I’m going to Georgia Tech for a couple of days at the kind invitation of JEG (Julien Emile-Geay) and Judith Curry. I’ll be presenting at their Friday afternoon EAS seminar series (http://www.eas.gatech.edu/school/seminars/) (3:30 to 4:30), which is geared towards a broad scientific audience. In addition, I’ll be spending time with each of the protagonists, plus the students of the Hockey Stick class, plus two dinners out. So it should be fun.
I’ve given invited presentations to a National Academy of Sciences panel, a subcommittee of the House Energy and Commerce Committee, an AGU Union session, but I’ve never given a presentation to a university seminar before. So this will be my first university seminar presentation.
It will also be my first presentation to climate scientists at a university. (Despite the wide coverage, I’ve only been invited to give one presentation to a university class – to Sinan Unur’s economics class.)
I think that I’m detecting a bit of a change in attitude among some climate scientists, especially younger ones. I’ve mentioned previously that a couple of young scientists at the 2006 AGU said that they thought that I had pretty much killed the Hockey Team studies and that the only way forward was through new and much improved data – which might take 10-20 years – something that I suspect is correct. This was obviously not the official viewpoint subsequently expressed in IPCC chapter 6 (but even there, as we now see from the Review Editor comments, there were some concerns on this section.) In 2006, they required that their identities be kept confidential.
At the 2006 AGU session, an enraged Malcolm Hughes said that there were so many errors in my presentation that he didn’t know where to start. If I’d been a little more alert in my repartee, I’d have suggested that he start by archiving his bristlecone data, but on my feet before an audience, I’m not Winston Churchill.
At the 2007 AGU, as I mentioned before, I was pleased by the very cordial attitude of several of the biggest names in paleo-oceanography. A lot of people came to my poster, mostly to introduce themselves and to encourage me.
JEG and Judith Curry have both been welcome visitors to this blog and, while they don’t necessarily agree with very much that I say, they’ve been brave enough to defend the proprietor of this blog to third parties, which I appreciate.
Young scientists are by nature probing their science – that’s what makes things “self-correcting”. Despite my calendar age, I’m relatively new at this particular game – I’ve been doing this about the same length of time as a grad student or post-doc. In lots of ways, I have more in common with young scientists than middle-aged scientists keen on defending their corpus.
Although I’m stepping on an airplane this afternoon (snow permitting), I’m still wrestling with what I’m going to say. I’ve been given a title designed to cover any eventuality: “Climate reconstructions of the past millennium : statistical considerations”. I haven’t really done much on the HS front for a while; the counterattacks in Wahl and Ammann 2007, Mann et al 2007 and Juckes et al 2007, didn’t raise any issues that I found interesting. One of the Nature reviewers in 2004 (who was probably Jolliffe) said of Mann’s response that he was particularly unimpressed with their attitude that by “shouting longer and louder they must be right”. Wahl and Ammann, in particularly, merely lengthened Mann’s 2004 reply submitted to Nature (though they nowhere even acknowledge Mann).
When I re-visited matters HS in preparation for the Georgia Tech presentation, I found myself drawn to three lines of thought, all of which have been discussed at the blog, but not all of which are easy to present to a general audience.
First, I found myself wanting to go back and discuss the linear algebra involved in reconstructions, showing how reconstructions could be placed in a more general statistical context (for example, that MBH98 could be simplified to weighting the proxies by correlation and that, in turn, was equivalent to Partial Least Squares.) And that there were all kinds of multivariate methods, with RegEM not being any sort of magic recipe. It’s hard to imagine anything less interesting to third parties than some linear algebra, but I’ve developed some relationships that I think are quite pretty and I’d like to give it a try. I’ll mull it over on the plane.
Second, on the basis that people accepted that statistical precautions were actually required for Team reconstructions, I fond myself wanting to review some of the econometric discussion of “spurious regression”. Many of the issues in dispute in proxy reconstructions were fought over long ago in econometrics, which confronted the problem of high correlation statistics (in Juckes’ terms, 99.999% significant) between series that had no possible connection – Yule’s famous example of the relationship between mortality and the proportion of C of E marriages or Hendry’s later example explaining inflation in terms of cumulative rainfall. For recons based on bristlecones or the Yamal reconstruction, the $64 question is whether the relationships that underlie Team studies are spurious or not. In this respect, the econometrics literature is far more aware of the risks of data mining – and, in particular, of cumulative data mining.
I found a great segue from these issues to some very specific proxy series that I think that I should discuss from Greene’s article on data mining:
But testing in un-mined data sets is a difficult standard to meet only to the extent one is impatient. There is a simple and honest way to avoid invalid testing. To be specific, suppose in 1980 one surveys the literature on money demand and decides the models could be improved. File the proposed improvement away until 2010 and test the new model over data with a starting date of 1981.
It’s impossible not to confront this with the IPCC AR4 statement in respect to divergence:
the possibility of investigating these issues further [a limit on the potential to reconstruct possible warm periods in earlier times] is restricted by the lack of recent tree ring data at most of the sites from which tree ring data discussed in this chapter were acquired.” (p. 473)
and then to show some slides and results from Almagre, which, among other things, showed that Colorado dendros could have a morning Starbucks and update bristlecones in the same day, a possibility that we’ve not proved for California, but which I suspect to be true there as well.
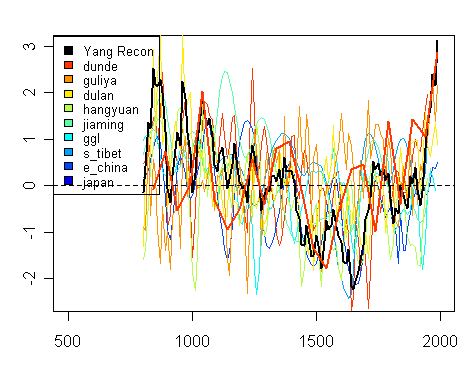
At this point, the inconsistency between versions at key sites (Sheep Mountain, Tornetrask, Polar Urals) becomes much more than a nit. In each case, there is a widely used version with a modern period that is warmer than the MWP (Graybill at Sheep Mountain, Briffa at Tornetrask and Briffa at Polar Urals). In each case, subsequent data has eliminated the modern-medieval differential (Ababneh 2006, 2007 at Sheep Mt; Grudd 2006, 2008 at Tornetrask and Schweingruber’s 1998 data at Polar Urals (in Esper 2002). In each case, later more ecological studies (Miller et al 2006 in California; Naurzbaev et al 2004 in Siberia) raise questions about the interpretations of the earlier studies.
In the ice core area, some dO18 series go up in the 20th century, some go down. I’m not sure that you can deduce very much.
Loehle did a new collection of data showing an MWP, but you don’t even need to add a new proxy compilation into the brew. You can get MWPs merely by taking variants of the key data sets in the canonical studies.
People can huff and puff all they like about multivariate methods, and, while there are many interesting statistical issues, at the end of the day, the results are being driven by the data and until the data is stable in individual localities, I don’t think that there’s much that can be concluded. And this means not just collecting more and new data, but reconciling completely to prior data, reconciling to ecological information in the area, better data recording, better data archiving.
If I keep writing this post any longer, I may actually figure out what I’m going to say.
Anyway, I’m looking forward to the trip.










 = .79 of this box, while the Sinusoidal only uses
= .79 of this box, while the Sinusoidal only uses 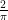 = .64 of this box. Thus, Mollweide gives about 23% more informational area within the same size figure.
= .64 of this box. Thus, Mollweide gives about 23% more informational area within the same size figure.