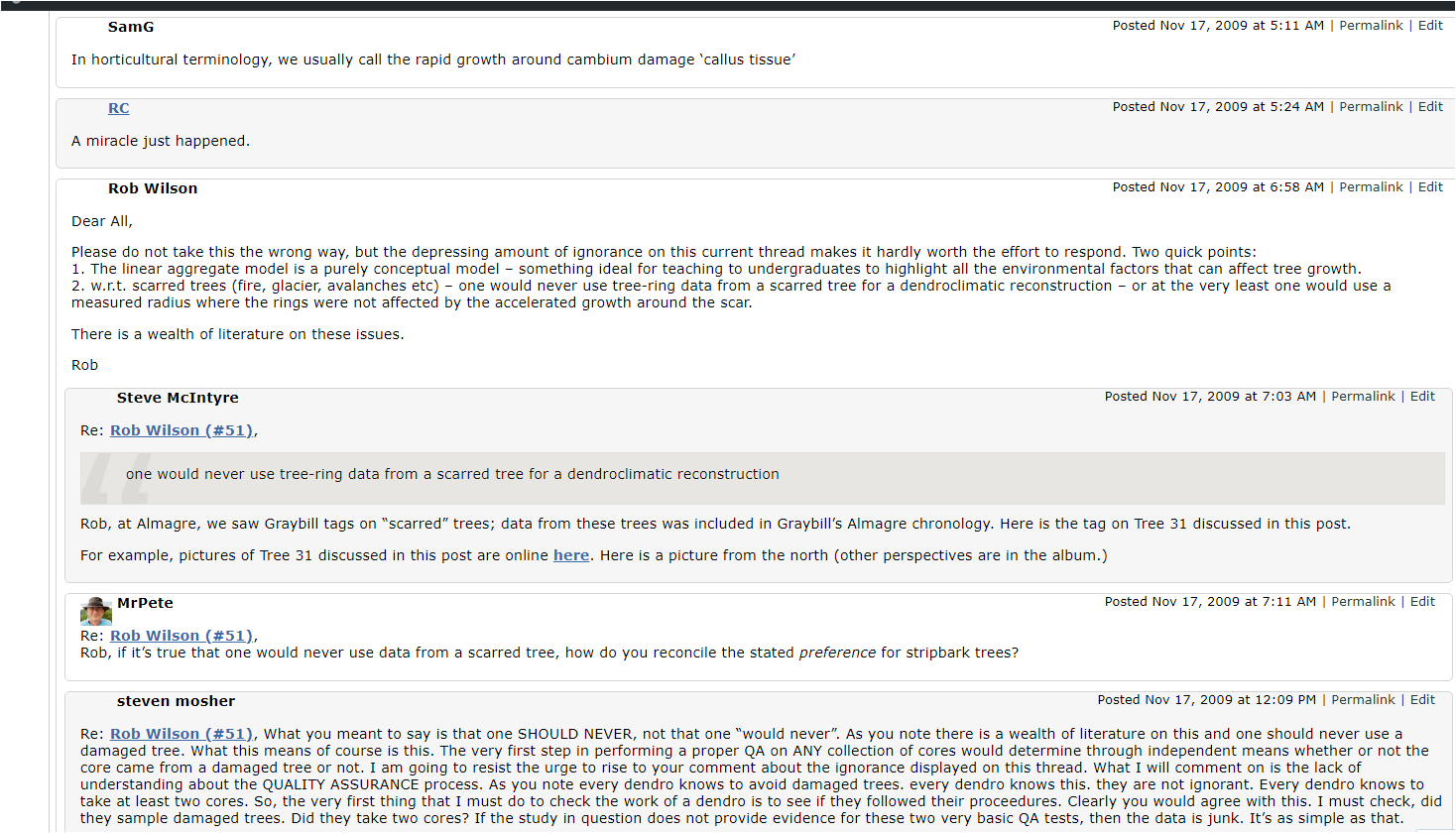
SM: This article by JD Ohio was submitted and briefly online on February 23, 2018, but, for some reason that I don’t recall, was taken offline. In any event, as Mann’s ancient libel case wends its way into a DC court, I noticed that it was still pending. It deals concisely with a central issue in the case.
By JDOhio
Analysis of Court of Appeals’ Defamation Opinion Holding That
Climategate Inquiries Exonerated Michael Mann
Foreword
I have followed climate matters for a long time and have been aware of the inquiries that followed Climategate. So, instinctively, when Michael Mann claimed that Climategate inquiries exonerated him, I believed the claim was incorrect. There were four inquiries that the appellate Court focused on (See p. 96 of court opinion which referred to “four separate investigations”) which accepted Mann’s argument that he had been exonerated. See link to opinion: https://cei.org/litigation/michael-e-mann-v-national-review-and-cei-et-al The Court’s identification of the inquiries was confusing, but I will focus on the main reports that seem to be the basis for the Court’s conclusion. Having reviewed the inquiries closely, my opinion is still that the investigations did not exonerate Mann.
Some of the emails are misleading, and the various reports and graphs that are important to the resolution of this case are very hard to keep track of. If one attempts to dive in the middle of this dispute without having a clear idea of the background, it is easy to get sucked down a rathole of confusing and overlapping studies, graphs, emails and inquiries. The point of this blog post is to create an accurate reference work that is comparatively easy to follow. So, although it is somewhat tedious, I have gone into a good amount of detail on what would otherwise be minor details.
