Since the publication of Rahmstorf et al 2007, a highly influential comparison of models to observations, David Stockwell has made a concerted effort to figure out how Rahmstorf smoothing worked. I now have a copy of the program and have worked through the linear algebra. It turns out that Rahmstorf has pulled an elaborate practical joke on the Community, as I’ll show below. It must have taken all of Rahmstorf’s will-power to have kept the joke to himself for so long and the punch-line (see below) is worth savoring.
Rahmstorf et al oracularly described Rahm-smoothing using big words like “embedding period” and the interesting concept of a “nonlinear…line”:
All trends are nonlinear trend lines and are computed with an embedding period of 11 years and a minimum roughness criterion at the end (6 – Moore et al EOS 2005) …
David’s efforts to obtain further particulars were stonewalled by Rahmstorf in a manner not unreminiscent of fellow realclimatescientists Steig and Mann. I won’t recap the stonewalling history on this occasion – it’s worth doing on another occasion but I want to focus on Rahmstorf’s practical joke today.
In April 2008, a year after publication, Rahmstorf stated at landshape.org and RC that:
The smoothing algorithm we used is the SSA algorithm 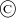 by Aslak Grinsted (2004), distributed in the matlab file ssatrend.m.
by Aslak Grinsted (2004), distributed in the matlab file ssatrend.m.
Unfortunaely Matlab did not actually “distribute” the file ssatrend.m, nor were David Stockwell and his commenters able to obtain the file at the time. When asked by UC (a highly competent academic statistician) where the file could be located, Rahmstorf, following GARP procedures, broke off communications.
A year later, I’m pleased to report that ssatrend.m and companion files ( Aslak Grinsted) may be downloaded from CA here – see the zip file. I’ve placed the supporting article Moore et al (EOS 2005) online here .
I transliterated ssatrend.m and its various functions into an R script here – see the function ssatrend.
Underneath the high-falutin’ language of “embedding dimension” and so on is some very elementary linear algebra. It’s hard to contemplate a linear algebra joke but this is one.
First of all, they calculate the “unbiased” autocovariances up to the “embedding dimension” – the “embedding dimension” proves to be nothing more than a big boy word for the number of lags (M) that are retained. This is turned into a MxM symmetric (“toeplitz”) matrix and the SVD is calculated, yielding M eigenvectors.
Another way of looking at this calculation step is to construct M copies of the time series of interest, with each column lagged one time step relative to the prior column, and then do a SVD of the rectangular matrix. (Some microscopic differences arise, but they are not material to the answer.) In this sort of situation, the first eigenvector assigns approximately equal weights to all M (say 11) copies. So the first eigenvector is very closely approximated by

They ultimately retain only one eigenvector (E in the ssatrend code), so the properties of lower order eigenvectors are immaterial. Following through the active parts of the code, from the first eigenvector (which is very closely approximate by the above simple form), they calculate a filter for use in obtaining their “nonlinear trend line” as follows (in Matlab code)”
tfilt=conv(E,flipud(E))/M;
Convolving an even vector by another even vector yields a triangular filter which in this case has the form:
(1 2 3 ……M ….. 3 2 1)/M^2
In the figure below, I’ve calculated actual values of the Rahmstorf filter for the HadCRU temperature series with M=11, demonstrating the virtual identity of the Rahmstorf filter with a simple triangular fllter ( The Team).

