Reader Tom P observed:
If Steve really wants to invalidate the Yamal chronology, he would have to find another set of cores that also gave good correlation with the instrument record, but indicated a previous climate comparable or warmer than that seen today.
As bender observed, Tom P’s question here is a bit of a slow pitch, since the Polar Urals (the unreported but well-known update) is precisely such a series and since the “Yamal Substitution” (where Briffa 2000 quietly replaced the Polar Urals site with its very pronounced MWP with the HS-shaped Yamal) has been a longstanding concern and issue at Climate Audit.
Yamal and Polar Urals are both nearby treeline sites in northwest Siberia (Yamal 67 30N; 70 30E; Polar Urals 66N 65E). Both have cores crossdated for at least the past millennium. RCS chronologies have been calculated for both sites by Team authors. One chronology (Yamal) is the belle of the ball. Its dancecard is completely full: Briffa 2000; Mann and Jones 2003 (the source for the former UNEP graph); Moberg et al 2005; D’Arrigo et al 2006; Osborn and Briffa 2006; Hegerl et al 2007; Briffa et al 2008; Kaufman et al 2009 and appears in the IPCC AR4 proxy spaghetti graph.
The other chronology (Polar Urals as updated) is a wallflower. It had one dance all evening (Esper et al 2002), but Esper also boogied with not just one, but two strip bark foxtails from California. Polar Urals was not illustrated in the IPCC AR4 proxy spaghetti graph; indeed, it has never been displayed in any article in the PeerReviewedLitchurchur. The only place that this chronology has ever been placed on display is here at Climate Audit.
The question today is – why is Yamal the belle of the ball and Polar Urals a wallflower? Is it because of Yamal’s “inner beauty” (temperature correlation, replication, rolling variance, that sort of thing) or because of its more obvious physical attributes exemplified in the diagram below? Today, we’ll compare the “inner beauty” of both debutantes, starting first with the graphic below, showing their “superficial” attributes.

Figure 1. RCS chronologies (minus 1) for Yamal (Briffa) and Polar Urals (Esper). Note the graph in Rob Wilson’s recent comment compares the RCS chronology for Yamal with the STD chronology for Polar Urals – and does not directly compare the two data sets using a consistent standardization methodology.
The two series are highly correlated (r=0.53) and have the same sort of appearance up to a sort of “dilation” in the modern portion of the Yamal series, which seems highly dilated relative to the Polar Urals series. (This dilation is not unlike the Graybill bristlecone chronologies relative to the Ababneh chronologies, where there was also high correlation combined with modern dilation.) Obviously, Yamal has a huge hockey stick (the largest stick in the IPCC AR4 Box 6.4 diagram), while the Polar Urals MWP exceeds modern values.
I’ve observed on a number of occasions that the difference between Polar Urals and Yamal is, by itself, material to most of the non-bristlecone reconstructions that supposedly “support” the Hockey Stick. For example, in June 2006, I showed the direct impact of a simple sensitivity study using Polar Urals versus Yamal – an issue also recently discussed here.
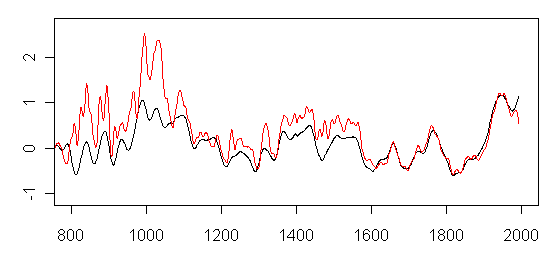
Figure 2. Impact on Briffa 2000 Reconstruction of using Polar Urals (red) rather than Yamal (black).
The disproportionate impact of Polar Urals versus Yamal motivated many of my Review Comments on AR4 (as reviewed in a recent post here), but these Review Comments were all shunted aside by Briffa, who was acting as IPCC section author.
