Mann et al 2007 is a new RegEM version, replacing the RegEM calculations of Rutherford et al 2005. The logic is not entirely self-contained and so I re-visited some of our previous comments on Rutherford et al here here here here . I’m going to reprise two issues today: Collation Errors, a small but amusing defect; and Calibration-Period Standardization, a more serious problem, raised last year by Jean S in this post – an issue evocative of the calibration period standardization error in MBH98. This latter problem has now been acknowledged; Mann and Rutherford have now deleted all source code pertaining to Rutherford et al 2005 in June 2007, nearly a year later. The error is mentioned in Mann et al 2007 – needless to say without mentioning climateaudit.
Collation Errors
First, the smaller point, collation errors. I observed an amusing collation error in Rutherford et al 2005, in which they had inadvertently spliced their instrumental data to the wrong calendar year. On an earlier occasion, we had reported collation errors in the first MBH98 data set to which we had been directed at Mann’s FTP site, which we reported in MBH98. After MM03, the “wrong version” was deleted from Mann’s ftp site and a new MBH98 directory appeared (which has in its turn dematerialized to be replaced by yet another version.) The collation errors observed in the first version did not occur in the later versions and some time ago, I arrived at the conclusion that the PCproxy version that Rutherford had directed us to was a version that he’d developed for his studies (perhaps Rutherford et al 2005) and that it probably hadn’t been a factor in the original MBH. Anyway, Rutherford et al 2005 contained a snark about this topic as follows:
some reported putative “errors” in the Mann et al. (1998) proxy data claimed by McIntyre and McKitrick (2003) are an artifact of (a) the use by these latter authors of an incorrect version of the Mann et al. (1998) proxy indicator dataset
.
Of course why did we use an “incorrect version”? Because they said to use it. I raised the splicing issue with Rutherford and he said that it was before his time. I asked Mann about it and he said that he was too busy to respond, but that Eduardo Zorita hadn’t had any problems replicating his results. 🙂 Anyway, when I went to re-check the code containing the collation error, it’s now been hoovered as well. If you go to the Rutherford et al 2005 SI and follow the link for MultiproxyPC Matlab Code, you go here , where a message states:
UPDATE (June 20, 2007):
Since the original publication of this work, we have revised the method upon discovering a sensitivity to the calibration period.
When, as in most studies, data are standardized over the calibration period, however, the fidelity of the reconstructions is diminished when employing ridge regression in the RegEM procedure as in M05 (in particular, amplitudes are potentially underestimated; see Auxiliary Material, section 2).
[Note: a re-visit on Feb 12, 2009 showed that the above link had been modified some time previously to say only:
UPDATE (June 20, 2007): Since the original publication of this work, we have revised the method upon discovering a sensitivity to the calibration period.
]
Interested parties can obtain the hoovered material here , originally saved by John A for me since I had been blocked from the Rutherford site.
3) Unreported “standardization”
The issue of sensitivity to the calibration period was noted on July 10, 2006, here when Jean S posted the following note, in which he noticed the then unreported short-segment standardization (a huge issue in MM2005) and thought that it was a potential problem (although he merely noted the issue without fully diagnosing it). (UC had noticed another interesting problem):
There is a “standardization” step in Rutherford’s code, which seems to be (to my knowledge) unreported. Here’s a segment of the code (taken from “mbhstepwiselowrecon.m”, but the same is present in all reconstruction codes):
[nrows,ncols]=size(composite);
if i==1% first step standardize everything
means=nanmean(composite(500:560,:));
stdevs=nanstd(composite(500:560,:));
composite=composite-repmat(means,nrows,1);
composite=composite./repmat(stdevs,nrows,1);
save standardlow
else % now just standardize the new pcproxy network
means=nanmean(composite(500:560,1009:1008+nproxies));
stdevs=nanstd(composite(500:560,1009:1008+nproxies));
composite(:,1009:1008+nproxies)=composite(:,1009:1008+nproxies)-repmat(means,nrows,1);
composite(:,1009:1008+nproxies)=composite(:,1009:1008+nproxies)./repmat(stdevs,nrows,1);
end
The above code “standardizes” all proxies (and the surface temperature field) by subtracting the mean of the calibration period (1901-1971) and then divides by the std of the calibration period. I’m not sure whether this has any effect to the final results, but it is definitely also worth checking. If it does not have any effect, why would it be there?
