Today, I’m going to discuss a couple of points arising out of Fleitmann et al 2007, a discussion of speleothems in western Asia. Most notably, I’m going to discuss a “statistical” calculation made in this article, where the authors relied on a “visual” interpretation of noisy time series, which readily permit an alternative interpretation. (The reference to Fleitmann et al 2007 arises out of prior discussion of speleothem dO18 series; the comment today is not a direct response to that discussion, it’s a standalone comment prompted by my reading of the article.)
The abstract to Fleitmann et al says (the bolding of the statistical term anti-correlation is mine):
For the late Holocene there is an anti-correlation between ISM precipitation in Oman and inter-monsoon (spring/autumn) precipitation on Socotra, revealing a possible long-term change in the duration of the summer monsoon season since at least 4.5 ka BP. Together with the progressive shortening of the ISM season, gradual southward retreat of the mean summer ITCZ and weakening of the ISM, the total amount of precipitation decreased in those areas located at the northern fringe of the Indian and Asian monsoon domains, but increased in areas closer to the equator.
One of their conclusions states (my bold):
During the late-Holocene, the observed anti-correlation between monsoon precipitation in Southern Oman and inter-monsoon (spring/autumn) precipitation on Socotra possibly reveals that the mean seasonal cycle of the ISM has also changed in response to insolation forcing.
This anti-correlation is discussed and illustrated in the running text as follows:
In order to better reveal the anti-correlation between precipitation in Southern Oman and Socotra in greater detail, we compared the overlapping d18O profiles of stalagmites Q5 and D1 (Fig. 9). This comparison shows a visible anti-correlation, with higher monsoon precipitation in Southern Oman coinciding with lower intermonsoon (spring/autumn) precipitation on Socotra.
Their Figure 9 is shown below. Observe that the term “strong” is added to anti-correlation in the caption comment: “Note the strong visible anti-correlation between D1 and Q5.”

Elsewhere the authors say of the relationship between Q5 and D1:
“In contrast to the gradual decrease in ISM precipitation recorded in stalagmite Q5 from Southern Oman, the D1 stalagmite d18O record from Socotra shows a long-term increase in inter-monsoon (spring and autumn) precipitation, as indicated by a long-term decrease in d18O since ~4.4 ka BP (Figs. 4 and 7). This anti-phase behavior between Southern Oman and Socotra seems to be apparent not only on millennial but also on multi-decadal timescales.”
They posit the following theoretical explanation for the “strong anti-correlation” between Q1 and D5:
Because the onset and termination of the summer monsoon on Socotra determines the end of the spring and start of the autumn precipitation season respectively (as it is in Eastern Africa; Camberlin and Okoola, 2003), it is conceivable that a gradual shortening in the length of the summer monsoon season resulted in an extension of pre- and post-monsoon rainy season precipitation on Socotra.
and suggest that their results may affect many interpretations:
A later advance and earlier retreat of the ITCZ in spring and autumn, respectively would lead to an on average shorter monsoon season over Southern Oman. If the movement of the ITCZ took place more slowly, a second effect would be a longer spring/autumn rainfall season over the northern Indian Ocean and Socotra, respectively. Provided that our interpretation is correct, our results should have far-reaching consequences for the interpretation of many monsoon proxy records in the ISM and other monsoon domains, as most paleoclimate time series are commonly interpreted to reflect overall monsoon intensity, but not the duration of the monsoon season.
The “Strong Anti-Correlation”
By now, most CA readers have seen a lot of noisy climate time series side by side and learned not to place a whole lot of weight on non-quantitative characterizations of statistical data. And Fleitmann et al provide no quantitative analysis to support their claims of “strong anti-correlation”; the edifice is built on the visual impression of their Figure 9, which, quite frankly, conveys an impression of noise to me, rather than “strong anti-correlation”.
Establishing correlations between two time series with irregularly spaced intervals and with uncertainties in the time calibration of both series is non-trivial. And establishing that an anti-correlation between two such series is “strong” or significant is also not all that easy.
The first step is to collect the data.
The Qunf Q5 data is archived at WDCP here ftp://ftp.ncdc.noaa.gov/pub/data/paleo/speleothem/asia/oman/qunf2007.txt.
The Dimarshim D1 data is not archived at WDCP. In early September, I sent two polite requests for data to Fleitmann coauthor, Stephen Burns, neither of which received a reply. (Burns is in Bradley’s department at U Mass and I guess that responding to such an email would be as bad as saying the name of He Who Must Not Be Named).
But the Dimarshim D1 (as plotted in Fleitmann Figure 7 #13) matches Mann’s Socotra dO18 series, where it has been interpolated to annual data. As a temperature proxy, Mann uses the Socotra dO18 series with positive dO18 up, while Fleitmann 2007, using the series as a monsoon proxy, uses it with negative dO18 up – the same orientation as Dongge, Wanxiang and Heshang as monsoon proxies. (As a note to a CA reader, Fleitmann accordingly does not rationalize the basis for Mann using Socotra/Dimarshim D1 oriented oppositely to Dongge; that issue remains outstanding.)
Between Mann’s version of Dimarshim D1/Socotra dO18 and the WDCP version of Qunf Q5, we have some tools for beginning a more quantitative approach to the evaluating the “strong anti-correlation”. First here is a plot of the two data sets (as I’ve used them), which can be compared to Fleitmann Figure 7 to confirm that we’re talking apples-and-apples.

