id,”r1″]
c(neff,N * (1-r1)/(1+r1) , santer[id,”neff”]) ; #15.0 14.5 14.5
Now for the part that’s a little bit tricky. Santer describes an adjustment of the number of degrees of freedom for autocorrelation according to the following equation:

My instinct in implementing this adjustment was to multiple the standard error of the slope from the linear regression model by sqrt(N/N_eff) as follows, but this left the result about 7% narrower than Santer:
c(sqrt(N/santer[id,”neff”])*summary(fm)$coef[2,”Std. Error”], santer[id,”se”] ) # 0.129 0.138
It took me quite a while to figure out where the difference lay. First, the standard error of the slope in the regression model can be described in first principles as the ssq of the residuals divided by the degrees of freedom (fm$df = N-2) and the ssq of the time intervals (ssx):
c(summary(fm)$coef[2,”Std. Error”],sqrt(sum(fm$residuals^2)/fm$df /ssx) )
# 0.031 0.031
Santer appears to calculate his slope SE from first principles, describing the operation as follows:

If the N_eff -2 is used for the adjustment instead of N_eff, the Santer standard error of the slope can be derived:
c( summary(fm)$coef[2,”Std. Error”] * sqrt( (N-2)/(santer[id,”neff”]-2)) , santer[id,”se”] )
# 0.139 0.138
Santer did not provide a statistical citation for the subtraction of 2 in this context, but was conscious enough of the issue to raise the matter in the SI (though not the article):
The “-2” in equation (5) requires explanation.
Indeed.
Speaking in general terms, I don’t like the idea of experimental statistical methods being used in contentious applied problems. After a short discussion in the SI, they argue that their method is not penalizing the Douglass results because their method tends to run slightly low and thereby give a higher N_eff than the data itself:
The small positive bias in rejection rates arises in part because r1, the sample value of the lag-1 autocorrelation coefficient (which is estimated from the regression residuals of the synthetic time series) is a biased estimate of the population value of a1 used in the AR-1 model (Nychka et al., 2000).
Unfortunately Nychka et al 2000 does not appear in the list of references and does not appear at Nychka’s list of publications. In the predecessor article (Santer et al JGR 2000), the corresponding academic reference was check-kited (Nychka et al, manuscript in preparation), but 8 years later, the check still seems not to have cleared. (I’ve written Nychka seeking clarification on this and will report further if anything changes.) [Update – we’ve tracked down Nychka et al 2000 through a 2007 citation to it as an unpublished manuscript. The link at UCAR is dead, but the article is available here (pdf). Even though the article has not appeared in the “peer reviewed” literature, it is a sensible technical report and has much of interest. It builds on Zwiers and von Storch (J Clim 1995), another sensible article. It’s not clear to me as of Oct 23 that the method in Santer et al 2008 is the same as the methods in Nychka et al 2000, but I’ll look at this. ]
In the running text, they purport to justify their procedure using a difference reference:
The key point to note here is that our paired trends test is slightly liberal – i.e., it is more likely to incorrectly reject hypothesis H1 (see Section 4)
Turning to section 4, it states:
Experiments with synthetic data reveal that the use of an AR-1 model for calculating N_eff tends to overestimate the true effective sample size (Zwiers and von Storch, 1995). This means that our d test is too liberal …
I attempted to test this claim by comparing the Santer CIs to the CIs calculated using the profile likelihood method described previously. The black colors show 1999 data – which is the only data discussed here. The dotted vertical lines show the 95% CI intervals calculated from profile likelihood. The black dots show the intervals calculated using a sqrt(N/N_eff) adjustment relative to the maximum likelihood slope under AR1 – which in this case appears to be less than the OLS slope. The black triangles show the Santer confidence intervals.