In February 2006, there were a series of posts at CA comparing the two series, which I broke off to prepare for the NAS presentations in March 2006. At the time, both Osborn and Briffa 2006 and D’Arrigo et al 2006 had been recently published and the Yamal Substitution was very much on my mind. As we’ve recently learned from the Phil Trans B archive in Sept 2009, the CRU data set had abysmally low replication in 1990 for RCS standardization, a point previously unknown to both myself and to other specialists (e.g. the authors of D’Arrigo et al 2006.)
Today’s analysis of the Yamal Substituion more or less picks up from where we left off in Feb 2006. While there is no formal discussion of the Yamal Substitution in the peerreviewedliterature, I can think of three potential arguments that might have been adduced to purport to justify the Yamal Substitution in terms of “inner beauty”: temperature correlation, replication and rolling variance (the latter, an argument invoked by Rob Wilson in discussion here.)
Relationship to Local Temperature
Both Jeff Id and I (and others) have discussed on many occasions that there is a notable bias in selecting proxies from a similarly constructed population (e.g. larch chronologies) ex post. However, for present purposes, even if this point is set aside for now and we temporarily stipulate the validity of such a procedure, the temperature relationships do not permit a preferential selection of Yamal over Polar Urals.
The Polar Urals chronology has a statistically significant relationship to annual temperature of the corresponding HadCRU/CRUTEM gridcell, while Yamal does not (Polar Urals t-statistic – 3.37; Yamal 0.92). For reference the correlation of the Polar Urals chronology to annual temperature is 0.31 (Yamal: 0.14). Both chronologies have statistically significant relationships to June-July temperature, but the t-statistic for Polar Urals is a bit higher (Polar Urals t-statistic – 5.90; Yamal 4.29; correlations are Polar Urals 0.50; Yamal 0.55). Any practising statistician would take the position that the t-statistic, which takes into consideration the number of measurements, is the relevant measure of statistical significance, a point known since the early 20th century.
Thus, both chronologies have a “statistically significant” correlation to summer temperature while being inconsistent in their medieval-modern relationship. This is a point that we’ve discussed from time to time – mainly to illustrate the difficulty of establishing confidence intervals when confronted with such a problem. I made a similar point in my online review of Juckes et al, contesting their interpretation of “99.9% significant”. In my AR4 Review Comments, I pointed out this ambiguity specifically in the context of these two series as follows:
There is an updated version of the Polar Urals series, used in Esper et al 2002, which has elevated MWP values and which has better correlations to gridcell temperature than the Yamal series. since very different results are obtained from the Yamal and Polar Urals Updated, again the relationship of the Yamal series to local temperature is “ambiguous” [ a term used in the caption to the figure being commented on]
In his capacity of IPCC section author, Briffa simply brushed aside this and related comments without providing any sort of plausible answer as discussed in a prior thread on Yamal in IPCC AR4, while conceding that both “the Polar Urals and Yamal series do exhibit a significant relationship with local summer temperature.”
In any event, the relationships of the chronologies to gridcell temperature do not provide any statistical or scientific basis for preferentially selecting the Yamal chronology over the Polar URals chronology into a multiproxy reconstruction.
Replication
The D’Arrigo et al authors believed that Briffa’s Yamal chronology was more “highly replicated” than the Polar Urals chronology, a belief that they held even though they did not actually obtain the Yamal data set from Briffa. CA reader Willis Eschenbach at the time asked the obvious question how they knew that this was the “optimal data-set” if they didn’t have the data.
First, if you couldn’t get the raw data … couldn’t that be construed as a clue as to whether you should include the processed results of that mystery data in a scientific paper? It makes the study unreplicable … Second, why was the Yamal data-set “optimal”? You mention it is for “clear statistical reasons” … but since as you say, you could not get the raw data, how on earth did you obtain the clear statistics?