One obvious impression from this picture is first that the Qunf Q5 speleothem has suffered a substantial hiatus. I plotted up a graph doing age-depth comparisons for the two speleothems, which have quite different patterns. So the comparison between the two speleothems is far from ideal on the above basis and it seems to me that one would like to compare two speleothems with more comparable growth histories before investing too much energy in elaborate conclusions. However, that’s not the main point here.

Second, given that there are uncertainties in the dating of both series, it doesn’t take a lot of imagination to wonder whether the wiggles might match a bit better with dating alternatives within the acknowledged error margins of the dating. In order to test this data, I examined the subset of overlapping data (from about 2700-4700 BP), interpolating the Qunf Q5 data to annual series (as Mann had done with the Dimarshim D1 series) and calculated the correlation between the two series (r= -0.08). This is a pretty rough-and-ready methodology, but I think that it is less bad than a “visual” comparison. The residuals from the linear fit (corresponding to the correlation calculation) were highly autocorrelated.
The average reported error bar for Dimarshim D1 dating in the 2700-4700BP range was 72 years and for Qunf Q5 was 113 years, yielding an error bar for relative dating of 134 years (Pythagorean).
“Visually”, it looked to me like the Qunf Q5 series might fit with the D1 series a bit better if its dates were brought a little closer to the present. So I displaced the Q5 series one year by one year towards the present and for each displacement calculated a correlation, yielding the graphic below (this sort of method is used in dendro dating as a check.) By bringing the Q5 series about 85 years closer to the present, instead of a negative correlation of -.078, we get a positive correlation exceeding 0.2 (probably with improved autocorrelation properties in the residuals though I didn’t check this.) An 85 year displacement is well within the error bounds of the speleo dating method.

As noted above, this analysis has nothing to do with the interpretation of dO18 records as monsoon proxies or as temperature proxies. It is restricted to the issue of whether there is an “observed” anti-correlation between Q5 and D1 dO18 records.
Am I claiming the opposite: that there is a statistically significant positive correlation between D1 and Q5 dO18 records? Nope. I don’t know enough about these records to make such claims and there are some intricate issues in estimating correlations between irregular time series that would need to be canvassed. But, on this data, it’s quite possible that there is no actual anti-correlation and that the “observed” anti-correlation is simply an artifact of relative dating errors.
[Update] Long-Term Trends
Dr Fleitmann points out in a comment below that, regardless of the above possible issue, the long-trends are different between Oman and Socotra, a point illustrated in their Figure 4, excerpted below:

Update – Dec 15
In my calculations, as noted above, because Fleitmann et al failed to archive their Socotra data and because Burns refused to provide the data when requested, I compared the Qunf Q5 data to Socotra as used in Mann et al 2008. However, given that I used Mann data, I obviously should not have assumed that it would correspond to other versions of the data. Below I’ve excerpted Figure 9 of Fleitmann et al (which shows Dimarshim D1) and a replot of the Mann Dimarshim D1 version (identified there as “burns_2003_socotrad18o”). The versions are similar, but there are notable differences that prohibit use of the Mann version for analysis without reconciliation. Note the downspike to nearly -5 in the Fleitmann version (grey series) at about 3570 BP. The corresponding downspike in the Mann version is about 3800 BP, about 230 years earlier. The preceding upsike to about -1.5 occurs just before 3900 BP in Fleitmann and about 4100 BP in Mann. The Fleitmann version ends just before 4500 BP, while the Mann version goes to about 2700 BP. The Mann version seems to be about 200 years earlier than the Fleitmann version.

Fleitmann et al 2007 Figure 9.

Replot of Mann et al 2008 Version of Socotra O18.
Reference:
Fleitmann, Dominik, Stephen J. Burns, Augusto Mangini, Manfred Mudelsee, Jan Kramers, Igor Villa, Ulrich Neff, Abdulkarim A. Al-Subbary, Annett Buettner, Dorothea Hippler, and Albert Mater, 2007. Holocene ITCZ and Indian monsoon dynamics recorded in stalagmites from Oman and Yemen (Socotra). Quaternary Science Reviews Vol. 26, No 1-2, pp. 170-188, January 2007,
online at http://www.manfredmudelsee.com/publ/pdf/Holocene_ITCZ_and_Indian_monsoon_dynamics_recorded_in_stalagmites_from_Oman_and_Yemen_(Socotra).pdf









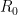 is the Th230/Th232 activity of present-day spring water (1.85 -see page 42), used here as an approximation for ancient spring water, while
is the Th230/Th232 activity of present-day spring water (1.85 -see page 42), used here as an approximation for ancient spring water, while  is the Th230/Th232 activity of detritus estimated at 0.526 (based on a sample from a nearby travertine site (Hass/Lauster).
is the Th230/Th232 activity of detritus estimated at 0.526 (based on a sample from a nearby travertine site (Hass/Lauster).

![\delta^{234}U[0]](https://s0.wp.com/latex.php?latex=%5Cdelta%5E%7B234%7DU%5B0%5D+&bg=ffffff&fg=000&s=0&c=20201002) by comparing the ratio of observed U234/U238 to the “equilibrium” ratio, subtracting 1 and multiplying by 1000:
by comparing the ratio of observed U234/U238 to the “equilibrium” ratio, subtracting 1 and multiplying by 1000:











