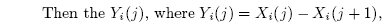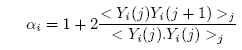Sometimes we hear that science is "self-correcting". To be "self-correcting", however, individual people have to step up to the plate now and then and actual do the work. To the extent that the term "science" includes the work of Mann et al., then analysis of MBH98 Figure 7 , which was actually the culmination of MBH98, is part of the "self-correcting" process. For all the sniping against blogs, we’ve seen a nice use of blogs over the past few days in exposing MBH98 Figure 7.
Chefen put the issue on the table, pointing out that the partial correlation coefficients simply didn’t tie together. I brought this to the attention of readers here. Jean S was able to decode Mann-speak and derive a graph that matched Mann’s (which I’ve now also been able to replicate.) Our replicating the Mann figure doesn’t mean that Mann was "right" and Chefen was "wrong" to point out the discrepancy. The difference identified by Chefen pointed to something potentially unstable in the results. Mann said that his results were "robust" – one of his favorite words" to different choices of window length (he used a 200-year window in the illustration), specifically mentioning that the conclusions were robust to a 100-year window. So Jean S ran the results for a 100-year window. I’ve replicated these results. Jean S’s script is here; mine is here.
It is inconceivable to me that any person could describe what you are about to see as "robust". For example, were a Nature referee presented with the 100 year graphs and asked to endorse the claim of "robustness", I do not believe that the claim would be accepted. But decide for yourselves.
Here’s how Mann described the construction of Figure 7:
We estimate the response of the climate to the three forcings based on an evolving multivariate regression method (Fig. 7). This time-dependent correlation approach generalizes on previous studies of (fixed) correlations between long-term Northern Hemisphere temperature records and possible forcing agents lLean et al 1995; Crowley and Kim, 1996]. Normalized regression (that is, correlation) coefficients r are simultaneously estimated between each of the three forcing series and the NH series from 1610 to 1995 in a 200-year moving window. The first calculated value centred at 1710 is based on data from 1610 to 1809, and the last value, centred at 1895, is based on data from 1796 to 1995″¢’¬?that is, the most recent 200 years. A window width of 200 yr was chosen to ensure that any given window contains enough samples to provide good signal-to-noise ratios in correlation estimates. Nonetheless, all of the important conclusions drawn below are robust to choosing other reasonable (for example, 100-year) window widths.
First, here is Jean S’s replication of MBH98 Figure 7.

Figure 1 : Jean S: solid – emulation; dash-dot lines from MBH98. Blue: CO2, green: solar, red: volcanic. There is no moving averages (smoothing) used here. Jean S: "Those are simply partial correlation coefficients in moving windows plotted such that the year corresponds to center of the window." SM – I think that Jean S and I are using "partial correlation coefficient" in different ways. Since our replication graphs are the same, underneath the algebra and terminology, we’re doing the same thing. I’ve haven’t tried to reconcile the terminology yet.
Now here is my version of the same thing expressed a little differently. Here I’ve shown in black – MBH98; blue – the regression coefficients from normalized multiple regression – Jean S’s partial coefficients; red – "partial correlation coefficients" a la Chefen. Like Jean S, I’ve obviously replicated the archived reconstruction. An interesting point here – I’ve simply used CO2 values without logging. I think that the CO2 curve is so smooth that logging must not make any difference. The blue version overprints the black version – so if you can’t tell the difference, it’s because the replication is exact.
 200-year window
200-year window
Figure 2. SM Emulation. Black – MBH98; blue – emulation using regression coefficients from normalized multiple regression – renormalized in each window; red – partial correlation coefficients.
100 Year Window
Remember Mann’s claim quoted above: "all of the important conclusions drawn below are robust to choosing other reasonable (for example, 100-year) window widths." Let’s look at the results using a 100-year window. First here is Jean S’s version/

Figure 3. Jean S – 100 year window, as Figure 1 above.
Now here is my version, arriving at virtually identical results as Jean S, again expressed a little differently.
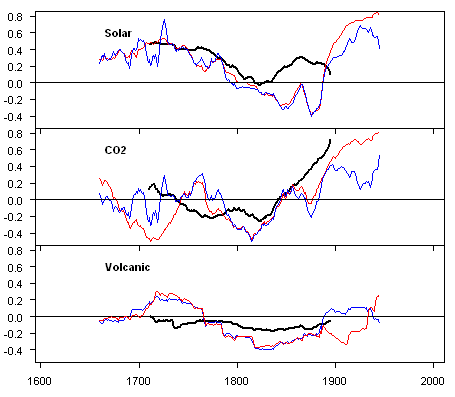
Black- MBH98 archived; red – partial correlation coefficients; blue- OLS regression coefficients from regression of scaled series. 100 -year window for latter two.