Concise Summary of Findings
Although the Court was not always clear as to what four studies it was looking at (See *** at end of this post), here is a brief description of my findings pertaining to the studies most relevant to the Court opinion.
1. Muir Russell Report (also called called the Independent Climate Change E-mails Review (ICCER): This report was commissioned by the University of East Anglia (UEA) to look at issues that arose concerning the UEA following the release of 1073 UEA emails. Although Mann was mentioned in some of the emails, the real focus was on the academic integrity of the UEA. It could not exonerate Mann. The House of Commons reviewed Muir Russell, and the Court subsumed Muir Russell under the United Kingdom House of Commons Report.
2. Oxburgh Report (formally known as the “Science Appraisal Panel of Climatic Research Unit of University of East Anglia): This report was reviewed by the House of Commons report. It didn’t even mention Mann or any of his publications.
3. Penn State Two Stage Inquiry: These reports did not closely examine scientific criticism of Mann’s work, and Penn State totally flubbed the investigation into whether, at the very least, Mann indirectly took part in an email deletion scheme when he forwarded an email from Phil Jones to Gene Wahl asking for the deletion of emails pertaining to the Fourth Assessment Report (AR4) of the IPCC.
4. National Science Foundation (NSF) Close-Out Memo regarding Penn State investigation of Michael Mann. This Memo is completely unsubstantiated; it is not clear who wrote the memo or did the underlying work. Also, although it is widely believed that it is referring to Penn State and Mann, it never explicitly names either.
5. EPA Reconsideration of Endangerment Finding: On p. 83 of the opinion, the Court referred to the EPA as having found that the science underlying the Hockey Stick was valid. When the EPA did look at Mann specifically, it downplayed his contributions, and he was only mentioned once in the Reconsideration Report. (See p. 85 of report) Since the EPA’s consideration of Mann was so skimpy, and was only briefly mentioned by the Court, I will not discuss it further.
Overview of Important Science and Email Issues
Useful to Understanding the Legal Dispute
I. Problems with Tree Proxies (Divergence)
Around 1960, tree proxies which seemed to be accurate indicators of rising and falling temperatures began showing declines (less growth and density), when the instrumental records were showing rising temperatures. There seems to be no doubt that a number of tree proxies were simply inaccurate after 1960. See https://climateaudit.org/2008/11/30/criag-loehle-on-the-divergence-problem/ Thus, to the extent that tree proxies were known to be inaccurate it is sometimes reasonable, with full DISCLOSURE, to splice together old tree proxies from, say 500 years ago up to 1960 with instrumental records. If you continued with tree proxies known to be defective, it would obviously be wrong.
The problem with tree proxies raises a huge issue. If they aren’t accurate now, how do we know that they were accurate four or eight hundred years ago? The answer is that we don’t know. However, for some reason, a lot of skeptics place the vast majority of their focus on the instrumental temperatures and not the fairly easy question dealing with the apparent unreliability of proxies. It seems to me that the only way anyone can say that today’s global average temperatures (for example) are, let’s say 2.5 degrees C higher than those in the 10th century is to preface that statement with the qualifier, my best guess is….
II. The Misleading “Hide the Decline” Email
From Phil Jones: “I’ve just completed Mike’s [Mann’s] Nature trick of adding in the real temps to each series for the last 20 years (i.e., from 1981 onwards) and from 1961 for Keith’s to hide the decline.”
From: Phil Jones [November 1999]
To: ray bradley ,mann@xxxxx.xxx, mhughes@xxxx.xxx
Subject: Diagram for WMO Statement
Date: Tue, 16 Nov 1999 13:31:15 +0000
Cc: k.briffa@xxx.xx.xx,t.osborn@xxxx.xxx
Dear Ray, Mike and Malcolm,
Once Tim’s got a diagram here we’ll send that either later today or
first thing tomorrow.
I’ve just completed Mike’s Nature trick of adding in the real temps
to each series for the last 20 years (ie from 1981 onwards) amd from
1961 for Keith’s to hide the decline. Mike’s series got the annual
land and marine values while the other two got April-Sept for NH land
N of 20N. The latter two are real for 1999, while the estimate for 1999
for NH combined is +0.44C wrt 61-90. The Global estimate for 1999 with
data through Oct is +0.35C cf. 0.57 for 1998.
Thanks for the comments, Ray.
Cheers
Phil
Prof. Phil Jones
Climatic Research Unit Telephone +44 (0) xxxxx
School of Environmental Sciences Fax +44 (0) xxxx
University of East Anglia
Norwich Email p.jones@xxxx.xxx
See https://climateaudit.org/2009/11/20/mike%e2%80%99s-nature-trick/
(See also Climate Audit https://climateaudit.org/2011/03/29/keiths-science-trick-mikes-nature-trick-and-phils-combo/)
When you first hear the phrase “hide the decline,” it is easy to believe that the speaker is talking about hiding a real decline in instrumental temperatures. Instead what Jones is talking about is hiding the decline evident in tree proxies after approximately 1960. However, if you are going to attempt to have 1,000 year or 1,400 year temperature reconstructions, just a little bit of thought will make it clear that the tree ring proxies have to be dropped after 1960. On the other hand, there is a large question as to whether it is worthwhile to do 1000 year reconstructions when the proxies used are known to be unreliable in today’s world; how is it really possible to know that proxies were reliable 1000 years ago?
