One of the longstanding CA criticisms of paleoclimate articles is that scientists with little-to-negligible statistical expertise too frequently use ad hoc and homemade methods in important applied articles, rather than proving their methodology in applied statistical literature using examples other than the one that they’re trying to prove.
Marcott’s uncertainty calculation is merely the most recent example. Although Marcott et al spend considerable time and energy on their calculation of uncertainties, I was unable to locate a single relevant statistical reference either in the article or the SI (nor indeed a statistical reference of any kind.) They purported to estimate uncertainty through simulations, but simulations in the absence of a theoretical framework can easily fail to simulate essential elements of uncertainty. For example, Marcott et al state of their simulations: “Added noise was not autocorrelated either temporally or spatially.” Well, one thing we know about residuals in proxy data is that they are highly autocorrelated both temporally and spatially.
Roman’s post drew attention to one such neglected aspect.
Very early in discussion of Marcott, several readers questioned how Marcott “uncertainty” in the mid-Holocene could possibly be lower than uncertainty in recent centuries. In my opinion, the readers are 1000% correct in questioning this supposed conclusion. It is the sort of question that peer reviewers ought to have asked. The effect is shown below (here uncertainties are shown for the Grid5x5 GLB reconstruction) – notice the mid-Holocene dimple of low uncertainty. How on earth could an uncertainty “dimple” arise in the mid-Holocene?
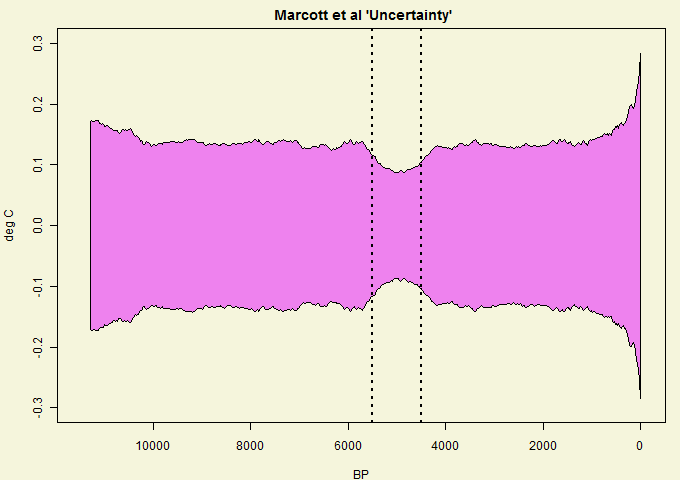
Figure 1. “Uncertainty” from Marcott et al 2013 spreadsheet sheet 2. Their Figure 1 plot results with “1 sigma uncertainty”.
It seems certain to me that “uncertainty” dimple is an artifact of their centering methodology, rather than of the data.
Marcott et al began their algorithm by centering all series between BP4500 and BP5500 – these boundaries are shown as dotted lines in the above graphic. The dimple of low “uncertainty” corresponds exactly to the centering period. It has no relationship to the data.
Arbitrary re-centering and re-scaling is embedded so deeply in paleoclimate that none of the practitioners even seem to notice that it is a statistical procedure with inherent estimation issues. In real statistics, much attention is paid to taking means and estimating standard deviation. The difference between modern (in some sense) and mid-Holocene mean values for individual proxies seems to me to be perhaps the most critical information for estimating the difference between modern and mid-Holocene temperatures, but, in effect, Marcott et al threw out this information by centering all data on the mid-Holocene.
Having thrown out this information, they then have to link their weighted average series to modern temperatures. They did this by a second re-centering, this time adjusting the mean of their reconstruction over 500-1450 to the mean of one of the Mann variations over 500-1450. (There are a number of potential choices for this re-centering, not all of which yield the same rhetorical impression, as Jean S has already observed.) That the level of the Marcott reconstruction should match the level of the Mann reconstruction over 500-1450 proves nothing: they match by construction.
The graphic shown above – by itself – shows that something is “wrong” in their estimation of uncertainty – as CA readers had surmised almost immediately. People like Marcott are far too quick to presume that “proxies” are a signal plus simple noise. But that’s not what one actually encounters: the difficulty in the field is that proxies all too often give inconsistent information. Assessing realistic uncertainties in the presence of inconsistent information is a very non-trivial statistical problem – one that Marcott et al, having taken a wrong turn somewhere, did not even begin to deal with.
I’m a bit tired of ad hoc and homemade methodologies being advanced by non-specialists in important journals without being established in applied statistical journals. We’ve seen this with the Mannian corpus. Marcott et al make matters worse by failing to publish the code for their novel methodology so that interested readers can quickly and efficiently see what they did, rather than try to guess at what they did.
While assembling Holocene proxies on a consistent basis seems a useful bit of clerical work, I see no purpose in publishing an uncertainty methodology that contains such an obvious bogus artifact as the mid-Holocene dimple shown above.


 Bobbie Hasselbring, editor of Real Food Traveller, has an article on “Aging as a State of Mind”. Her
Bobbie Hasselbring, editor of Real Food Traveller, has an article on “Aging as a State of Mind”. Her 