Pretty reasonable questions. The Phil Trans B archive thoroughly refuted the belief that the Yamal data set was more highly replicated than the Polar Urals data set. The graphic below shows the core counts since 800 for the three Briffa et al 2008 data sets (Tornetrask-Finland; Avam-Taimyr and Yamal) plus Polar Urals. Obviously, the replication of the Yamal data set (10 cores in 1990) is far less than the replication of the other two Briffa et al 2008 data sets (both well over 100 in 1990) and also less than Polar Urals since approximately AD1200 and far below Polar Urals in the modern period (an abysmally low 10 cores in 1990 versus 57 cores for Polar Urals. The modern Yamal replication is far below Briffa’s own stated protocols for RCS chronologies (see here for example.) This low replication was unknown even to specialists until a couple of weeks ago.

Figure 2. Core Counts for the three Briffa et al 2008 data sets plus Polar Urals
Obviously, contrary to previous beliefs of the D’Arrigo et al authors, Briffa’s Yamal data set is not more highly replicated than Polar Urals. Had the D’Arrigo authors obtained the Yamal measurement data during the preparation of their article, there is no doubt in my mind that the D’Arrigo authors would have discovered the low Yamal replication in 2005, prior to publication of D’Arrigo et al 2006. However, they didn’t and the low replication remained unknown until Sept 2009.
Running Variance
Rob Wilson defended the Yamal Substitution at CA in Feb 2006 on the grounds that the variance of the Polar Urals RCS chronology was “not stable through time” and that use of this version would therefore be “wrong”, whereas Yamal “at least had a roughly stable variance through time”.
Rob assessed the supposed variance instability using a 101-year windowed variance – a screening method likewise not mentioned in D’Arrigo et al 2006 nor, to my knowledge, elsewhere in the peerreviewedliterature. An obvious question is: how does the stability of the Polar Urals windowed variance compare to windowed variance on other RCS series that are in use? And does Yamal’s windowed variance show an “inner beauty” that is lacking in Polar Urals? The graphic below calculates windowed 101-year standard deviations for 13 Esper RCS chronologies (including Polar Urals) plus Briffa’s Yamal.

Figure . Running windowed-101 year standard deviation 850-1946 for 13 Esper RCS chronologies. Polar Urals in red; Briffa Yamal in black.
From 1100AD on, the Polar Urals chronology doesn’t seem particularly objectionable relative to the other Esper RCS chronologies. Its variance is elevated in the 15th century, but another Esper chronology has similar variance in the 12th century. Its variance is definitely elevated relative to other chronologies in the 11th century, a period in which there are only a few comparanda, most of which are in less severe conditions: the two strip bark foxtails and Tornetrask (Taimyr is presumably equally severe.)
Also shown in the above graphic is the corresponding graphic for Briffa’s Yamal series. Whatever points of reservation that Wilson may have regarding the Polar Urals RCS chronology would seem to apply even more with the Yamal chronology. Using Wilson’s rolling variance test, the variance of the Yamal chronology has been as high or higher than Polar Urals since AD1100 and has increased sharply in the 20th century when other chronologies have had stable variances. I am totally unable to discern any visual metric by which one could conclude that Yamal had a “roughly stable” variance in any sense that Polar Urals did not have as well. (Rob Wilson’s own comparison (see here used a different (his own) version of Urals RCS, where the rolling variance of the MWP is more elevated than in the version shown here using Esper’s RCS. However, Rob has also recently observed that he will rely on third party RCS chronologies and, in this case, Esper’s Polar Urals RCS would obviously qualify under that count.)
In respect to “rolling variance”, if anything, Yamal seems to have less “inner beauty” than Polar Urals.
Update: Kenneth Frisch in #207 below observes (see his code):
The results of these calculations indicate that the magnitude of the sd follows that of the mean and not that of the tree ring counts. Based on that explanatory evidence, I do not see where Rob Wilson’s sd windows would account for much inner beauty for the Yamal series or, likely, for any other RCS series (Polar Urals).
Yamal Already a “Standard”?
Another possible argument was raised by Ben Hale, supposedly drawing on realclimate: that Yamal was already “standard” prior to Briffa. This is totally untrue – Polar Urals was the type site for this region prior to Briffa 2000.