Figure 1. Comparison of Triangular and Rahmstorf Filters
In comments at RC and David Stockwell’s, Rahmstorf categorically asserted that they did “not use padding”:
you equate “minimum roughness” with “padding with reflected values”. Indeed such padding would mean that the trend line runs into the last point, which it does not in our graph, and hence you (wrongly) conclude that we did not use minimum roughness. The correct conclusion is that we did not use padding.
Parsing the ssatrend.m code, it turns out that this statement is untrue. The ssatrend algorithm pads with the linear projection using the trend over the last M points – terms like “minimum roughness” seem like rather unhelpful descriptions. Mannian handling of endpoints is a little different – Mann reflected the last M points and flipped them centered on the last point. I observed some time ago (a point noted by David Stockwell in his inquiry to Rahmstorf) that this procedure, when used with a symmetric filter, pinned the smooth on the end-point ( a procedure used in Emanuel’s 2005 hurricane study, but not used when 2006-7 values were low.)
Rahmstorf padding yields results that are a little different from Mannian padding, because the symmetric (very near-)triangular filter applies to actual values in the observed period, but uses linear trend values rather than flipped values in the padding period. If the linear trend “explains” a considerable proportion of the last M points, then, in the padding period, the linear projection values will approximate the flipped values and the smooth from one filter will approximate the smooth from the other filter. Rahmstorf’s statement that he did not use “padding” is manifestly untrue.
Given that the filter is such a simple triangular filter, you can see how the endpoint smoothing works. M years out from the end, it is a triangular filter. But at the last point, in Mannian padding, all the filter terms cancel out except the loading on the last year – hence the end point pinning. The transition of coefficients from the triangular filter to the one-year loading can be calculated in an elementary formula.
Turning now to the underlying reference, Moore et al 2005, I note that EOS is the AGU newsletter and not a statistical journal. [Update note: its webpage states: “Eos is a newspaper, not a research journal.” I receive EOS and often find it interesting, but it is not a statistical journal.]
Given that we now know that the various and sundry operations simply yield a triangular filter, it’s worthwhile re-assessing the breathless prose of “New Tools for Analyzing Time Series Relationships and Trends”.
Moore et al begins:
Remarkable progress recently has been made in the statistical analysis of time series…. This present article highlights several new approaches that are easy to use and that may be of general interest.
Claims that a couple of Arctic scientists had discovered something novel about time series analysis should have alerted the spidey-senses of any scientific reader. They go on:
Extracting trends from data is a key element of many geophysical studies; however, when the best fit is clearly not linear, it can be difficult to evaluate appropriate errors for the trend. Here, a method is suggested of finding a data-adaptive nonlinear trend and its error at any point along the trend. The method has significant advantages over, e.g., low-pass filtering or fitting by polynomial functions in that as the fit is data adaptive, no preconceived functions are forced on the data; the errors associated with the trend are then usually much smaller than individual measurement errors…
The widely used methods of estimating trends are simple linear or polynomial least squares fitting, or low-pass filtering of data followed by extension to data set boundaries by some method [e.g., Mann, 2004]. A new approach makes use of singular spectrum analysis (SSA) [Ghil et al., 2002] to extract a nonlinear trend and, in addition, to find the confidence interval of the nonlinear trend. This gives confidence intervals that are easily calculated and much smaller than for polynomial fitting….
In MC-SSA, lagged copies of the time series are used to define coordinates in a phase space that will approximate the dynamics of the system…
Here, the series is padded so the local trend is preserved (cf. minimum roughness criterion, [Mann, 2004]). The confidence interval of the nonlinear trend is usually much smaller than for a least squares fit, as the data are not forced to fit any specified set of basis functions.
Here’s a figure that probably caught Rahmstorf’s eye. The “new” method had extracted a bigger uptick at the end than they had got using Mannian smoothing. No wonder Rahmstorf grabbed the method. Looking at the details of the caption, the uptick almost certainly arises simply from a difference in filter length.

Fig. 2. Nonlinear trend in global (60°S–60°N) sea surface temperature anomaly relative to 1961–1990 (bold curve) based on the 150- year-long reconstructed sea surface temperature 2° data set (dotted [Smith and Reynolds 2004]), using an embedding dimension equivalent to 30 years; errors are the mean yearly standard errors of the data set. Shading is the 95% confidence interval of the nonlinear trend. The curve was extended to the data boundaries using a variation on the minimum roughness criterion [Mann, 2004]. For comparison the thin curve is the low-pass trend using Mann’s low-pass filter and minimum roughness with a 60-year cutoff frequency.
At the end of the day, the secret of Rahm-smoothing is that it’s a triangular filter with linear padding. All the high-falutin’ talk about “embedding dimension” and “nonlinear … lines” is simply fluff. All the claims about doing something “new” are untrue, as are Rahmstorf’s claims that he did not use “padding”. Rahmstorf’s shift from M=11 to M=15 is merely a shift from one triangular filter to a wider triangular filter – it is not unreasonable to speculate on the motive for the shift, given that there was a material change in the rhetorical appearance of the smoothed series.
Finally, I do not believe that the Team could successful assert a copyright interest in the triangular filter ( The Team).