It is true that before the 1998 Hockey Stick introduced by Mann, the divergence problem had been discussed in was openly discussed in the literature. What Jones was doing when he spoke of “hide[ing] the decline” was attempting to gloss over the divergence problem and the decline in temperatures that would be shown by continuing to use tree proxies when extrapolating temperatures as shown in a paper written by Keith Briffa of University of East Anglia [UEA] who was part of the Climatic Research Unit (CRU).
III. Mike’s Nature Trick
This Trick is mentioned in the Nov. 16, 1999 email. To fully understand it, one must understand statistical smoothing and be conversant with, and compare, three different studies. I am not good at statistics and any explanation I could give would unduly complicate this post. So, I am skipping it. Steve McIntyre was kind enough to provide his summary, which is attached at the end of this post. See ***4
Analysis of “Exoneration” Part of Court of Appeals Decision
The Court of Appeals issued a lengthy, 111 page opinion, holding that Michael Mann had a valid defamation case to present against Rand Simberg, Rich Lowry, the National Review , the Competitive Enterprise Institute, and inferentially, Mark Steyn. (Who did not appeal, but whose case would rise and fall on the case of the others). The portion of the opinion that I am focusing on is that portion, from p. 82 to p. 97 in which the Court heavily relied on four investigations to reach the conclusion that the defendants could have acted with actual malice in criticizing Mann for the research he did.
My basic conclusion is that the four “investigations/endeavors” did not thoroughly investigate Mann and that the Court made a clear mistake when it incorrectly relied on the investigations to allow Mann’s lawsuit to proceed.
A. Some Publications, Resources and Facts That Are Important to the Case.
1. The Court of Appeals Decision
(See https://cei.org/litigation/michael-e-mann-v-national-review-and-cei-et-al )
2. The alleged defamatory columns attached to the end of the decision.
3. The Defendants are not claiming that Mann acted in a criminally fraudulent manner in the sense that he could have made up numbers. The defendants were using the term “fraud” in a polemical sense. In common polemical usage, “fraudulent” doesn’t mean honest-to-goodness criminal fraud. It means intellectually bogus and wrong.” (See p. 110 of the opinion)
4. MBH 98 (first Hockey Stick paper), MBH 99 (Second Hockey Stick Paper, going
1000 years further) See https://en.wikipedia.org/wiki/Michael_E._Mann See also, S. McIntyre collection of Hockey Stick publications.
Hockey Stick Studies
5. WMO Diagram and explanation of Hide the Decline email. Also, IPCC Third Assessment Graph
https://climateaudit.org/2009/12/10/ipcc-and-the-trick/ For more context, see http://www.americanthinker.com/articles/2010/02/climategates_phil_jones_confes.html
6. Hide the Decline email:
I’ve just completed Mike’s Nature trick of adding in the real temps to each series for the last 20 years (i.e., from 1981 onwards) and from 1961 for Keith’s to hide the decline. See:
https://www.justfacts.com/globalwarming.hidethedecline.asp
7. Phil Jones deletion email request sent to Mann for him to forward to Eugene Wahl, which Mann did.
“Mike,
Can you delete any emails you may have had with Keith [Briffa] re AR4? Keith will do likewise… Can you also email Gene [Wahl] and get him to do the same? I don’t have his new email address. We will be getting Caspar [Ammann] to do likewise.
Cheers, Phil
**** Mann reply:
“Hi Phil,
… I’ll contact Gene [Wahl] about this ASAP. His new email is: generwahl@xxx talk to you later, mike
For context, see: https://climateaudit.org/2011/02/23/new-light-on-delete-any- emails/ and https://climateaudit.org/2011/09/02/nsf-on-jones- email-destruction-enterprise/
B. Conceptual Errors Made by the Court of Appeals
The Court makes three fundamental errors. First, it assumes that those who label themselves as investigators really do investigate. Second, it assumes that a general investigation (assuming arguendo that a real investigation occurred) into a scientific field of study that finds there was no fraud in the field exonerates all of those in that field even if any individual’s work was only tangentially involved, if at all. Third, it assumes that those with advanced degrees, by virtue of their possession of advanced degrees, are competent and fair commentators and investigators in an area of much controversy. (See p. 85 of opinion)
Although the Court refers to “eight separate inquiries” (p. 82), in reality it only focused on four. The Court concluded on p. 96 that:
“We come to the same conclusion as in Nader. In the case before us now, not
one but four separate investigations were undertaken by different bodies following
accusations, based on the CRU emails, that Dr. Mann had engaged in deceptive
practices and scientific and academic misconduct. Each investigation unanimously
concluded that there was no misconduct.”
For a more detailed explanation of the four reports, one may go to McKitrick. See https://www.bing.com/search?q=ross+mckitrick+summary+of+climategate+investigations&qs=n&form=QBRE&sp=-1&pq=ross+mckitrick+summary+of+climategate+investigations&sc=0-52&sk=&cvid=DCB9DE01989A4284AA5A0D887E2E1254 I will discuss the the two UEA sponsored endeavors first, then the House of Commons report which evaluated them, and then discuss the NSF report.