The Santer 95% upper CI is 0.051 deg C higher than my result (0.336 vs 0.285). This result is exactly opposite to the assertion in Santer’s SI, as the expanded confidence intervals would make it more difficult to show inconsistency (rather than less difficult.)
I think that one can see how the Santer method might actually over-estimate the AR1 coefficient of the residuals relative to the maximum likelihood method that I used. The Santer results are NOT maximum likelihood for the combination of trend and AR1 coefficient. They calculate the slope and then the AR1 coefficient given the slope, whereas I did a joint maximization over both the slope and AR1 coefficient using profile likelihoods. In the specific examples, the AR1 coeffficient of this method is less than the Santer (N_eff -2) coefficient. This makes sense – the slope in the combined ML result is not the same as the OLS slope; the differences are not huge, but neither are the differences in the AR1 coefficient. So I’m not persuaded by the Santer argument for a combined ML calculation, even if it holds when the calculations are done one at a time.
As noted before, with the inclusion of data up to 2008, the upper CI declines quite dramatically to 0.182 deg C/decade (as compared to Santer’s 0.336), a change which may not be irrelevant when one considers that the ensemble mean trend is 0.214 deg C/decade. As noted before, the change arises primarily from narrowing of the CI intervals owing to AR1 modeling, with changes in the trend estimate being surprisingly slight.
Table 3
This is an important table as the results from this table are ultimately applied to significance testing. As noted above, controversy arose between beaker and Lucia over exactly what Santer was doing. Lucia’s interpretation (also mine) was that the only difference between the Douglass and Santer tests was the inclusion of an error relating to the observations and that both studies used the standard error of the model means; beaker argued that the appropriate standard error was the population standard error and argued that this must have been Santer used (however they made a typo in their article.) I can now report that Lucia’s interpretation can be verified in the calculations.
First let’s collect some data for the Table III calculations.
d1=1.11;d1star=7.16 #from Table III
trend.model=santer[“Multi-model_mean_T2LT”,”trend”]; # 0.215
# this is a little higher than the multi-model mean of Douglass Table 1 (0.208)
sd.model=santer[“Inter-model_S.D._T2LT”,1]; #0.0920
# this is a little higher than the multi-model sd of Douglass Table 1 (0.0913)
trend.obs=santer[“UAH_T2LT”,”trend”];trend.obs # 0.06
se.obs=santer[“UAH_T2LT”,”se”];se.obs #0.138
# this is the adjusted Std. Error of the trend estimate
M=19 #from Santer
Next we can verify that Santer’s Table III d1star calculation for his Douglass emulation (presuming his methods):
c( (trend.model-trend.obs)/ (sd.model/sqrt(M-1)), d1star)
## 7.15 7.16 #replicates Table III
Now here is the calculation yielding Santer’s Table III d1 result, proving that they used the standard deviation of the model mean (the method decried by beaker):
c( (trend.model-trend.obs)/ sqrt( (sd.model/sqrt(M-1))^2 + se.obs^2), d1)
#1.11 1.11
At this point, we really don’t need to hear back from Gavin Schmidt on what he thinks that they did. We know what they did.
![Reblog this post [with Zemanta]](https://i0.wp.com/img.zemanta.com/reblog_e.png)






 , i.e. what bayesians call a “posterior distribution”, but I’m just learning the lingo. The dotted vertical lines represent 95% confidence intervals from the profile likelihood calculations shown in a prior post, color coded by endpoint. The colored dots represent 95% confidence intervals calculated using the Neff rule of thumb for AR1 autocorrelation in Santer. The black triangle at the bottom shows ensemble mean trend (0.214 deg C/decade).
, i.e. what bayesians call a “posterior distribution”, but I’m just learning the lingo. The dotted vertical lines represent 95% confidence intervals from the profile likelihood calculations shown in a prior post, color coded by endpoint. The colored dots represent 95% confidence intervals calculated using the Neff rule of thumb for AR1 autocorrelation in Santer. The black triangle at the bottom shows ensemble mean trend (0.214 deg C/decade).

 . The dotted lines are as before; the solid color-coded vertical lines are the maximum likelihood trend estimates for the respective periods. Again for an analyst, the models seem to the the right of these estimates.
. The dotted lines are as before; the solid color-coded vertical lines are the maximum likelihood trend estimates for the respective periods. Again for an analyst, the models seem to the the right of these estimates.