Briffa et al (Nature 1995), a paper discussed on many occasions here, used the Polar Urals site (Schweingruber dataset russ021) to argue that the 11th century was cold and, in particular, 1032 was the coldest year of the millennium. A few years later, more material from Polar Urals was crossdated (Schweingruber dataset russ176) and, when this crossdated material is combined with the previous material, a combined RCS ring width chronology yields an entirely different picture – a warm MWP. Such calculations were done both by Esper (in connection with Esper et al 2002) and for D’Arrigo et al 2006, but the resulting RCS reconstruction was never published nor, as noted previously, has the resulting RCS reconstruction ever appeared in print nor were the resulting RCS reconstructions placed in a digital archive in connection with either publication.
Instead of using and publishing the updated information from Polar Urals, the Yamal chronology was introduced in Briffa 2000 url, a survey article on worldwide dendro activities, in whichBriffa’s RCS Yamal chronology replaced the Polar Urals in his Figure 1. Rudimentary information like core counts was not provided. Briffa placed digital versions of these chronologies, including Yamal, online at his own website (not ITRDB). A composite of three Briffa chronologies (Yamal, Taimyr and Tornetrask) had been introduced in Osborn and Briffa (Science 1999), a less than one page letter. Despite the lack of any technical presentation and lack of any information on core counts, as noted elsewhere, this chronology was used in multiproxy study after another and was even separately illustrated in the IPCC AR4 Box 6.4 spaghetti graph.
Authors frequently purport to excuse the re-use of stereotyped proxies on the grounds that there are few millennium-length chronologies, a point made on occasion by Briffa himself. Thus, an updated millennium-length Polar Urals chronology should have been a welcome addition to the literature. But it never happened. Briffa’s failure to publish the updated Polar Urals RCS reconstruction has itself added to the bias within the archived information. Subsequent multiproxy collectors could claim that they had examined the “available” data and used what was “available”. And because Briffa never published the updated Polar Urals series, it was never “available”.
The Original Question
At this point, in the absence of any other explanation holding up, perhaps even critics can look squarely at the possibility that Yamal was preferred over Polar Urals because of its obvious exterior attributes. After all, Rosanne D’Arrigo told an astonished NAS panel: “you need to pick cherries if you want to make cherry pie”. Is that what happened here?
I looked at all possible origins of “inner beauty” that might justify why Yamal’s dance card is so full. None hold up. Polar Urals’ temperature correlations are as good or better than Yamal’s; Polar Urals is more “highly replicated” than Yamal since AD1100 with massively better replication in the 19th and 20th centuries; throughout most of the millennium (since approximately AD1100), Yamal’s windowed variance is as high or higher as Polar Urals and massively higher in the 20th century.
In summary, there is no compelling “inner beauty” that would require or even entitle an analyst to select Yamal over Polar Urals. Further, given the known sensitivity of important reconstructions to this decision, the choice should have been clearly articulated for third parties so that they could judge for themselves. Had this been done, IPCC reviewers would have been able to point to these caveats in their Review Comments; because it wasn’t done, IPCC Authors rejected valid Review Comments because, in effect, the IPCC Authors themselves had failed to disclose relevant information in their publications.
Proxy Inconsistency
Over and above the cherrypicking issue is the overriding issue of proxy inconsistency – a point made in our PNAS 2009 comment and again recently at Andy Revkin’s blog recently:
There are fundamental inconsistencies at the regional level as well, including key locations of California (bristlecones) and Siberia (Yamal), where other evidence is contradictory to Mann-Briffa approachs (e.g. Millar et al 2006 re California; Naurzbaev et al 2004 and Polar Urals re Siberia,) These were noted up in the N.A.S. panel report, but Briffa refused to include the references in I.P.C.C. AR4. Without such detailed regional reconciliations, it cannot be concluded that inconsistency is evidence of “regional” climate as opposed to inherent defects in the “proxies” themselves.
I repeat this point because without a reconciliation of such inconsistencies, without an ability to reconcile all the loose ends in regional climate, how can anyone in the field expect to carry out multiproxy studies.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}