1. The House of Commons Report
On January 25, 2011, the House of Commons issued its report regarding the investigations of the Climatic Research Unit of the University of East Anglia. Essentially what it did was to evaluate the Oxburgh and Muir Russell Reports. Inferentially, it also independently, in a small way, evaluated climate science as practiced by the CRU.
With respect to Michael Mann, his name is found three times in the report. See https://publications.parliament.uk/pa/cm201011/cmselect/cmsctech/444/44410.htm His name was mentioned twice in connection with two papers he co-authored, and once in regards to an email that Phil Jones sent him asking Mann to keep matters dealing with multi-proxy studies secret as between two other climate research colleagues. (See para. 71 of Report) Although the ethics of Mr. Jones were being examined, there was no focus on ethics of Michael Mann.
There are numerous scientific and practical issues raised by the report. However, although Mann was mentioned tangentially, there was no focus whatsoever on the individual quality of his work or of Mann’s personal ethics.
The report, in a small way, validates climate science by finding that those working at the UEA were not fraudulently manipulating data and were not unethically manipulating peer review. However, it in no way focused on Mann. Thus, there is no way that it exonerated Mann.
2. Oxburgh Endeavor (claimed investigation)
The House of Commons Report devoted virtually all of its attention to examining the validity of two investigatory (claimed) reports commissioned by the UEA. The first undertaking was the Science Appraisal Panel of Climatic Research Unit of University of East Anglia report that was issued April 14, 2010. It is Commonly known as Oxburgh [Ronald ]Inquiry. See ftn. 62 of https://en.wikipedia.org/wiki/Climatic_Research_Unit_email_controversy#Science_Assessment_Panel
It is clear beyond any doubt that the did not clear Michael Mann because it did not look at his work. Here are excerpts from the actual report:
“The Panel was set up …to assess the integrity of the research published by the [East Anglia] Climatic Research Unit [Emphasis added] in the light of various external assertions
… The essence of the criticism that the Panel was asked to address was that climatic data had been dishonestly selected, manipulated and/or presented to arrive at pre-determined conclusions that were not compatible with a fair interpretation of the original data….”
2. The Panel was not concerned with the question of whether the conclusions of the published research were correct. Rather it was asked to come to a view on
the integrity of the Unit’s research and whether as far as could be determined
the conclusions represented an honest and scientifically justified interpretation
of the data. The Panel worked by examining representative publications by
members of the Unit and subsequently by making two visits to the University
and interviewing and questioning members of the Unit…. ”
3. The eleven representative publications that the Panel considered in detail are
listed in Appendix B. The papers cover a period of more than twenty years and
were selected on the advice of the Royal Society. All had been published in
international scientific journals and had been through a process of peer review.
CRU agreed that they were a fair sample of the work of the Unit. [Emphasis added]…
Conclusions [of report]
…. We cannot help remarking that it is very surprising that research in an area that
depends so heavily on statistical methods has not been carried out in close
collaboration with professional statisticians….”
It is absolutely clear that this report had nothing to do with Mann and could not possibly have “exonerated” him. In fact, he was not mentioned in the report, and the 11 publications that were reviewed did not include any in which Mann was listed as a contributor. It is astonishing that Mann and his Attorney would make this argument. See p. 12 of Mann brief of Sept. 3, 2014 and https://cei.org/litigation/michael-e-mann-v-national-review-and-cei-et-al
3. Muir Russell Report
The Muir Russell report, officially, in Great Britain, called the Independent Climate Change E-mails Review (ICCER) commissioned by the UEA was extensively reviewed by the House of Commons. See here. It was a real, although not completely competent investigation, which issued a report that was 96 pages long. (As opposed to the Oxburgh report, which was 5 pages) On page 10 in para. no. 6, it stated in its conclusions that:
“The [Climategate] allegations relate to aspects of the behaviour of the CRU (UEA) scientists, such as their handling and release of data, their approach to peer review, and their role in the public presentation of results….”
****
18. On the allegation of withholding station identifiers we find that CRU shouldhave made available an unambiguous list of the stations used in each of the versionsof the Climatic Research Unit Land Temperature Record (CRUTEM) at the time of publication.We find that CRU’s responses to reasonable requests for information were unhelpful and defensive.
19. The overall implication of the allegations was to cast doubt on the extent to which CRU’s work in this area could be trusted and should be relied upon and we find no evidence to support that implication.
****
22. On the allegation that the phenomenon of “divergence” may not have been properly taken into account when expressing the uncertainty associated with [proxy] reconstructions, we are satisfied that it is not hidden and that the subject is openly and extensively discussed in the literature, including CRU papers.
23. On the allegation that the references in a specific e-mail to a ‘trick’ and to ‘hide the decline* in respect of a 1999 WMO report figure show evidence of intent to paint a misleading picture, we find that, given its subsequent iconic significance (not least the use of a similar figure in the IPCC Third Assessment Report), the figure supplied for the WMO Report was misleading. We do not find that it is misleading to curtail reconstructions at some point per se, or to splice data, but we believe that both of these procedures should have been made plain – ideally in the figure but certainly clearly described in either the caption or the text.
