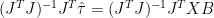De’ath et al (Science 2009) here SI received a considerable amount of press at the start of 2009. De’ath et al reported that the there was an “unprecedented” decline in Great Barrier Reef coral calcification:
The data suggest that such a severe and sudden decline in calcification is unprecedented in at least the past 400 years
A climate scientist not involved in the study said that the findings were “pretty scary”. And so on. An occasional Australian reader brought the data set to my attention the other day. There are some interesting aspects to the data set (a collated version of which I’ve placed online in tab-separated csv form here. Original data is online at ncdc/paleo.
[Update; see also https://climateaudit.org/2009/06/12/a-small-victory-for-the-r-philosophy/%5D
Here is an excerpt from De’ath Figure 2 showing the “scary” decline in calcification that the scientists have alerted the public to, of which they observed:
since 1990 [calcification] has declined from 1.76 to 1.51 g cm−2 year−1, an overall decline of 14.2% (SE = 2.3%). The rate of this decline has increased from 0.3% per year in 1990 to 1.5% per year in 2005.

Figure 1. Smoothed calcification for the 20th century,

Figure 2. Smoothed calcification 1572-2005.
I thought that it was a little surprising to see the presentation of trends calculated over such short periods, a practice much criticized in the blogosphere, but I guess that the PRL (Peer Reviewed Literature) – or, at any rate, Science – takes these concerns less seriously. The heavy smoothing is also troubling – Matt Briggs won’t be very happy.
To see the impact of unsmoothed data, I did a simple plot of the average calcification by year over the data set. I understand that the coral data spans a considerable length and that various sorts of adjustments might be justified, but it’s never a bad idea to plot an average. Here are two plots, showing a simple average, first from 1572-2005 and then in the 20th century. Based only on the first plot, one could not say that even the 2004-2005 results were “unprecedented in at least 400 years” – values in 1852 were lower. So I can confirm that the values before adjustment are unprecedented since at least 1852.
Visually, this graph looks to me like calcification has been increasing over time, with a downspike in 2004-5, but, as my critics like to observe, I am not a “climate scientist” and therefore presumably unqualified to see the downward trend that was reported by the Wizards of Oz.

Figure 3. Average Calcification by Year.
Here’s a similar plot for the 20th century also showing the count of sites – which has declined sharply in the past 15 years with only one site contributing nearly all the 2005 values. Curiously, there is a very high correlation (0.48) between calcification and the number of measurements available in a year. The unsmoothed data gives a very different impression that the Science cartoons. Unsmoothed, years up to 2003 were not particularly low; it’s only two years – 2004 and 2005 – that have anomalously low values. But it seems a little premature to conclude that this is a “wide-scale” trend as opposed to a downspike -which occur on other occasions in the record.

Figure 4. Average Calcification by Year, 1900-2005. Also showing the number of sites (2 in 2005).
Now there may well be sensible adjustments to the average. The cores don’t come from the same site and the average latitude may vary. The average age of a core varies by year. These are the sorts of problem that dendros deal – an analogy that the authors don’t mention.
The authors do not actually show averages but “partial effects” plots obtained from the lmer program in the R package lme4. As it happens, I’ve used this very package to make tree ring chronologies – I think that I’ve illustrated this in some older posts. So I think that it’s fair to say that there probably aren’t a whole lot of readers who are better placed than I am to try to figure out how their adjustments are done. But as so often in climate science articles, the methodological descriptions don’t permit replication. I’ve spent some time on this and don’t understand how they constructed their model and, if I can’t, I can’t imagine that many readers will be able to. For example, given the many forms of structuring a linear mixed effects model, in my opinion, the following statement is only slightly more informative than saying that they used “statistics”:
The dependencies of calcification, extension, and density of annual growth bands on year (the year the band was laid down), location (the relative distance of the reef across the shelf and along the GBR), and SST were assessed with linear mixed-effects models (16) [supporting online material (SOM)].
Nor does a statement like the following give usable information on how they actually did the calculation:
Fixed effects were represented as smooth splines, with the degree of smoothness being determined by cross-validation (17 – Wahba, 1983).
If the Supplementary Information laid things out, but it doesn;t. lmer has a huge number of options; without a script, one is just guessing. I can’t imagine that there will be many readers of this article that are both interested in the subject matter and as familiar with the tools as I am. I couldn’t figure out how their model was specified from their material and don’t have enough present interest in the topic to try to reverse engineer it.
In any event, regardless of their claim to have “cross-validated” the smoothing, it sure looks to me like a couple of low closing values have been leveraged into a downward trend, when they might simply be a downspike (or even due to limited sampling.) I haven’t vetted the calculation of trend standard errors, but they look to me like OLS trends without being adjusted for autocorrelation (but that’s just a guess). The leverage of a couple of closing values on the illustrated trend is reminiscent of the Emanuel’s bin-and-pin method (which he recanted), in that there seems to be an undue amount of influence on a couple of closing values.
The existence of a positive correlation between calcification and SST resulted in some intriguing contortions. The authors note that “Calcification increases linearly with increasing large-scale SST”, but nonetheless interpret the present results as evidence that “the recent increase in heat stress episode is likely to have contributed to declining coral calcification in the period 1990-2005”. Go figure.
The data seems rather thin as a basis for concluding “unprecedentedness” and surely it would be prudent for worried Australians to take few more coral samples.
Interestingly, we’ve previously encountered coral data from the Great Barrier Reef, as it was one of the proxies in MBH98, where it was held to be “teleconnected” to weather phenomena throughout the world and used as a predictor of NH temperature. You don’t believe me – look at the SI here.
For some reason, the authors have failed to address the important issue of teleconnections between their coral calcification data and NH climate. In particular, using the technical language preferred by the Community, the inverse of the 2004-2005 coral calcification spike is “remarkably similar” to the 2004-2005 spike in Emanual’s Atlantic hurricane PDI. We’ve had difficulty locating proxies for Atlantic hurricane activity and it looks like we may finally have found one. I recommend to the authors that they forthwith join forces with Mann and Rutherford for the purposes of carrying out a RegEM calculation combining Atlantic hurricanes and Great Barrier Reef coral calcification, as it is likely that this will obtain a skilful reconstruction of Atlantic hurricane PDI. (In order to encourage the authors in this long overdue study, I will waive any obligation on their part to acknowledge that they got the idea from Climate Audit.)
UPDATE June 4: As an exercise, I’ve done some mixed effects models of this data using lmer. CA readers, you can do what peer reviewers at leading science tabloids don’t – you can actually do some lmer runs on the data (I don’t for a minute believe that any Science reviewers bothered.) Here are 6 lines of code that load the data, do a lmer run on a model with two fixed effects: age and latitude and extracts a random effect for the year.
library(lme4)
Data=read.csv(“http://data.climateaudit.org/data/coral/GBR.csv”,sep=”\t”,header=TRUE); dim(Data)
Data=Data[Data$year<2006,] #removes a singleton
Data$yearf=factor(Data$year)
(fm1< -lmer(calcification~ lat+ exp(-age)+(1|yearf) ,data=Data))
chron1= ts(ranef(fm1)$yearf,start=min(Data$year) )
ts.plot(chron1)
I’ve done some experiments and show the effect of the above calculation, as well as the effect of not having an aging factor. In effect, this model “adjusts” for varying contributions from latitude and ages. This is not the same model as used by De’ath et al – I don’t know what their model is, but this is a fairly plausible model and one that I’d consider before feeling obliged to use De’ath-type splines.

