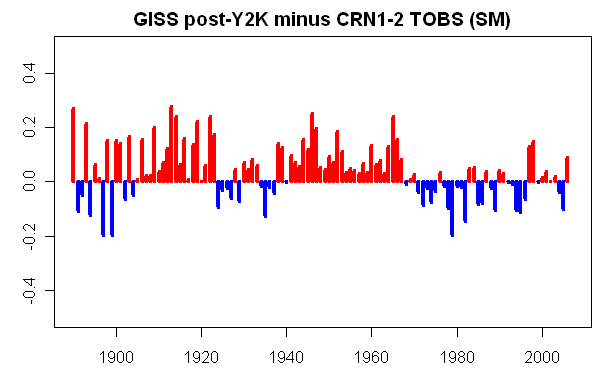
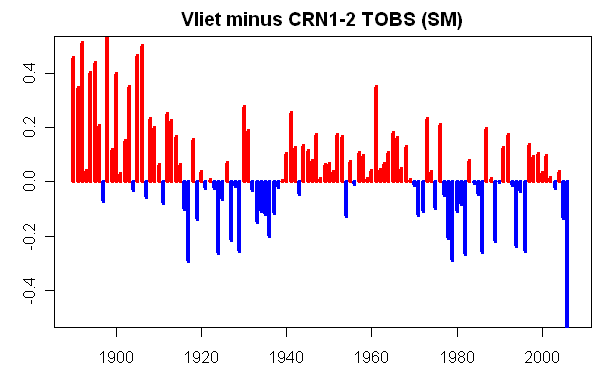
Recently Keigwin’s Sargasso Sea dO18 temperature reconstructions have been mentioned in the climate public eye. Keigwin’s reconstruction famously has a warm MWP as shown below. This reconstruction uses modern dO18 measurements at Station S to calibrate two cores (with modern Station S values specifically shown in the graphic below):

I observed last year that the Juckesian version of the Moberg reconstruction had a very different appearance using Sargasso Sea instead of Arabian Sea G Bulloides and using Indigirka instead of Yamal – a point that I re-iterated recently in light of the final Juckes paper. I discussed Juckes and the Sargasso Sea last year and in my Review Comments at CPD. We’ve discussed the Juckesian pretext for withholding the results with Indigirka. His pretext for excluding the Sargasso Sea SST reconstruction from dO18 is that the data ends in 1925 (a point was recently picked up at realclimate).
The Sargasso Sea series used by MSH2005 is sometimes mistakenly presented as having a 1975 data point representing the 19502000 mean, but the actual end point is 1925 and so this series is also omitted.
Today I want to discuss exactly what is and isn’t in the Keigwin Sargasso Sea data, amending some first thoughts based on clarifications provided below by several readers. Keigwin (1996) (see here) archived a data set with SST, salinity and dO!8 values from 1955 to 1995 here . Keigwin 1996 says:
As expected, the effects of decreased SST and increased salinity during the late 1960s combined to increase the dO18 value of equilibrium calcite. Over the full 42-year series, linear regressions between the SST, salinity and dO18 values show that temperature accounts for about two-thirds of the isotopic signal ( r2 = 0.61), whereas salinity accounts for one-third (r2 = 0.29). Thus, by comparison to sea surface changes during the past several decades, it is reasonable to interpret the foraminiferal isotopic data mostly in terms of SST change.
This statement, combined with the data set, looks like a calibration set. The above discussion – in which variance is allocated to factors – looks very much like a conventional statistical analysis. As I observed in my first cut at this:
The statistical model from the two-factor model is so uncannily accurate (r2= 0.9988) that I’m wondering whether some of the data here has been forced somehow. Actual and fitted dO18 values are shown below: you have to look very closely to see any discrepancy. The dashed line is not simply a replot of the data: you can notice some very small differences. I’ve never seen any proxy model that is remotely this accurate – so it is puzzling. Some time, I’ll try to check whether (say) the salinity measurements are forced and that’s why the model is so accurate.
My surmise that the model was forced was correct, but I missed what was being forced. The explanation is latent in the article – it’s just that what was being done was something that I hadn’t expected. Keigwin forced the dO18 values from SST and salinity measurements at Station S and then did a regression using the forced data set.
In order to gauge the influence of the annual variability of SST and salinity on the oxygen isotope ratios that might be recorded by surface-dwelling foraminifera at Station “S”, I calculated the 6% value of calcite precipitated in oxygen isotopic equilibrium with seawater (Fig. 3) (26).
What exactly does this calculation do – I guess that it somewhat quantifies the expected contributions of salinity and SST to dO18 variation, given the measured variability of SST and dO18. Here’s a way of representing the calculation which clarifies things for me: the black points show reconstructed SST from core sediments against the dO18 of the core sediments (in a linear relationship according to the reconstruction transfer model), while the red points show two 20-year averages of reconstructed (“modeled”) dO18 from measured SST and salinity using the Deuser/Keigwin methodology. Keigwin observed that core dO18 values (which integrated decadal periods) were outside the range of modern (estimated) values from Station S using current transfer models. His plot shown above amalgamates the modern and core data along these lines.
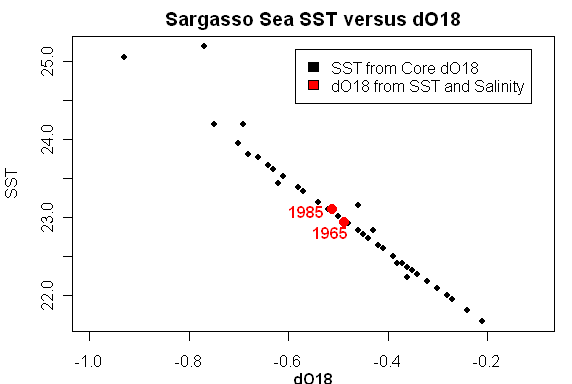
While I was looking at this data, I became intrigued with some of the properties of the original calibration of dO18 to SST in the Station S data set, which illustrate rather nicely some of the issues involved in reconstructions of any kind. The dO18 values here are forced and that’s why the model is 100% accurate. But let’s suppose that we actually did have a 100% accurate model and see what the effect of not knowing salinity does to the error structure of SST reconstructions. These are just thoughts right now.
Two-Factor dO18 Model
Although dO18 is used to reconstruct SST, the actual physical relationship goes from SST and salinity to dO18. As an experiment, I tried a simple regression of dO18 values against SST and salinity data as follows:
fm=lm(dO18~SST+Sal_psu,data=sarg.mod)