As, the above quotations make clear, Michael Mann’s work was not the focus of the investigation, and, although his actions were of moderate importance to some of the actions of the CRU scientists, his work, in and of itself was only tangentially scrutinized. For instance on p. 81, the Muir Russell report stated that Keith Briffa had explained:
“WA2007 had then shown that the results of MBH98 could be replicated very closely using their implementation of the MBH98 methods and using the same data.”
However, that statement was diminished in importance by the statement that:
“Briffa and his colleague Osborn commented that in any case the MBH98 was only one of 12 such reconstructions in figure 6.10 in Chapter 6, and does not therefore dominate the picture.” (p. 81 Muir Russell Report)
It is worth noting that although skeptics were allowed to make submissions, Muir Russell relied on Keith Briffa (of the CRU and the lead author) and John Mitchell (a review editor for Chapter 6) to evaluate the validity of paleoclimate work in AR4 [Fourth Assessment Report of IPCC] and that since it was their ultimate product that was being evaluated, they are not neutral, objective observers.
Thus, any claim that Muir Russell exonerated Mann is clearly false. In one, very important, aspect, the Report, even considering its limited scope, was very deficient; it failed to ask Phil Jones whether he deleted emails after Jones received a FOIA request. See https://climateaudit.org/2012/02/06/acton-tricks-the-ico/ (The particular email that raised this issue is discussed in the next section)
4. Penn State Endeavor — Alleged Research Investigation
Because the Penn State endeavor was superficial and did not interview critics of Mann, it does not deserve to be called an “investigation.” Instead, I am calling it an endeavor. In the Sixth Edition of Black’s Law Dictionary, the word “investigate” is defined as:
“To trace or track; to search into with care and accuracy; to find out by careful inquisition; examination; …”
Under Black’s definition, and general usage, what Penn State did was not an investigation. It did not interview people who had problems with Mann’s work. It is as if there was an accusation of theft, and the police went only to the accused thief and asked him if stole anything, and the accused said no. For there to be a true investigation, people from both sides of the controversy have to be questioned and interviewed. There was an inquiry report published on Feb. 3, 2010 and a later investigation report filed on June 4, 2010. About 85% of the Feb. 3, 2010 report was subsumed into the June 4, 2010 report, so this commentary will be focused on the June report.
For example, Steven McIntyre, in an Amicus Brief, pp3-4, stated that “falsification concerns about Mann’s research” included:
- “Mann’s undisclosed use in a 1998 paper (“MBH98”) of an algorithm which mined data for hockey-stick shaped series. The algorithm was so powerful that it could produce hockey-stick shaped “reconstructions” from auto-correlated red noise. Mann’s failure to disclose the algorithm continued even in a 2004 corrigendum.”
- Mann’s misleading claims about the “robustness” of his reconstruction to the presence/absence of tree ring chronologies, including failing to fully disclose calculations excluding questionable data from strip bark bristlecone pine trees.” ….
- Mann’s deletion of the late 20th century portion of the Briffa temperature reconstruction in Figure 2.21 in the IPCC Third Assessment Report (2001) to conceal its sharp decline, in apparent response to concerns that showing the data would “dilute the message” and give “fodder to the skeptics.”
- Mann’s insistence in 2004 that “no researchers in this field have ever, to our knowledge, ‘grafted the thermometer record onto'” any reconstruction. But it was later revealed that in one figure for the cover of the 1999 World Meteorological Organization (WMO) annual report, the temperature record had not only been grafted onto the various reconstructions-and in the case of
the Briffa reconstruction, had been substituted for the actual proxy data.”
For the present purposes, putting aside whose version of the matters alluded to by McIntyre is correct, at the very least Penn State should have questioned both Mann and McIntyre closely about the matters discussed above. It failed to do so. Thus, Clive Crook’s criticism is spot on:
“The Penn State inquiry exonerating Michael Mann — the paleoclimatologist who came up with “the hockey stick” — would be difficult to parody. Three of four allegations are dismissed out of hand at the outset: the inquiry announces that, for “lack of credible evidence”, it will not even investigate them. … Moving on, the report then says, in effect, that Mann is a distinguished scholar, a successful raiser of research funding, a man admired by his peers — so any allegation of academic impropriety must be false.” See here.
One very important issue that was to be determined by the PSU endeavor concerned the collusion by Mann and others to destroy email correspondence:
“Did you engage in, or participate in, directly or indirectly, any actions with the intent to delete, conceal or otherwise destroy emails, information and/or data, related to AR4, as suggested by Phil Jones?” (See )
This issue was described in detail and put in context, by Stephen McIntyre at Climate Audit here beginning with Jones’ email on May 29, 2008:
“[Phil] Jones then notoriously asked Mann to delete his emails, asking Mann to forward the request to [Gene] Wahl, saying that Briffa and Ammann would do likewise:
‘Mike,
Can you delete any emails you may have had with Keith [Briffa] re AR4? Keith will do likewise… Can you also email Gene [Wahl] and get him to do the same? I don’t have his new email address. We will be getting Caspar [Ammann] to do likewise.