In Mann et al 2007, they say:
When, as in most studies, data are standardized over the calibration period, however, the fidelity of the reconstructions is diminished when employing ridge regression in the RegEM procedure as in M05 (in particular, amplitudes are potentially underestimated; see Auxiliary Material, section 2).
The difference is not illustrated in the article itself, but here is the relevant comparison from the SI, illustrating the impact of calibration period standardization on Rutherford et al 2005 RegEM (using ridge regression) said to be corrected in Mann et al 2007 (using TTLS regression).
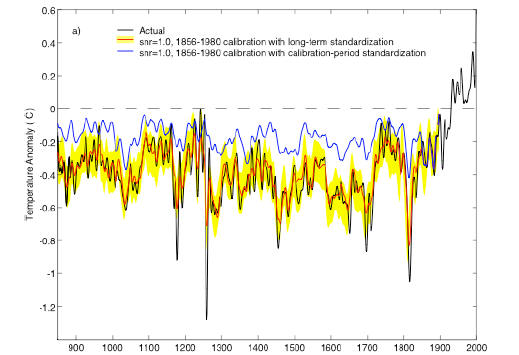
Rutherford et al had cited their code in their Journal of Climate article. In my opinion, Journal of Climate should require them to restore the code even if it was erroneous so that people can inspect what they did.
Stepwise Reconstruction
In Jean S’ note, he observes that the RegEM method is not really designed to deal with stepwise situations. In the MBH PCproxy network where PCs are calculated on several occasions, this poses an interesting conundrum: the PC most dominated by the bristlecones changes position so that bristlecones contribute mainly to the MBH PC2 in the AD1820 network, while they morph over to the PC1 in the earlier networks. What happens in a RegEM situation when PCs change places? It’s not discussed in any of the publications. It seems to me like it would be an issue, although I have no plans to investigate the matter.


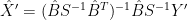
 and
and 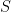 are ML estimates of
are ML estimates of  and
and 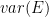 , obtained from the calibration experiment with a model
, obtained from the calibration experiment with a model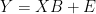
 , I get exactly the same result as with double pinv. Which verifies my observation that MBH9x is CCE with special assumption about proxy noise and with incorrect variance matching step after this classical estimation.
, I get exactly the same result as with double pinv. Which verifies my observation that MBH9x is CCE with special assumption about proxy noise and with incorrect variance matching step after this classical estimation.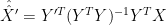
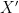 , which we don’t have. Thus OLS is out of the question. Yet, it is interesting to observe that OLS is actually a matrix weighted average between CCE and zero-matrix (Brown82, Eq 2.21) :
, which we don’t have. Thus OLS is out of the question. Yet, it is interesting to observe that OLS is actually a matrix weighted average between CCE and zero-matrix (Brown82, Eq 2.21) :![\hat{\hat{X}}'=[(X^TX)^{-1}+\hat{B}S^{-1}\hat{B}^T]^{-1}(\hat{B}S^{-1}\hat{B}^T)\hat{X}'](https://s0.wp.com/latex.php?latex=%5Chat%7B%5Chat%7BX%7D%7D%27%3D%5B%28X%5ETX%29%5E%7B-1%7D%2B%5Chat%7BB%7DS%5E%7B-1%7D%5Chat%7BB%7D%5ET%5D%5E%7B-1%7D%28%5Chat%7BB%7DS%5E%7B-1%7D%5Chat%7BB%7D%5ET%29%5Chat%7BX%7D%27+&bg=ffffff&fg=000&s=0&c=20201002)