I hardly need editorialize about some of the key points. Observe that the solar coefficient for some reason goes to negative relationships in the 19th century and then increases dramatically in the 20th century with values exceeding that of the CO2 coefficient. Now let’s see the "conclusions" which are supposedly "robust" to the use of 100 year windows.
The first conclusion is the significance of the correlation coefficients. As an editorial aside, didn’t Mann tell us that calculating correlation coefficients would be a "silly and incorrect thing" to do. And didn’t Wahl and Ammann agree with that? Oh well. Mann:
We test the significance of the correlation coefficients (r) relative to a null hypothesis of random correlation arising from natural climate variability, taking into account the reduced degrees of freedom in the correlations owing to substantial trends and low frequency variability in the NH series. The reduced degrees of freedom are modelled in terms of first-order markovian “Åred noise’ correlation structure of the data series, described by the lag-one autocorrelation coefficient r during a 200-year window…For (positive) correlations with both CO2 and solar irradiance, the confidence levels are both approximately 0.24 (90%), 0.31 (95%), 0.41 (99%), while for the “Åwhiter’, relatively trendless, DVI index, the confidence levels for (negative) correlations are somewhat lower (-0.16, -0.20, -0.27 respectively). A one-sided significance test is used in each case because the physical nature of the forcing dictates a unique expected sign to the correlations (positive for CO2 and solar irradiance variations, negative for the DVI fluctuations).
The 200-year window has kept the solar coefficient in the positive range, while the 100-year window has the solar coefficient going from positive to negative. The volcanic coefficient is negative in the 200-year window, but its sign changes in the 100-year window. In fact, the sign of even the CO2 coefficient changes in both windows. I haven’t checked the correlation coefficients for significance yet. But my intuition is that the negative correlation coefficient for solar in the 19th century will prove "significant", which makes you wonder how realistic Mann’s significance testing us. Anyway on to the next conclusion:
The correlation statistics indicate highly significant detection of solar irradiance forcing in the NH series during the “ÅMaunder Minimum’ of solar activity from the mid-seventeenth to early eighteenth century which corresponds to an especially cold period. In turn, the steady increase in solar irradiance from the early nineteenth century through to the mid-twentieth century coincides with the general warming over the period, showing peak correlation during the mid-nineteenth century. The regression against solar irradiance indicates a sensitivity to changes in the “Åsolar constant’ of ,0.1 KW-1m-2, which is consistent with recent model based studies [42].
If you go back and look at the 200-year window, you see the rationalization for the bolded remark. There is a sort of local maximum to the solar regression coefficient in the mid-19th century. Now look at the 100-year window. The situation is exactly the opposite. You reach a maximum negative regression coefficient in the 19th century. What a crock. Going on:
Greenhouse forcing, on the other hand, shows no sign of significance until a large positive correlation sharply emerges as the moving window slides into the twentieth century. The partial correlation with CO2 indeed dominates over that of solar irradiance for the most recent 200-year interval, as increases in temperature and CO2 simultaneously accelerate through to the end of 1995, while solar irradiance levels off after the mid-twentieth century.
Using the 100-year window supposedly "robust", again, this is simply not true. You see increases in the regression coefficients of both solar and CO2 in the 20th century, with solar values actually out-stripping CO2 values. In these calculations, Mann has, by the way "grafted" the 1980-1995 instrumental record onto the proxy record up to 1980 and used the grafted values in calculation of the coefficients. Again, the reported conclusion is simply not true for the 100-year window. Next:
Explosive volcanism exhibits the expected marginally significant negative correlation with temperature during much of 1610–1995 period, most pronounced in the 200-year window centred near 1830 which includes the most explosive volcanic events.
Once again, going to a 100-year window, the conclusions don’t hold up. You get positive "correlations" at the beginning of the graph and again in the early 20th century. From this "analysis", Mann then concludes:
It is reasonable to infer that greenhouse-gas forcing is now the dominant external forcing of the climate system.
This is the analysis. I kid you not. Let’s suppose that a 3rd year student handed in this analysis – what grade would it get just as statistics? You probably wouldn’t fail a phys ed student in a state university who was taking a required statistics course, especially if he played on the basketball team. How about a Ph. D. student at an Ivy League university?
The other remarkable thing about this analysis is that this is so easy to do. In this case, Mann archived the data. Anyone – including me – could have done this analysis at any point in the past 6 years. It could have been done by our phys ed student mentioned above. One presumes that no one ever has or else the topic would have emerged before now. So score one for the blogs.