Cheers, Phil’
Mann replied the same day as follows:
‘ Hi Phil,
… I’ll contact Gene [Wahl] about this ASAP. His new email is: generwahl@xxx
talk to you later,
mike’
That Mann lived up to his promise to Jones to contact Wahl about deleting the emails seems certain. In early 2011, from the report of the NOAA OIG, we learned that Wahl (by this time, a NOAA employee), told the NOAA IG that “he believes that he deleted the referenced emails at the time.” See here.
It is clear that, at the very least, being charitable to Mann, he indirectly engaged in : “actions with the intent to delete, conceal or otherwise destroy emails, information and/or data, related to AR4, as suggested by Phil Jones” Yet the alleged PSU investigation totally botched this simple, very important issue.
5. National Science Foundation Closeout Memorandum
On page 90 of its opinion, the Court of Appeals referred a National Science Foundation (NSF) report, which did investigate Mann and in which its investigators talked to Stephen McIntyre, but did not reference his comments or the questions that were asked. The report was barely over four pages long and was unsigned and not dated. See bottom of page here. The report contained no indication whatsoever as to who wrote the memo or who performed the tasks that were identified in the memo. Moreover, neither Penn State nor Michael Mann were specifically named in the report. In over 30 years of practicing law, I have never seen such a weird document.
The memo was dense and filled with “bureaucratic speak” which tends to distract attention from those matters that are pertinent to the opinion of the Court of Appeals. It is difficult to improve on Steve McIntyre’s summary of the report from his Amicus Brief (See ), so I will borrow heavily from him. The relevant portions of his summary were that:
“The National Science Foundation (“NSF”) spoke to some of Mann’s critics (including … [Stephen] Mclntyre), but the report did not name them or discuss any of the falsification concerns.
* Nor was the NSF investigation “broadened” to the extent portrayed by the division. Its investigation was limited to misconduct as defined in the NSF Research Misconduct Policy, which concerns only “fabrication, falsification and plagiarism … in research funded by NSF.” It stated that Mann “did not directly receive NSF research funding as a Principal Investigator until late 2001 or 2002.” Because the MBH98 and Figure 2.21 falsification allegations pre-dated 2001, the NSF had no jurisdiction over these allegations.
* There is no evidence that the NSF “broadened” its investigation to consider claims regarding Mann’s unprofessional conduct under Policy AD47 (over which it had no jurisdiction).
* Finally, the NSF (like Penn State) never investigated Mann’s role in getting Wahl to delete the most sensitive email correspondence. ” (See p.10 of brief.)
There are three basic points to be made about the NSF memo. First, the memo does not investigate much of Mann’s work, and so it could not exonerate him from charges concerning the validity of the whole body of his work. Second, it did not investigate whether Mann assisted, or encouraged Eugene Wahl to delete emails, which is an extremely important issue touching on his professionalism and compliance with the law. Third, the memo is completely unsubstantiated; it is not clear who wrote the memo or did the underlying work. Without being familiar with the genesis and the manner in which the memo was written, there is no way to assess its credibility or the accuracy of its findings.
6. Climategate Emails
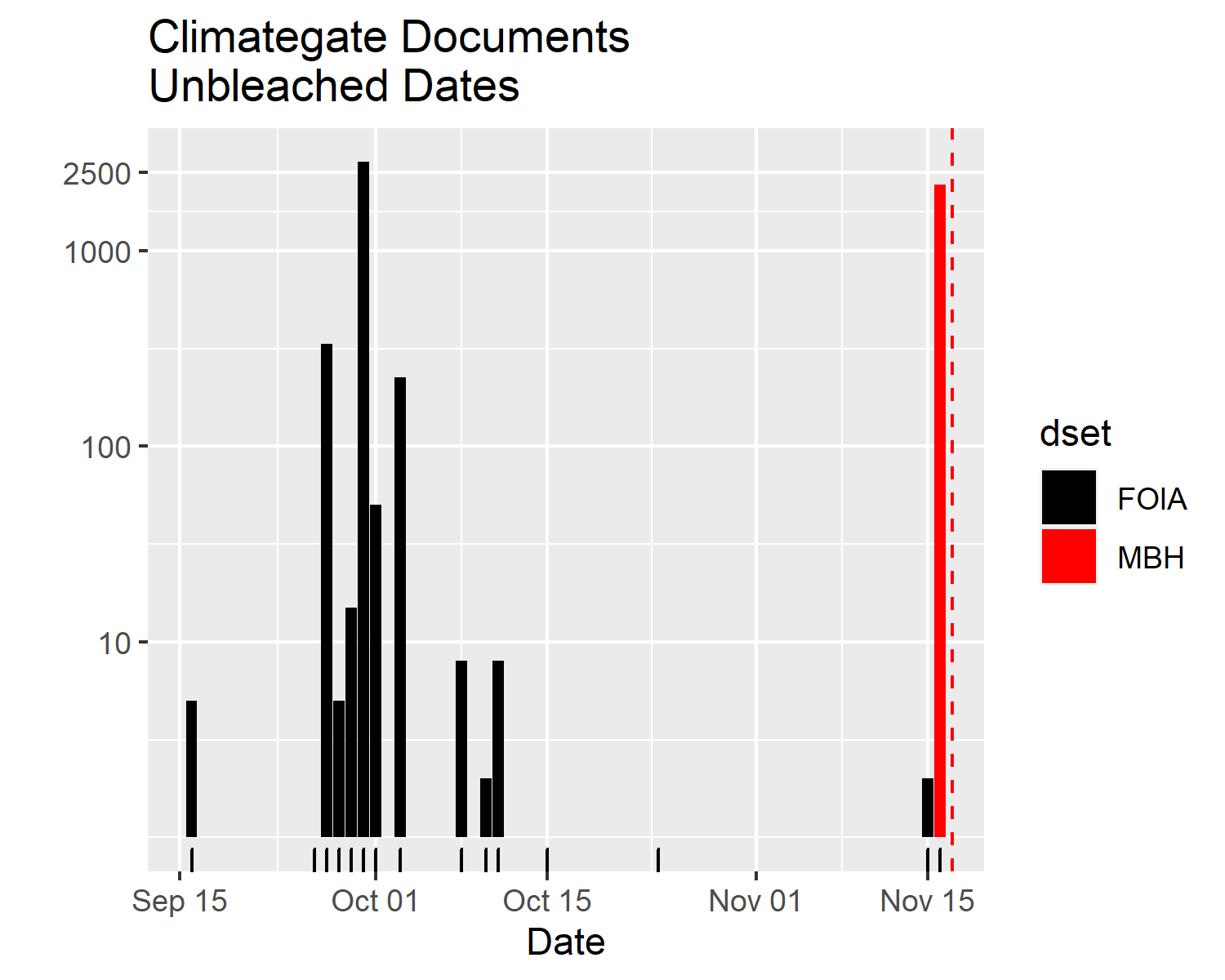
On p. 84 of its opinion, the Court referred to 1075 CRU emails and claimed that investigations of these emails contributed to the exoneration of Mann. (The Muir Russell Report on p. 26 referred to 1073 emails)