First, let’s look at the dO18 model (note that we’re fitting dO18 here rather than SST) if we just use SST for the reconstruction, as shown below. You can readily see that the model using only SST is less successful and that the residuals from the model leaving out a factor have positive autocorrelation (and a failed Durbin-Watson statistic.) This is a rather nice demonstration of how the Durbin Watson statistic gives evidence that a salient factor has been left out of the model. In econometrics, this is evidence that the model is mis-specified – a statistical method that Juckes et al for example simply repudiated without providing any statistical authority. Juckes’ say-so was high enough authority for editor Goosse, I guess. In this case, there is a fair amount of autocorrelation in the salinity data and this carries forward into the residuals from the incompletely specified model.

The above plot illustrates the situation for the modeling of dO18. However in climate studies, the procedure of interest is the reverse: the use of dO18 as a “proxy” to “reconstruct” SST. A common strategy is the use of “inverse regression” of SST against dO18 -even though the physical relationship is the opposite. I use the term “inverse regression” here as it’s used in calibration statistics off the Island. There’s been much made of inverse regression in climate science (von Storch, Juckes), where the term “inverse regression” does not coincide with “inverse regression” as used in conventional statistics, but to describe a variant of partial least squares used on the Island in various guises- a topic that I’ve discussed here. If the calibration is done from the regression of dO18 against SST, this is called “classic calibration” in calibration studies. For the discussion here, don’t worry about the terminology in the various studies, but about what is being done. Here I’m regressing SST against dO18 as shown below:
fm.inv=lm(SST~dO18,data=sarg.mod)
The figure below shows the SST reconstruction (top) and residuals (bottom) using inverse regression based only on SST – a defective model to be sure, but a model containing some information. I’ve also shown the reconstruction using variance matching. In a univariate case, this simply dilates the reconstruction a little, in which the price for matching the variance is the increase in the average size of the residuals. As you can readily see, the autocorrelation in the reconstruction residuals is intimately related to the defective model (in which the autocorrelation of the salinity is imposed onto the residuals.) You can also see that the variance-matching reconstruction and the inverse regression reconstruction are intimately related, with the one just being a dilation of the other.
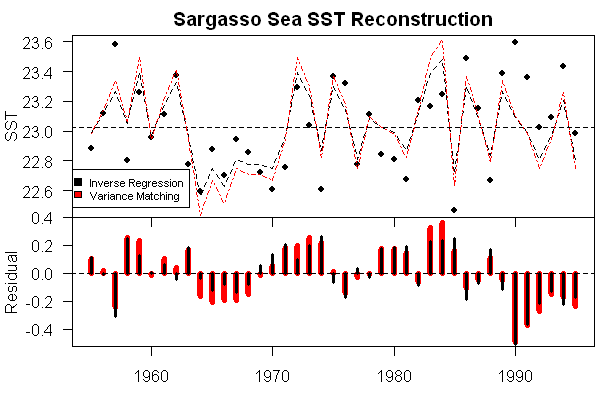
Thus, estimating the confidence interval of the reconstruction depends on the size of the impact of unreconstructed salinity. Because the mis-specified factor has considerable autocorrelation, the confidence intervals cannot be calculated in an elementary way. A common recipe in climate studies is to estimate the reduction in number of degrees of freedom. While the approach is not absurd, the devil is always in the details. I think that the salient question is: how many measurements are needed in an average so that the probability of the average error being within 
It should also be a little sobering to see how large the errors are in this case when one factor is unavailable for a proxy where, in this case, due to forcing, the model is specified to 100% accuracy. The standard deviation of the residuals was 0.2, while the standard deviation of the SST was 0.29 – this is in a perfect model with unknown salinity. If the dO18 model explained (say) 50% of the variance in the model, then these errors would have to be added in. I’ll do the calculations some time to try to figure out where the model “breaks even”.