Figure 3. Random Effects Model for GBR Calcification.
As one reader observed, there is a very limited population of reefs that have values after 1991 and before 1800. In fact, there are only two such reefs: ABR and MYR. To try to preserve a bit of homogeneity in the data set, I did the same procedures using the restricted data set from only these two sites. This yielded the following random effects chronology, plotted here with counts, showing how limited the data is before 1800 and in 2005. Interestingly, this one looks like a classic Mann hockey stick up to 1980, followed by a sharp decline. Maybe they teleconnect with Graybill strip-bark bristlecones, rather than Atlantic hurricanes.



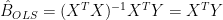

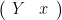
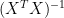 , only the first k eigenvectors are used in the inversion.
, only the first k eigenvectors are used in the inversion. 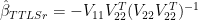

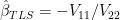
 . This is not a magic matrix, but merely one of many possible multivariate methods. To my knowledge, there are no commandments mandating the use of this matrix.
. This is not a magic matrix, but merely one of many possible multivariate methods. To my knowledge, there are no commandments mandating the use of this matrix. .
. are the reconstructed PCs (using regpar=r). In this context, they correspond to the reconstructed X-matrix in the usual X-Y matrices. In the following lines, I’ll denote here
are the reconstructed PCs (using regpar=r). In this context, they correspond to the reconstructed X-matrix in the usual X-Y matrices. In the following lines, I’ll denote here  .
.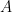 ) can be expressed in usual SVD nomenclature, taking care to observe that this SVD decomposition is distinct from the one just done on the augmented matrix, as follows:
) can be expressed in usual SVD nomenclature, taking care to observe that this SVD decomposition is distinct from the one just done on the augmented matrix, as follows:
 in this context is the AVHRR eigenvector (and is a different eigenvector matrix than the augmented matrix used in the calibration). Steig (as in MBH) obtains the reconstructed matrix of Antarctic gridcells
in this context is the AVHRR eigenvector (and is a different eigenvector matrix than the augmented matrix used in the calibration). Steig (as in MBH) obtains the reconstructed matrix of Antarctic gridcells  by using the reconstructed PCs
by using the reconstructed PCs 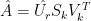
 and
and 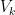 are restricted to k=3 columns.
are restricted to k=3 columns. is an average of the gridcells (equal area here by construction), which can be expressed as a right multiplication of the matrix
is an average of the gridcells (equal area here by construction), which can be expressed as a right multiplication of the matrix 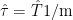
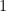 here denotes a vector of 1’s of length m=5509 gridcells. Collecting the terms used to derive
here denotes a vector of 1’s of length m=5509 gridcells. Collecting the terms used to derive 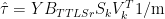
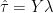
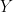 is the matrix of station data,
is the matrix of station data, 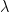 is a vector of length q representing weights for each of the stations denoted in the above equation:
is a vector of length q representing weights for each of the stations denoted in the above equation:


 – see script below for definition). By expanding
– see script below for definition). By expanding  is simply a linear weighting of the individual station trends multiplied by the vector of weights
is simply a linear weighting of the individual station trends multiplied by the vector of weights