This reliance on investigations of the emails is misplaced for a number of reasons. First the emails examined were less than .3% of the CRU’s emails. (See p. 26 of Muir Russell Report) From 1998 on, there would be many more emails written by Mann at the institutions where he worked that were not sent to the UEA, and none of these were included in the 1075 emails discussed by the Court. Second, the Muir Russell Report report found that out of the 1073 emails only 140 involved Mann. (Muir Russell Report p. 26). Third, the one report that explained its procedures in detail and did appear to take a substantial look at the emails, the Muir Russell Report, was only examining the emails to determine how they reflected on the CRU; there was no attempt to focus specifically on Mann’s culpability or innocence.
7. Legal Sleights of Hand
Since this post is focused mostly on whether, as a factual matter, Mann was exonerated by the investigations identified by the Court, it is designed to mostly avoid legal issues and standards. However, there are several instances of legal misdirections that are closely tied to the exoneration issue. I would like to highlight them.
First, the Court stated: “Dr. Mann also submitted extensive documentation from eight separate inquiries that either found no evidence supporting allegations that he engaged in fraud or misconduct or concluded that the methodology used to generate the data that resulted in the hockey stick graph is valid and that the data were not fabricated or wrongly manipulated.” The phrase beginning with “or concluded” has the effect of shifting the focus from the actions of Mann to climate science in general. This shift is improper in this case because it is the actions of Michael Mann that are at issue in the defamation case, not the validity or invalidity of “mainstream” climate science. For instance, mainstream climate science could be valid, but Mann, as an individual, could be misapplying it.
Second, the Court stated: “We set aside the reports and articles that deal with the validity of the hockey stick graph representation of global warming and its underlying scientific methodology. The University of East Anglia, the U.S. Environmental Protection Agency, and the U.S. Department of Commerce issued reports that concluded that the CRU emails did not compromise the validity of the science underlying the hockey stick graph.” (See p. 83). This makes no sense at all because one of the main criticisms of Mann was that he, in some circumstances, was complicit in the publication of graphs that concealed the decline in the tree ring density proxies relative to instrumental temperatures. As previously noted, p. 13 of the Muir Russell Report stated:
“On the allegation that the references in a specific e-mail to a ‘trick’ and to ‘hide the decline* in respect of a 1999 WMO report figure show evidence of intent to paint a misleading picture, we find that, given its subsequent iconic significance (not least the use of a similar figure in the IPCC Third Assessment Report), the figure supplied for the WMO Report was misleading.”
Third, on p. 83 of its opinion, the Court stated that the alleged false statements that formed a legitimate basis for Mann’s defamation suit were: “that Dr. Mann engaged in “dishonesty,” “fraud,” and “misconduct.” The undisclosed concealing of the decline in the IPCC report and the splicing of two different data sets in the WMO report can certainly be criticized as being “dishonest” or as evidence of “misconduct.” By putting aside evidence that Mann was involved in undisclosed manipulation, the Court is unfairly penalizing the defendants, for potentially, pointing out, at the very least, objectionable behavior by Mann.
Fourth, on p. 84, the Court stated four institutions: “conducted investigations and issued reports that concluded that the scientists’ correspondence in the 1,075 CRU emails that were reviewed did not reveal research or scientific misconduct. Appellants do not counter any of these reports with other investigations into the CRU emails that reach a contrary conclusion about Dr. Mann’s integrity.” As this post makes clear, there is no evidence that any of the four investigations thoroughly examined Mann. Thus, the Court should not rely on those investigations. Additionally, even if there were thorough investigations, they do not have to be rebutted by other institutional investigations. For instance, if McIntyre’s criticisms, set forth in Sec. 4 of this post are true, it does not matter what the reports referenced by the Court stated.
Conclusion
A true exoneration of someone accused of misconduct would involve transparent, thorough exchanges between the supporters and opponents of the accused. Then, at the conclusion of that process, there would be clear, verifiable proof that the charges were incorrect. That did not occur with respect to Mr. Mann.
The recent mistakes made in the investigation of Larry Nassar, a Michigan State and USA Gymnastics physician, illustrate the problems in relying on one-sided and superficial reports. Michigan State began receiving reports of sexual abuse in 1997, and it was not until 2016 that the reports were finally given credence. Patrick Fitzgerald, a nationally known Federal Prosecutor, was hired to investigate the claims of sexual abuse in 2014. Later, in 2017, he was asked about his work and Fitzgerald stated:
“his law firm and another were retained by MSU, in part, “to review the underlying facts and disclose any evidence that others knowingly assisted or concealed” Nassar’s criminal conduct.
“Had we found such conduct, we would have reported such evidence to law enforcement promptly. And much as there is no ‘investigative report,’ there is no document that constitutes ‘Fitzgerald findings.’ ”
http://www.detroitnews.com/story/news/local/michigan/2017/12/08/msu-larry-nassar-investigation/108437686/
In light of the numerous cases of sexual abuse that came to light, it is clear that Fitzgerald, notwithstanding, his, to that point, sterling national reputation, had done a poor job in his work for Michigan State. In much the same way, even though there are a number of reports that purport to exonerate Mann, a reasonably close look at the reports reveals that they are superficial and couldn’t possibly exonerate Mann from charges of misconduct. Further, some of the investigations that Mann claimed exonerated him did not even focus on his work.
JD Ohio
END OF POST
Explanatory Notes
1. I originally proposed this post to Lucia, and she agreed to host it. Steve McIntyre provided some links and materials to me, so I offered to cross-post at his site, and he accepted. So, I am posting at both sites.
2. Popehat also criticized the exoneration portion of the Court’s opinion. See https://www.popehat.com/2017/01/04/dc-appellate-court-hands-michael-mann-a-partial-victory-on-climate-change-libel-case/
3. I actually have the PSU reports, but I can’t find a working link. If someone has a link to their reports, it will help. In the post, I linked to McKitrick’s article on the Climategate investigations, which gives a good summary.
***4. From Steve McIntyre here is his summary of Mike’s Nature Trick.
Mike’s Nature Trick was totally different from his subsequent talking-points, in which he claimed that his “trick” was to show actual data (e.g. instrumental temperature) and estimates (e.g. proxy reconstruction) in the same figure. However, such figures have been commonplace since the start of statistics. The technique was not invented by Mann nor is it a “trick”.
Mann’s Nature Trick was a sly method of creating an uptick in the smoothed proxy reconstruction, a topic of ongoing interest to Mann. Smoothed graphs require data after the end point. Mann spliced his unsmoothed proxy reconstruction up to 1980 with actual temperature data from 1981 to 1995 (MBH98), then later 1998(MBH99), prior to smoothing with a Butterworth filter of 50 years in MBH98 (MBH99- 40 years) with additional padding from average instrumental data. All values of the smooth subsequent to the end of the proxy period were then discarded. (For more detail, see here; the topic was originally diagnosed in 2007 by CA reader UC here and expounded in greater length with Matlab code here.)
The effect of the trick was to remove an inconvenient downturn at the end of the smoothed series, which resulted using Mann’s smoothing method without splicing instrumental data. Mann’s “trick” was first noticed at Climate Audit in 2007, long before the Climategate email. UC and others sardonically contrasted Mann’s actual technique with his loud proclamations at realclimate that no climate scientist had ever spliced instrumental and proxy data in a reconstruction.
Despite Jones’ email, the technique described in Jones’ email varied somewhat from the technique in Mann’s 1998 article. Like Mann’s 1998 article, Jones combined the proxy reconstruction and instrumental data to construct the smoothed series shown in the WMO 1999 report. But whereas Mann had cut the smoothed reconstruction back to the end of the proxy reconstruction, Jones instead showed the single merged series, a glaring rebuttal of Mann’s strident claim that:
No researchers in this field have ever, to our knowledge, “grafted the thermometer record onto” any reconstruction. It is somewhat disappointing to find this specious claim (which we usually find originating from industry-funded climate disinformation websites) appearing in this forum.
5. I am fairly busy now and may be slow responding to comments.
***As to the reports actually relied upon by the Court, it is confusing. There is one reference to an EPA report in passing, but it is never discussed in detail. There are detailed discussions of the House of Commons Report (roughly 85% of it discussed the Muir Russell Report and the Oxburgh Report) Even more confusing, is that the Court never specifically discussed the Oxburgh Report. In any event, for my purposes, I will consider the the four reports referenced by the Court requiring some substantive discussion to be, the Muir Russell Report, the Oxburg Report, the Penn State Reports (two different reports were made to Penn State)
*************





 associated with the notorious “dirty laundry” Climategate email (
associated with the notorious “dirty laundry” Climategate email (